本文已經收錄到Github倉庫,該倉庫包含計算機基礎、Java基礎、多執行緒、JVM、資料庫、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服務、設計模式、架構、校招社招分享等核心知識點,歡迎star~
Github地址:https://github.com/Tyson0314/Java-learning
為什么要使用訊息佇列?
總結一下,主要三點原因:解耦、異步、削峰,
1、解耦,比如,用戶下單后,訂單系統需要通知庫存系統,假如庫存系統無法訪問,則訂單減庫存將失敗,從而導致訂單操作失敗,訂單系統與庫存系統耦合,這個時候如果使用訊息佇列,可以回傳給用戶成功,先把訊息持久化,等庫存系統恢復后,就可以正常消費減去庫存了,
2、異步,將訊息寫入訊息佇列,非必要的業務邏輯以異步的方式運行,不影響主流程業務,
3、削峰,消費端慢慢的按照資料庫能處理的并發量,從訊息佇列中慢慢拉取訊息,在生產中,這個短暫的高峰期積壓是允許的,比如秒殺活動,一般會因為流量過大,從而導致流量暴增,應用掛掉,這個時候加上訊息佇列,服務器接收到用戶的請求后,首先寫入訊息佇列,如果訊息佇列長度超過最大數量,則直接拋棄用戶請求或跳轉到錯誤頁面,
使用了訊息佇列會有什么缺點
- 系統可用性降低,引入訊息佇列之后,如果訊息佇列掛了,可能會影響到業務系統的可用性,
- 系統復雜性增加,加入了訊息佇列,要多考慮很多方面的問題,比如:一致性問題、如何保證訊息不被重復消費、如何保證訊息可靠性傳輸等,
常見的訊息佇列對比
| 對比方向 | 概要 |
|---|---|
| 吞吐量 | 萬級的 ActiveMQ 和 RabbitMQ 的吞吐量(ActiveMQ 的性能最差)要比 十萬級甚至是百萬級的 RocketMQ 和 Kafka 低一個數量級, |
| 可用性 | 都可以實作高可用,ActiveMQ 和 RabbitMQ 都是基于主從架構實作高可用性,RocketMQ 基于分布式架構, kafka 也是分布式的,一個資料多個副本,少數機器宕機,不會丟失資料,不會導致不可用 |
| 時效性 | RabbitMQ 基于 erlang 開發,所以并發能力很強,性能極其好,延時很低,達到微秒級,其他三個都是 ms 級, |
| 功能支持 | 除了 Kafka,其他三個功能都較為完備, Kafka 功能較為簡單,主要支持簡單的 MQ 功能,在大資料領域的實時計算以及日志采集被大規模使用,是事實上的標準 |
| 訊息丟失 | ActiveMQ 和 RabbitMQ 丟失的可能性非常低, RocketMQ 和 Kafka 理論上不會丟失, |
總結:
- ActiveMQ 的社區算是比較成熟,但是較目前來說,ActiveMQ 的性能比較差,而且版本迭代很慢,不推薦使用,
- RabbitMQ 在吞吐量方面雖然稍遜于 Kafka 和 RocketMQ ,但是由于它基于 erlang 開發,所以并發能力很強,性能極其好,延時很低,達到微秒級,但是也因為 RabbitMQ 基于 erlang 開發,所以國內很少有公司有實力做 erlang 原始碼級別的研究和定制,如果業務場景對并發量要求不是太高(十萬級、百萬級),那這四種訊息佇列中,RabbitMQ 一定是你的首選,如果是大資料領域的實時計算、日志采集等場景,用 Kafka 是業內標準的,絕對沒問題,社區活躍度很高,絕對不會黃,何況幾乎是全世界這個領域的事實性規范,
- RocketMQ 阿里出品,Java 系開源專案,源代碼我們可以直接閱讀,然后可以定制自己公司的 MQ,并且 RocketMQ 有阿里巴巴的實際業務場景的實戰考驗,RocketMQ 社區活躍度相對較為一般,不過也還可以,檔案相對來說簡單一些,然后介面這塊不是按照標準 JMS 規范走的有些系統要遷移需要修改大量代碼,還有就是阿里出臺的技術,你得做好這個技術萬一被拋棄,社區黃掉的風險,那如果你們公司有技術實力我覺得用 RocketMQ 挺好的
- Kafka 的特點其實很明顯,就是僅僅提供較少的核心功能,但是提供超高的吞吐量,ms 級的延遲,極高的可用性以及可靠性,而且分布式可以任意擴展,同時 kafka 最好是支撐較少的 topic 數量即可,保證其超高吞吐量,kafka 唯一的一點劣勢是有可能訊息重復消費,那么對資料準確性會造成極其輕微的影響,在大資料領域中以及日志采集中,這點輕微影響可以忽略這個特性天然適合大資料實時計算以及日志收集,
如何保證訊息佇列的高可用?
RabbitMQ:鏡像集群模式
RabbitMQ 是基于主從做高可用性的,Rabbitmq有三種模式:單機模式、普通集群模式、鏡像集群模式,單機模式一般在生產環境中很少用,普通集群模式只是提高了系統的吞吐量,讓集群中多個節點來服務某個 Queue 的讀寫操作,那么真正實作 RabbitMQ 高可用的是鏡像集群模式,
鏡像集群模式跟普通集群模式不一樣的是,創建的 Queue,無論元資料還是Queue 里的訊息都會存在于多個實體上,然后每次你寫訊息到 Queue 的時候,都會自動和多個實體的 Queue 進行訊息同步,這樣設計,好處在于:任何一個機器宕機不影響其他機器的使用,壞處在于:1. 性能開銷太大:訊息同步所有機器,導致網路帶寬壓力和消耗很重;2. 擴展性差:如果某個 Queue 負載很重,即便加機器,新增的機器也包含了這個 Queue 的所有資料,并沒有辦法線性擴展你的 Queue,
Kafka:partition 和 replica 機制
Kafka 基本架構是多個 broker 組成,每個 broker 是一個節點,創建一個 topic 可以劃分為多個 partition,每個 partition 可以存在于不同的 broker 上,每個 partition 就放一部分資料,這就是天然的分布式訊息佇列,就是說一個 topic 的資料,是分散放在多個機器上的,每個機器就放一部分資料,
Kafka 0.8 以前,是沒有 HA 機制的,任何一個 broker 宕機了,它的 partition 就沒法寫也沒法讀了,沒有什么高可用性可言,
Kafka 0.8 以后,提供了 HA 機制,就是 replica 副本機制,每個 partition 的資料都會同步到其他機器上,形成自己的多個 replica 副本,然后所有 replica 會選舉一個 leader 出來,生產和消費都跟這個 leader 打交道,然后其他 replica 就是 follower,寫的時候,leader 會負責把資料同步到所有 follower 上去,讀的時候就直接讀 leader 上資料即可,Kafka 會均勻的將一個 partition 的所有 replica 分布在不同的機器上,這樣才可以提高容錯性,
MQ常用協議
-
AMQP協議 AMQP即Advanced Message Queuing Protocol,一個提供統一訊息服務的應用層標準高級訊息佇列協議,是應用層協議的一個開放標準,為面向訊息的中間件設計,基于此協議的客戶端與訊息中間件可傳遞訊息,并不受客戶端/中間件不同產品,不同開發語言等條件的限制,
優點:可靠、通用
-
MQTT協議 MQTT(Message Queuing Telemetry Transport,訊息佇列遙測傳輸)是IBM開發的一個即時通訊協議,有可能成為物聯網的重要組成部分,該協議支持所有平臺,幾乎可以把所有聯網物品和外部連接起來,被用來當做傳感器和致動器(比如通過Twitter讓房屋聯網)的通信協議,
優點:格式簡潔、占用帶寬小、移動端通信、PUSH、嵌入式系統
-
STOMP協議 STOMP(Streaming Text Orientated Message Protocol)是流文本定向訊息協議,是一種為MOM(Message Oriented Middleware,面向訊息的中間件)設計的簡單文本協議,STOMP提供一個可互操作的連接格式,允許客戶端與任意STOMP訊息代理(Broker)進行互動,
優點:命令模式(非topic/queue模式)
-
XMPP協議 XMPP(可擴展訊息處理現場協議,Extensible Messaging and Presence Protocol)是基于可擴展標記語言(XML)的協議,多用于即時訊息(IM)以及在線現場探測,適用于服務器之間的準即時操作,核心是基于XML流傳輸,這個協議可能最終允許因特網用戶向因特網上的其他任何人發送即時訊息,即使其作業系統和瀏覽器不同,
優點:通用公開、兼容性強、可擴展、安全性高,但XML編碼格式占用帶寬大
-
其他基于TCP/IP自定義的協議:有些特殊框架(如:redis、kafka、zeroMq等)根據自身需要未嚴格遵循MQ規范,而是基于TCP\IP自行封裝了一套協議,通過網路socket介面進行傳輸,實作了MQ的功能,
MQ的通訊模式
- 點對點通訊:點對點方式是最為傳統和常見的通訊方式,它支持一對一、一對多、多對多、多對一等多種配置方式,支持樹狀、網狀等多種拓撲結構,
- 多點廣播:MQ適用于不同型別的應用,其中重要的,也是正在發展中的是"多點廣播"應用,即能夠將訊息發送到多個目標站點(Destination List),可以使用一條MQ指令將單一訊息發送到多個目標站點,并確保為每一站點可靠地提供資訊,MQ不僅提供了多點廣播的功能,而且還擁有智能訊息分發功能,在將一條訊息發送到同一系統上的多個用戶時,MQ將訊息的一個復制版本和該系統上接收者的名單發送到目標MQ系統,目標MQ系統在本地復制這些訊息,并將它們發送到名單上的佇列,從而盡可能減少網路的傳輸量,
- 發布/訂閱(Publish/Subscribe)模式:發布/訂閱功能使訊息的分發可以突破目的佇列地理指向的限制,使訊息按照特定的主題甚至內容進行分發,用戶或應用程式可以根據主題或內容接收到所需要的訊息,發布/訂閱功能使得發送者和接收者之間的耦合關系變得更為松散,發送者不必關心接收者的目的地址,而接收者也不必關心訊息的發送地址,而只是根據訊息的主題進行訊息的收發,在MQ家族產品中,MQ Event Broker是專門用于使用發布/訂閱技術進行資料通訊的產品,它支持基于佇列和直接基于TCP/IP兩種方式的發布和訂閱,
- 集群(Cluster):為了簡化點對點通訊模式中的系統配置,MQ提供 Cluster 的解決方案,集群類似于一個 域(Domain) ,集群內部的佇列管理器之間通訊時,不需要兩兩之間建立訊息通道,而是采用 Cluster 通道與其它成員通訊,從而大大簡化了系統配置,此外,集群中的佇列管理器之間能夠自動進行負載均衡,當某一佇列管理器出現故障時,其它佇列管理器可以接管它的作業,從而大大提高系統的高可靠性
如何保證訊息的順序性?
RabbitMQ
拆分多個 Queue,每個 Queue一個 Consumer;或者就一個 Queue 但是對應一個 Consumer,然后這個 Consumer 內部用記憶體佇列做排隊,然后分發給底層不同的 Worker 來處理,
Kafka
-
一個 Topic,一個 Partition,一個 Consumer,內部單執行緒消費,單執行緒吞吐量太低,一般不會用這個,
-
寫 N 個記憶體 Queue,具有相同 key 的資料都到同一個記憶體 Queue;然后對于 N 個執行緒,每個執行緒分別消費一個記憶體 Queue 即可,這樣就能保證順序性,
如何避免訊息重復消費?
在訊息生產時,MQ內部針對每條生產者發送的訊息生成一個唯一id,作為去重和冪等的依據(訊息投遞失敗并重傳),避免重復的訊息進入佇列,
在訊息消費時,要求訊息體中也要有一全域唯一id作為去重和冪等的依據,避免同一條訊息被重復消費,
大量訊息在 MQ 里長時間積壓,該如何解決?
一般這個時候,只能臨時緊急擴容了,具體操作步驟和思路如下:
- 先修復 consumer 的問題,確保其恢復消費速度,然后將現有 consumer 都停掉;
- 新建一個 topic,partition 是原來的 10 倍,臨時建立好原先 10 倍的 queue 數量;
- 然后寫一個臨時的分發資料的 consumer 程式,這個程式部署上去消費積壓的資料,消費之后不做耗時的處理,直接均勻輪詢寫入臨時建立好的 10 倍數量的 queue;
- 接著臨時用 10 倍的機器來部署 consumer,每一批 consumer 消費一個臨時 queue 的資料,這種做法相當于是臨時將 queue 資源和 consumer 資源擴大 10 倍,以正常的 10 倍速度來消費資料;
- 等快速消費完積壓資料之后,得恢復原先部署的架構,重新用原先的 consumer 機器來消費訊息,
MQ 中的訊息過期失效了怎么辦?
如果使用的是RabbitMQ的話,RabbtiMQ 是可以設定過期時間的(TTL),如果訊息在 Queue 中積壓超過一定的時間就會被 RabbitMQ 給清理掉,這個資料就沒了,這時的問題就不是資料會大量積壓在 MQ 里,而是大量的資料會直接搞丟,這個情況下,就不是說要增加 Consumer 消費積壓的訊息,因為實際上沒啥積壓,而是丟了大量的訊息,
我們可以采取一個方案,就是批量重導,就是大量積壓的時候,直接將資料寫到資料庫,然后等過了高峰期以后將這批資料一點一點的查出來,然后重新灌入 MQ 里面去,把丟的資料給補回來,
訊息中間件如何做到高可用?
以Kafka為例,
Kafka 的基礎集群架構,由多個broker組成,每個broker都是一個節點,當你創建一個topic時,它可以劃分為多個partition,而每個partition放一部分資料,分別存在于不同的 broker 上,也就是說,一個 topic 的資料,是分散放在多個機器上的,每個機器就放一部分資料,
每個partition放一部分資料,如果對應的broker掛了,那這部分資料是不是就丟失了?那不是保證不了高可用嗎?
Kafka 0.8 之后,提供了復制多副本機制來保證高可用,即每個 partition 的資料都會同步到其它機器上,形成多個副本,然后所有的副本會選舉一個 leader 出來,讓leader去跟生產和消費者打交道,其他副本都是follower,寫資料時,leader 負責把資料同步給所有的follower,讀訊息時,直接讀 leader 上的資料即可,如何保證高可用的?就是假設某個 broker 宕機,這個broker上的partition 在其他機器上都有副本的,如果掛的是leader的broker呢?其他follower會重新選一個leader出來,
如何保證資料一致性,事務訊息如何實作?
一條普通的MQ訊息,從產生到被消費,大概流程如下:
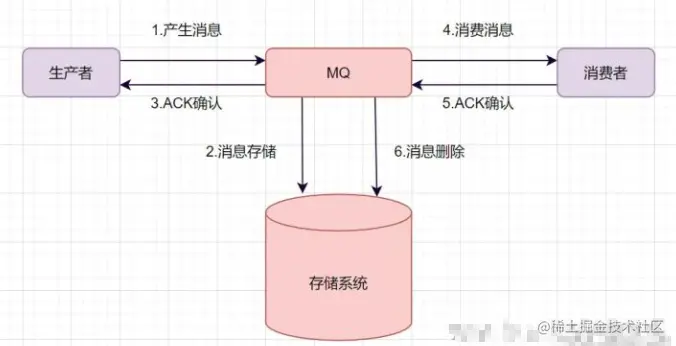
- 生產者產生訊息,發送帶MQ服務器
- MQ收到訊息后,將訊息持久化到存盤系統,
- MQ服務器回傳ACk到生產者,
- MQ服務器把訊息push給消費者
- 消費者消費完訊息,回應ACK
- MQ服務器收到ACK,認為訊息消費成功,即在存盤中洗掉訊息,
舉個下訂單的例子吧,訂單系統創建完訂單后,再發送訊息給下游系統,如果訂單創建成功,然后訊息沒有成功發送出去,下游系統就無法感知這個事情,出導致資料不一致,
如何保證資料一致性呢?可以使用事務訊息,一起來看下事務訊息是如何實作的吧,
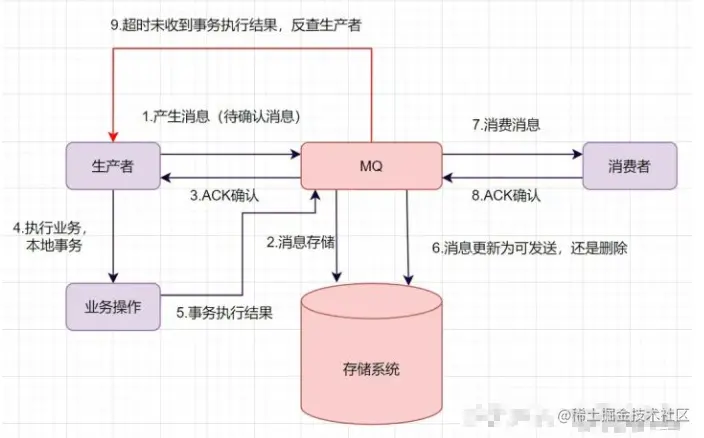
- 生產者產生訊息,發送一條半事務訊息到MQ服務器
- MQ收到訊息后,將訊息持久化到存盤系統,這條訊息的狀態是待發送狀態,
- MQ服務器回傳ACK確認到生產者,此時MQ不會觸發訊息推送事件
- 生產者執行本地事務
- 如果本地事務執行成功,即commit執行結果到MQ服務器;如果執行失敗,發送rollback,
- 如果是正常的commit,MQ服務器更新訊息狀態為可發送;如果是rollback,即洗掉訊息,
- 如果訊息狀態更新為可發送,則MQ服務器會push訊息給消費者,消費者消費完就回ACK,
- 如果MQ服務器長時間沒有收到生產者的commit或者rollback,它會反查生產者,然后根據查詢到的結果執行最終狀態,
如何設計一個訊息佇列?
首先是訊息佇列的整體流程,producer發送訊息給broker,broker存盤好,broker再發送給consumer消費,consumer回復消費確認等,
producer發送訊息給broker,broker發訊息給consumer消費,那就需要兩次RPC了,RPC如何設計呢?可以參考開源框架Dubbo,你可以說說服務發現、序列化協議等等
broker考慮如何持久化呢,是放檔案系統還是資料庫呢,會不會訊息堆積呢,訊息堆積如何處理呢,
消費關系如何保存呢? 點對點還是廣播方式呢?廣播關系又是如何維護呢?zk還是config server
訊息可靠性如何保證呢?如果訊息重復了,如何冪等處理呢?
訊息佇列的高可用如何設計呢? 可以參考Kafka的高可用保障機制,多副本 -> leader & follower -> broker 掛了重新選舉 leader 即可對外服務,
訊息事務特性,與本地業務同個事務,本地訊息落庫;訊息投遞到服務端,本地才洗掉;定時任務掃描本地訊息庫,補償發送,
MQ得伸縮性和可擴展性,如果訊息積壓或者資源不夠時,如何支持快速擴容,提高吞吐?可以參照一下 Kafka 的設計理念,broker -> topic -> partition,每個 partition 放一個機器,就存一部分資料,如果現在資源不夠了,簡單啊,給 topic 增加 partition,然后做資料遷移,增加機器,不就可以存放更多資料,提供更高的吞吐量了嗎,
參考鏈接
多執行緒異步和MQ的區別
- CPU消耗,多執行緒異步可能存在CPU競爭,而MQ不會消耗本機的CPU,
- MQ 方式實作異步是完全解耦的,適合于大型互聯網專案,
- 削峰或者訊息堆積能力,當業務系統處于高并發,MQ可以將訊息堆積在Broker實體中,而多執行緒會創建大量執行緒,甚至觸發拒絕策略,
- 使用MQ引入了中間件,增加了專案復雜度和運維難度,
總的來說,規模比較小的專案可以使用多執行緒實作異步,大專案建議使用MQ實作異步,
最后給大家分享一個Github倉庫,上面有大彬整理的300多本經典的計算機書籍PDF,包括C語言、C++、Java、Python、前端、資料庫、作業系統、計算機網路、資料結構和演算法、機器學習、編程人生等,可以star一下,下次找書直接在上面搜索,倉庫持續更新中~
Github地址:https://github.com/Tyson0314/java-books
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/546156.html
標籤:Java
上一篇:中國沒有ChatGPT