Java的特點
Java是一門面向物件的編程語言,面向物件和面向程序的區別參考下一個問題,
Java具有平臺獨立性和移植性,
- Java有一句口號:
Write once, run anywhere,一次撰寫、到處運行,這也是Java的魅力所在,而實作這種特性的正是Java虛擬機JVM,已編譯的Java程式可以在任何帶有JVM的平臺上運行,你可以在windows平臺撰寫代碼,然后拿到linux上運行,只要你在撰寫完代碼后,將代碼編譯成.class檔案,再把class檔案打成Java包,這個jar包就可以在不同的平臺上運行了,
Java具有穩健性,
- Java是一個強型別語言,它允許擴展編譯時檢查潛在型別不匹配問題的功能,Java要求顯式的方法宣告,它不支持C風格的隱式宣告,這些嚴格的要求保證編譯程式能捕捉呼叫錯誤,這就導致更可靠的程式,
- 例外處理是Java中使得程式更穩健的另一個特征,例外是某種類似于錯誤的例外條件出現的信號,使用
try/catch/finally陳述句,程式員可以找到出錯的處理代碼,這就簡化了出錯處理和恢復的任務,
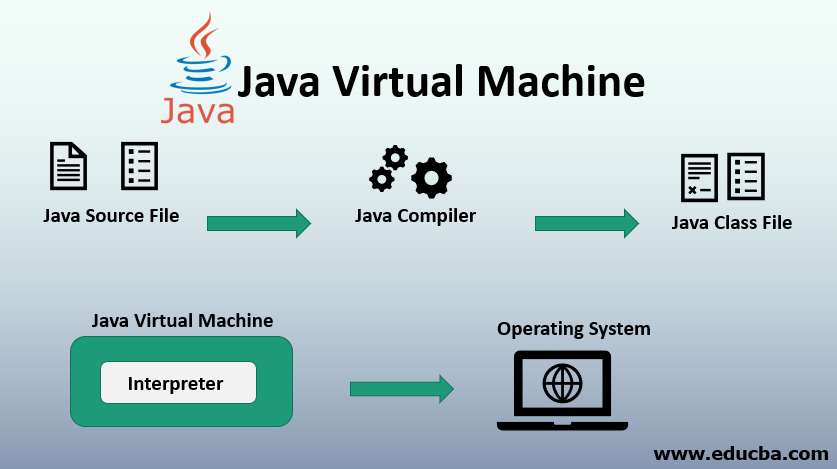
Java是如何實作跨平臺的?
Java是通過JVM(Java虛擬機)實作跨平臺的,
JVM可以理解成一個軟體,不同的平臺有不同的版本,我們撰寫的Java代碼,編譯后會生成.class 檔案(位元組碼檔案),Java虛擬機就是負責將位元組碼檔案翻譯成特定平臺下的機器碼,通過JVM翻譯成機器碼之后才能運行,不同平臺下編譯生成的位元組碼是一樣的,但是由JVM翻譯成的機器碼卻不一樣,
只要在不同平臺上安裝對應的JVM,就可以運行位元組碼檔案,運行我們撰寫的Java程式,
因此,運行Java程式必須有JVM的支持,因為編譯的結果不是機器碼,必須要經過JVM的翻譯才能執行,
Java 與 C++ 的區別
- Java 是純粹的面向物件語言,所有的物件都繼承自 java.lang.Object,C++ 兼容 C ,不但支持面向物件也支持面向程序,
- Java 通過虛擬機從而實作跨平臺特性, C++ 依賴于特定的平臺,
- Java 沒有指標,它的參考可以理解為安全指標,而 C++ 具有和 C 一樣的指標,
- Java 支持自動垃圾回收,而 C++ 需要手動回收,
- Java 不支持多重繼承,只能通過實作多個介面來達到相同目的,而 C++ 支持多重繼承,
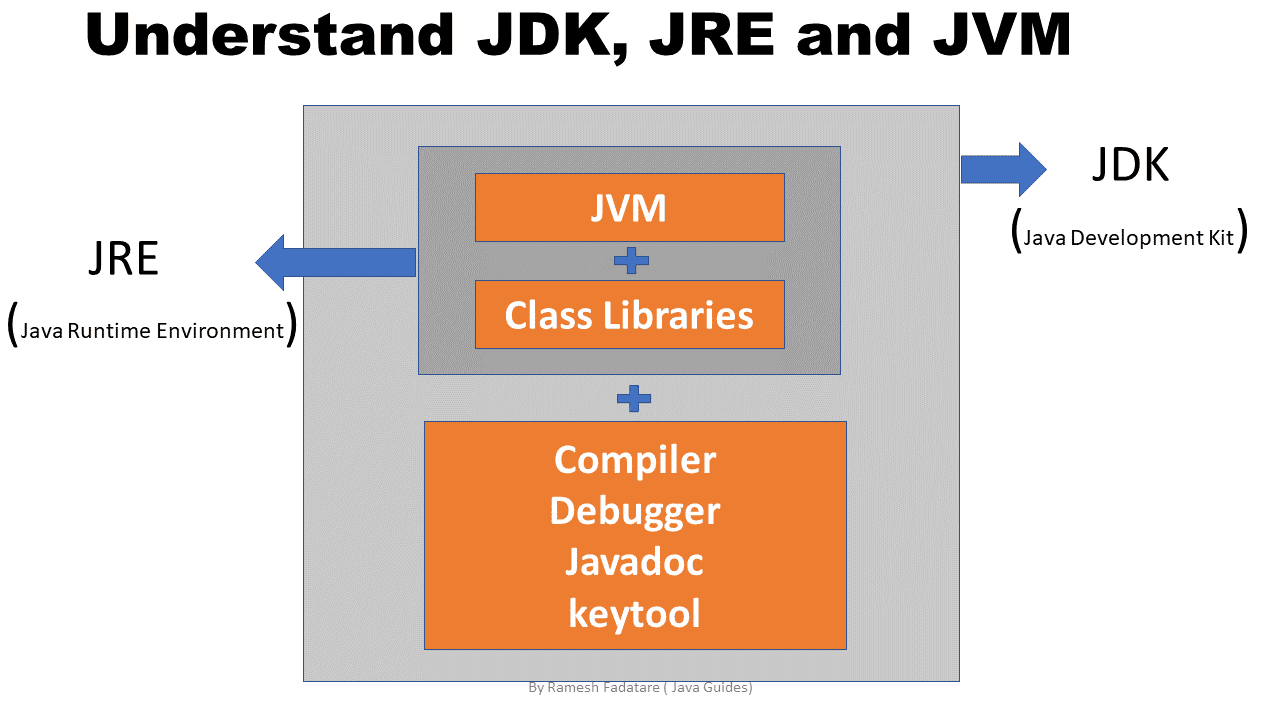
JDK/JRE/JVM三者的關系
JVM
英文名稱(Java Virtual Machine),就是我們耳熟能詳的 Java 虛擬機,Java 能夠跨平臺運行的核心在于 JVM ,
本文已經收錄到Github倉庫,該倉庫包含計算機基礎、Java基礎、多執行緒、JVM、資料庫、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服務、設計模式、架構、校招社招分享等核心知識點,歡迎star~
Github地址:https://github.com/Tyson0314/Java-learning
所有的java程式會首先被編譯為.class的類檔案,這種類檔案可以在虛擬機上執行,也就是說class檔案并不直接與機器的作業系統互動,而是經過虛擬機間接與作業系統互動,由虛擬機將程式解釋給本地系統執行,
針對不同的系統有不同的 jvm 實作,有 Linux 版本的 jvm 實作,也有Windows 版本的 jvm 實作,但是同一段代碼在編譯后的位元組碼是一樣的,這就是Java能夠跨平臺,實作一次撰寫,多處運行的原因所在,
JRE
英文名稱(Java Runtime Environment),就是Java 運行時環境,我們撰寫的Java程式必須要在JRE才能運行,它主要包含兩個部分,JVM 和 Java 核心類別庫,
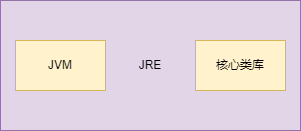
JRE是Java的運行環境,并不是一個開發環境,所以沒有包含任何開發工具,如編譯器和除錯器等,
如果你只是想運行Java程式,而不是開發Java程式的話,那么你只需要安裝JRE即可,
JDK
英文名稱(Java Development Kit),就是 Java 開發工具包
學過Java的同學,都應該安裝過JDK,當我們安裝完JDK之后,目錄結構是這樣的
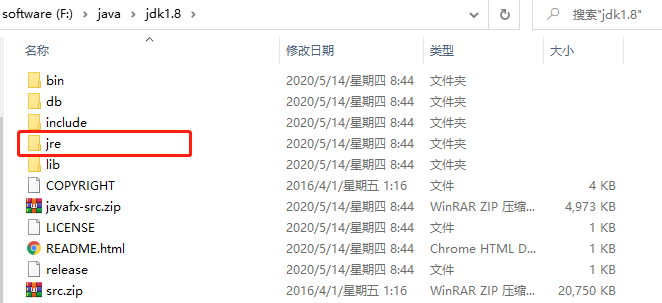
可以看到,JDK目錄下有個JRE,也就是JDK中已經集成了 JRE,不用單獨安裝JRE,
另外,JDK中還有一些好用的工具,如jinfo,jps,jstack等,
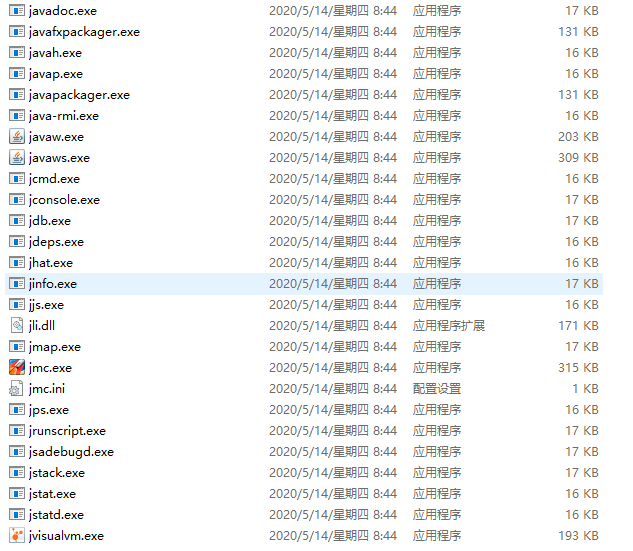
最后,總結一下JDK/JRE/JVM,他們三者的關系
JRE = JVM + Java 核心類別庫
JDK = JRE + Java工具 + 編譯器 + 除錯器
Java程式是編譯執行還是解釋執行?
先看看什么是編譯型語言和解釋型語言,
編譯型語言
在程式運行之前,通過編譯器將源程式編譯成機器碼可運行的二進制,以后執行這個程式時,就不用再進行編譯了,
優點:編譯器一般會有預編譯的程序對代碼進行優化,因為編譯只做一次,運行時不需要編譯,所以編譯型語言的程式執行效率高,可以脫離語言環境獨立運行,
缺點:編譯之后如果需要修改就需要整個模塊重新編譯,編譯的時候根據對應的運行環境生成機器碼,不同的作業系統之間移植就會有問題,需要根據運行的作業系統環境編譯不同的可執行檔案,
總結:執行速度快、效率高;依靠編譯器、跨平臺性差些,
代表語言:C、C++、Pascal、Object-C以及Swift,
解釋型語言
定義:解釋型語言的源代碼不是直接翻譯成機器碼,而是先翻譯成中間代碼,再由解釋器對中間代碼進行解釋運行,在運行的時候才將源程式翻譯成機器碼,翻譯一句,然后執行一句,直至結束,
優點:
- 有良好的平臺兼容性,在任何環境中都可以運行,前提是安裝了解釋器(如虛擬機),
- 靈活,修改代碼的時候直接修改就可以,可以快速部署,不用停機維護,
缺點:每次運行的時候都要解釋一遍,性能上不如編譯型語言,
總結:解釋型語言執行速度慢、效率低;依靠解釋器、跨平臺性好,
代表語言:JavaScript、Python、Erlang、PHP、Perl、Ruby,
對于Java這種語言,它的源代碼會先通過javac編譯成位元組碼,再通過jvm將位元組碼轉換成機器碼執行,即解釋運行 和編譯運行配合使用,所以可以稱為混合型或者半編譯型,
最全面的Java面試網站
面向物件和面向程序的區別?
面向物件和面向程序是一種軟體開發思想,
-
面向程序就是分析出解決問題所需要的步驟,然后用函式按這些步驟實作,使用的時候依次呼叫就可以了,
-
面向物件是把構成問題事務分解成各個物件,分別設計這些物件,然后將他們組裝成有完整功能的系統,面向程序只用函式實作,面向物件是用類實作各個功能模塊,
以五子棋為例,面向程序的設計思路就是首先分析問題的步驟:
1、開始游戲,2、黑子先走,3、繪制畫面,4、判斷輸贏,5、輪到白子,6、繪制畫面,7、判斷輸贏,8、回傳步驟2,9、輸出最后結果,
把上面每個步驟用分別的函式來實作,問題就解決了,
而面向物件的設計則是從另外的思路來解決問題,整個五子棋可以分為:
- 黑白雙方
- 棋盤系統,負責繪制畫面
- 規則系統,負責判定諸如犯規、輸贏等,
黑白雙方負責接受用戶的輸入,并告知棋盤系統棋子布局發生變化,棋盤系統接收到了棋子的變化的資訊就負責在螢屏上面顯示出這種變化,同時利用規則系統來對棋局進行判定,
面向物件有哪些特性?
面向物件四大特性:封裝,繼承,多型,抽象
1、封裝就是將類的資訊隱藏在類內部,不允許外部程式直接訪問,而是通過該類的方法實作對隱藏資訊的操作和訪問, 良好的封裝能夠減少耦合,
2、繼承是從已有的類中派生出新的類,新的類繼承父類的屬性和行為,并能擴展新的能力,大大增加程式的重用性和易維護性,在Java中是單繼承的,也就是說一個子類只有一個父類,
3、多型是同一個行為具有多個不同表現形式的能力,在不修改程式代碼的情況下改變程式運行時系結的代碼,實作多型的三要素:繼承、重寫、父類參考指向子類物件,
- 靜態多型性:通過多載實作,相同的方法有不同的參數串列,可以根據引數的不同,做出不同的處理,
- 動態多型性:在子類中重寫父類的方法,運行期間判斷所參考物件的實際型別,根據其實際型別呼叫相應的方法,
4、抽象,把客觀事物用代碼抽象出來,
面向物件編程的六大原則?
- 物件單一職責:我們設計創建的物件,必須職責明確,比如商品類,里面相關的屬性和方法都必須跟商品相關,不能出現訂單等不相關的內容,這里的類可以是模塊、類別庫、程式集,而不單單指類,
- 里式替換原則:子類能夠完全替代父類,反之則不行,通常用于實作介面時運用,因為子類能夠完全替代基(父)類,那么這樣父類就擁有很多子類,在后續的程式擴展中就很容易進行擴展,程式完全不需要進行修改即可進行擴展,比如IA的實作為A,因為專案需求變更,現在需要新的實作,直接在容器注入處更換介面即可.
- 迪米特法則,也叫最小原則,或者說最小耦合,通常在設計程式或開發程式的時候,盡量要高內聚,低耦合,當兩個類進行互動的時候,會產生依賴,而迪米特法則就是建議這種依賴越少越好,就像建構式注入父類物件時一樣,當需要依賴某個物件時,并不在意其內部是怎么實作的,而是在容器中注入相應的實作,既符合里式替換原則,又起到了解耦的作用,
- 開閉原則:開放擴展,封閉修改,當專案需求發生變更時,要盡可能的不去對原有的代碼進行修改,而在原有的基礎上進行擴展,
- 依賴倒置原則:高層模塊不應該直接依賴于底層模塊的具體實作,而應該依賴于底層的抽象,介面和抽象類不應該依賴于實作類,而實作類依賴介面或抽象類,
- 介面隔離原則:一個物件和另外一個物件互動的程序中,依賴的內容最小,也就是說在介面設計的時候,在遵循物件單一職責的情況下,盡量減少介面的內容,
簡潔版:
- 單一職責:物件設計要求獨立,不能設計萬能物件,
- 開閉原則:物件修改最小化,
- 里式替換:程式擴展中抽象被具體可以替換(介面、父類、可以被實作類物件、子類替換物件)
- 迪米特:高內聚,低耦合,盡量不要依賴細節,
- 依賴倒置:面向抽象編程,也就是引數傳遞,或者回傳值,可以使用父型別別或者介面型別,從廣義上講:基于介面編程,提前設計好介面框架,
- 介面隔離:介面設計大小要適中,過大導致污染,過小,導致呼叫麻煩,
陣列到底是不是物件?
先說說物件的概念,物件是根據某個類創建出來的一個實體,表示某類事物中一個具體的個體,
物件具有各種屬性,并且具有一些特定的行為,站在計算機的角度,物件就是記憶體中的一個記憶體塊,在這個記憶體塊封裝了一些資料,也就是類中定義的各個屬性,
所以,物件是用來封裝資料的,
java中的陣列具有java中其他物件的一些基本特點,比如封裝了一些資料,可以訪問屬性,也可以呼叫方法,
因此,可以說,陣列是物件,
也可以通過代碼驗證陣列是物件的事實,比如以下的代碼,輸出結果為java.lang.Object,
Class clz = int[].class;
System.out.println(clz.getSuperclass().getName());
由此,可以看出,陣列類的父類就是Object類,那么可以推斷出陣列就是物件,
Java的基本資料型別有哪些?
- byte,8bit
- char,16bit
- short,16bit
- int,32bit
- float,32bit
- long,64bit
- double,64bit
- boolean,只有兩個值:true、false,可以使?用 1 bit 來存盤
| 簡單型別 | boolean | byte | char | short | Int | long | float | double |
|---|---|---|---|---|---|---|---|---|
| 二進制位數 | 1 | 8 | 16 | 16 | 32 | 64 | 32 | 64 |
| 包裝類 | Boolean | Byte | Character | Short | Integer | Long | Float | Double |
在Java規范中,沒有明確指出boolean的大小,在《Java虛擬機規范》給出了單個boolean占4個位元組,和boolean陣列1個位元組的定義,具體 還要看虛擬機實作是否按照規范來,因此boolean占用1個位元組或者4個位元組都是有可能的,
為什么不能用浮點型表示金額?
由于計算機中保存的小數其實是十進制的小數的近似值,并不是準確值,所以,千萬不要在代碼中使用浮點數來表示金額等重要的指標,
建議使用BigDecimal或者Long來表示金額,
什么是值傳遞和參考傳遞?
- 值傳遞是對基本型變數而言的,傳遞的是該變數的一個副本,改變副本不影響原變數,
- 參考傳遞一般是對于物件型變數而言的,傳遞的是該物件地址的一個副本,并不是原物件本身,兩者指向同一片記憶體空間,所以對參考物件進行操作會同時改變原物件,
java中不存在參考傳遞,只有值傳遞,即不存在變數a指向變數b,變數b指向物件的這種情況,
了解Java的包裝型別嗎?為什么需要包裝類?
Java 是一種面向物件語言,很多地方都需要使用物件而不是基本資料型別,比如,在集合類中,我們是無法將 int 、double 等型別放進去的,因為集合的容器要求元素是 Object 型別,
為了讓基本型別也具有物件的特征,就出現了包裝型別,相當于將基本型別包裝起來,使得它具有了物件的性質,并且為其添加了屬性和方法,豐富了基本型別的操作,
給大家分享一個Github倉庫,上面有大彬整理的300多本經典的計算機書籍PDF,包括C語言、C++、Java、Python、前端、資料庫、作業系統、計算機網路、資料結構和演算法、機器學習、編程人生等,可以star一下,下次找書直接在上面搜索,倉庫持續更新中~
Github地址:https://github.com/Tyson0314/java-books
自動裝箱和拆箱
Java中基礎資料型別與它們對應的包裝類見下表:
| 原始型別 | 包裝型別 |
|---|---|
| boolean | Boolean |
| byte | Byte |
| char | Character |
| float | Float |
| int | Integer |
| long | Long |
| short | Short |
| double | Double |
裝箱:將基礎型別轉化為包裝型別,
拆箱:將包裝型別轉化為基礎型別,
當基礎型別與它們的包裝類有如下幾種情況時,編譯器會自動幫我們進行裝箱或拆箱:
- 賦值操作(裝箱或拆箱)
- 進行加減乘除混合運算 (拆箱)
- 進行>,<,==比較運算(拆箱)
- 呼叫equals進行比較(裝箱)
- ArrayList、HashMap等集合類添加基礎型別資料時(裝箱)
示例代碼:
Integer x = 1; // 裝箱 調? Integer.valueOf(1)
int y = x; // 拆箱 調?了 X.intValue()
下面看一道常見的面試題:
Integer a = 100;
Integer b = 100;
System.out.println(a == b);
Integer c = 200;
Integer d = 200;
System.out.println(c == d);
輸出:
true
false
為什么第三個輸出是false?看看 Integer 類的原始碼就知道啦,
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
Integer c = 200; 會呼叫 調?Integer.valueOf(200),而從Integer的valueOf()原始碼可以看到,這里的實作并不是簡單的new Integer,而是用IntegerCache做一個cache,
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
https://www.cnblogs.com/tyson03/p/sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
}
...
}
這是IntegerCache靜態代碼塊中的一段,默認Integer cache 的下限是-128,上限默認127,當賦值100給Integer時,剛好在這個范圍內,所以從cache中取對應的Integer并回傳,所以a和b回傳的是同一個物件,所以==比較是相等的,當賦值200給Integer時,不在cache 的范圍內,所以會new Integer并回傳,當然==比較的結果是不相等的,
String 為什么不可變?
先看看什么是不可變的物件,
如果一個物件,在它創建完成之后,不能再改變它的狀態,那么這個物件就是不可變的,不能改變狀態的意思是,不能改變物件內的成員變數,包括基本資料型別的值不能改變,參考型別的變數不能指向其他的物件,參考型別指向的物件的狀態也不能改變,
接著來看Java8 String類的原始碼:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
}
從原始碼可以看出,String物件其實在內部就是一個個字符,存盤在這個value陣列里面的,
value陣列用final修飾,final 修飾的變數,值不能被修改,因此value不可以指向其他物件,
String類內部所有的欄位都是私有的,也就是被private修飾,而且String沒有對外提供修改內部狀態的方法,因此value陣列不能改變,
所以,String是不可變的,
那為什么String要設計成不可變的?
主要有以下幾點原因:
- 執行緒安全,同一個字串實體可以被多個執行緒共享,因為字串不可變,本身就是執行緒安全的,
- 支持hash映射和快取,因為String的hash值經常會使用到,比如作為 Map 的鍵,不可變的特性使得 hash 值也不會變,不需要重新計算,
- 出于安全考慮,網路地址URL、檔案路徑path、密碼通常情況下都是以String型別保存,假若String不是固定不變的,將會引起各種安全隱患,比如將密碼用String的型別保存,那么它將一直留在記憶體中,直到垃圾收集器把它清除,假如String類不是固定不變的,那么這個密碼可能會被改變,導致出現安全隱患,
- 字串常量池優化,String物件創建之后,會快取到字串常量池中,下次需要創建同樣的物件時,可以直接回傳快取的參考,
既然我們的String是不可變的,它內部還有很多substring, replace, replaceAll這些操作的方法,這些方法好像會改變String物件?怎么解釋呢?
其實不是的,我們每次呼叫replace等方法,其實會在堆記憶體中創建了一個新的物件,然后其value陣列參考指向不同的物件,
為何JDK9要將String的底層實作由char[]改成byte[]?
主要是為了節約String占用的記憶體,
在大部分Java程式的堆記憶體中,String占用的空間最大,并且絕大多數String只有Latin-1字符,這些Latin-1字符只需要1個位元組就夠了,
而在JDK9之前,JVM因為String使用char陣列存盤,每個char占2個位元組,所以即使字串只需要1位元組,它也要按照2位元組進行分配,浪費了一半的記憶體空間,
到了JDK9之后,對于每個字串,會先判斷它是不是只有Latin-1字符,如果是,就按照1位元組的規格進行分配記憶體,如果不是,就按照2位元組的規格進行分配,這樣便提高了記憶體使用率,同時GC次數也會減少,提升效率,
不過Latin-1編碼集支持的字符有限,比如不支持中文字符,因此對于中文字串,用的是UTF16編碼(兩個位元組),所以用byte[]和char[]實作沒什么區別,
String, StringBuffer 和 StringBuilder區別
1. 可變性
- String 不可變
- StringBuffer 和 StringBuilder 可變
2. 執行緒安全
- String 不可變,因此是執行緒安全的
- StringBuilder 不是執行緒安全的
- StringBuffer 是執行緒安全的,內部使用 synchronized 進行同步
最全面的Java面試網站
什么是StringJoiner?
StringJoiner是 Java 8 新增的一個 API,它基于 StringBuilder 實作,用于實作對字串之間通過分隔符拼接的場景,
StringJoiner 有兩個構造方法,第一個構造要求依次傳入分隔符、前綴和后綴,第二個構造則只要求傳入分隔符即可(前綴和后綴默認為空字串),
StringJoiner(CharSequence delimiter, CharSequence prefix, CharSequence suffix)
StringJoiner(CharSequence delimiter)
有些字串拼接場景,使用 StringBuffer 或 StringBuilder 則顯得比較繁瑣,
比如下面的例子:
List<Integer> values = Arrays.asList(1, 3, 5);
StringBuilder sb = new StringBuilder("(");
for (int i = 0; i < values.size(); i++) {
sb.append(values.get(i));
if (i != values.size() -1) {
sb.append(",");
}
}
sb.append(")");
而通過StringJoiner來實作拼接List的各個元素,代碼看起來更加簡潔,
List<Integer> values = Arrays.asList(1, 3, 5);
StringJoiner sj = new StringJoiner(",", "(", ")");
for (Integer value : values) {
sj.add(value.toString());
}
另外,像平時經常使用的Collectors.joining(","),底層就是通過StringJoiner實作的,
原始碼如下:
public static Collector<CharSequence, ?, String> joining(
CharSequence delimiter,CharSequence prefix,CharSequence suffix) {
return new CollectorImpl<>(
() -> new StringJoiner(delimiter, prefix, suffix),
StringJoiner::add, StringJoiner::merge,
StringJoiner::toString, CH_NOID);
}
String 類的常用方法有哪些?
- indexOf():回傳指定字符的索引,
- charAt():回傳指定索引處的字符,
- replace():字串替換,
- trim():去除字串兩端空白,
- split():分割字串,回傳一個分割后的字串陣列,
- getBytes():回傳字串的 byte 型別陣列,
- length():回傳字串長度,
- toLowerCase():將字串轉成小寫字母,
- toUpperCase():將字串轉成大寫字符,
- substring():截取字串,
- equals():字串比較,
new String("dabin")會創建幾個物件?
使用這種方式會創建兩個字串物件(前提是字串常量池中沒有 "dabin" 這個字串物件),
- "dabin" 屬于字串字面量,因此編譯時期會在字串常量池中創建一個字串物件,指向這個 "dabin" 字串字面量;
- 使用 new 的方式會在堆中創建一個字串物件,
什么是字串常量池?
字串常量池(String Pool)保存著所有字串字面量,這些字面量在編譯時期就確定,字串常量池位于堆記憶體中,專門用來存盤字串常量,在創建字串時,JVM首先會檢查字串常量池,如果該字串已經存在池中,則回傳其參考,如果不存在,則創建此字串并放入池中,并回傳其參考,
String最大長度是多少?
String類提供了一個length方法,回傳值為int型別,而int的取值上限為2^31 -1,
所以理論上String的最大長度為2^31 -1,
達到這個長度的話需要多大的記憶體嗎?
String內部是使用一個char陣列來維護字符序列的,一個char占用兩個位元組,如果說String最大長度是2^31 -1的話,那么最大的字串占用記憶體空間約等于4GB,
也就是說,我們需要有大于4GB的JVM運行記憶體才行,
那String一般都存盤在JVM的哪塊區域呢?
字串在JVM中的存盤分兩種情況,一種是String物件,存盤在JVM的堆疊中,一種是字串常量,存盤在常量池里面,
什么情況下字串會存盤在常量池呢?
當通過字面量進行字串宣告時,比如String s = "程式新大彬";,這個字串在編譯之后會以常量的形式進入到常量池,
那常量池中的字串最大長度是2^31-1嗎?
不是的,常量池對String的長度是有另外限制的,,Java中的UTF-8編碼的Unicode字串在常量池中以CONSTANT_Utf8型別表示,
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}
length在這里就是代表字串的長度,length的型別是u2,u2是無符號的16位整數,也就是說最大長度可以做到2^16-1 即 65535,
不過javac編譯器做了限制,需要length < 65535,所以字串常量在常量池中的最大長度是65535 - 1 = 65534,
最后總結一下:
String在不同的狀態下,具有不同的長度限制,
- 字串常量長度不能超過65534
- 堆內字串的長度不超過2^31-1
Object常用方法有哪些?
Java面試經常會出現的一道題目,Object的常用方法,下面給大家整理一下,
Object常用方法有:toString()、equals()、hashCode()、clone()等,
toString
默認輸出物件地址,
public class Person {
private int age;
private String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
public static void main(String[] args) {
System.out.println(new Person(18, "程式員大彬").toString());
}
//output
//me.tyson.java.core.Person@4554617c
}
可以重寫toString方法,按照重寫邏輯輸出物件值,
public class Person {
private int age;
private String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public String toString() {
return name + ":" + age;
}
public static void main(String[] args) {
System.out.println(new Person(18, "程式員大彬").toString());
}
//output
//程式員大彬:18
}
equals
默認比較兩個參考變數是否指向同一個物件(記憶體地址),
public class Person {
private int age;
private String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
public static void main(String[] args) {
String name = "程式員大彬";
Person p1 = new Person(18, name);
Person p2 = new Person(18, name);
System.out.println(p1.equals(p2));
}
//output
//false
}
可以重寫equals方法,按照age和name是否相等來判斷:
public class Person {
private int age;
private String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (o instanceof Person) {
Person p = (Person) o;
return age == p.age && name.equals(p.name);
}
return false;
}
public static void main(String[] args) {
String name = "程式員大彬";
Person p1 = new Person(18, name);
Person p2 = new Person(18, name);
System.out.println(p1.equals(p2));
}
//output
//true
}
hashCode
將與物件相關的資訊映射成一個哈希值,默認的實作hashCode值是根據記憶體地址換算出來,
public class Cat {
public static void main(String[] args) {
System.out.println(new Cat().hashCode());
}
//out
//1349277854
}
clone
Java賦值是復制物件參考,如果我們想要得到一個物件的副本,使用賦值操作是無法達到目的的,Object物件有個clone()方法,實作了對
象中各個屬性的復制,但它的可見范圍是protected的,
protected native Object clone() throws CloneNotSupportedException;
所以物體類使用克隆的前提是:
- 實作Cloneable介面,這是一個標記介面,自身沒有方法,這應該是一種約定,呼叫clone方法時,會判斷有沒有實作Cloneable介面,沒有實作Cloneable的話會拋例外CloneNotSupportedException,
- 覆寫clone()方法,可見性提升為public,
public class Cat implements Cloneable {
private String name;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
public static void main(String[] args) throws CloneNotSupportedException {
Cat c = new Cat();
c.name = "程式員大彬";
Cat cloneCat = (Cat) c.clone();
c.name = "大彬";
System.out.println(cloneCat.name);
}
//output
//程式員大彬
}
getClass
回傳此 Object 的運行時類,常用于java反射機制,
public class Person {
private String name;
public Person(String name) {
this.name = name;
}
public static void main(String[] args) {
Person p = new Person("程式員大彬");
Class clz = p.getClass();
System.out.println(clz);
//獲取類名
System.out.println(clz.getName());
}
/**
* class com.tyson.basic.Person
* com.tyson.basic.Person
*/
}
wait
當前執行緒呼叫物件的wait()方法之后,當前執行緒會釋放物件鎖,進入等待狀態,等待其他執行緒呼叫此物件的notify()/notifyAll()喚醒或者等待超時時間wait(long timeout)自動喚醒,執行緒需要獲取obj物件鎖之后才能呼叫 obj.wait(),
notify
obj.notify()喚醒在此物件上等待的單個執行緒,選擇是任意性的,notifyAll()喚醒在此物件上等待的所有執行緒,
講講深拷貝和淺拷貝?
淺拷貝:拷?物件和原始物件的引?型別參考同?個物件,
以下例子,Cat物件里面有個Person物件,呼叫clone之后,克隆物件和原物件的Person參考的是同一個物件,這就是淺拷貝,
public class Cat implements Cloneable {
private String name;
private Person owner;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
public static void main(String[] args) throws CloneNotSupportedException {
Cat c = new Cat();
Person p = new Person(18, "程式員大彬");
c.owner = p;
Cat cloneCat = (Cat) c.clone();
p.setName("大彬");
System.out.println(cloneCat.owner.getName());
}
//output
//大彬
}
深拷貝:拷貝物件和原始物件的參考型別參考不同的物件,
以下例子,在clone函式中不僅呼叫了super.clone,而且呼叫Person物件的clone方法(Person也要實作Cloneable介面并重寫clone方法),從而實作了深拷貝,可以看到,拷貝物件的值不會受到原物件的影響,
public class Cat implements Cloneable {
private String name;
private Person owner;
@Override
protected Object clone() throws CloneNotSupportedException {
Cat c = null;
c = (Cat) super.clone();
c.owner = (Person) owner.clone();//拷貝Person物件
return c;
}
public static void main(String[] args) throws CloneNotSupportedException {
Cat c = new Cat();
Person p = new Person(18, "程式員大彬");
c.owner = p;
Cat cloneCat = (Cat) c.clone();
p.setName("大彬");
System.out.println(cloneCat.owner.getName());
}
//output
//程式員大彬
}
兩個物件的hashCode()相同,則 equals()是否也一定為 true?
equals與hashcode的關系:
- 如果兩個物件呼叫equals比較回傳true,那么它們的hashCode值一定要相同;
- 如果兩個物件的hashCode相同,它們并不一定相同,
hashcode方法主要是用來提升物件比較的效率,先進行hashcode()的比較,如果不相同,那就不必在進行equals的比較,這樣就大大減少了equals比較的次數,當比較物件的數量很大的時候能提升效率,
為什么重寫 equals 時一定要重寫 hashCode?
之所以重寫equals()要重寫hashcode(),是為了保證equals()方法回傳true的情況下hashcode值也要一致,如果重寫了equals()沒有重寫hashcode(),就會出現兩個物件相等但hashcode()不相等的情況,這樣,當用其中的一個物件作為鍵保存到hashMap、hashTable或hashSet中,再以另一個物件作為鍵值去查找他們的時候,則會查找不到,
Java創建物件有幾種方式?
Java創建物件有以下幾種方式:
- 用new陳述句創建物件,
- 使用反射,使用Class.newInstance()創建物件,
- 呼叫物件的clone()方法,
- 運用反序列化手段,呼叫java.io.ObjectInputStream物件的readObject()方法,
說說類實體化的順序
Java中類實體化順序:
- 靜態屬性,靜態代碼塊,
- 普通屬性,普通代碼塊,
- 構造方法,
public class LifeCycle {
// 靜態屬性
private static String staticField = getStaticField();
// 靜態代碼塊
static {
System.out.println(staticField);
System.out.println("靜態代碼塊初始化");
}
// 普通屬性
private String field = getField();
// 普通代碼塊
{
System.out.println(field);
System.out.println("普通代碼塊初始化");
}
// 構造方法
public LifeCycle() {
System.out.println("構造方法初始化");
}
// 靜態方法
public static String getStaticField() {
String statiFiled = "靜態屬性初始化";
return statiFiled;
}
// 普通方法
public String getField() {
String filed = "普通屬性初始化";
return filed;
}
public static void main(String[] argc) {
new LifeCycle();
}
/**
* 靜態屬性初始化
* 靜態代碼塊初始化
* 普通屬性初始化
* 普通代碼塊初始化
* 構造方法初始化
*/
}
equals和==有什么區別?
-
對于基本資料型別,==比較的是他們的值,基本資料型別沒有equal方法;
-
對于復合資料型別,==比較的是它們的存放地址(是否是同一個物件),
equals()默認比較地址值,重寫的話按照重寫邏輯去比較,
常見的關鍵字有哪些?
static
static可以用來修飾類的成員方法、類的成員變數,
static變數也稱作靜態變數,靜態變數和非靜態變數的區別是:靜態變數被所有的物件所共享,在記憶體中只有一個副本,它當且僅當在類初次加載時會被初始化,而非靜態變數是物件所擁有的,在創建物件的時候被初始化,存在多個副本,各個物件擁有的副本互不影響,
以下例子,age為非靜態變數,則p1列印結果是:Name:zhangsan, Age:10;若age使用static修飾,則p1列印結果是:Name:zhangsan, Age:12,因為static變數在記憶體只有一個副本,
public class Person {
String name;
int age;
public String toString() {
return "Name:" + name + ", Age:" + age;
}
public static void main(String[] args) {
Person p1 = new Person();
p1.name = "zhangsan";
p1.age = 10;
Person p2 = new Person();
p2.name = "lisi";
p2.age = 12;
System.out.println(p1);
System.out.println(p2);
}
/**Output
* Name:zhangsan, Age:10
* Name:lisi, Age:12
*///~
}
static方法一般稱作靜態方法,靜態方法不依賴于任何物件就可以進行訪問,通過類名即可呼叫靜態方法,
public class Utils {
public static void print(String s) {
System.out.println("hello world: " + s);
}
public static void main(String[] args) {
Utils.print("程式員大彬");
}
}
靜態代碼塊只會在類加載的時候執行一次,以下例子,startDate和endDate在類加載的時候進行賦值,
class Person {
private Date birthDate;
private static Date startDate, endDate;
static{
startDate = Date.valueOf("2008");
endDate = Date.valueOf("2021");
}
public Person(Date birthDate) {
this.birthDate = birthDate;
}
}
靜態內部類
在靜態方法里,使用?靜態內部類依賴于外部類的實體,也就是說需要先創建外部類實體,才能用這個實體去創建非靜態內部類,?靜態內部類不需要,
public class OuterClass {
class InnerClass {
}
static class StaticInnerClass {
}
public static void main(String[] args) {
// 在靜態方法里,不能直接使用OuterClass.this去創建InnerClass的實體
// 需要先創建OuterClass的實體o,然后通過o創建InnerClass的實體
// InnerClass innerClass = new InnerClass();
OuterClass outerClass = new OuterClass();
InnerClass innerClass = outerClass.new InnerClass();
StaticInnerClass staticInnerClass = new StaticInnerClass();
outerClass.test();
}
public void nonStaticMethod() {
InnerClass innerClass = new InnerClass();
System.out.println("nonStaticMethod...");
}
}
final
-
基本資料型別用final修飾,則不能修改,是常量;物件參考用final修飾,則參考只能指向該物件,不能指向別的物件,但是物件本身可以修改,
-
final修飾的方法不能被子類重寫
-
final修飾的類不能被繼承,
this
this.屬性名稱指訪問類中的成員變數,可以用來區分成員變數和區域變數,如下代碼所示,this.name訪問類Person當前實體的變數,
/**
* @description:
* @author: 程式員大彬
* @time: 2021-08-17 00:29
*/
public class Person {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
this.方法名稱用來訪問本類的方法,以下代碼中,this.born()呼叫類 Person 的當前實體的方法,
/**
* @description:
* @author: 程式員大彬
* @time: 2021-08-17 00:29
*/
public class Person {
String name;
int age;
public Person(String name, int age) {
this.born();
this.name = name;
this.age = age;
}
void born() {
}
}
super
super 關鍵字用于在子類中訪問父類的變數和方法,
class A {
protected String name = "大彬";
public void getName() {
System.out.println("父類:" + name);
}
}
public class B extends A {
@Override
public void getName() {
System.out.println(super.name);
super.getName();
}
public static void main(String[] args) {
B b = new B();
b.getName();
}
/**
* 大彬
* 父類:大彬
*/
}
在子類B中,我們重寫了父類的getName()方法,如果在重寫的getName()方法中我們要呼叫父類的相同方法,必須要通過super關鍵字顯式指出,
final, finally, finalize 的區別
- final 用于修飾屬性、方法和類, 分別表示屬性不能被重新賦值,方法不可被覆寫,類不可被繼承,
- finally 是例外處理陳述句結構的一部分,一般以
try-catch-finally出現,finally代碼塊表示總是被執行, - finalize 是Object類的一個方法,該方法一般由垃圾回收器來呼叫,當我們呼叫
System.gc()方法的時候,由垃圾回收器呼叫finalize()方法,回收垃圾,JVM并不保證此方法總被呼叫,
final關鍵字的作用?
- final 修飾的類不能被繼承,
- final 修飾的方法不能被重寫,
- final 修飾的變數叫常量,常量必須初始化,初始化之后值就不能被修改,
方法多載和重寫的區別?
同個類中的多個方法可以有相同的方法名稱,但是有不同的引數串列,這就稱為方法多載,引數串列又叫引數簽名,包括引數的型別、引數的個數、引數的順序,只要有一個不同就叫做引數串列不同,
多載是面向物件的一個基本特性,
public class OverrideTest {
void setPerson() { }
void setPerson(String name) {
//set name
}
void setPerson(String name, int age) {
//set name and age
}
}
方法的重寫描述的是父類和子類之間的,當父類的功能無法滿足子類的需求,可以在子類對方法進行重寫,方法重寫時, 方法名與形參串列必須一致,
如下代碼,Person為父類,Student為子類,在Student中重寫了dailyTask方法,
public class Person {
private String name;
public void dailyTask() {
System.out.println("work eat sleep");
}
}
public class Student extends Person {
@Override
public void dailyTask() {
System.out.println("study eat sleep");
}
}
介面與抽象類區別?
1、語法層面上的區別
- 抽象類可以有方法實作,而介面的方法中只能是抽象方法(Java 8 之后介面方法可以有默認實作);
- 抽象類中的成員變數可以是各種型別的,介面中的成員變數只能是public static final型別;
- 介面中不能含有靜態代碼塊以及靜態方法,而抽象類可以有靜態代碼塊和靜態方法(Java 8之后介面可以有靜態方法);
- 一個類只能繼承一個抽象類,而一個類卻可以實作多個介面,
2、設計層面上的區別
- 抽象層次不同,抽象類是對整個類整體進行抽象,包括屬性、行為,但是介面只是對類行為進行抽象,繼承抽象類是一種"是不是"的關系,而介面實作則是 "有沒有"的關系,如果一個類繼承了某個抽象類,則子類必定是抽象類的種類,而介面實作則是具備不具備的關系,比如鳥是否能飛,
- 繼承抽象類的是具有相似特點的類,而實作介面的卻可以不同的類,
門和警報的例子:
class AlarmDoor extends Door implements Alarm {
//code
}
class BMWCar extends Car implements Alarm {
//code
}
常見的Exception有哪些?
常見的RuntimeException:
ClassCastException//型別轉換例外IndexOutOfBoundsException//陣列越界例外NullPointerException//空指標ArrayStoreException//陣列存盤例外NumberFormatException//數字格式化例外ArithmeticException//數學運算例外
checked Exception:
NoSuchFieldException//反射例外,沒有對應的欄位ClassNotFoundException//類沒有找到例外IllegalAccessException//安全權限例外,可能是反射時呼叫了private方法
Error和Exception的區別?
Error:JVM 無法解決的嚴重問題,如堆疊溢位StackOverflowError、記憶體溢位OOM等,程式無法處理的錯誤,
Exception:其它因編程錯誤或偶然的外在因素導致的一般性問題,可以在代碼中進行處理,如:空指標例外、陣列下標越界等,
運行時例外和非運行時例外(checked)的區別?
unchecked exception包括RuntimeException和Error類,其他所有例外稱為檢查(checked)例外,
RuntimeException由程式錯誤導致,應該修正程式避免這類例外發生,checked Exception由具體的環境(讀取的檔案不存在或檔案為慷訓sql例外)導致的例外,必須進行處理,不然編譯不通過,可以catch或者throws,
throw和throws的區別?
-
throw:用于拋出一個具體的例外物件,
-
throws:用在方法簽名中,用于宣告該方法可能拋出的例外,子類方法拋出的例外范圍更加小,或者根本不拋例外,
通過故事講清楚NIO
下面通過一個例子來講解下,
假設某銀行只有10個職員,該銀行的業務流程分為以下4個步驟:
1) 顧客填申請表(5分鐘);
2) 職員審核(1分鐘);
3) 職員叫保安去金庫取錢(3分鐘);
4) 職員列印票據,并將錢和票據回傳給顧客(1分鐘),
下面我們看看銀行不同的作業方式對其作業效率到底有何影響,
首先是BIO方式,
每來一個顧客,馬上由一位職員來接待處理,并且這個職員需要負責以上4個完整流程,當超過10個顧客時,剩余的顧客需要排隊等候,
一個職員處理一個顧客需要10分鐘(5+1+3+1)時間,一個小時(60分鐘)能處理6個顧客,一共10個職員,那就是只能處理60個顧客,
可以看到銀行職員的作業狀態并不飽和,比如在第1步,其實是處于等待中,
這種作業其實就是BIO,每次來一個請求(顧客),就分配到執行緒池中由一個執行緒(職員)處理,如果超出了執行緒池的最大上限(10個),就扔到佇列等待 ,
那么如何提高銀行的吞吐量呢?
思路就是:分而治之,將任務拆分開來,由專門的人負責專門的任務,
具體來講,銀行專門指派一名職員A,A的作業就是每當有顧客到銀行,他就遞上表格讓顧客填寫,每當有顧客填好表后,A就將其隨機指派給剩余的9名職員完成后續步驟,
這種方式下,假設顧客非常多,職員A的作業處于飽和中,他不斷的將填好表的顧客帶到柜臺處理,
柜臺一個職員5分鐘能處理完一個顧客,一個小時9名職員能處理:9*(60/5)=108,
可見作業方式的轉變能帶來效率的極大提升,
這種作業方式其實就NIO的思路,
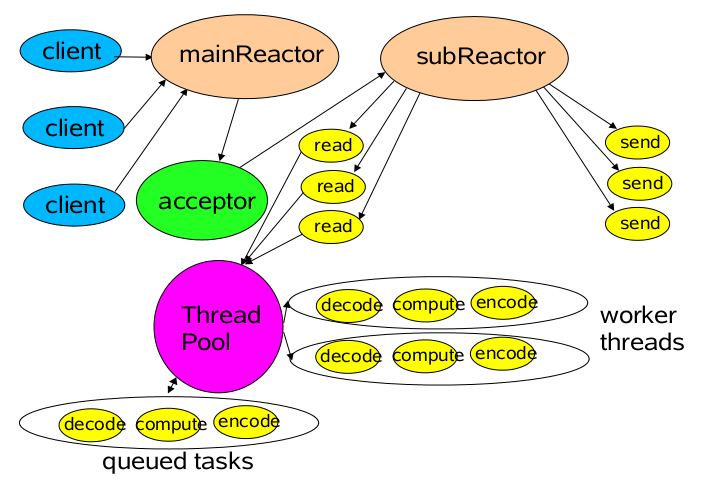
下圖是非常經典的NIO說明圖,mainReactor執行緒負責監聽server socket,接收新連接,并將建立的socket分派給subReactor
subReactor可以是一個執行緒,也可以是執行緒池,負責多路分離已連接的socket,讀寫網路資料,這里的讀寫網路資料可類比顧客填表這一耗時動作,對具體的業務處理功能,其扔給worker執行緒池完成
可以看到典型NIO有三類執行緒,分別是mainReactor執行緒、subReactor執行緒、work執行緒,
不同的執行緒干專業的事情,最終每個執行緒都沒空著,系統的吞吐量自然就上去了,
那這個流程還有沒有什么可以提高的地方呢?
可以看到,在這個業務流程里邊第3個步驟,職員叫保安去金庫取錢(3分鐘),這3分鐘柜臺職員是在等待中度過的,可以把這3分鐘利用起來,
還是分而治之的思路,指派1個職員B來專門負責第3步驟,
每當柜臺員工完成第2步時,就通知職員B來負責與保安溝通取錢,這時候柜臺員工可以繼續處理下一個顧客,
當職員B拿到錢之后,通知顧客錢已經到柜臺了,讓顧客重新排隊處理,當柜臺職員再次服務該顧客時,發現該顧客前3步已經完成,直接執行第4步即可,
在當今web服務中,經常需要通過RPC或者Http等方式呼叫第三方服務,這里對應的就是第3步,如果這步耗時較長,通過異步方式將能極大降低資源使用率,
NIO+異步的方式能讓少量的執行緒做大量的事情,這適用于很多應用場景,比如代理服務、api服務、長連接服務等等,這些應用如果用同步方式將耗費大量機器資源,
不過雖然NIO+異步能提高系統吞吐量,但其并不能讓一個請求的等待時間下降,相反可能會增加等待時間,
最后,NIO基本思想總結起來就是:分而治之,將任務拆分開來,由專門的人負責專門的任務
BIO/NIO/AIO區別的區別?
同步阻塞IO : 用戶行程發起一個IO操作以后,必須等待IO操作的真正完成后,才能繼續運行,
同步非阻塞IO: 客戶端與服務器通過Channel連接,采用多路復用器輪詢注冊的Channel,提高吞吐量和可靠性,用戶行程發起一個IO操作以后,可做其它事情,但用戶行程需要輪詢IO操作是否完成,這樣造成不必要的CPU資源浪費,
異步非阻塞IO: 非阻塞異步通信模式,NIO的升級版,采用異步通道實作異步通信,其read和write方法均是異步方法,用戶行程發起一個IO操作,然后立即回傳,等IO操作真正的完成以后,應用程式會得到IO操作完成的通知,類似Future模式,
守護執行緒是什么?
- 守護執行緒是運行在后臺的一種特殊行程,
- 它獨立于控制終端并且周期性地執行某種任務或等待處理某些發生的事件,
- 在 Java 中垃圾回收執行緒就是特殊的守護執行緒,
Java支持多繼承嗎?
java中,類不支持多繼承,介面才支持多繼承,介面的作用是拓展物件功能,當一個子介面繼承了多個父介面時,說明子介面拓展了多個功能,當一個類實作該介面時,就拓展了多個的功能,
Java不支持多繼承的原因:
- 出于安全性的考慮,如果子類繼承的多個父類里面有相同的方法或者屬性,子類將不知道具體要繼承哪個,
- Java提供了介面和內部類以達到實作多繼承功能,彌補單繼承的缺陷,
如何實作物件克隆?
- 實作
Cloneable介面,重寫clone()方法,這種方式是淺拷貝,即如果類中屬性有自定義參考型別,只拷貝參考,不拷貝參考指向的物件,如果物件的屬性的Class也實作Cloneable介面,那么在克隆物件時也會克隆屬性,即深拷貝, - 結合序列化,深拷貝,
- 通過
org.apache.commons中的工具類BeanUtils和PropertyUtils進行物件復制,
同步和異步的區別?
同步:發出一個呼叫時,在沒有得到結果之前,該呼叫就不回傳,
異步:在呼叫發出后,被呼叫者回傳結果之后會通知呼叫者,或通過回呼函式處理這個呼叫,
阻塞和非阻塞的區別?
阻塞和非阻塞關注的是執行緒的狀態,
阻塞呼叫是指呼叫結果回傳之前,當前執行緒會被掛起,呼叫執行緒只有在得到結果之后才會恢復運行,
非阻塞呼叫指在不能立刻得到結果之前,該呼叫不會阻塞當前執行緒,
舉個例子,理解下同步、阻塞、異步、非阻塞的區別:
同步就是燒開水,要自己來看開沒開;異步就是水開了,然后水壺響了通知你水開了(回呼通知),阻塞是燒開水的程序中,你不能干其他事情,必須在旁邊等著;非阻塞是燒開水的程序里可以干其他事情,
Java8的新特性有哪些?
- Lambda 運算式:Lambda允許把函式作為一個方法的引數
- Stream API :新添加的Stream API(java.util.stream) 把真正的函式式編程風格引入到Java中
- 默認方法:默認方法就是一個在介面里面有了一個實作的方法,
- Optional 類 :Optional 類已經成為 Java 8 類別庫的一部分,用來解決空指標例外,
- Date Time API :加強對日期與時間的處理,
Java8 新特性總結
序列化和反序列化
- 序列化:把物件轉換為位元組序列的程序稱為物件的序列化.
- 反序列化:把位元組序列恢復為物件的程序稱為物件的反序列化.
什么時候需要用到序列化和反序列化呢?
當我們只在本地 JVM 里運行下 Java 實體,這個時候是不需要什么序列化和反序列化的,但當我們需要將記憶體中的物件持久化到磁盤,資料庫中時,當我們需要與瀏覽器進行互動時,當我們需要實作 RPC 時,這個時候就需要序列化和反序列化了.
前兩個需要用到序列化和反序列化的場景,是不是讓我們有一個很大的疑問? 我們在與瀏覽器互動時,還有將記憶體中的物件持久化到資料庫中時,好像都沒有去進行序列化和反序列化,因為我們都沒有實作 Serializable 介面,但一直正常運行.
下面先給出結論:
只要我們對記憶體中的物件進行持久化或網路傳輸,這個時候都需要序列化和反序列化.
理由:
服務器與瀏覽器互動時真的沒有用到 Serializable 介面嗎? JSON 格式實際上就是將一個物件轉化為字串,所以服務器與瀏覽器互動時的資料格式其實是字串,我們來看來 String 型別的原始碼:
public final class String
implements java.io.Serializable,Comparable<String>,CharSequence {
/\*\* The value is used for character storage. \*/
private final char value\[\];
/\*\* Cache the hash code for the string \*/
private int hash; // Default to 0
/\*\* use serialVersionUID from JDK 1.0.2 for interoperability \*/
private static final long serialVersionUID = -6849794470754667710L;
......
}
String 型別實作了 Serializable 介面,并顯示指定 serialVersionUID 的值.
然后我們再來看物件持久化到資料庫中時的情況,Mybatis 資料庫映射檔案里的 insert 代碼:
<insert id="insertUser" parameterType="org.tyshawn.bean.User">
INSERT INTO t\_user(name,age) VALUES (#{name},#{age})
</insert>
實際上我們并不是將整個物件持久化到資料庫中,而是將物件中的屬性持久化到資料庫中,而這些屬性(如Date/String)都實作了 Serializable 介面,
實作序列化和反序列化為什么要實作 Serializable 介面?
在 Java 中實作了 Serializable 介面后, JVM 在類加載的時候就會發現我們實作了這個介面,然后在初始化實體物件的時候就會在底層幫我們實作序列化和反序列化,
如果被寫物件型別不是String、陣列、Enum,并且沒有實作Serializable介面,那么在進行序列化的時候,將拋出NotSerializableException,原始碼如下:
// remaining cases
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
實作 Serializable 介面之后,為什么還要顯示指定 serialVersionUID 的值?
如果不顯示指定 serialVersionUID,JVM 在序列化時會根據屬性自動生成一個 serialVersionUID,然后與屬性一起序列化,再進行持久化或網路傳輸. 在反序列化時,JVM 會再根據屬性自動生成一個新版 serialVersionUID,然后將這個新版 serialVersionUID 與序列化時生成的舊版 serialVersionUID 進行比較,如果相同則反序列化成功,否則報錯.
如果顯示指定了 serialVersionUID,JVM 在序列化和反序列化時仍然都會生成一個 serialVersionUID,但值為我們顯示指定的值,這樣在反序列化時新舊版本的 serialVersionUID 就一致了.
如果我們的類寫完后不再修改,那么不指定serialVersionUID,不會有問題,但這在實際開發中是不可能的,我們的類會不斷迭代,一旦類被修改了,那舊物件反序列化就會報錯, 所以在實際開發中,我們都會顯示指定一個 serialVersionUID,
static 屬性為什么不會被序列化?
因為序列化是針對物件而言的,而 static 屬性優先于物件存在,隨著類的加載而加載,所以不會被序列化.
看到這個結論,是不是有人會問,serialVersionUID 也被 static 修飾,為什么 serialVersionUID 會被序列化? 其實 serialVersionUID 屬性并沒有被序列化,JVM 在序列化物件時會自動生成一個 serialVersionUID,然后將我們顯示指定的 serialVersionUID 屬性值賦給自動生成的 serialVersionUID.
transient關鍵字的作用?
Java語言的關鍵字,變數修飾符,如果用transient宣告一個實體變數,當物件存盤時,它的值不需要維持,
也就是說被transient修飾的成員變數,在序列化的時候其值會被忽略,在被反序列化后, transient 變數的值被設為初始值, 如 int 型的是 0,物件型的是 null,
什么是反射?
動態獲取的資訊以及動態呼叫物件的方法的功能稱為Java語言的反射機制,
在運行狀態中,對于任意一個類,能夠知道這個類的所有屬性和方法,對于任意一個物件,能夠呼叫它的任意一個方法和屬性,
反射有哪些應用場景呢?
- JDBC連接資料庫時使用
Class.forName()通過反射加載資料庫的驅動程式 - Eclispe、IDEA等開發工具利用反射動態決議物件的型別與結構,動態提示物件的屬性和方法
- Web服務器中利用反射呼叫了Sevlet的
service方法 - JDK動態代理底層依賴反射實作
講講什么是泛型?
Java泛型是JDK 5中引?的?個新特性, 允許在定義類和介面的時候使?型別引數,宣告的型別引數在使?時?具體的型別來替換,
泛型最?的好處是可以提?代碼的復?性,以List介面為例,我們可以將String、 Integer等型別放?List中, 如不?泛型, 存放String型別要寫?個List介面, 存放Integer要寫另外?個List介面, 泛型可以很好的解決這個問題,
如何停止一個正在運行的執行緒?
有幾種方式,
1、使用執行緒的stop方法,
使用stop()方法可以強制終止執行緒,不過stop是一個被廢棄掉的方法,不推薦使用,
使用Stop方法,會一直向上傳播ThreadDeath例外,從而使得目標執行緒解鎖所有鎖住的監視器,即釋放掉所有的物件鎖,使得之前被鎖住的物件得不到同步的處理,因此可能會造成資料不一致的問題,
2、使用interrupt方法中斷執行緒,該方法只是告訴執行緒要終止,但最終何時終止取決于計算機,呼叫interrupt方法僅僅是在當前執行緒中打了一個停止的標記,并不是真的停止執行緒,
接著呼叫 Thread.currentThread().isInterrupted()方法,可以用來判斷當前執行緒是否被終止,通過這個判斷我們可以做一些業務邏輯處理,通常如果isInterrupted回傳true的話,會拋一個中斷例外,然后通過try-catch捕獲,
3、設定標志位
設定標志位,當標識位為某個值時,使執行緒正常退出,設定標志位是用到了共享變數的方式,為了保證共享變數在記憶體中的可見性,可以使用volatile修飾它,這樣的話,變數取值始侄訓從主存中獲取最新值,
但是這種volatile標記共享變數的方式,在執行緒發生阻塞時是無法完成回應的,比如呼叫Thread.sleep() 方法之后,執行緒處于不可運行狀態,即便是主執行緒修改了共享變數的值,該執行緒此時根本無法檢查回圈標志,所以也就無法實作執行緒中斷,
因此,interrupt() 加上手動拋例外的方式是目前中斷一個正在運行的執行緒最為正確的方式了,
什么是跨域?
簡單來講,跨域是指從一個域名的網頁去請求另一個域名的資源,由于有同源策略的關系,一般是不允許這么直接訪問的,但是,很多場景經常會有跨域訪問的需求,比如,在前后端分離的模式下,前后端的域名是不一致的,此時就會發生跨域問題,
那什么是同源策略呢?
所謂同源是指"協議+域名+埠"三者相同,即便兩個不同的域名指向同一個ip地址,也非同源,
同源策略限制以下幾種行為:
1. Cookie、LocalStorage 和 IndexDB 無法讀取
2. DOM 和 Js物件無法獲得
3. AJAX 請求不能發送
為什么要有同源策略?
舉個例子,假如你剛剛在網銀輸入賬號密碼,查看了自己的余額,然后再去訪問其他帶顏色的網站,這個網站可以訪問剛剛的網銀站點,并且獲取賬號密碼,那后果可想而知,因此,從安全的角度來講,同源策略是有利于保護網站資訊的,
跨域問題怎么解決呢?
嗯,有以下幾種方法:
CORS,跨域資源共享
CORS(Cross-origin resource sharing),跨域資源共享,CORS 其實是瀏覽器制定的一個規范,瀏覽器會自動進行 CORS 通信,它的實作主要在服務端,通過一些 HTTP Header 來限制可以訪問的域,例如頁面 A 需要訪問 B 服務器上的資料,如果 B 服務器 上宣告了允許 A 的域名訪問,那么從 A 到 B 的跨域請求就可以完成,
@CrossOrigin注解
如果專案使用的是Springboot,可以在Controller類上添加一個 @CrossOrigin(origins ="*") 注解就可以實作對當前controller 的跨域訪問了,當然這個標簽也可以加到方法上,或者直接加到入口類上對所有介面進行跨域處理,注意SpringMVC的版本要在4.2或以上版本才支持@CrossOrigin,
nginx反向代理介面跨域
nginx反向代理跨域原理如下: 首先同源策略是瀏覽器的安全策略,不是HTTP協議的一部分,服務器端呼叫HTTP介面只是使用HTTP協議,不會執行JS腳本,不需要同源策略,也就不存在跨越問題,
nginx反向代理介面跨域實作思路如下:通過nginx配置一個代理服務器(域名與domain1相同,埠不同)做跳板機,反向代理訪問domain2介面,并且可以順便修改cookie中domain資訊,方便當前域cookie寫入,實作跨域登錄,
// proxy服務器
server {
listen 81;
server_name www.domain1.com;
location / {
proxy_pass http://www.domain2.com:8080; #反向代理
proxy_cookie_domain www.domain2.com www.domain1.com; #修改cookie里域名
index index.html index.htm;
add_header Access-Control-Allow-Origin http://www.domain1.com;
}
}
這樣我們的前端代理只要訪問 http:www.domain1.com:81/*就可以了,
通過jsonp跨域
通常為了減輕web服務器的負載,我們把js、css,img等靜態資源分離到另一臺獨立域名的服務器上,在html頁面中再通過相應的標簽從不同域名下加載靜態資源,這是瀏覽器允許的操作,基于此原理,我們可以通過動態創建script,再請求一個帶參網址實作跨域通信,
設計介面要注意什么?
- 介面引數校驗,介面必須校驗引數,比如入參是否允許為空,入參長度是否符合預期,
- 設計介面時,充分考慮介面的可擴展性,思考介面是否可以復用,怎樣保持介面的可擴展性,
- 串行呼叫考慮改并行呼叫,比如設計一個商城首頁介面,需要查商品資訊、營銷資訊、用戶資訊等等,如果是串行一個一個查,那耗時就比較大了,這種場景是可以改為并行呼叫的,降低介面耗時,
- 介面是否需要防重處理,涉及到資料庫修改的,要考慮防重處理,可以使用資料庫防重表,以唯一流水號作為唯一索引,
- 日志列印全面,入參出參,介面耗時,記錄好日志,方便甩鍋,
- 修改舊介面時,注意兼容性設計,
- 例外處理得當,使用finally關閉流資源、使用log列印而不是e.printStackTrace()、不要吞例外等等
- 是否需要考慮限流,限流為了保護系統,防止流量洪峰超過系統的承載能力,
過濾器和攔截器有什么區別?
1、實作原理不同,
過濾器和攔截器底層實作不同,過濾器是基于函式回呼的,攔截器是基于Java的反射機制(動態代理)實作的,一般自定義的過濾器中都會實作一個doFilter()方法,這個方法有一個FilterChain引數,而實際上它是一個回呼介面,
2、使用范圍不同,
過濾器實作的是 javax.servlet.Filter 介面,而這個介面是在Servlet規范中定義的,也就是說過濾器Filter的使用要依賴于Tomcat等容器,導致它只能在web程式中使用,而攔截器是一個Spring組件,并由Spring容器管理,并不依賴Tomcat等容器,是可以單獨使用的,攔截器不僅能應用在web程式中,也可以用于Application、Swing等程式中,
3、使用的場景不同,
因為攔截器更接近業務系統,所以攔截器主要用來實作專案中的業務判斷的,比如:日志記錄、權限判斷等業務,而過濾器通常是用來實作通用功能過濾的,比如:敏感詞過濾、回應資料壓縮等功能,
4、觸發時機不同,
過濾器Filter是在請求進入容器后,但在進入servlet之前進行預處理,請求結束是在servlet處理完以后,
攔截器 Interceptor 是在請求進入servlet后,在進入Controller之前進行預處理的,Controller 中渲染了對應的視圖之后請求結束,
5、攔截的請求范圍不同,
請求的執行順序是:請求進入容器 -> 進入過濾器 -> 進入 Servlet -> 進入攔截器 -> 執行控制器,可以看到過濾器和攔截器的執行時機也是不同的,過濾器會先執行,然后才會執行攔截器,最后才會進入真正的要呼叫的方法,
參考鏈接:https://segmentfault.com/a/1190000022833940
對接第三方介面要考慮什么?
嗯,需要考慮以下幾點:
- 確認介面對接的網路協議,是https/http或者自定義的私有協議等,
- 約定好資料傳參、回應格式(如application/json),弱型別對接強型別語言時要特別注意
- 介面安全方面,要確定身份校驗方式,使用token、證書校驗等
- 確認是否需要介面呼叫失敗后的重試機制,保證資料傳輸的最終一致性,
- 日志記錄要全面,介面出入引數,以及決議之后的引數值,都要用日志記錄下來,方便定位問題(甩鍋),
參考:https://blog.csdn.net/gzt19881123/article/details/108791034
后端介面性能優化有哪些方法?
有以下這些方法:
1、優化索引,給where條件的關鍵欄位,或者order by后面的排序欄位,加索引,
2、優化sql陳述句,比如避免使用select *、批量操作、避免深分頁、提升group by的效率等
3、避免大事務,使用@Transactional注解這種宣告式事務的方式提供事務功能,容易造成大事務,引發其他的問題,應該避免在事務中一次性處理太多資料,將一些跟事務無關的邏輯放到事務外面執行,
4、異步處理,剝離主邏輯和副邏輯,副邏輯可以異步執行,異步寫庫,比如用戶購買的商品發貨了,需要發短信通知,短信通知是副流程,可以異步執行,以免影響主流程的執行,
5、降低鎖粒度,在并發場景下,多個執行緒同時修改資料,造成資料不一致的情況,這種情況下,一般會加鎖解決,但如果鎖加得不好,導致鎖的粒度太粗,也會非常影響介面性能,
6、加快取,如果表資料量非常大的話,直接從資料庫查詢資料,性能會非常差,可以使用Redis和memcached提升查詢性能,從而提高介面性能,
7、分庫分表,當系統發展到一定的階段,用戶并發量大,會有大量的資料庫請求,需要占用大量的資料庫連接,同時會帶來磁盤IO的性能瓶頸問題,或者資料庫表資料非常大,SQL查詢即使走了索引,也很耗時,這時,可以通過分庫分表解決,分庫用于解決資料庫連接資源不足問題,和磁盤IO的性能瓶頸問題,分表用于解決單表資料量太大,sql陳述句查詢資料時,即使走了索引也非常耗時問題,
8、避免在回圈中查詢資料庫,回圈查詢資料庫,非常耗時,最好能在一次查詢中獲取所有需要的資料,
為什么在阿里巴巴Java開發手冊中強制要求使用包裝型別定義屬性呢?
嗯,以布爾欄位為例,當我們沒有設定物件的欄位的值的時候,Boolean型別的變數會設定默認值為null,而boolean型別的變數會設定默認值為false,
也就是說,包裝型別的默認值都是null,而基本資料型別的默認值是一個固定值,如boolean是false,byte、short、int、long是0,float是0.0f等,
舉一個例子,比如有一個扣費系統,扣費時需要從外部的定價系統中讀取一個費率的值,我們預期該介面的回傳值中會包含一個浮點型的費率欄位,當我們取到這個值得時候就使用公式:金額*費率=費用 進行計算,計算結果進行劃扣,
如果由于計費系統例外,他可能會回傳個默認值,如果這個欄位是Double型別的話,該默認值為null,如果該欄位是double型別的話,該默認值為0.0,
如果扣費系統對于該費率回傳值沒做特殊處理的話,拿到null值進行計算會直接報錯,阻斷程式,拿到0.0可能就直接進行計算,得出介面為0后進行扣費了,這種例外情況就無法被感知,
那我可以對0.0做特殊判斷,如果是0就阻斷報錯,這樣是否可以呢?
不對,這時候就會產生一個問題,如果允許費率是0的場景又怎么處理呢?
使用基本資料型別只會讓方案越來越復雜,坑越來越多,
這種使用包裝型別定義變數的方式,通過例外來阻斷程式,進而可以被識別到這種線上問題,如果使用基本資料型別的話,系統可能不會報錯,進而認為無例外,
因此,建議在POJO和RPC的回傳值中使用包裝型別,
8招讓介面性能提升100倍
池化思想
如果你每次需要用到執行緒,都去創建,就會有增加一定的耗時,而執行緒池可以重復利用執行緒,避免不必要的耗時,
比如TCP三次握手,它為了減少性能損耗,引入了Keep-Alive長連接,避免頻繁的創建和銷毀連接,
拒絕阻塞等待
如果你呼叫一個系統B的介面,但是它處理業務邏輯,耗時需要10s甚至更多,然后你是一直阻塞等待,直到系統B的下游介面回傳,再繼續你的下一步操作嗎?這樣顯然不合理,
參考IO多路復用模型,即我們不用阻塞等待系統B的介面,而是先去做別的操作,等系統B的介面處理完,通過事件回呼通知,我們介面收到通知再進行對應的業務操作即可,
遠程呼叫由串行改為并行
比如設計一個商城首頁介面,需要查商品資訊、營銷資訊、用戶資訊等等,如果是串行一個一個查,那耗時就比較大了,這種場景是可以改為并行呼叫的,降低介面耗時,
鎖粒度避免過粗
在高并發場景,為了防止超賣等情況,我們經常需要加鎖來保護共享資源,但是,如果加鎖的粒度過粗,是很影響介面性能的,
不管你是synchronized加鎖還是redis分布式鎖,只需要在共享臨界資源加鎖即可,不涉及共享資源的,就不必要加鎖,
耗時操作,考慮放到異步執行
耗時操作,考慮用異步處理,這樣可以降低介面耗時,比如用戶注冊成功后,短信郵件通知,是可以異步處理的,
使用快取
把要查的資料,提前放好到快取里面,需要時,直接查快取,而避免去查資料庫或者計算的程序,
提前初始化到快取
預取思想很容易理解,就是提前把要計算查詢的資料,初始化到快取,如果你在未來某個時間需要用到某個經過復雜計算的資料,才實時去計算的話,可能耗時比較大,這時候,我們可以采取預取思想,提前把將來可能需要的資料計算好,放到快取中,等需要的時候,去快取取就行,這將大幅度提高介面性能,
壓縮傳輸內容
壓縮傳輸內容,傳輸報文變得更小,因此傳輸會更快,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/548688.html
標籤:Java