ElasticSearch 性能調優

-
作者: 博學谷狂野架構師
-
GitHub地址:GitHub地址 (有我們精心準備的130本電子書PDF)
概述
性能優化是個涉及面非常廣的問題,不同的環境,不同的業務場景可能會存在不同的優化方案,本文只對一些相關的知識點做簡單的總結,具體方案可以根據場景自行嘗試,
組態檔調優
通過
elasticsearch.yml組態檔調優
記憶體鎖定
允許 JVM 鎖住記憶體,禁止作業系統交換出去
由于JVM發生swap交換會導致極大降低ES的性能,為了防止ES發生記憶體交換,我們可以通過鎖定記憶體來實作,這將極大提高查詢性能,但同時可能造成OOM,需要對應做好資源監控,必要的時候進行干預,
修改ES配置
修改ES的組態檔elasticsearch.yml,設定bootstrap.memory_lock為true
COPY#集群名稱
cluster.name: elastic
#當前該節點的名稱
node.name: node-3
#是不是有資格競選主節點
node.master: true
#是否存盤資料
node.data: true
#最大集群節點數
node.max_local_storage_nodes: 3
#給當前節點自定義屬性(可以省略)
#node.attr.rack: r1
#資料存檔位置
path.data: /usr/share/elasticsearch/data
#日志存放位置
path.logs: /usr/share/elasticsearch/log
#是否開啟時鎖定記憶體(默認為是)
#bootstrap.memory_lock: true
#設定網關地址,我是被這個坑死了,這個地址我原先填寫了自己的實際物理IP地址,
#然后啟動一直報無效的IP地址,無法注入9300埠,這里只需要填寫0.0.0.0
network.host: 0.0.0.0
#設定映射埠
http.port: 9200
#內部節點之間溝通埠
transport.tcp.port: 9300
#集群發現默認值為127.0.0.1:9300,如果要在其他主機上形成包含節點的群集,如果搭建集群則需要填寫
#es7.x 之后新增的配置,寫入候選主節點的設備地址,在開啟服務后可以被選為主節點,也就是說把所有的節點都寫上
discovery.seed_hosts: ["node-1","node-2","node-3"]
#當你在搭建集群的時候,選出合格的節點集群,有些人說的太官方了,
#其實就是,讓你選擇比較好的幾個節點,在你節點啟動時,在這些節點中選一個做領導者,
#如果你不設定呢,elasticsearch就會自己選舉,這里我們把三個節點都寫上
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#在群集完全重新啟動后阻止初始恢復,直到啟動N個節點
#簡單點說在集群啟動后,至少復活多少個節點以上,那么這個服務才可以被使用,否則不可以被使用,
gateway.recover_after_nodes: 2
#洗掉索引是是否需要顯示其名稱,默認為顯示
#action.destructive_requires_name: true
# 允許記憶體鎖定,提高ES性能
bootstrap.memory_lock: true
修改JVM配置
修改jvm.options,通常設定-Xms和-Xmx的的值為“物理記憶體大小的一半和32G的較小值”
這是因為,es內核使用lucene,lucene本身是單獨占用記憶體的,并且占用的還不少,官方建議設定es記憶體,大小為物理記憶體的一半,剩下的一半留給lucene
COPY-Xms2g
-Xmx2g
關閉作業系統的swap
臨時關閉
COPYsudo swapoff -a
永久關閉
注釋掉或洗掉所有swap相關的內容
COPYvi /etc/fstab

修改檔案描述符
修改/etc/security/limits.conf,設定memlock為unlimited
COPYelk hard memlock unlimited
elk soft memlock unlimited
修改系統配置
設定虛擬記憶體
修改
/etc/systemd/system.conf,設定vm.max_map_count為一個較大的值
COPYvm.max_map_count=10240000
修改檔案上限
修改
/etc/systemd/system.conf,設定DefaultLimitNOFILE,DefaultLimitNPROC,DefaultLimitMEMLOCK為一個較大值,或者不限定
COPYDefaultLimitNOFILE=100000
DefaultLimitNPROC=100000
DefaultLimitMEMLOCK=infinity
重啟ES
服務發現優化
Elasticsearch 默認被配置為使用單播發現,以防止節點無意中加入集群
組播發現應該永遠不被使用在生產環境了,否則你得到的結果就是一個節點意外的加入到了你的生產環境,僅僅是因為他們收到了一個錯誤的組播信號,ES是一個P2P型別的分布式系統,使用gossip協議,集群的任意請求都可以發送到集群的任一節點,然后es內部會找到需要轉發的節點,并且與之進行通信,在es1.x的版本,es默認是開啟組播,啟動es之后,可以快速將局域網內集群名稱,默認埠的相同實體加入到一個大的集群,后續再es2.x之后,都調整成了單播,避免安全問題和網路風暴;
單播discovery.zen.ping.unicast.hosts,建議寫入集群內所有的節點及埠,如果新實體加入集群,新實體只需要寫入當前集群的實體,即可自動加入到當前集群,之后再處理原實體的配置即可,新實體加入集群,不需要重啟原有實體;
節點zen相關配置:discovery.zen.ping_timeout:判斷master選舉程序中,發現其他node存活的超時設定,主要影響選舉的耗時,引數僅在加入或者選舉 master 主節點的時候才起作用discovery.zen.join_timeout:節點確定加入到集群中,向主節點發送加入請求的超時時間,默認為3sdiscovery.zen.minimum_master_nodes:參與master選舉的最小節點數,當集群能夠被選為master的節點數量小于最小數量時,集群將無法正常選舉,
故障檢測( fault detection )
故障檢測情況
以下兩種情況下回進行故障檢測
COPY* 第一種是由master向集群的所有其他節點發起ping,驗證節點是否處于活動狀態
* 第二種是:集群每個節點向master發起ping,判斷master是否存活,是否需要發起選舉
配置方式
故障檢測需要配置以下設定使用
discovery.zen.fd.ping_interval:節點被ping的頻率,默認為1s,discovery.zen.fd.ping_timeout等待ping回應的時間,默認為 30s,運行的集群中,master 檢測所有節點,以及節點檢測 master 是否正常,discovery.zen.fd.ping_retriesping失敗/超時多少導致節點被視為失敗,默認為3,
佇列數量優化
不建議盲目加大es的佇列數量,要根據實際情況來進行調整
如果是偶發的因為資料突增,導致佇列阻塞,加大佇列size可以使用記憶體來快取資料,如果是持續性的資料阻塞在佇列,加大佇列size除了加大記憶體占用,并不能有效提高資料寫入速率,反而可能加大es宕機時候,在記憶體中可能丟失的上資料量,
查看執行緒池情況
通過以下可以查看執行緒池的情況,哪些情況下,加大佇列size呢?
COPYGET /_cat/thread_pool
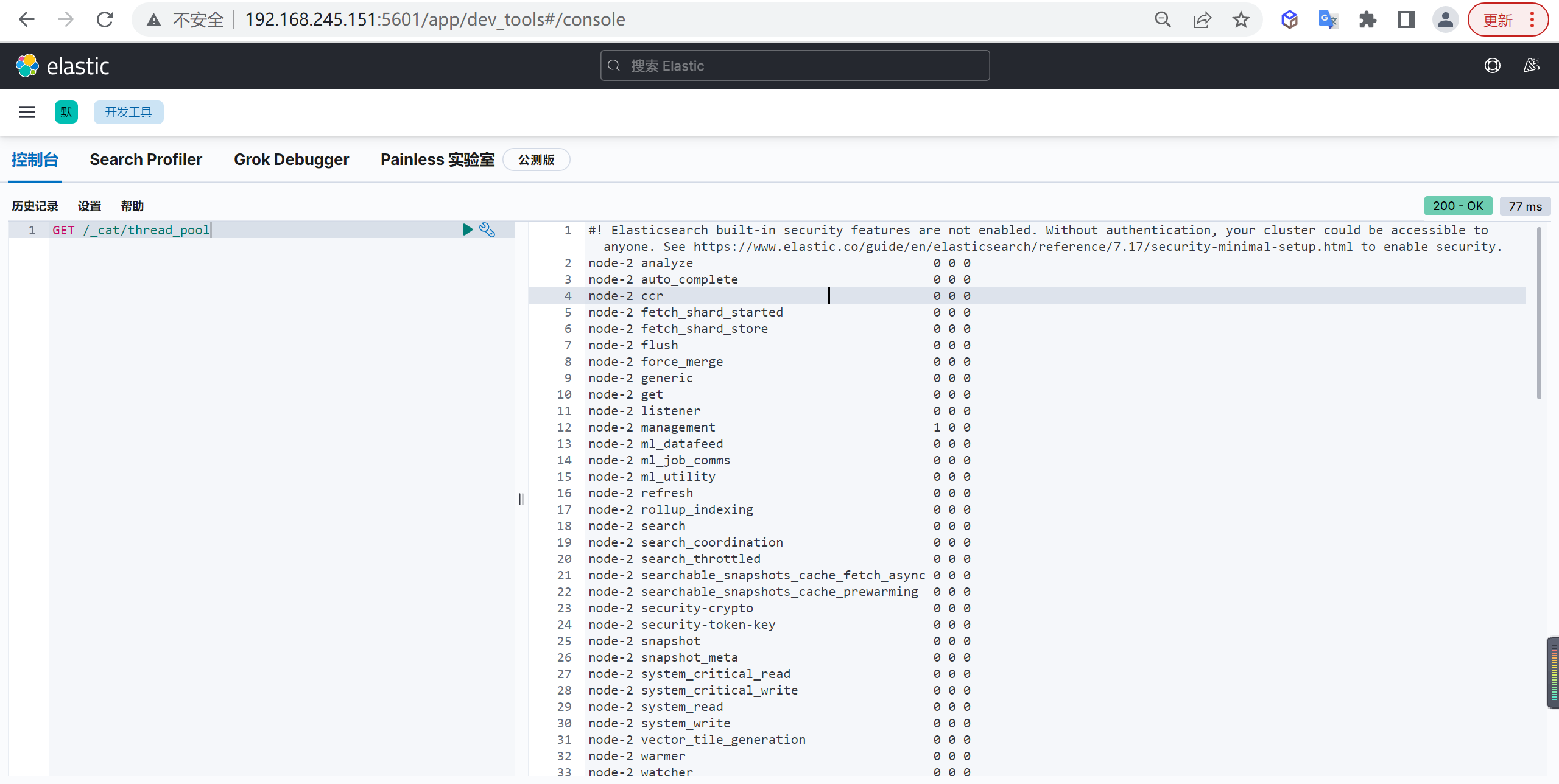
觀察api中回傳的queue和rejected,如果確實存在佇列拒絕或者是持續的queue,可以酌情調整佇列size,
記憶體使用
配置熔斷限額
設定indices的記憶體熔斷相關引數,根據實際情況進行調整,防止寫入或查詢壓力過高導致OOM
indices.breaker.total.limit: 50%,集群級別的斷路器,默認為jvm堆的70%indices.breaker.request.limit: 10%,單個request的斷路器限制,默認為jvm堆的60%indices.breaker.fielddata.limit: 10%,fielddata breaker限制,默認為jvm堆的60%,
配置快取
根據實際情況調整查詢占用cache,避免查詢cache占用過多的jvm記憶體,引數為靜態的,需要在每個資料節點配置
indices.queries.cache.size: 5%,控制過濾器快取的記憶體大小,默認為10%,接受百分比值,5%或者精確值,例如512mb,
創建分片優化
如果集群規模較大,可以阻止新建shard時掃描集群內全部shard的元資料,提升shard分配速度
cluster.routing.allocation.disk.include_relocations: false,默認為true
系統層面調優
jdk版本
選用當前版本ES推薦使用的ES,或者使用ES自帶的JDK
jdk記憶體配置
首先,-Xms和-Xmx設定為相同的值,避免在運行程序中再進行記憶體分配,同時,如果系統記憶體小于64G,建議設定略小于機器記憶體的一半,剩余留給系統使用,同時,jvm heap建議不要超過32G(不同jdk版本具體的值會略有不同),否則jvm會因為記憶體指標壓縮導致記憶體浪費
關閉交換磁區
關閉交換磁區,防止記憶體發生交換導致性能下降(部分情況下,寧死勿慢)
swapoff -a
檔案句柄
Lucene 使用了 大量的 檔案,同時,Elasticsearch 在節點和 HTTP 客戶端之間進行通信也使用了大量的套接字,所有這一切都需要足夠的檔案描述符,默認情況下,linux默認運行單個行程打開1024個檔案句柄,這顯然是不夠的,故需要加大檔案句柄數 ulimit -n 65536
mmap
Elasticsearch 對各種檔案混合使用了 NioFs( 注:非阻塞檔案系統)和 MMapFs ( 注:記憶體映射檔案系統),
請確保你配置的最大映射數量,以便有足夠的虛擬記憶體可用于 mmapped 檔案,這可以暫時設定:sysctl -w vm.max_map_count=262144 或者你可以在 /etc/sysctl.conf 通過修改 vm.max_map_count 永久設定它,
磁盤
如果你正在使用 SSDs,確保你的系統 I/O 調度程式是配置正確的
當你向硬碟寫資料,I/O 調度程式決定何時把資料實際發送到硬碟,大多數默認linux 發行版下的調度程式都叫做 cfq(完全公平佇列),但它是為旋轉介質優化的:機械硬碟的固有特性意味著它寫入資料到基于物理布局的硬碟會更高效,
這對 SSD 來說是低效的,盡管這里沒有涉及到機械硬碟,但是,deadline 或者 noop 應該被使用,deadline 調度程式基于寫入等待時間進行優化, noop 只是一個簡單的 FIFO 佇列,
COPYecho noop > /sys/block/sd/queue/scheduler
磁盤掛載
COPYmount -o noatime,data=https://www.cnblogs.com/jiagooushi/p/writeback,barrier=0,nobh /dev/sd* /esdata*
其中,noatime,禁止記錄訪問時間戳;data=https://www.cnblogs.com/jiagooushi/p/writeback,不記錄journal;barrier=0,因為關閉了journal,所以同步關閉barrier;nobh,關閉buffer_head,防止內核影響資料IO
磁盤其他注意事項
使用 RAID 0,條帶化 RAID 會提高磁盤I/O,代價顯然就是當一塊硬碟故障時整個就故障了,不要使用鏡像或者奇偶校驗 RAID 因為副本已經提供了這個功能,
另外,使用多塊硬碟,并允許 Elasticsearch 通過多個 path.data 目錄配置把資料條帶化分配到它們上面,不要使用遠程掛載的存盤,比如 NFS 或者 SMB/CIFS,這個引入的延遲對性能來說完全是背道而馳的,
使用方式調優
當elasticsearch本身的配置沒有明顯的問題之后,發現es使用還是非常慢,這個時候,就需要我們去定位es本身的問題了,首先祭出定位問題的第一個命令:
Index(寫)調優
副本數置0
如果是集群首次灌入資料,可以將副本數設定為0,寫入完畢再調整回去,這樣副本分片只需要拷貝,節省了索引程序
COPYPUT /my_temp_index/_settings
{
"number_of_replicas": 0
}
自動生成doc ID
通過Elasticsearch寫入流程可以看出,如果寫入doc時如果外部指定了id,則Elasticsearch會先嘗試讀取原來doc的版本號,以判斷是否需要更新,這會涉及一次讀取磁盤的操作,通過自動生成doc ID可以避免這個環節
合理設定mappings
將不需要建立索引的欄位index屬性設定為not_analyzed或no,
- 對欄位不分詞,或者不索引,可以減少很多運算操作,降低CPU占用,尤其是binary型別,默認情況下占用CPU非常高,而這種型別進行分詞通常沒有什么意義,
- 減少欄位內容長度,如果原始資料的大段內容無須全部建立 索引,則可以盡量減少不必要的內容,
- 使用不同的分析器(analyzer),不同的分析器在索引程序中 運算復雜度也有較大的差異,
調整_source欄位
_source` 欄位用于存盤 doc 原始資料,對于部分不需要存盤的欄位,可以通過 includes excludes過濾,或者將`_source`禁用,一般用于索引和資料分離,這樣可以降低 I/O 的壓力,不過實際場景中大多不會禁用`_source
對analyzed的欄位禁用norms
Norms用于在搜索時計算doc的評分,如果不需要評分,則可以將其禁用
COPYtitle": {
"type": "string",
"norms": {
"enabled": false
}
調整索引的重繪間隔
該引數預設是1s,強制ES每秒創建一個新segment,從而保證新寫入的資料近實時的可見、可被搜索到,比如該引數被調整為30s,降低了重繪的次數,把重繪操作消耗的系統資源釋放出來給index操作使用
COPYPUT /my_index/_settings
{
?"index" : {
??? ??"refresh_interval": "30s"
????}
}
這種方案以犧牲可見性的方式,提高了index操作的性能,
批處理
批處理把多個index操作請求合并到一個batch中去處理,和mysql的jdbc的bacth有類似之處
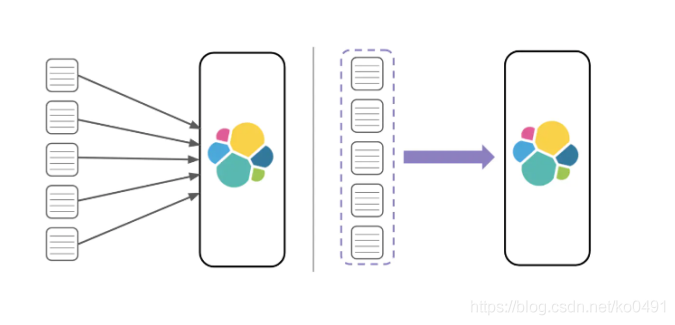
比如每批1000個documents是一個性能比較好的size,每批中多少document條數合適,受很多因素影響而不同,如單個document的大小等,ES官網建議通過在單個node、單個shard做性能基準測驗來確定這個引數的最優值
Document的路由處理
當對一批中的documents進行index操作時,該批index操作所需的執行緒的個數由要寫入的目的shard的個數決定
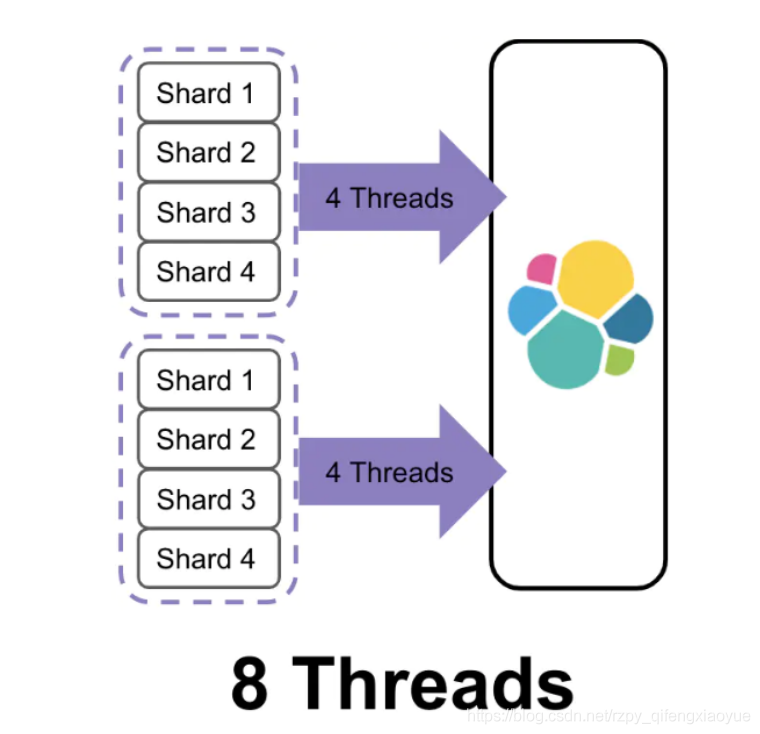
有2批documents寫入ES, 每批都需要寫入4個shard,所以總共需要8個執行緒,如果能減少shard的個數,那么耗費的執行緒個數也會減少,例如下圖,兩批中每批的shard個數都只有2個,總共執行緒消耗個數4個,減少一半,
默認的routing就是id,也可以在發送請求的時候,手動指定一個routing value,比如說put/index/doc/id?routing=user_id
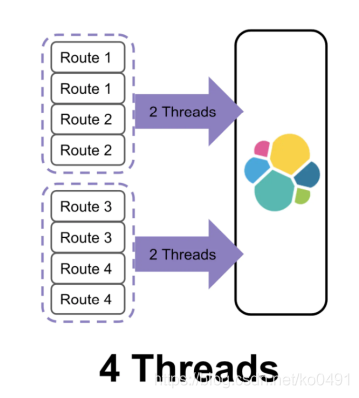
值得注意的是執行緒數雖然降低了,但是單批的處理耗時可能增加了,和提高重繪間隔方法類似,這有可能會延長資料不見的時間
Search(讀)調優
在存盤的Document條數超過10億條后,我們如何進行搜索調優
資料分組
很多人拿ES用來存盤日志,日志的索引管理方式一般基于日期的,基于天、周、月、年建索引,如下圖,基于天建索引
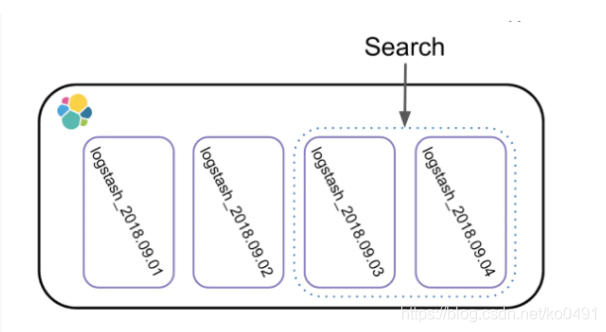
當搜索單天的資料,只需要查詢一個索引的shards就可以,當需要查詢多天的資料時,需要查詢多個索引的shards,這種方案其實和資料庫的分表、分庫、磁區查詢方案相比,思路類似,小資料范圍查詢而不是大海撈針,
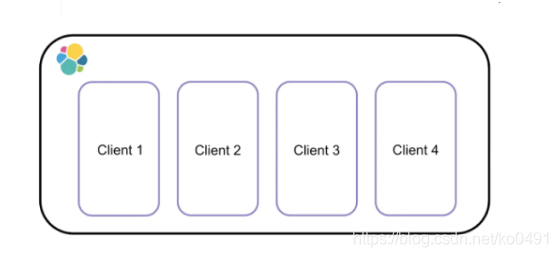
開始的方案是建一個index,當資料量增大的時候,就擴容增加index的shard的個數,當shards增大時,要搜索的shards個數也隨之顯著上升,基于資料分組的思路,可以基于client進行資料分組,每一個client只需依賴自己的index的資料shards進行搜索,而不是所有的資料shards,大大提高了搜索的性能,如下圖:
使用Filter替代Query
在搜索時候使用Query,需要為Document的相關度打分,使用Filter,沒有打分環節處理,做的事情更少,而且filter理論上更快一些,
如果搜索不需要打分,可以直接使用filter查詢,如果部分搜索需要打分,建議使用’bool’查詢,這種方式可以把打分的查詢和不打分的查詢組合在一起使用,如
COPYGET /_search
{
"query": {
"bool": {
"must": {
"term": {
"user": "kimchy"
}
},
"filter": {
"term": {
"tag": "tech"
}
}
}
}
}
ID欄位定義為keyword
一般情況,如果ID欄位不會被用作Range 型別搜索欄位,都可以定義成keyword型別,這是因為keyword會被優化,以便進行terms查詢,Integers等數字類的mapping型別,會被優化來進行range型別搜索,將integers改成keyword型別之后,搜索性能大約能提升30%
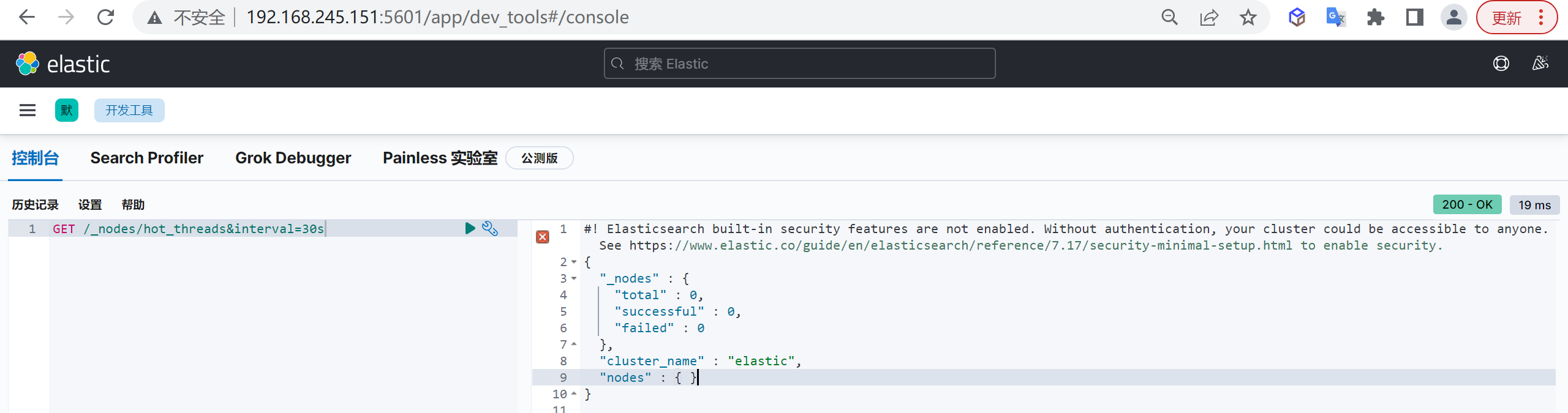
hot_threads
可以使用以下命令,抓取30s區間內的節點上占用資源的熱執行緒,并通過排查占用資源最多的TOP執行緒來判斷對應的資源消耗是否正常
COPYGET /_nodes/hot_threads&interval=30s
一般情況下,bulk,search類的執行緒占用資源都可能是業務造成的,但是如果是merge執行緒占用了大量的資源,就應該考慮是不是創建index或者刷磁盤間隔太小,批量寫入size太小造成的,
pending_tasks
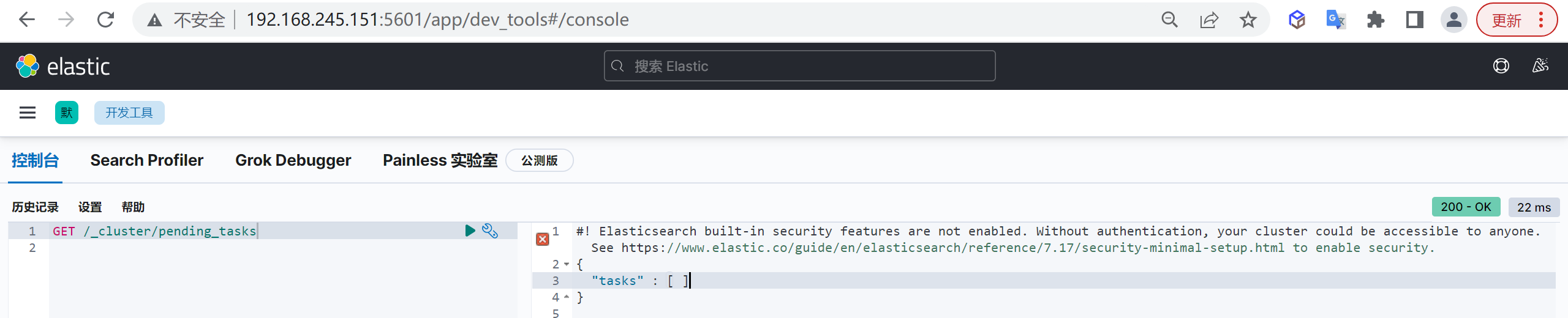
有一些任務只能由主節點去處理,比如創建一個新的索引或者在集群中移動分片,由于一個集群中只能有一個主節點,所以只有這一master節點可以處理集群級別的元資料變動
在99.9999%的時間里,這不會有什么問題,元資料變動的佇列基本上保持為零,在一些罕見的集群里,元資料變動的次數比主節點能處理的還快,這會導致等待中的操作會累積成佇列,這個時候可以通過pending_tasks api分析當前什么操作阻塞了es的佇列,比如,集群例外時,會有大量的shard在recovery,如果集群在大量創建新欄位,會出現大量的put_mappings的操作,所以正常情況下,需要禁用動態mapping,
COPYGET /_cluster/pending_tasks
欄位存盤
當前es主要有doc_values,fielddata,storefield三種型別,大部分情況下,并不需要三種型別都存盤,可根據實際場景進行調整:
當前用得最多的就是doc_values,列存盤,對于不需要進行分詞的欄位,都可以開啟doc_values來進行存盤(且只保留keyword欄位),節約記憶體,當然,開啟doc_values會對查詢性能有一定的影響,但是,這個性能損耗是比較小的,而且是值得的;
fielddata構建和管理 100% 在記憶體中,常駐于 JVM 記憶體堆,所以可用于快速查詢,但是這也意味著它本質上是不可擴展的,有很多邊緣情況下要提防,如果對于欄位沒有分析需求,可以關閉fielddata;
storefield主要用于_source欄位,默認情況下,資料在寫入es的時候,es會將doc資料存盤為_source欄位,查詢時可以通過_source欄位快速獲取doc的原始結構,如果沒有update,reindex等需求,可以將_source欄位disable;
_all,ES在6.x以前的版本,默認將寫入的欄位拼接成一個大的字串,并對該欄位進行分詞,用于支持整個doc的全文檢索,在知道doc欄位名稱的情況下,建議關閉掉該欄位,節約存盤空間,也避免不帶欄位key的全文檢索;
norms:搜索時進行評分,日志場景一般不需要評分,建議關閉;
事務日志
Elasticsearch 2.0之后為了保證不丟資料,每次 index、bulk、delete、update 完成的時候,一定會觸發同步重繪 translog 到磁盤上,才給請求回傳 200 OK
異步重繪
采用異步重繪,這個改變在提高資料安全性的同時當然也降低了一點性能,如果你不在意這點可能性,還是希望性能優先,可以在 index template 里設定如下引數
COPY{
"index.translog.durability": "async"
}
其他引數
index.translog.sync_interval
對于一些大容量的偶爾丟失幾秒資料問題也并不嚴重的集群,使用異步的 fsync 還是比較有益的,比如,寫入的資料被快取到記憶體中,再每5秒執行一次 fsync ,默認為5s,小于的值100ms是不允許的,
index.translog.flush_threshold_size
translog存盤尚未安全保存在Lucene中的所有操作,雖然這些操作可用于讀取,但如果要關閉并且必須恢復,則需要重新編制索引,此設定控制這些操作的最大總大小,以防止恢復時間過長,達到設定的最大size后,將發生重繪,生成新的Lucene提交點,默認為512mb,
refresh_interval
執行重繪操作的頻率,這會使索引的最近更改對搜索可見,默認為1s,可以設定-1為禁用重繪,對于寫入速率要求較高的場景,可以適當的加大對應的時長,減小磁盤io和segment的生成;
禁止動態mapping
動態mapping的缺點
- 造成集群元資料一直變更,導致 不穩定;
- 可能造成資料型別與實際型別不一致;
- 對于一些例外欄位或者是掃描類的欄位,也會頻繁的修改mapping,導致業務不可控,
映射配置
動態mapping配置的可選值及含義如下
- true:支持動態擴展,新增資料有新的欄位屬性時,自動添加對于的mapping,資料寫入成功
- false:不支持動態擴展,新增資料有新的欄位屬性時,直接忽略,資料寫入成功
- strict:不支持動態擴展,新增資料有新的欄位時,報錯,資料寫入失敗
批量寫入
批量請求顯然會大大提升寫入速率,且這個速率是可以量化的,官方建議每次批量的資料物理位元組數5-15MB是一個比較不錯的起點,注意這里說的是物理位元組數大小,
檔案計數對批量大小來說不是一個好指標,比如說,如果你每次批量索引 1000 個檔案,記住下面的事實:1000 個 1 KB 大小的檔案加起來是 1 MB 大,1000 個 100 KB 大小的檔案加起來是 100 MB 大,
這可是完完全全不一樣的批量大小了,批量請求需要在協調節點上加載進記憶體,所以批量請求的物理大小比檔案計數重要得多,從 5–15 MB 開始測驗批量請求大小,緩慢增加這個數字,直到你看不到性能提升為止,
然后開始增加你的批量寫入的并發度(多執行緒等等辦法),用iostat 、 top 和 ps 等工具監控你的節點,觀察資源什么時候達到瓶頸,如果你開始收到 EsRejectedExecutionException ,你的集群沒辦法再繼續了:至少有一種資源到瓶頸了,或者減少并發數,或者提供更多的受限資源(比如從機械磁盤換成 SSD),或者添加更多節點,
索引和shard
es的索引,shard都會有對應的元資料,
因為es的元資料都是保存在master節點,且元資料的更新是要hold住集群向所有節點同步的,當es的新建欄位或者新建索引的時候,都會要獲取集群元資料,并對元資料進行變更及同步,此時會影響集群的回應,所以需要關注集群的index和shard數量,
使用建議
建議如下
- 使用shrink和rollover api,相對生成合適的資料shard數;
- 根據資料量級及對應的性能需求,選擇創建index的名稱,形如:按月生成索引:test-YYYYMM,按天生成索引:test-YYYYMMDD;
- 控制單個shard的size,正常情況下,日志場景,建議單個shard不大于50GB,線上業務場景,建議單個shard不超過20GB;
段合并
段合并的計算量龐大, 而且還要吃掉大量磁盤 I/O
合并在后臺定期操作,因為他們可能要很長時間才能完成,尤其是比較大的段,這個通常來說都沒問題,因為大規模段合并的概率是很小的,
如果發現merge占用了大量的資源,可以設定:index.merge.scheduler.max_thread_count: 1 特別是機械磁盤在并發 I/O 支持方面比較差,所以我們需要降低每個索引并發訪問磁盤的執行緒數,這個設定允許 max_thread_count + 2 個執行緒同時進行磁盤操作,也就是設定為 1 允許三個執行緒,對于 SSD,你可以忽略這個設定,默認是 Math.min(3, Runtime.getRuntime().availableProcessors() / 2) ,對 SSD 來說運行的很好,
業務低峰期通過force_merge強制合并segment,降低segment的數量,減小記憶體消耗;關閉冷索引,業務需要的時候再進行開啟,如果一直不使用的索引,可以定期洗掉,或者備份到hadoop集群;
自動生成_id
當寫入端使用特定的id將資料寫入es時,es會去檢查對應的index下是否存在相同的id,這個操作會隨著檔案數量的增加而消耗越來越大,所以如果業務上沒有強需求,建議使用es自動生成的id,加快寫入速率,
routing
對于資料量較大的業務查詢場景,es側一般會創建多個shard,并將shard分配到集群中的多個實體來分攤壓力,正常情況下,一個查詢會遍歷查詢所有的shard,然后將查詢到的結果進行merge之后,再回傳給查詢端,
此時,寫入的時候設定routing,可以避免每次查詢都遍歷全量shard,而是查詢的時候也指定對應的routingkey,這種情況下,es會只去查詢對應的shard,可以大幅度降低合并資料和調度全量shard的開銷,
使用alias
生產提供服務的索引,切記使用別名提供服務,而不是直接暴露索引名稱,避免后續因為業務變更或者索引資料需要reindex等情況造成業務中斷,
避免寬表
在索引中定義太多欄位是一種可能導致映射爆炸的情況,這可能導致記憶體不足錯誤和難以恢復的情況,這個問題可能比預期更常見,index.mapping.total_fields.limit ,默認值是1000
避免稀疏索引
因為索引稀疏之后,對應的相鄰檔案id的delta值會很大,lucene基于檔案id做delta編碼壓縮導致壓縮率降低,從而導致索引檔案增大,同時,es的keyword,陣列型別采用doc_values結構,每個檔案都會占用一定的空間,即使欄位是空值,所以稀疏索引會造成磁盤size增大,導致查詢和寫入效率降低,
最后說一句(求關注,別白嫖我)
如果這篇文章對您有所幫助,或者有所啟發的話,求一鍵三連:點贊、轉發、在看,您的支持是我堅持寫作最大的動力,
-
作者: 博學谷狂野架構師
-
GitHub地址:GitHub地址 (有我們精心準備的130本電子書PDF)
本文由
傳智教育博學谷狂野架構師教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/548559.html
標籤:Java
上一篇:MyBatis常見問題描述
下一篇:Java資料型別、識別符號