作者:愿許浪盡天涯
鏈接:https://juejin.cn/post/7077744714954309669
前言
我們公司有個專案的資料量高達五千萬,但是因為報表那塊資料不太準確,業務庫和報表庫又是跨庫操作,所以并不能使用 SQL 來進行同步,當時的打算是通過 mysqldump 或者存盤的方式來進行同步,但是嘗試后發現這些方案都不切實際:
mysqldump:不僅備份需要時間,同步也需要時間,而且在備份的程序,可能還會有資料產出(也就是說同步等于沒同步)
存盤方式:這個效率太慢了,要是資料量少還好,我們使用這個方式的時候,三個小時才同步兩千條資料 ...
后面在網上查看后:
- 發現 DataX 這個工具用來同步不僅速度快,而且同步的資料量基本上也相差無幾,
一、DataX 簡介
DataX 是阿里云 DataWorks 資料集成 的開源版本,主要就是用于實作資料間的離線同步, DataX 致力于實作包括關系型資料庫(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等 各種異構資料源(即不同的資料庫) 間穩定高效的資料同步功能,
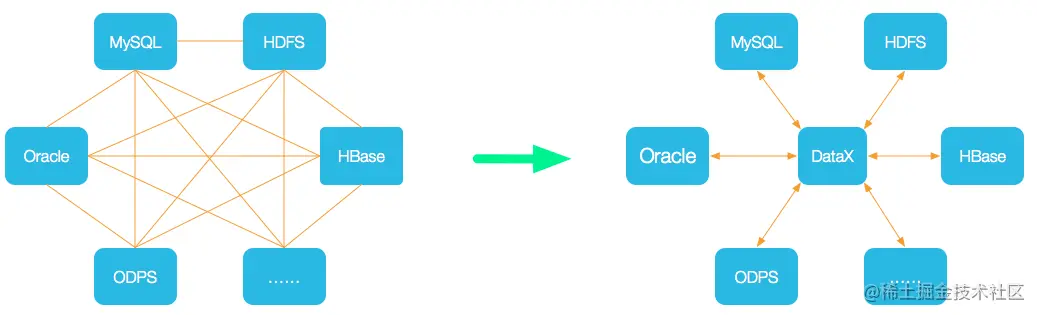
為了 解決異構資料源同步問題,DataX 將復雜的網狀同步鏈路變成了星型資料鏈路,DataX 作為中間傳輸載體負責連接各種資料源;當需要接入一個新的資料源時,只需要將此資料源對接到 DataX,便能跟已有的資料源作為無縫資料同步,
1.DataX3.0 框架設計
DataX 采用 Framework + Plugin 架構,將資料源讀取和寫入抽象稱為 Reader/Writer 插件,納入到整個同步框架中,

| 角色 | 作用 |
|---|---|
| Reader(采集模塊) | 負責采集資料源的資料,將資料發送給 Framework, |
| Writer(寫入模塊) | 負責不斷向 Framework 中取資料,并將資料寫入到目的端, |
| Framework(中間商) | 負責連接 Reader 和 Writer,作為兩者的資料傳輸通道,并處理緩沖,流控,并發,資料轉換等核心技術問題, |
2.DataX3.0 核心架構
DataX 完成單個資料同步的作業,我們稱為 Job,DataX 接收到一個 Job 后,將啟動一個行程來完成整個作業同步程序,DataX Job 模塊是單個作業的中樞管理節點,承擔了資料清理、子任務切分、TaskGroup 管理等功能,
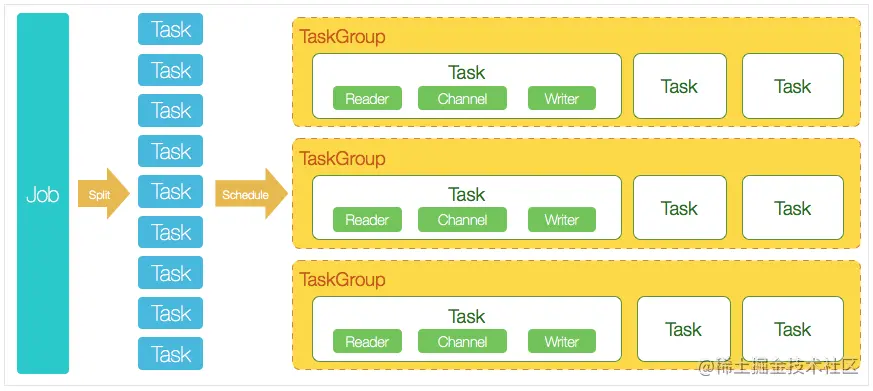
DataX Job 啟動后,會根據不同源端的切分策略,將 Job 切分成多個小的 Task (子任務),以便于并發執行,接著 DataX Job 會呼叫 Scheduler 模塊,根據配置的并發數量,將拆分成的 Task 重新組合,組裝成 TaskGroup(任務組)
每一個 Task 都由 TaskGroup 負責啟動,Task 啟動后,會固定啟動 Reader --> Channel --> Writer 執行緒來完成任務同步作業,DataX 作業運行啟動后,Job 會對 TaskGroup 進行監控操作,等待所有 TaskGroup 完成后,Job 便會成功退出(例外退出時 值非 0)
DataX 調度程序:
首先 DataX Job 模塊會根據分庫分表切分成若干個 Task,然后根據用戶配置并發數,來計算需要分配多少個 TaskGroup(計算程序:Task / Channel = TaskGroup)最后由 TaskGroup 根據分配好的并發數來運行 Task(任務)
二、使用 DataX 實作資料同步
準備作業:
- JDK(1.8 以上,推薦 1.8)
- Python(2,3 版本都可以)
- Apache Maven 3.x(Compile DataX)(手動打包使用,使用
tar包方式不需要安裝)
| 主機名 | 作業系統 | IP 地址 | 軟體包 |
|---|---|---|---|
| MySQL-1 | CentOS 7.4 | 192.168.1.1 | jdk-8u181-linux-x64.tar.gz datax.tar.gz |
| MySQL-2 | CentOS 7.4 | 192.168.1.2 |
安裝 JDK:
[root@MySQL-1 ~]# ls
anaconda-ks.cfg jdk-8u181-linux-x64.tar.gz
[root@MySQL-1 ~]# tar zxf jdk-8u181-linux-x64.tar.gz
[root@DataX ~]# ls
anaconda-ks.cfg jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz
[root@MySQL-1 ~]# mv jdk1.8.0_181 /usr/local/java
[root@MySQL-1 ~]# cat <<END >> /etc/profile
export JAVA_HOME=/usr/local/java
export PATH=$PATH:"$JAVA_HOME/bin"
END
[root@MySQL-1 ~]# source /etc/profile
[root@MySQL-1 ~]# java -version
因為 CentOS 7 上自帶 Python 2.7 的軟體包,所以不需要進行安裝,
1.Linux 上安裝 DataX 軟體
[root@MySQL-1 ~]# wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
[root@MySQL-1 ~]# tar zxf datax.tar.gz -C /usr/local/
[root@MySQL-1 ~]# rm -rf /usr/local/datax/plugin/*/._* # 需要洗掉隱藏檔案 (重要)
當未洗掉時,可能會輸出:[/usr/local/datax/plugin/reader/._drdsreader/plugin.json] 不存在. 請檢查您的組態檔.
驗證:
[root@MySQL-1 ~]# cd /usr/local/datax/bin
[root@MySQL-1 ~]# python datax.py ../job/job.json # 用來驗證是否安裝成功
輸出:
2021-12-13 19:26:28.828 [job-0] INFO JobContainer - PerfTrace not enable!
2021-12-13 19:26:28.829 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.060s | All Task WaitReaderTime 0.068s | Percentage 100.00%
2021-12-13 19:26:28.829 [job-0] INFO JobContainer -
任務啟動時刻 : 2021-12-13 19:26:18
任務結束時刻 : 2021-12-13 19:26:28
任務總計耗時 : 10s
任務平均流量 : 253.91KB/s
記錄寫入速度 : 10000rec/s
讀出記錄總數 : 100000
讀寫失敗總數 : 0
推薦一個開源免費的 Spring Boot 最全教程:
https://github.com/javastacks/spring-boot-best-practice
2.DataX 基本使用
查看 streamreader --> streamwriter 的模板:
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py -r streamreader -w streamwriter
輸出:
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Please refer to the streamreader document:
https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md
Please refer to the streamwriter document:
https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
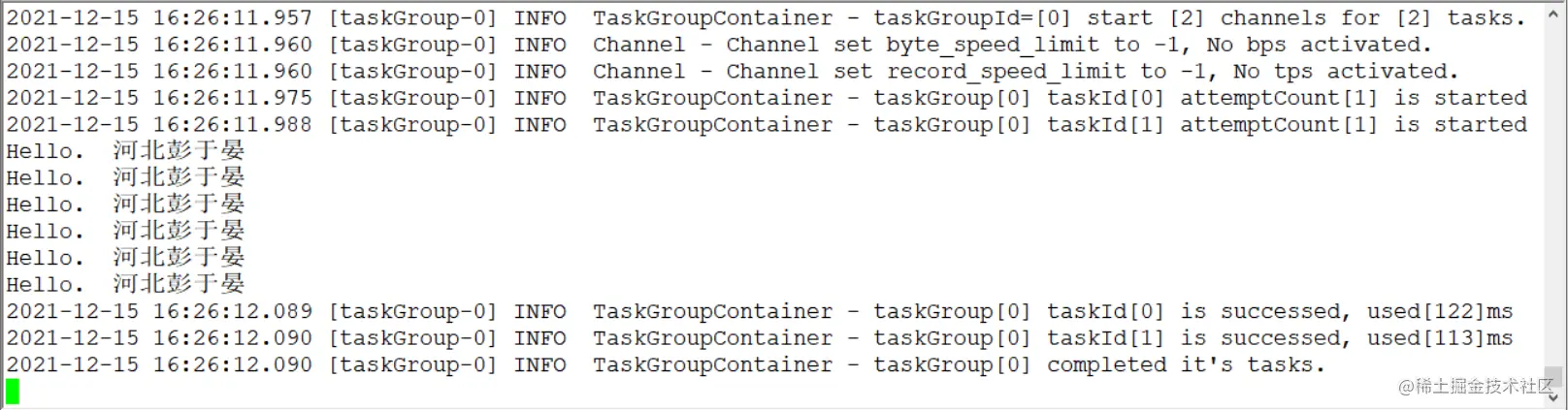
根據模板撰寫 json 檔案
[root@MySQL-1 ~]# cat <<END > test.json
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [ # 同步的列名 (* 表示所有)
{
"type":"string",
"value":"Hello."
},
{
"type":"string",
"value":"河北彭于晏"
},
],
"sliceRecordCount": "3" # 列印數量
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "utf-8", # 編碼
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "2" # 并發 (即 sliceRecordCount * channel = 結果)
}
}
}
}
輸出:(要是復制我上面的話,需要把 # 帶的內容去掉)
3.安裝 MySQL 資料庫
分別在兩臺主機上安裝:
[root@MySQL-1 ~]# yum -y install mariadb mariadb-server mariadb-libs mariadb-devel
[root@MySQL-1 ~]# systemctl start mariadb # 安裝 MariaDB 資料庫
[root@MySQL-1 ~]# mysql_secure_install # 初始化
NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDB
SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY!
Enter current password for root (enter for none): # 直接回車
OK, successfully used password, moving on...
Set root password? [Y/n] y # 配置 root 密碼
New password: 123123
Re-enter new password: 123123
Password updated successfully!
Reloading privilege tables..
... Success!
Remove anonymous users? [Y/n] y # 移除匿名用戶
... skipping.
Disallow root login remotely? [Y/n] n # 允許 root 遠程登錄
... skipping.
Remove test database and access to it? [Y/n] y # 移除測驗資料庫
... skipping.
Reload privilege tables now? [Y/n] y # 重新加載表
... Success!
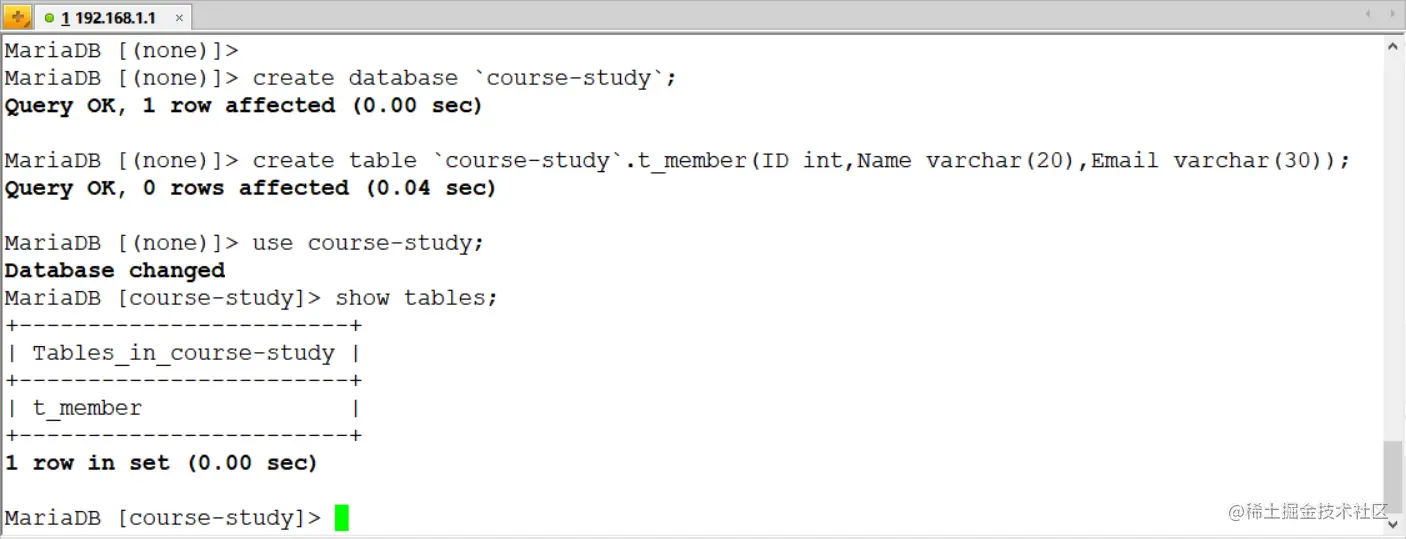
1)準備同步資料(要同步的兩臺主機都要有這個表)
MariaDB [(none)]> create database `course-study`;
Query OK, 1 row affected (0.00 sec)
MariaDB [(none)]> create table `course-study`.t_member(ID int,Name varchar(20),Email varchar(30));
Query OK, 0 rows affected (0.00 sec)
因為是使用 DataX 程式進行同步的,所以需要在雙方的資料庫上開放權限:
grant all privileges on *.* to root@'%' identified by '123123';
flush privileges;
2)創建存盤程序:
DELIMITER $$
CREATE PROCEDURE test()
BEGIN
declare A int default 1;
while (A < 3000000)do
insert into `course-study`.t_member values(A,concat("LiSa",A),concat("LiSa",A,"@163.com"));
set A = A + 1;
END while;
END $$
DELIMITER ;
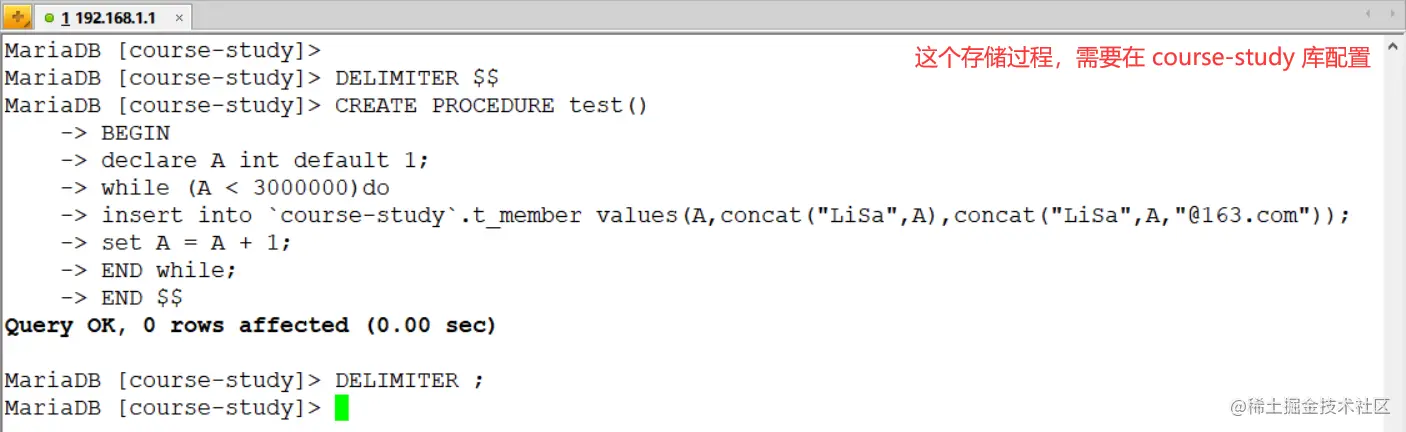
3)呼叫存盤程序(在資料源配置,驗證同步使用):
call test();
4.通過 DataX 實 MySQL 資料同步
1)生成 MySQL 到 MySQL 同步的模板:
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py -r mysqlreader -w mysqlwriter
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader", # 讀取端
"parameter": {
"column": [], # 需要同步的列 (* 表示所有的列)
"connection": [
{
"jdbcUrl": [], # 連接資訊
"table": [] # 連接表
}
],
"password": "", # 連接用戶
"username": "", # 連接密碼
"where": "" # 描述篩選條件
}
},
"writer": {
"name": "mysqlwriter", # 寫入端
"parameter": {
"column": [], # 需要同步的列
"connection": [
{
"jdbcUrl": "", # 連接資訊
"table": [] # 連接表
}
],
"password": "", # 連接密碼
"preSql": [], # 同步前. 要做的事
"session": [],
"username": "", # 連接用戶
"writeMode": "" # 操作型別
}
}
}
],
"setting": {
"speed": {
"channel": "" # 指定并發數
}
}
}
}
2)撰寫 json 檔案:
[root@MySQL-1 ~]# vim install.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123123",
"column": ["*"],
"splitPk": "ID",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"
],
"table": ["t_member"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8",
"table": ["t_member"]
}
],
"password": "123123",
"preSql": [
"truncate t_member"
],
"session": [
"set session sql_mode='ANSI'"
],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
3)驗證
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py install.json
輸出:
2021-12-15 16:45:15.120 [job-0] INFO JobContainer - PerfTrace not enable!
2021-12-15 16:45:15.120 [job-0] INFO StandAloneJobContainerCommunicator - Total 2999999 records, 107666651 bytes | Speed 2.57MB/s, 74999 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 82.173s | All Task WaitReaderTime 75.722s | Percentage 100.00%
2021-12-15 16:45:15.124 [job-0] INFO JobContainer -
任務啟動時刻 : 2021-12-15 16:44:32
任務結束時刻 : 2021-12-15 16:45:15
任務總計耗時 : 42s
任務平均流量 : 2.57MB/s
記錄寫入速度 : 74999rec/s
讀出記錄總數 : 2999999
讀寫失敗總數 : 0
你們可以在目的資料庫進行查看,是否同步完成,
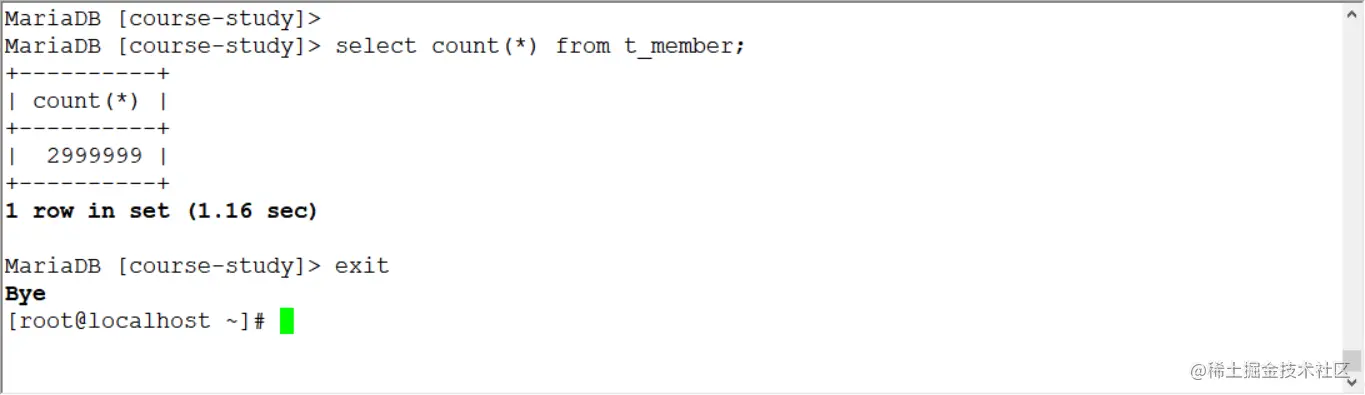
- 上面的方式相當于是完全同步,但是當資料量較大時,同步的時候被中斷,是件很痛苦的事情;
- 所以在有些情況下,增量同步還是蠻重要的,
5.使用 DataX 進行增量同步
使用 DataX 進行全量同步和增量同步的唯一區別就是:增量同步需要使用 where 進行條件篩選,
- 即,同步篩選后的 SQL,
1)撰寫 json 檔案:
[root@MySQL-1 ~]# vim where.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123123",
"column": ["*"],
"splitPk": "ID",
"where": "ID <= 1888",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"
],
"table": ["t_member"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8",
"table": ["t_member"]
}
],
"password": "123123",
"preSql": [
"truncate t_member"
],
"session": [
"set session sql_mode='ANSI'"
],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}
- 需要注意的部分就是:
where(條件篩選) 和preSql(同步前,要做的事) 引數,
2)驗證:
[root@MySQL-1 ~]# python /usr/local/data/bin/data.py where.json
輸出:
2021-12-16 17:34:38.534 [job-0] INFO JobContainer - PerfTrace not enable!
2021-12-16 17:34:38.534 [job-0] INFO StandAloneJobContainerCommunicator - Total 1888 records, 49543 bytes | Speed 1.61KB/s, 62 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.002s | All Task WaitReaderTime 100.570s | Percentage 100.00%
2021-12-16 17:34:38.537 [job-0] INFO JobContainer -
任務啟動時刻 : 2021-12-16 17:34:06
任務結束時刻 : 2021-12-16 17:34:38
任務總計耗時 : 32s
任務平均流量 : 1.61KB/s
記錄寫入速度 : 62rec/s
讀出記錄總數 : 1888
讀寫失敗總數 : 0
目標資料庫上查看:
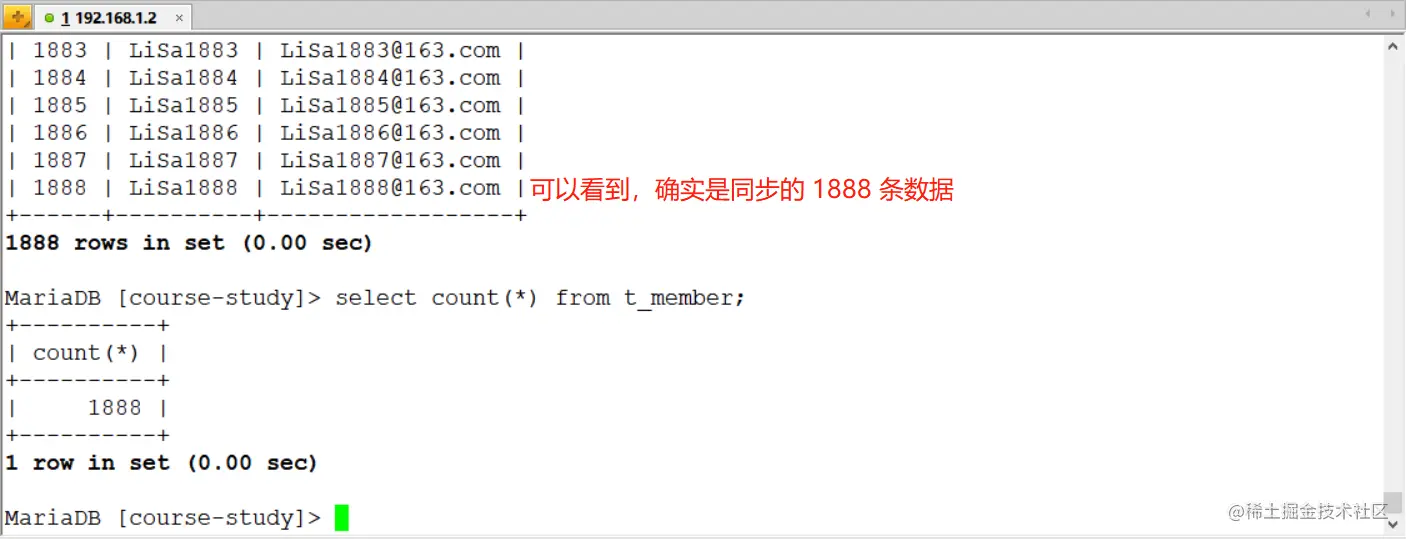
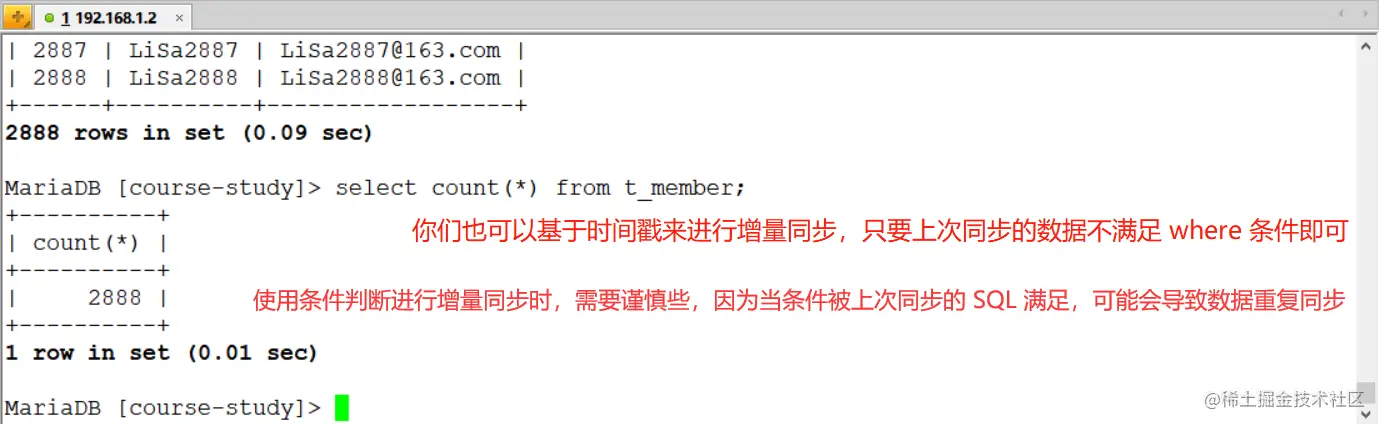
3)基于上面資料,再次進行增量同步:
- 主要是
where配置:"where": "ID > 1888 AND ID <= 2888"(通過條件篩選來進行增量同步) - 同時需要將我上面的
preSql洗掉 (因為我上面做的操作是 truncate 表)
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
2.勁爆!Java 協程要來了,,,
3.Spring Boot 2.x 教程,太全了!
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/547877.html
標籤:其他
下一篇:Python工具箱系列(二十九)