一、問題引入
單鏈表的實作【01】:Student-Management-System 只體現了專案功能實作,未對代碼部分做出說明,
故新增隨筆進行補充說明代碼部分,
重構代碼,迭代版本:Student Mangement System(Version 2.0)
二、解決程序
基于單鏈表實作就離不開鏈表的幾個重要概念:頭結點、首元結點、頭指標
2-1 鏈表概念
線性表鏈式存盤結構的特點是:用一組任意的存盤單元存盤線性表的資料元素(這組存盤單元可以是連續的,也可以是不連續的),
根據鏈表結點所含指標個數、指標指向和指標連接方式,可將鏈表分為單鏈表、回圈鏈表、雙向鏈表、二叉鏈表、十字鏈表、鄰接表、鄰接多重表等
本隨筆基于單鏈表實作,這里重點介紹它,
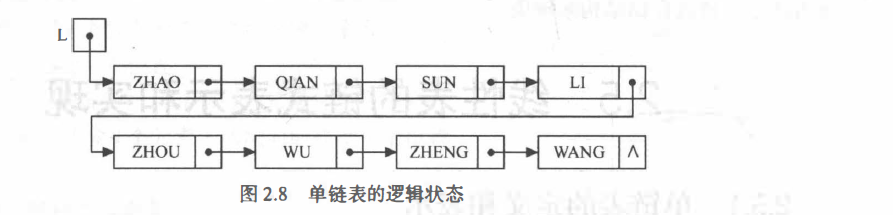
?? 不帶附加結點(即頭結點)的單鏈表
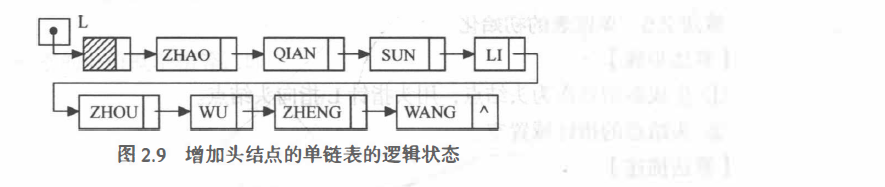
?? 帶附加結點(即頭結點)的單鏈表
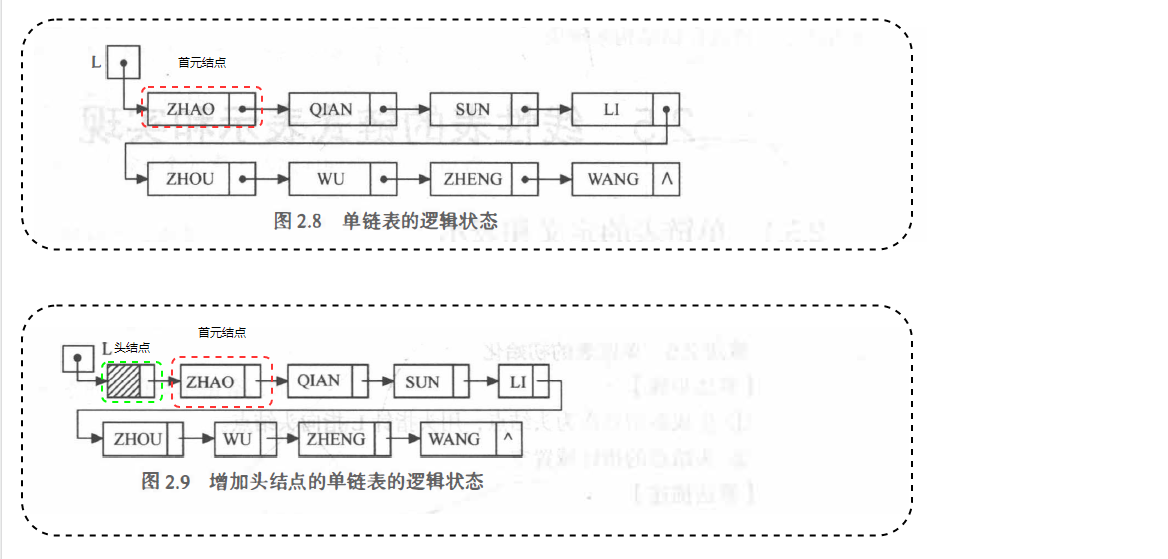
-
首元結點:指鏈表中存盤第一個資料元素a1的結點
-
頭結點:在首元結點之前附設的一個結點,其指標域指向首元結點
-
頭指標:指向鏈表中第一個結點的指標
若鏈表設有頭結點,則頭指標所指結點為線性表的頭結點;
若鏈表不設頭結點,則頭指標所指結點為該線性表的首元結點
?? 鏈表增加頭結點的作用如下:
(1)便于首元結點的處理增加了頭結點后,首元結點的地址保存在頭結點(即其“前驅” 結點)的指標域中,則對鏈表的第一個資料元素的操作與其他資料元素相同,無需進行特殊處理,
(2)便于空表和非空表的統一處理當鏈表不設頭結點時,假設L 為單鏈表的頭指標,它應該指向首元結點,則當單鏈表為長度n 為0 的空表時, L 指標為空(判定空表的條件可記為:L== NULL),
?? 為了提高程式的可讀性,在此對同一結構體指標型別起了兩個名稱,LinkList 與LNode* , 兩者本質上是等價的,通常習慣上用LinkList 定義單鏈表,強調定義的是某個單鏈表的頭指標;用LNode *定義指向單鏈表中任意結點的指標變數
2-2 鏈表實作
- 結構體定義
#define ERROR -1 // 錯誤
#define OK 0 // 成功
#define OVERFLOW -2 // 溢位
#define TRUE 1 // 真
#define FALSE 0 // 假
typedef struct
{
char stu_name[10]; // 學生姓名
char stu_sex[10]; // 學生性別
int stu_age; // 學生年齡
int stu_id; // 學生學號
}Student_T;
typedef Student_T ElemType;
typedef struct LNode_T
{
ElemType data; // 結點資料域
struct LNode_T *next; // 結點指標域
}LNode_T, *LinkList_T; //LinkList_T 為指向結構體LNode_T的指標型別
- 單鏈表的初始化
int list_init(LinkList_T *L)
{
// 構造一個空的單鏈表
// 生成新結點作為頭結點,用頭指標*L(即單鏈表L)指向頭結點
*L = (LNode_T *)malloc(sizeof(LNode_T));
if (NULL == *L)
exit(OVERFLOW);
memset(*L, 0, sizeof(LNode_T));
(*L)->next = NULL;
return OK;
}
- 單鏈表的銷毀
int list_destory(LinkList_T *L)
{
// 釋放所有結點(包括頭結點)空間
LNode_T *temp;
while (*L)
{
temp = *L;
*L = (*L)->next;
free(temp);
}
return OK;
}
- 單鏈表的查找(匹配學號查找結點)
LNode_T * list_locate(LinkList_T L, int stu_id)
{
// p指向首元結點
LNode_T *p = L->next;
LNode_T *q = NULL;
while (p != NULL)
{
if (stu_id == p->data.stu_id)
{
q = p;
break;
}
p = p->next;
}
return q;
}
- 單鏈表的結點更新
int list_update(LinkList_T L, int stu_id, const char *stu_name)
{
int result = ERROR;
LNode_T *p_node = list_locate(L, stu_id);
if (NULL != p_node)
{
strcpy(p_node->data.stu_name, stu_name);
result = OK;
}
return result;
}
- 單鏈表的洗掉(匹配學號洗掉結點)
int list_delete(LinkList_T *L, int stu_id)
{
// p指向頭結點
LNode_T *p;
LNode_T *q;
int is_found = ERROR;
for (q = NULL, p = *L; p != NULL; q = p, p = p->next)
{
if (stu_id == p->data.stu_id)
{
q->next = p->next;
free(p);
is_found = OK;
break;
}
}
return is_found;
}
- 創建單鏈表(尾插法)
int list_create_r(LinkList_T *L, ElemType elem)
{
// r指向頭結點
LNode_T *r = (*L);
while (r->next != NULL)
{
r = r->next;
}
LNode_T *p = (LNode_T *)malloc(sizeof(LNode_T));
p->data = https://www.cnblogs.com/caojun97/p/elem;
p->next = NULL;
r->next = p;
return OK;
- 單鏈表的遍歷
int list_traverse(LinkList_T L)
{
// p指向首元結點
LNode_T *p;
for (p = L->next; p != NULL; p = p->next)
{
printf("%d %s %s %d\n", p->data.stu_id, p->data.stu_name,
p->data.stu_sex, p->data.stu_age);
}
return OK;
}
三、反思總結
單鏈表的實作程序,需要考慮是否附加頭結點,有頭結點和沒有頭結點的實作會有所不同
單鏈表的操作可以獨立封裝,根據具體的應用場景可以進行二次封裝
四、參考參考
資料結構第二版:C語言版 【嚴蔚敏】 第二章 線性表(鏈表)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/548686.html
標籤:C