資源調度器是 YARN 中最核心的組件之一,它是 ResourceManager 中的一個插拔式服務組件,負責整個集群資源的管理和分配,
Yarn 默認提供了三種可用資源調度器,分別是FIFO (First In First Out )、 Yahoo! 的 Capacity Scheduler 和 Facebook 的 Fair Scheduler,
本節會重點介紹資源調度器的基本框架,在之后文章中詳細介紹 Capacity Scheduler 和 Fair Scheduler,
一、基本架構
資源調度器是最核心的組件之一,并且在 Yarn 中是可插拔的,Yarn 中定義了一套介面規范,以方便用戶實作自己的調度器,同時 Yarn 中自帶了FIFO,CapacitySheduler, FairScheduler三種常用資源調度器,
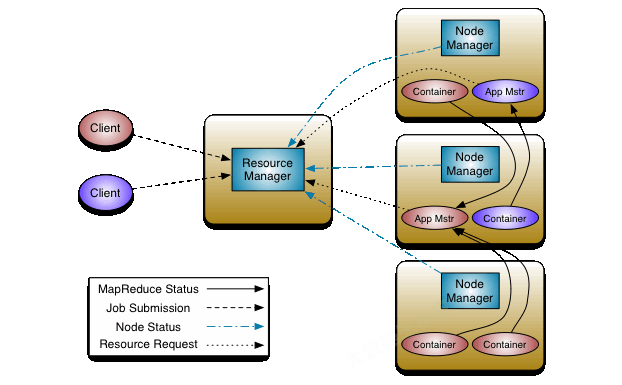
一)資源調度模型
Yarn 采用了雙層資源調度模型,
- 第一層中,RM 中的資源調度器將資源分配給各個 AM(Scheduler 處理的部分)
- 第二層中,AM 再進一步將資源分配給它的內部任務(不是本節關注的內容)
Yarn 的資源分配程序是異步的,資源調度器將資源分配給一個應用程式后,它不會立刻 push 給對應的 AM,而是暫時放到一個緩沖區中,等待 AM 通過周期性的心跳主動來取(pull-based通信模型)
- NM 通過周期心跳匯報節點資訊
- RM 為 NM 回傳一個心跳應答,包括需要釋放的 container 串列等資訊
- RM 收到的 NM 資訊觸發一個NODE_UPDATED事件,之后會按照一定策略將該節點上的資源分配到各個應用,并將分配結果放到一個記憶體資料結構中
- AM 向 RM 發送心跳,獲得最新分配的 container 資源
- AM 將收到的新 container 分配給內部任務
二)資源表示模型
NM 啟動時會向 RM 注冊,注冊資訊中包含該節點可分配的 CPU 和記憶體總量,這兩個值均可通過配置選項設定,具體如下:
yarn.nodemanager.resource.memory-mb:可分配的物理記憶體總量,默認是8Gyarn.nodemanager.vmem-pmem-ratio:任務使用單位物理記憶體量對應最多可使用的虛擬記憶體,默認值是2.1,表示使用1M的物理記憶體,最多可以使用2.1MB的虛擬記憶體總量yarn.nodemanager.resource.cpu-vcores:可分配的虛擬CPU個數,默認是8,為了更細粒度地劃分CPU資源和考慮到CPU性能差異,YARN允許管理員根據實際需要和CPU性能將每個物理CPU劃分成若干個虛擬CPU,而管理員可為每個節點單獨配置可用的虛擬CPU個數,且用戶提交應用程式時,也可指定每個任務需要的虛擬CPU數
Yarn 支持的調度語意:
- 請求某個節點上的特定資源量
- 請求某個特定機架上的特定資源量
- 將某些節點加入(或移除)黑名單,不再為自己分配這些節點上的資源
- 請求歸還某些資源
Yarn 不支持的調度語意(隨著 Yarn 的不斷迭代,可能會在未來實作):
- 請求任意節點上的特定資源量
- 請求任意機架上的特定資源量
- 請求一組或幾組符合某種特質的資源
- 超細粒度資源,比如CPU性能要求、系結CPU等
- 動態調整Container資源,允許根據需要動態調整Container資源量
三)資源保證機制
當單個節點的閑置資源無法滿足應用的一個 container 時,有兩種策略:
- 放棄當前節點等待下一個節點;
- 在當前節點上預留一個 container 申請,等到節點有資源時優先滿足預留,
YARN 采用了第二種增量資源分配機制(當應用程式申請的資源暫時無法保證時,為應用程式預留一個節點上的資源直到累計釋放的空閑資源滿足應用程式需求),這種機制會造成浪費,但不會出現餓死現象
四)層級佇列管理
Yarn 的佇列是層級關系,每個佇列可以包含子佇列,用戶只能將任務提交到葉子佇列,管理員可以配置每個葉子佇列對應的作業系統用戶和用戶組,也可以配置每個佇列的管理員,管理員可以殺死佇列中的任何應用程式,改變任何應用的優先級等,
佇列的命名用 . 來連接,比如 root.A1、root.A1.B1,
二、三種調度器
Yarn 的資源調度器是可以配置的,默認實作有三種 FIFO、CapacityScheduler、FairScheduler,
一)FIFO
FIFO 是 Hadoop設計之初提供的一個最簡單的調度機制:先來先服務,
所有任務被統一提交到一個隊里中,Hadoop按照提交順序依次運行這些作業,只有等先來的應用程式資源滿足后,再開始為下一個應用程式進行調度運行和分配資源,
優點:
- 原理是和實作簡單,也不需要任何單獨的配置
缺點:
- 無法提供 QoS,只能對所有的任務按照同一優先級處理,
- 無法適應多租戶資源管理,先來的大應用程式把集群資源占滿,導致其他用戶的程式無法得到及時執行,
- 應用程式并發運行程度低,
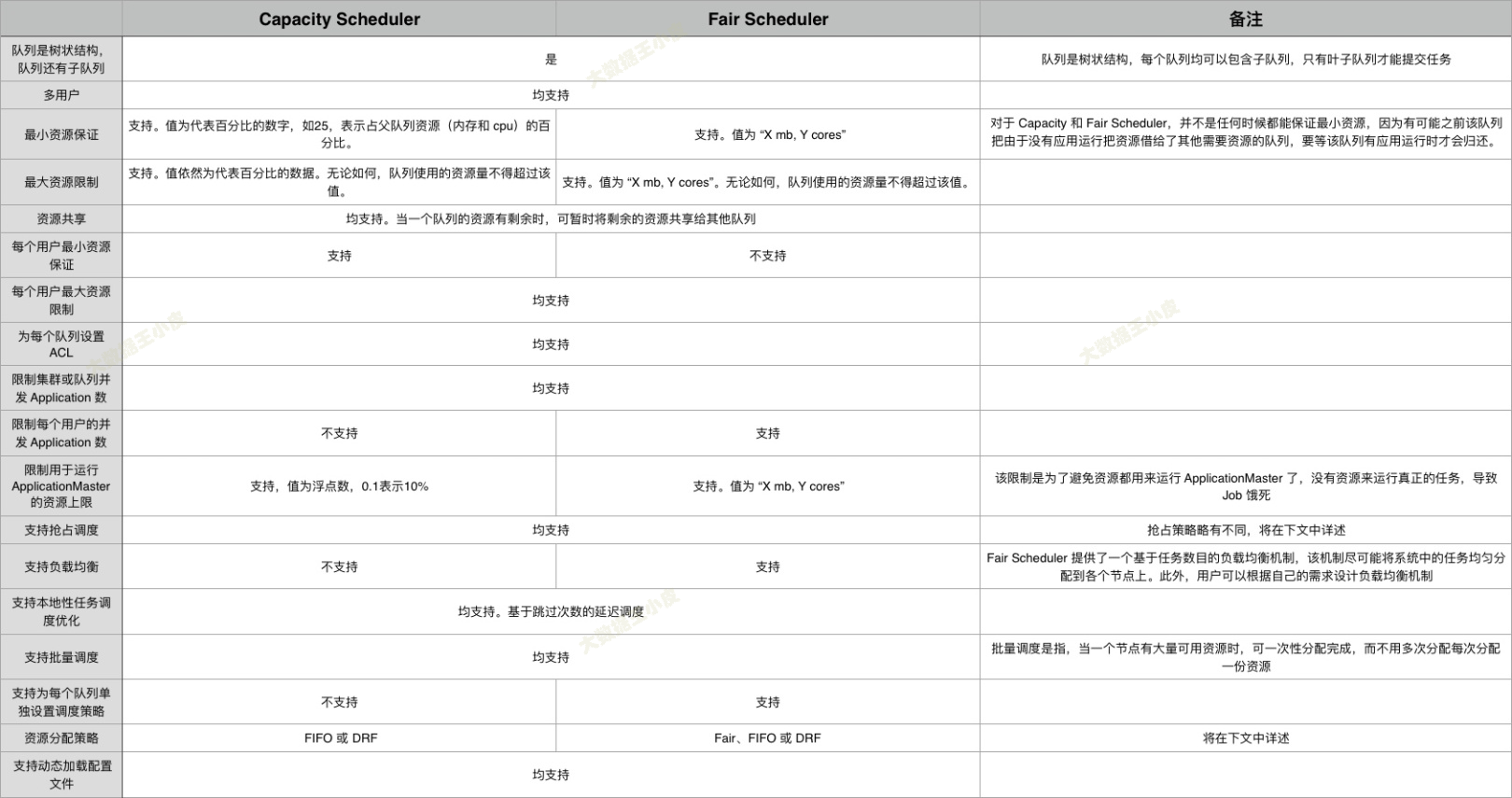
二)Capacity Scheduler
Capacity Scheduler 容量調度是 Yahoo! 開發的多用戶調度器,以佇列為單位劃分資源,
每個佇列可設定一定比例的資源最低保證和使用上限,每個用戶也可設定一定的資源使用上限,以防資源濫用,并支持資源共享,將佇列剩余資源共享給其他佇列使用,組態檔名稱為 capacity-scheduler.xml,
主要特點:
- 容量保證:可為每個佇列設定資源最低保證(capacity)和資源使用上限(maximum-capacity,默認100%),而所有提交到該佇列的應用程式可以共享這個佇列中的資源,
- 彈性調度:如果佇列中的資源有剩余或者空閑,可以暫時共享給那些需要資源的佇列,一旦該佇列有新的應用程式需要資源運行,則其他佇列釋放的資源會歸還給該佇列,從而實作彈性靈活分配調度資源,提高系統資源利用率,
- 多租戶管理:支持多用戶共享集群資源和多應用程式同時運行,且可對每個用戶可使用資源量(user-limit-factor)設定上限,
- 安全隔離:每個佇列設定嚴格的ACL串列(acl_submit_applications),用以限制可以用戶或者用戶組可以在該佇列提交應用程式,
三)Fair Scheduler
Fair Scheduler 是 Facebook 開發的多用戶調度器,設計目標是為所有的應用分配「公平」的資源(對公平的定義可以通過引數來設定),公平不僅可以在佇列中的應用體現,也可以在多個佇列之間作業,
在 Fair 調度器中,我們不需要預先占用一定的系統資源,Fair 調度器會為所有運行的 job 動態的調整系統資源,如下圖所示,當第一個大 job 提交時,只有這一個 job 在運行,此時它獲得了所有集群資源;當第二個小任務提交后,Fair 調度器會分配一半資源給這個小任務,讓這兩個任務公平的共享集群資源,
與Capacity Scheduler不同之處:
四)原始碼繼承關系
看下面三個圖中調度器的繼承關系,這三個 Scheduler 都繼承自 AbstractYarnScheduler,這個抽象類又 extends AbstractService implements ResourceScheduler,繼承 AbstractService 說明是一個服務,實作 ResourceScheduler 是 scheduler 的主要功能,
三者還有一些區別,FairScheduler 沒實作 Configurable 介面,少了 setConf() 方法;FifoScheduler 不支持資源搶占,FairScheduler 支持資源搶占卻沒實作 PreemptableResourceScheduler 介面,
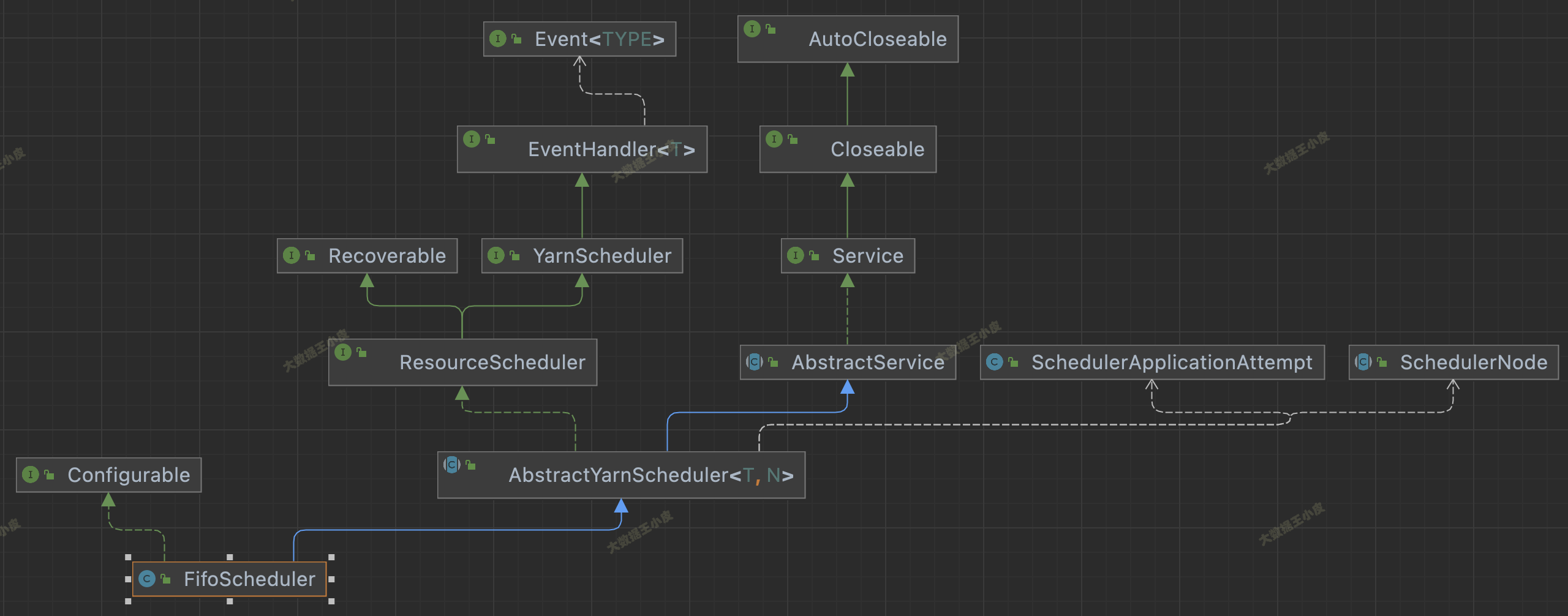
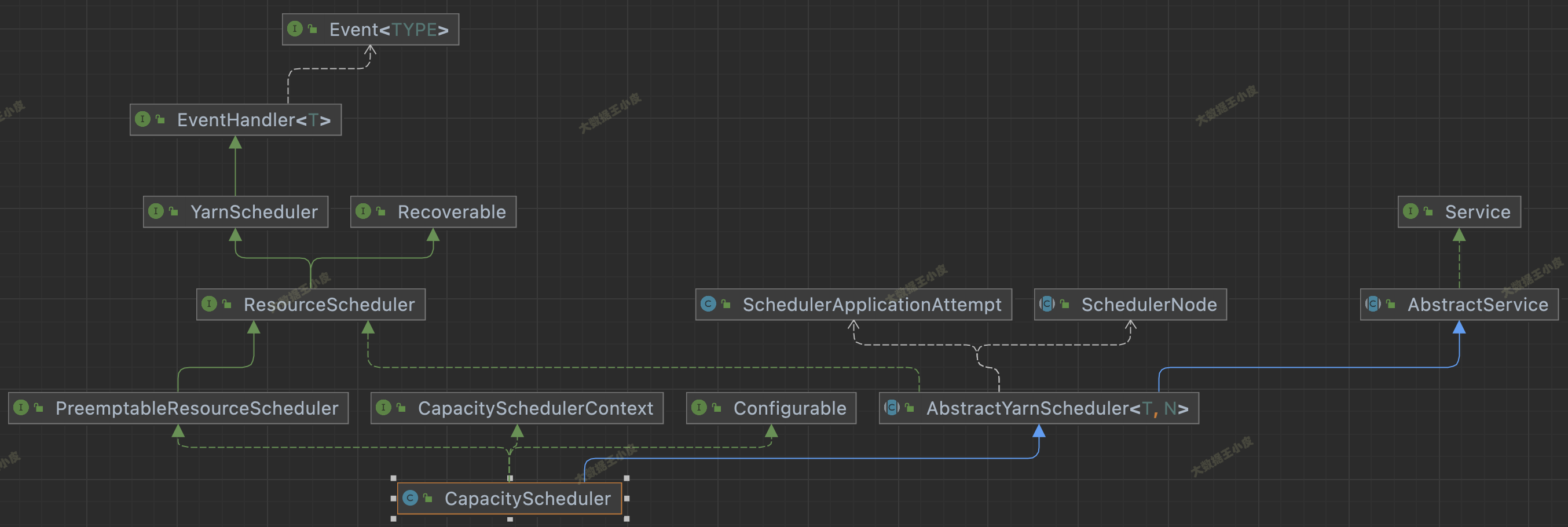
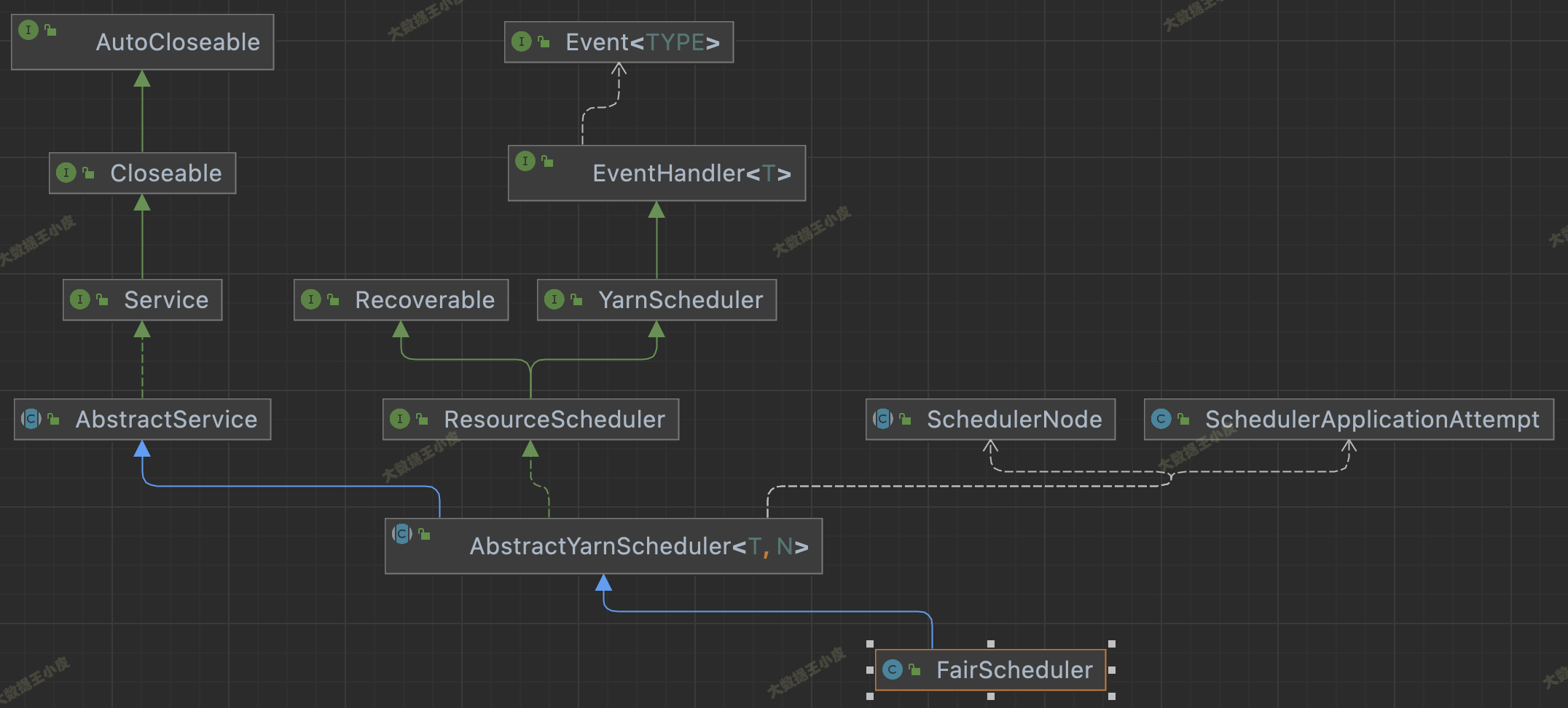
在 YarnScheduler 中,定義了一個資源調度器應該實作的方法,在 AbstractYarnScheduler 中實作了大部分方法,若自己實作調度器可繼承該類,將發開重點放在資源分配實作上,
public interface YarnScheduler extends EventHandler<SchedulerEvent> {
// 獲得一個佇列的基本資訊
public QueueInfo getQueueInfo(String queueName, boolean includeChildQueues,
boolean recursive) throws IOException;
// 獲取集群資源
public Resource getClusterResource();
/**
* AM 和資源調度器之間最主要的一個方法
* AM 通過該方法更新資源請求、待釋放資源串列、黑名單串列增減
*/
@Public
@Stable
Allocation allocate(ApplicationAttemptId appAttemptId,
List<ResourceRequest> ask, List<ContainerId> release,
List<String> blacklistAdditions, List<String> blacklistRemovals,
List<UpdateContainerRequest> increaseRequests,
List<UpdateContainerRequest> decreaseRequests);
// 獲取節點資源使用情況報告
public SchedulerNodeReport getNodeReport(NodeId nodeId);
ResourceScheduler 本質是個事件處理器,主要處理10種事件(CapacityScheduler 還會多處理幾種搶占相關的事件),可以到對應 Scheduler 的 handle() 方法中查看這些事件處理邏輯:
NODE_ADDED: 集群中增加一個節點NODE_REMOVED: 集群中移除一個節點NODE_RESOURCE_UPDATE: 集群中有一個節點的資源增加了NODE_LABELS_UPDATE: 更新node labelsNODE_UPDATE: 該事件是 NM 通過心跳和 RM 通信時發送的,會匯報該 node 的資源使用情況,同時觸發一次分配操作,APP_ADDED: 增加一個ApplicationAPP_REMOVED: 移除一個applicationAPP_ATTEMPT_ADDED: 增加一個application AttemptAPP_ATTEMPT_REMOVED: 移除一個application attemptCONTAINER_EXPIRED: 回收一個超時的container
三、資源調度維度
目前有兩種:DefaultResourceCalculator 和 DominantResourceCalculator,
DefaultResourceCalculator: 僅考慮記憶體資源DominantResourceCalculator: 同時考慮記憶體和 CPU 資源(后續更新中支持更多型別資源,FPGA、GPU 等),該演算法擴展了最大最小公平演算法(max-min fairness),- 在 DRF 演算法中,將所需份額(資源比例)最大的資源稱為主資源,而 DRF 的基本設計思想則是將最大最小公平演算法應用于主資源上,進而將多維資源調度問題轉化為單資源調度問題,即 DRF 總是最大化所有主資源中最小的
- 感興趣的話,可到原始碼中
DominantResourceCalculator#compare探究實作邏輯 - 對應的論文 《Dominant Resource Fairness: Fair Allocation of Multiple Resource Types》
(這里注意!很多文章和書中寫的是「YARN 資源調度器默認采用了 DominantResourceCalculator」,實際并不是這樣的!)
FifoScheduler默認使用DefaultResourceCalculator且不可更改,CapacityScheduler是在capacity-scheduler.xml中配置yarn.scheduler.capacity.resource-calculator引數決定的,FairScheduler才默認使用DominantResourceCalculator,
四、資源搶占模型
這里僅簡要介紹資源搶占模型,在后面的文章中會深入原始碼分析搶占的流程,
- 在資源調度器中,每個佇列可設定一個最小資源量和最大資源量,其中,最小資源量是資源緊缺情況下每個佇列需保證的資源量,而最大資源量則是極端情況下佇列也不能超過的資源使用量
- 為了提高資源利用率,資源調度器(包括Capacity Scheduler和Fair Scheduler)會將負載較輕的佇列的資源暫時分配給負載重的佇列,僅當負載較輕佇列突然收到新提交的應用程式時,調度器才進一步將本屬于該佇列的資源分配給它,
五、總結
本文介紹了 Yarn 資源調度器的基本框架,包括基本架構,以及簡要介紹三種 YARN 實作的調度器,并對資源調度維度,資源搶占模型等進行了介紹,
后續文章中將會圍繞三種 YARN 調度器,深入原始碼進行探究,看其在原始碼中是如何一步步實作對應功能的,
參考文章:
《Hadoop 技術內幕:深入決議 YARN 架構設計與實作原理》第六章
深入決議yarn架構設計與技術實作-資源調度器
Yarn原始碼分析5-資源調度
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/547614.html
標籤:Java
上一篇:二刷整合
下一篇:Maven 中<optional>true</optional>和<scope>provided</scope>之間的區別