布隆過濾器
- 作者: 博學谷狂野架構師
- GitHub:GitHub地址 (有我精心準備的130本電子書PDF)
只分享干貨、不吹水,讓我們一起加油!??
什么是布隆過濾器
布隆過濾器(Bloom Filter)是1970年由布隆提出的,它實際上是一個很長的二進制向量和一系列隨機映射函式,布隆過濾器可以用于檢索一個元素是否在一個集合中,它的優點是空間效率和查詢時間都比一般的演算法要好的多,缺點是有一定的誤識別率和洗掉困難,
布隆過濾器可以理解為一個不怎么精確的 set 結構,當你使用它的 contains 方法判斷某個物件是否存在時,它可能會誤判,但是布隆過濾器也不是特別不精確,只要引數設定的合理,它的精確度可以控制的相對足夠精確,只會有小小的誤判概率,
當布隆過濾器說某個值存在時,這個值可能不存在;當它說不存在時,那就肯定不存在,打個比方,當它說不認識你時,肯定就不認識;當它說見過你時,可能根本就沒見過面,不過因為你的臉跟它認識的人中某臉比較相似 (某些熟臉的系陣列合),所以誤判以前見過你,
套在上面的使用場景中,布隆過濾器能準確過濾掉那些已經看過的內容,那些沒有看過的新內容,它也會過濾掉極小一部分 (誤判),但是絕大多數新內容它都能準確識別,這樣就可以完全保證推薦給用戶的內容都是無重復的,
布隆過濾器的原理
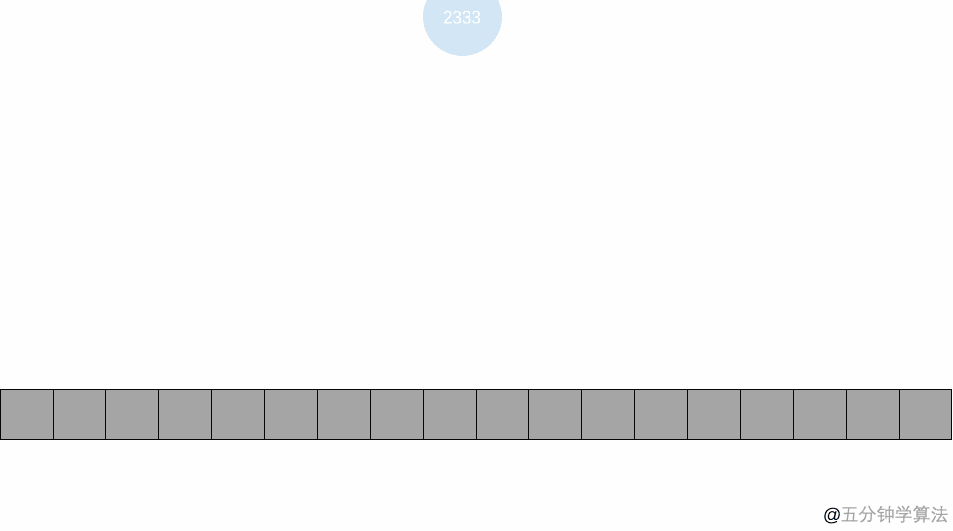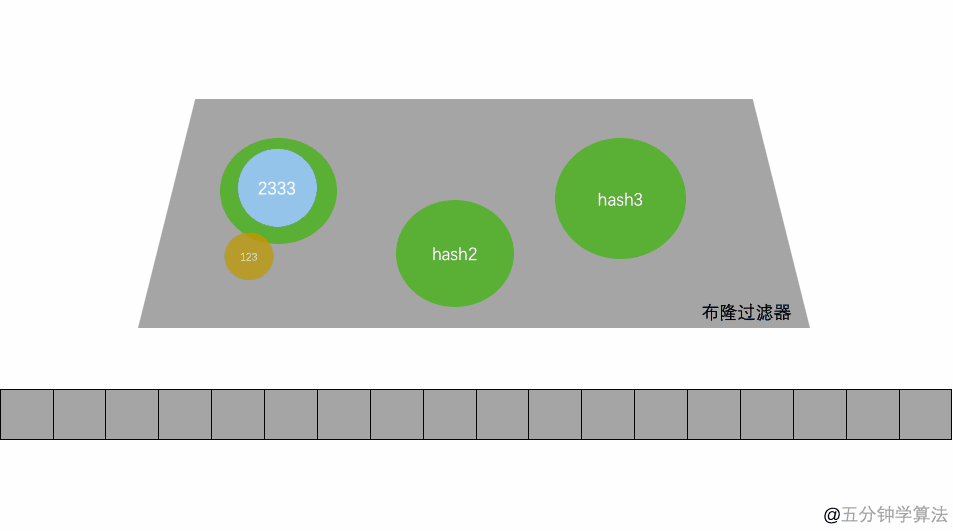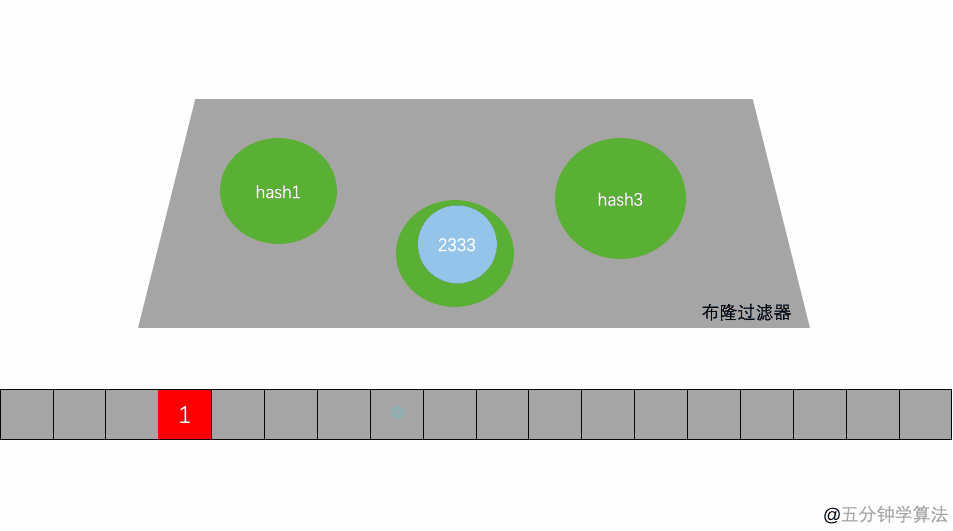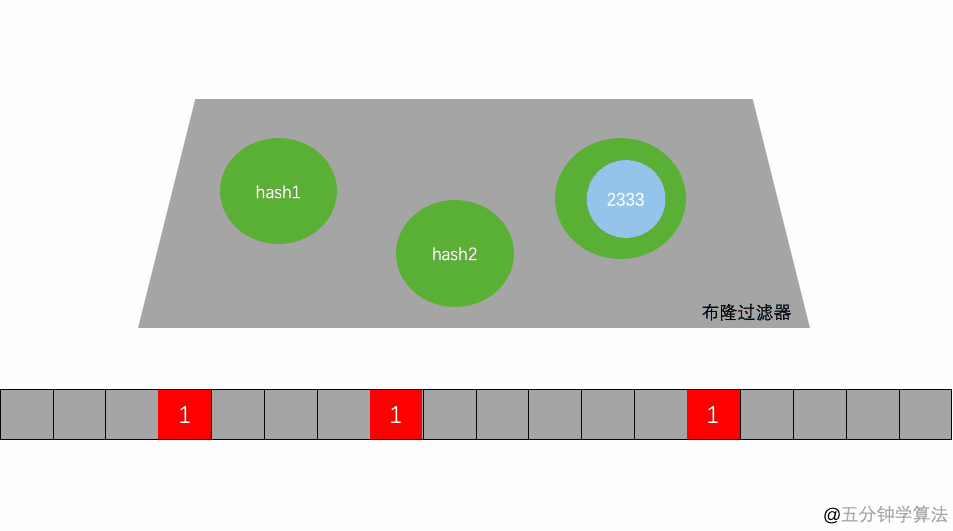
其本質就是一個只包含0和1的陣列,具體操作當一個元素被加入到集合里面后,該元素通過K個Hash函式運算得到K個hash后的值,然后將K個值映射到這個位陣列對應的位置,把對應位置的值設定為1,查詢是否存在時,我們就看對應的映射點位置如果全是1,他就很可能存在(跟hash函式的個數和hash函式的設計有關),如果有一個位置是0,那這個元素就一定不存在,
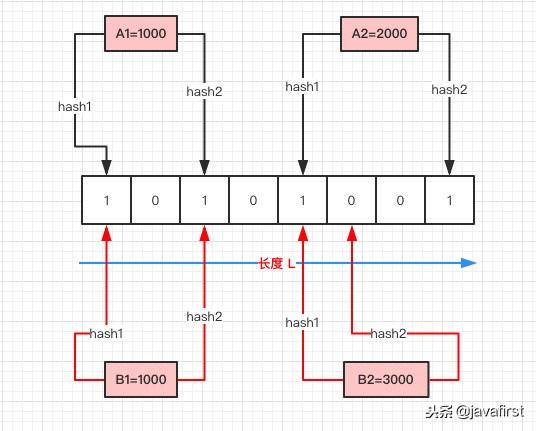
- 首先需要初始化一個二進制的陣列,長度設為 L,同時初始值全為 0 ,
- 當寫入一個 A1=1000 的資料時,需要進行 H 次 hash 函式的運算(這里為 2 次);與 HashMap 有點類似,通過算出的 HashCode 與 L 取模后定位到 0、2 處,將該處的值設為 1,
- A2=2000 也是同理計算后將 4、7 位置設為 1,
- 當有一個 B1=1000 需要判斷是否存在時,也是做兩次 Hash 運算,定位到 0、2 處,此時他們的值都為 1 ,所以認為 B1=1000 存在于集合中,
- 當有一個 B2=3000 時,也是同理,第一次 Hash 定位到 index=4 時,陣列中的值為 1,所以再進行第二次 Hash 運算,結果定位到 index=5 的值為 0,所以認為 B2=3000 不存在于集合中,
整個的寫入、查詢的流程就是這樣,匯總起來就是:
對寫入的資料做 H 次 hash 運算定位到陣列中的位置,同時將資料改為 1 ,當有資料查詢時也是同樣的方式定位到陣列中,一旦其中的有一位為 0 則認為資料肯定不存在于集合,否則資料可能存在于集合中,
布隆過濾器的特點
只要回傳資料不存在,則肯定不存在,
回傳資料存在,但只能是大概率存在,
同時不能清除其中的資料,
在有限的陣列長度中存放大量的資料,即便是再完美的 Hash 演算法也會有沖突,所以有可能兩個完全不同的 A、B 兩個資料最后定位到的位置是一模一樣的,
洗掉資料也是同理,當我把 B 的資料洗掉時,其實也相當于是把 A 的資料刪掉了,這樣也會造成后續的誤報,
基于以上的 Hash 沖突的前提,所以 Bloom Filter 有一定的誤報率,這個誤報率和 Hash 演算法的次數 H,以及陣列長度 L 都是有關的,
應用場景
快取穿透
我們經常會把一部分資料放在Redis等快取,比如產品詳情,這樣有查詢請求進來,我們可以根據產品Id直接去快取中取資料,而不用讀取資料庫,這是提升性能最簡單,最普遍,也是最有效的做法,一般的查詢請求流程是這樣的:先查快取,有快取的話直接回傳,如果快取中沒有,再去資料庫查詢,然后再把資料庫取出來的資料放入快取,一切看起來很美好,但是如果現在有大量請求進來,而且都在請求一個不存在的產品Id,會發生什么?既然產品Id都不存在,那么肯定沒有快取,沒有快取,那么大量的請求都懟到資料庫,資料庫的壓力一下子就上來了,還有可能把資料庫打死,
使用布隆過濾器的特點,只要回傳資料不存在,則肯定不存在,回傳資料存在,但只能是大概率存在,這種特點可以大批量的無效請求過濾掉,能夠穿透快取的知識漏網之魚,無關緊要,
檢查單詞拼寫
檢查一個單詞拼寫是否正確,因為有海量的單詞數量,每天可能有新的單詞,使用布隆過濾器,可以將單詞映射到很小的記憶體中,可以經過簡單的幾次hash運行就可以進行校驗,只要回傳資料不存在,則肯定不存在,回傳資料存在,但只能是大概率存在,雖然可能有誤報,但是對系統的提升是革命性的,
Guava的布隆過濾器
這就又要提起我們的Guava了,它是Google開源的Java包,提供了很多常用的功能,
Guava中,布隆過濾器的實作主要涉及到2個類,BloomFilter和BloomFilterStrategies,首先來看一下BloomFilter的成員變數,需要注意的是不同Guava版本的BloomFilter實作不同,
布隆過濾器決議
成員變數分析
COPY/** guava實作的以CAS方式設定每個bit位的bit陣列 */
private final LockFreeBitArray bits;
/** hash函式的個數 */
private final int numHashFunctions;
/** guava中將物件轉換為byte的通道 */
private final Funnel<? super T> funnel;
/**
* 將byte轉換為n個bit的策略,也是bloomfilter hash映射的具體實作
*/
private final Strategy strategy;
這是它的4個成員變數:
-
LockFreeBitArray是定義在
BloomFilterStrategies中的內部類,封裝了布隆過濾器底層bit陣列的操作, -
numHashFunctions表示哈希函式的個數,
-
Funnel,它和PrimitiveSink配套使用,能將任意型別的物件轉化成Java基本資料型別,默認用java.nio.ByteBuffer實作,最終均轉化為byte陣列,
-
Strategy是定義在BloomFilter類內部的介面,代碼如下,主要有2個方法,put和mightContain,
COPYinterface Strategy extends java.io.Serializable { /** 設定元素 */ <T> boolean put(T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits); /** 判斷元素是否存在*/ <T> boolean mightContain( T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits); ..... }
創建布隆過濾器,BloomFilter并沒有公有的建構式,只有一個私有建構式,而對外它提供了5個多載的create方法,在預設情況下誤判率設定為3%,采用BloomFilterStrategies.MURMUR128_MITZ_64的實作,
BloomFilterStrategies.MURMUR128_MITZ_64是Strategy的兩個實作之一,Guava以列舉的方式提供這兩個實作,這也是《Effective Java》書中推薦的提供物件的方法之一,
COPYenum BloomFilterStrategies implements BloomFilter.Strategy {
MURMUR128_MITZ_32() {//....}
MURMUR128_MITZ_64() {//....}
}
二者對應了32位哈希映射函式,和64位哈希映射函式,后者使用了murmur3 hash生成的所有128位,具有更大的空間,不過原理是相通的,我們選擇相對簡單的MURMUR128_MITZ_32來分析,
先來看一下它的put方法,它用兩個hash函式來模擬多個hash函式的情況,這是布隆過濾器的一種優化,
put方法
COPYpublic <T> boolean put(
T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits) {
long bitSize = bits.bitSize();
// 先利用murmur3 hash對輸入的funnel計算得到128位的哈希值,funnel現將object轉換為byte陣列,
// 然后在使用哈希函式轉換為long
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
// 根據hash值的高低位算出hash1和hash2
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
boolean bitsChanged = false;
// 回圈體內采用了2個函式模擬其他函式的思想,相當于每次累加hash2
for (int i = 1; i <= numHashFunctions; i++) {
int combinedHash = hash1 + (i * hash2);
// 如果是負數就變為正數
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
// 通過基于bitSize取模的方式獲取bit陣列中的索引,然后呼叫set函式設定,
bitsChanged |= bits.set(combinedHash % bitSize);
}
return bitsChanged;
}
在put方法中,先是將索引位置上的二進制置為1,然后用bitsChanged記錄插入結果,如果回傳true表明沒有重復插入成功,而mightContain方法則是將索引位置上的數值取出,并判斷是否為0,只要其中出現一個0,那么立即判斷為不存在,
mightContain方法
COPYpublic <T> boolean mightContain(
T object, Funnel<? super T> funnel, int numHashFunctions, BitArray bits) {
long bitSize = bits.bitSize();
long hash64 = Hashing.murmur3_128().hashObject(object, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int combinedHash = hash1 + (i * hash2);
// Flip all the bits if it's negative (guaranteed positive number)
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
// 和put的區別就在這里,從set轉換為get,來判斷是否存在
if (!bits.get(combinedHash % bitSize)) {
return false;
}
}
return true;
}
Guava為了提供效率,自己實作了LockFreeBitArray來提供bit陣列的無鎖設定和讀取,我們只來看一下它的put函式,
COPYboolean set(long bitIndex) {
if (get(bitIndex)) {
return false;
}
int longIndex = (int) (bitIndex >>> LONG_ADDRESSABLE_BITS);
long mask = 1L << bitIndex; // only cares about low 6 bits of bitIndex
long oldValue;
long newValue;
// 經典的CAS自旋重試機制
do {
oldValue = https://www.cnblogs.com/jiagooushi/p/data.get(longIndex);
newValue = oldValue | mask;
if (oldValue == newValue) {
return false;
}
} while (!data.compareAndSet(longIndex, oldValue, newValue));
bitCount.increment();
return true;
}
Guava布隆過濾器使用
引入坐標
COPY<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
代碼實作
COPY
public class GuavaBloomFilter {
/**
* 設定布隆過濾器大小
*/
private static final int size = 100000;
/**
* 構建一個BloomFilter
* 第一個引數Funnel型別的引數
* 第二個引數 期望處理的資料量
* 第三個引數 誤判率 可不加,默認 0.03D
*/
private static final BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), size);
public static void main(String[] args) {
//成功計數
float success = 0;
//失敗計數
float fial = 0;
Set<String> stringSet = new HashSet<String>();
for (int i = 0; i < size; i++) {
//生成隨機字串
String randomStr = RandomStringUtils.randomNumeric(10);
//加入到set中
stringSet.add(randomStr);
//加入到布隆過濾器
bloomFilter.put(randomStr);
}
for (int i = 0; i < size; i++) {
//生成隨機字串
String randomStr = RandomStringUtils.randomNumeric(10);
//布隆過濾器校驗存在
if (bloomFilter.mightContain(randomStr)) {
//set中存在
if (stringSet.contains(randomStr)) {
//成功計數
success++;
} else {
//失敗計數
fial++;
}
//布隆過濾器校驗不存在
} else {
// set中存在
if (stringSet.contains(randomStr)) {
//失敗計數
fial++;
} else {
//成功計數
success++;
}
}
}
System.out.println("判斷成功數:"+success + ",判斷失敗數:" + fial + ",誤判率:" + fial / 100000);
}
輸出
COPY判斷成功數:97084.0,判斷失敗數:2916.0,誤判率:0.02916
可以通過增加誤判率的引數來調整誤判率
COPY/**
* 構建一個BloomFilter
* 第一個引數Funnel型別的引數
* 第二個引數 期望處理的資料量
* 第三個引數 誤判率 可不加,默認 0.03D
*/
private static final BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), size,0.00001);
輸出
COPY判斷成功數:100000.0,判斷失敗數:0.0,誤判率:0.0
本文由
傳智教育博學谷狂野架構師教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/548696.html
標籤:Java