
大資料時代,各行各業對資料采集的需求日益增多,網路爬蟲的運用也更為廣泛,越來越多的人開始學習網路爬蟲這項技術,K哥爬蟲此前已經推出不少爬蟲進階、逆向相關文章,為實作從易到難全方位覆寫,特設【0基礎學爬蟲】專欄,幫助小白快速入門爬蟲,本期為網頁決議庫的使用,
概述
前幾期的文章中講到了網路請求庫的使用,我們已經能夠使用各種庫對目標網址發起請求,并獲取回應資訊,本期我們會介紹各網頁決議庫的使用,講解如何決議回應資訊,提取所需資料,
XPath的使用
XPath 是一門在 XML 檔案中查找資訊的語言,XPath 可用來在 XML 檔案中對元素和屬性進行遍歷,同樣,XPath 也支持HTML檔案的決議,
介紹
XPath 使用路徑運算式來匹配HTML檔案中的節點或節點集,路徑運算式基于HTML檔案樹,因此在學習XPath 時需要對網頁結構有一個初步了解,關于網頁結構這些在之前的文章《網頁基本結構》中已經介紹到了,
安裝
使用XPath 需要安裝Python的第三方庫lxml,可以使用命令pip install lxml進行安裝
使用
下文中,我們會通過一個示例來了解xpath的用法,
<div id="box">
<p name="test">這是一個測驗網頁1</p>
</div>
<p name="test">這是一個測驗網頁2</p>
<div id="city">
<ul>
<li id="u1">北京</li>
<li id="u2">上海</li>
<li id="u3">廣州</li>
<li id="u4"><a name="sz" href="https://www.cnblogs.com/ikdl/p/sz.html" target="_self">深圳</a></li>
</ul>
</div>
<div ><h3>標題</h3></div>
<div ><p>內容1</p></div>
<div ><p>內容2</p></div>
<div ><p>內容3</p></div>
這是一個簡單的網頁body結構,我們想要提取頁面中的資訊,就需要先分析它的結構,理清結構后,撰寫路徑運算式就會更加方便,
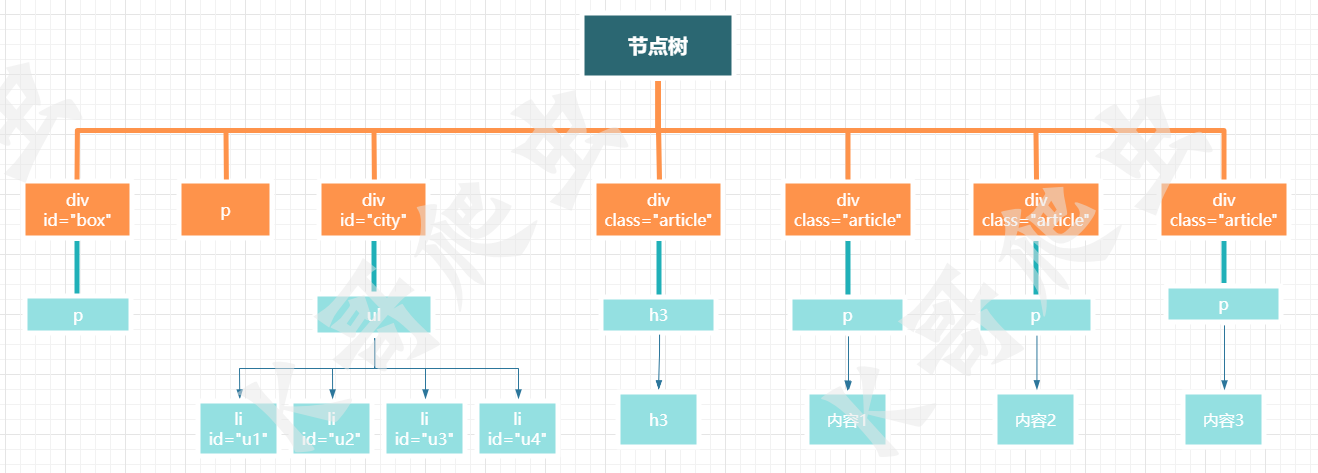
在前文對xpath的介紹中我們了解到xpath是對XML或HTML檔案進行決議的功能,但在代碼中,示例中的html文本只是一段字串,所以在使用xpath進行匹配前首先要將字串轉成HTML物件,
from lxml import etree
element = '''
<div id="box">
<p name="test">這是一個測驗網頁1</p>
</div>
<p name="test">這是一個測驗網頁2</p>
<div id="city">
<ul>
<li id="u1">北京</li>
<li id="u2">上海</li>
<li id="u3">廣州</li>
<li id="u4"><a name="sz" href="https://www.cnblogs.com/ikdl/p/sz.html" target="_self">深圳</a></li>
</ul>
</div>
<div ><h3>標題</h3></div>
<div ><p>內容1</p></div>
<div ><p>內容2</p></div>
<div ><p>內容3</p></div>
'''
html = etree.HTML(element)
print(html)
#輸出:<Element html at 0x1b642114388>
將文本轉化為html物件后,就可以使用xpath進行匹配了,
路徑運算式
| 運算式 | 描述 | 示例 | 示例描述 |
|---|---|---|---|
| nodename | 選取此節點下的所有子節點 | head | 獲取當前head節點下的所有子節點 |
| / | 從根節點選取 | /html/head | 從根節點匹配head節點 |
| // | 從任意位置匹配節點 | //head | 匹配任意head節點 |
| . | 選取當前節點 | ||
| .. | 選取當前節點的父節點 | //head/.. | 匹配head節點的父節點 |
| @ | 選取屬性 | //div[@id="box"] | 匹配任意id值為box的div標簽 |
選取節點
以示例代碼為例,我們想要匹配所有的li標簽,可以這樣實作:
html.xpath("//li")
#輸出 [<Element li at 0x24c09d3e5c8>, <Element li at 0x24c09d3e588>, <Element li at 0x24c09d3e648>, <Element li at 0x24c09d3e688>]
謂語
獲取id屬性值為box的div標簽資訊
html.xpath('//div[@id="box"]')
#輸出 [<Element div at 0x127672dc688>]
獲取所有class屬性值為article的標簽資訊
html.xpath('//*[@]')
#輸出 [<Element div at 0x2898696e4c8>, <Element div at 0x2898696e588>, <Element div at 0x2898696e5c8>, <Element div at 0x2898696e608>]
獲取所有class屬性值為article的標簽下h3標簽的文本資訊
html.xpath('//*[@]/h3/text()')
#輸出 ['標題']
獲取所有class屬性值為article的標簽下p標簽的文本資訊
html.xpath('//*[@]/p/text()')
#輸出 ['內容1', '內容2', '內容3']
獲取第一個li標簽的文本資訊
html.xpath('//li[1]/text()')
#輸出 ['北京']
獲取最后一個li標簽下的所有文本資訊
html.xpath('//li[last()]//text()')
#輸出 ['深圳']
獲取倒數第二個li標簽下的所有文本資訊
html.xpath('//li[last()-1]//text()')
#輸出 ['廣州']
獲取前兩個li標簽下的文本資訊
html.xpath('//li[position()<3]//text()')
#輸出 ['北京', '上海']
選取多個路徑
html.xpath('//div[@]/h3/text() | //div[@id="box"]/p/text()')
#輸出 ['這是一個測驗網頁1', '標題']
軸
軸可定義相對于當前節點的節點集,
| 軸名稱 | 結果 |
|---|---|
| ancestor | 選取當前節點的所有先輩(父、祖父等), |
| ancestor-or-self | 選取當前節點的所有先輩(父、祖父等)以及當前節點本身, |
| attribute | 選取當前節點的所有屬性, |
| child | 選取當前節點的所有子元素, |
| descendant | 選取當前節點的所有后代元素(子、孫等), |
| descendant-or-self | 選取當前節點的所有后代元素(子、孫等)以及當前節點本身, |
| following | 選取檔案中當前節點的結束標簽之后的所有節點, |
| namespace | 選取當前節點的所有命名空間節點, |
| parent | 選取當前節點的父節點, |
| preceding | 選取檔案中當前節點的開始標簽之前的所有節點, |
| preceding-sibling | 選取當前節點之前的所有同級節點, |
| self | 選取當前節點, |
獲取ul標簽下的子li標簽下的a標簽的href屬性
html.xpath('//ul/child::li/a/@href')
#輸出 ['sz.html']
獲取a標簽的所有先輩div標簽
html.xpath('//a/ancestor::div')
#輸出 [<Element div at 0x23a712de588>]
獲取a標簽的所有屬性
html.xpath('//a/attribute::*')
#輸出 ['sz', 'sz.html', '_self']
獲取id屬性值為u2的li標簽之后的所有p標簽的文本資訊
html.xpath('//li[@id="u2"]/following::p/text()')
#輸出 ['內容1', '內容2', '內容3']
獲取id屬性值為u2的li標簽之前的所有p標簽的文本資訊
html.xpath('//li[@id="u2"]/preceding::p/text()')
#輸出 ['這是一個測驗網頁1', '這是一個測驗網頁2']
獲取id屬性值為u2的li標簽之后的所有同級標簽的文本資訊
html.xpath('//li[@id="u2"]/following-sibling::*/text()')
#輸出 ['廣州']
獲取id屬性值為u3的li標簽之前的所有同級標簽的文本資訊
html.xpath('//li[@id="u2"]/preceding-sibling::*/text()')
#輸出 ['北京']
運算子
獲取id屬性值為u1或者u2的標簽下的文本資訊
html.xpath('//li[@id="u1" or @id="u2"]/text()')
#輸出 ['北京', '上海']
判斷a標簽的name屬性值是否為sz
html.xpath('//a/@name="sz"')
#輸出 True
函式
xpath提供了非常多的內置函式,這些函式可以用于各種值的計算與處理,這里只介紹常用的函式,
獲取所有屬性值包含test的標簽的文本資訊
html.xpath('//*[contains(attribute::*,"test")]/text()')
#輸出 ['這是一個測驗網頁1', '這是一個測驗網頁2']
將id為u1的li標簽和id為u2的li標簽的文本資訊進行拼接
html.xpath('concat(//li[@id="u1"]/text(),//li[@id="u2"]/text())')
#輸出 北京上海
獲取id屬性值以u開頭的所有li標簽的文本資訊
html.xpath('//li[starts-with(@id,"u")]/text()')
#輸出 ['北京', '上海', '廣州']
上文中講到的路徑運算式的寫法只是xpath中比較常用的寫法,基本能夠覆寫大部分需求,xpath路徑也可以通過F12開發者工具直接獲取,在 element 中右鍵需要匹配的節點元素,復制完整xpath即可,復制下來的完整xpath路徑如:/html/body/ul/li[1],這種方法雖然簡單,但實際上路徑并不準確,而且路徑為絕對路徑,相對復雜,所以路徑運算式推薦自己手動撰寫,
BeautifulSoup的使用
BeautifulSoup與上文中介紹的xpath一樣,都是用于決議XML或HTML標簽中的資訊,BeautifulSoup 與 xpath 各有優勢,使用哪個可以憑個人喜好,
安裝
目前流行的 beautifulsoup 版本為beautifulsoup4,下面簡稱bs4,
pip install beautifulsoup4
使用
與 xpath 不同,bs4 需要自己選擇決議器,常用的決議器有:
html.parser:Python內置決議器
lxml HTML:HTML決議器
lxml XML:XML決議器
各決議器之間的區別主要在于檔案決議容錯能力,對于不規范的 HTML 文本,它們的決議結果并不一致,
這里我們推薦使用 lxml 作為決議器,使用 lxml 作為決議器需要提前安裝 lxml 第三方庫,
from bs4 import BeautifulSoup
html = '''
<div id="box">
<p name="test">這是一個測驗網頁1</p>
</div>
<p name="test">這是一個測驗網頁2</p>
<div id="city">
<ul>
<li id="u1">北京</li>
<li id="u2">上海</li>
<li id="u3">廣州</li>
<li id="u4"><a name="sz" href="https://www.cnblogs.com/ikdl/p/sz.html" target="_self">深圳</a></li>
</ul>
</div>
<div ><h3>標題</h3></div>
<div ><p>內容1</p></div>
<div ><p>內容2</p></div>
<div ><p>內容3</p></div>
'''
soup = BeautifulSoup(html,'lxml')
#回傳完整的html文本
bs4的寫法比較簡潔,更人性化,
soup.body :獲取body資訊
soup.li :獲取第一個li標簽
soup.div :獲取第一個div標簽
soup.li['id'] :獲取第一個li標簽的id屬性值
soup.a.attrs :獲取第一個a標簽的所有屬性值,回傳型別為字典
獲取多個資訊
soup.find_all('li') :獲取所有li標簽
soup.find_all(["p","a"]) :獲取所有p標簽與a標簽
soup.find_all('div','article') :獲取所有類名為article的div標簽
soup.find_all(id="box") :獲取所有id屬性值為box的標簽
節點
soup.ul.parent :獲取ul標簽的父節點
soup.find('a').find_parent("li") :獲取第一個a標簽的父li標簽
soup.find('a').find_parents("li") :獲取第一個a標簽的所有父li標簽
soup.find('li').find_next_siblings("li") :獲取第一個li標簽后的兄弟li標簽
soup.find('li').find_next_sibling("li") :獲取第一個li標簽后的第一個兄弟li標簽
soup.find(attrs={'id':'u4'}).find_previous_siblings("li") :獲取id屬性值為u4的li標簽前的所有兄弟li標簽
soup.find(attrs={'id':'u4'}).find_previous_sibling("li") :獲取id屬性值為u4的li標簽前的第一個兄弟li標簽
CSS選擇器
BeautifulSoup 支持大部分的CSS選擇器,CSS選擇器在之前的文章《網頁基本結構》中做了介紹,
soup.select('div h3') :獲取div下的h3標簽
soup.select('#city #u2') :獲取id屬性值為city的標簽下id值u2的標簽
soup.select('a[href="https://www.cnblogs.com/ikdl/p/sz.html"]') :獲取href屬性值為sz.html的a標簽
soup.select_one(".article") :獲取第一個類名為article的標簽
bs4 作用上與 xpath 基本一致,但是 bs4 的優勢就在于陳述句的簡潔性,用bs4匹配資料比 xpath 稍微簡單一些,但是它在性能上比 xpath 要稍弱,
re正則運算式的使用
正則運算式(Regular Expression,通常簡寫為“regex”或“regexp”)是一種用來匹配文本字串的模式,在編程和文本處理中,正則運算式通常被用來進行字串匹配、搜索、替換等操作,
實際開發中,我們會對一些非結構化資料進行決議,對于這類資料,無論是 xpath 還是 BeautifulSoup 都無法進行決議,這時我們就需要用到正則運算式,正則運算式的強大在于它能夠匹配任意型別的文本資料,可以幫助開發者快速的處理文本資料,
安裝
Python 中內置了 re 庫,無需額外安裝
使用
| 模式 | 描述 |
|---|---|
| \w | 匹配字母數字及下劃線 |
| \W | 匹配非字母數字及下劃線 |
| \s | 匹配任意空白字符,等價于[\t\n\r\f] |
| \S | 匹配任意非空白字符 |
| \d | 匹配任意數字,等價于[0-9] |
| \D | 匹配任意非數字的字符 |
| \A | 匹配字串的開頭 |
| \Z | 匹配字串的結尾,如存在換行,只匹配到換行前的結束字串 |
| \z | 匹配字串的結尾,如存在換行,會匹配換行符 |
| ^ | 匹配字串的開頭 |
| $ | 匹配字串的結尾 |
| . | 匹配任意字符,除換行符,當re.DOTALL被指定時可以匹配包括換行符的任意字符 |
| [...] | 匹配一組字符,如[abc],匹配a,b,c |
| [^...] | 匹配不在[]中的字符 |
| * | 匹配0或多個運算式 |
| + | 匹配1或多個運算式 |
| ? | 對它前面的正則式匹配0到1次 |
| 匹配n個之前的正則運算式 | |
| 對運算式進行n到m次匹配,盡量取最多 | |
| a|b | 匹配a或b |
| () | 匹配括號內的任意運算式 |
compile函式
re.compile 可以將正則運算式樣式的字串編譯為一個正則運算式物件,可以通過這個物件來呼叫下述方法,
pattern = re.compile("\d")
match函式
re.match 會從字串的起始位置進行匹配正則運算式,匹配成功后會回傳匹配成功的結果,匹配失敗則回傳None,
import re
#匹配字符a
pattern = re.compile("a")
#從字串開頭開始匹配
print(pattern.match("cat"))
#從下標為1的位置開始匹配
print(pattern.match("cat",1))
運行結果:
None
<re.Match object; span=(1, 2), match='a'>
運算式匹配:
#以hello開頭中間為數字后面是World的字串
pattern = re.compile("^hello\s(\d+)\sWorld")
print(pattern.match("hello 123 World!!!"))
運行結果:
<re.Match object; span=(0, 15), match='hello 123 World'>
可以看到,兩次的運行結果都是一個物件,可以使用group()方法獲取匹配到的文本資訊,
pattern = re.compile("^hello\s(\d+)\sWorld")
result = pattern.match("hello 123 World!!!")
print(result.group())
print(result.group(1))
運行結果:
hello 123 World
123
group(1)會回傳第一個被括號包圍的匹配結果,示例中被括號包圍的是\d+,所以輸出的結果為123,
Search函式
match函式是從字串的開頭開始匹配,想要從其它地方開始匹配需要自己傳入位置,用這種方法匹配資料局限性很大,我們想要從任意位置開始匹配資料可以使用 re.search 函式,
pattern = re.compile("(\d+)")
result = pattern.search("hello 123 World321!!!")
print(result)
print(result.group(1))
運行結果:
<re.Match object; span=(6, 9), match='123'>
123
可以看到,使用 search 方法我們無需指定位置,它會搜尋整個字串,回傳第一個匹配成功的結果,
findall函式
search 函式可以從任意位置進行匹配,但是它只會回傳第一個匹配成功的結果,我們想要獲取所有匹配成功的結果就需要用到 findall 函式,
pattern = re.compile("(\d+)")
result = pattern.findall("hello 123 World321!!!")
print(result)
運行結果:
['123', '321']
findall 函式會回傳一個串列,因此 findall 函式回傳的結果無法使用 group 方法,
通用匹配
在實際開發中,我們往往會遇到非常復雜的文本結構如:
"hello 123 this is a 999Regex Demo!!!World321"
這時如果使用\w,\s進行匹配會顯得非常復雜,這時我們就可以使用一個通配組合.*,上文中介紹到了.是匹配任意字符,*是匹配0或多個運算式,.*搭配在一起就是匹配任意多個字符,使用.*可以簡單有效的進行資料匹配,
#匹配hello World之間的資訊
pattern = re.compile("hello(.*)World")
result = pattern.findall("hello123 World this is a 999Regex Demo!!!World321")
print(result)
運行結果:
['123 World this is a 999Regex Demo!!!']
這里我們可以看到,使用.*后它匹配到了第一個 hello 到最后一個 World 之間的所有文本,但如果我們想要匹配 hello 到第一個 world 之間的資訊呢,這時我們就需要了解一下貪婪匹配與非貪婪匹配,
貪婪與非貪婪
顧名思義,貪婪模式表示盡可能多的匹配,非貪婪模式表示盡可能少的匹配,從上文的示例我們可以看到re.compile("hello(.*)World")它會從 hello 開始,匹配到最后一個 World,這顯然就是貪婪模式,它會盡可能多的匹配,也就是匹配到最后一個符合規則的位置,正則運算式中,非貪婪模式需要使用到?,前文中講到了?是匹配0到1次,使用?就能實作盡可能少的匹配,
#匹配hello World之間的資訊(非貪婪)
pattern = re.compile("hello(.*?)World")
result = pattern.findall("hello123 World this is a 999Regex Demo!!!World321")
print(result)
運行結果:
['123 ']
可以看到使用.*?后,正則運算式只匹配到第一個 World 就停下了,這樣就實作了非貪婪匹配,
Newspaper智能決議庫的使用
Newspaper 是 Python 的第三方庫,主要用于抓取新聞網頁,它能夠自動決議網頁內容,匹配出新聞的各種資訊,而且操作簡單,非常容易上手,但是它并不適用于實際開發,因為它不夠穩定,存在各種問題,無法應對爬蟲開發中可能遇到的問題,如反爬蟲等,所以這里對它只做介紹,
安裝
命令列安裝:pip install newspaper3k
使用
它的使用非常簡單,傳入目標網址后,呼叫 download() 方法下載網頁源代碼,使用 parse() 方法決議原始碼,
from newspaper import Article
# 目標新聞網址
url = 'https://目標文章'
news = Article(url, language='zh')
news.download()
news.parse()
#獲取新聞網頁原始碼
print(news.html)
#獲取新聞標題
print(news.title)
#獲取新聞正文
print(news.text)
#獲取新聞作者
print(news.authors)
#獲取新聞發布時間
print(news.publish_date)
#獲取新聞關鍵詞
print(news.keywords)
#獲取新聞摘要
print(news.summary)
#獲取新聞配圖地址
print(news.top_image)
#獲取新聞視頻地址
print(news.movies)
Newspaper 可以與 requests 配合使用,通過 requests 獲取原始碼,由 Newspaper 進行決議提取,Newspaper 庫并不能完美的決議出各種資訊,適合非專業人士使用,
總結
上文中,講到了四個爬蟲決議庫的使用,其中 xpath 與 beautifulSoup 主要用于對 html 文本的決議,正則運算式主要用于對非結構化文本的決議,無法用 xpath 和 beautifulSoup 決議的文本資訊通常會使用正則來進行匹配,Newspaper 是智能決議庫,使用它可以自動決議新聞資訊,無需自己撰寫運算式,但是缺點也很明顯 ,
與網路請求庫一樣,網頁決議庫的使用是每一個爬蟲初學者都應該牢牢掌握的知識點,能夠熟練的使用決議庫才能更好的完成資料采集作業,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/548703.html
標籤:Python