一、延遲計算
RDD 代表的是分布式資料形態,因此,RDD 到 RDD 之間的轉換,本質上是資料形態上的轉換(Transformations)
在 RDD 的編程模型中,一共有兩種算子,Transformations 類算子和 Actions 類算子,開發者需要使用 Transformations 類算子,定義并描述資料形態的轉換程序,然后呼叫 Actions 類算子,將計算結果收集起來、或是物化到磁盤,
在這樣的編程模型下,Spark 在運行時的計算被劃分為兩個環節,
- 基于不同資料形態之間的轉換,構建計算流圖(DAG,Directed Acyclic Graph)
- 通過 Actions 類算子,以回溯的方式去觸發執行這個計算流圖
換句話說,開發者呼叫的各類 Transformations 算子,并不立即執行計算,當且僅當開發者呼叫 Actions 算子時,之前呼叫的轉換算子才會付諸執行,在業內,這樣的計算模式有個專門的術語,叫作“延遲計算”(Lazy Evaluation),
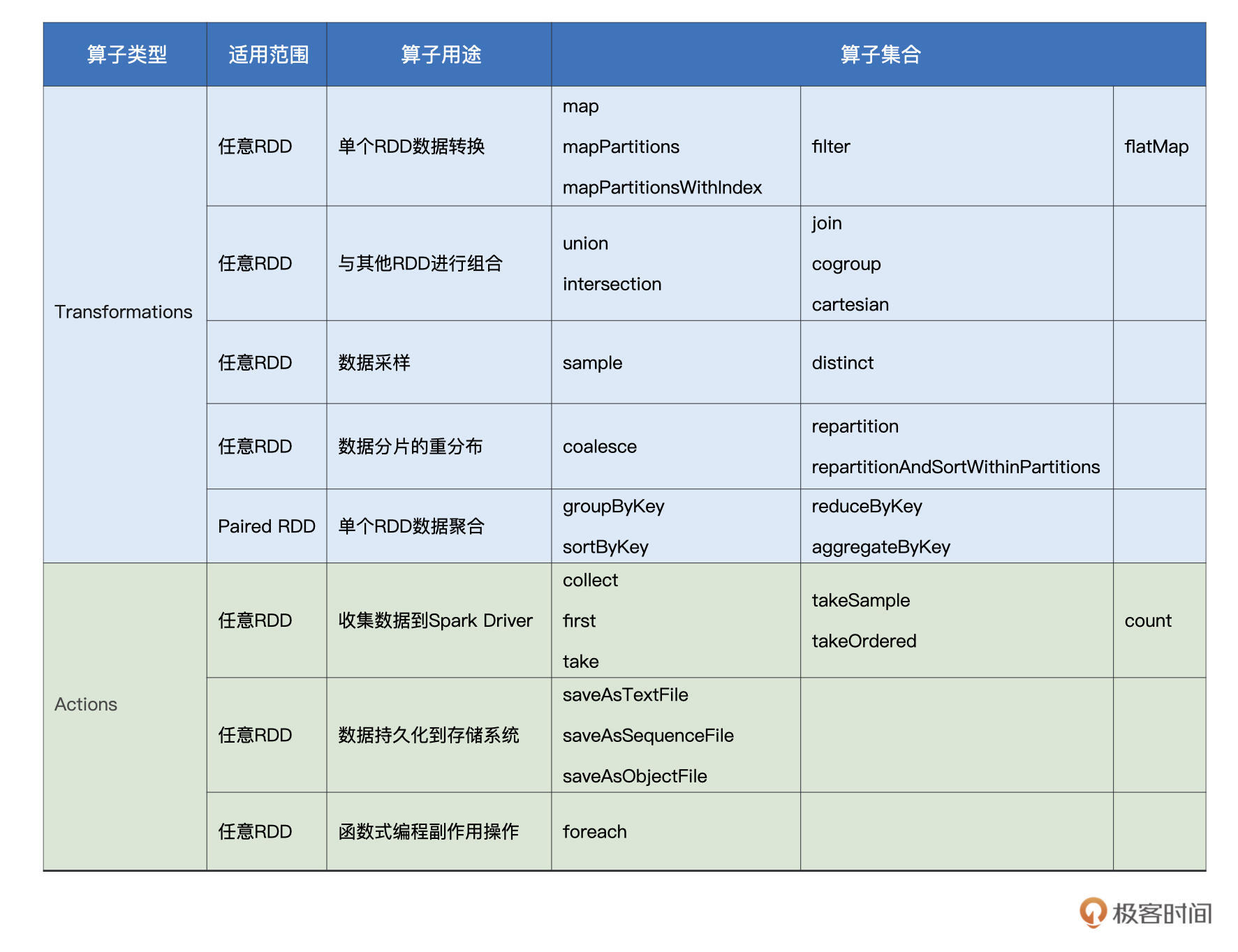
二、Spark算子分類
在 RDD 的開發框架下,哪些算子屬于 Transformations 算子,哪些算子是 Actions 算子呢?
這里給出一張自己在極客看的課程中的圖
三、Transform算子執行流程(原始碼)
Map轉換算是 RDD 的經典轉換操作之一了.就以它開頭.Map的原始碼如下:

1. sc.clean(f)
首先掉了一個sc.clean(f) , 我們進到clean函式里看下:
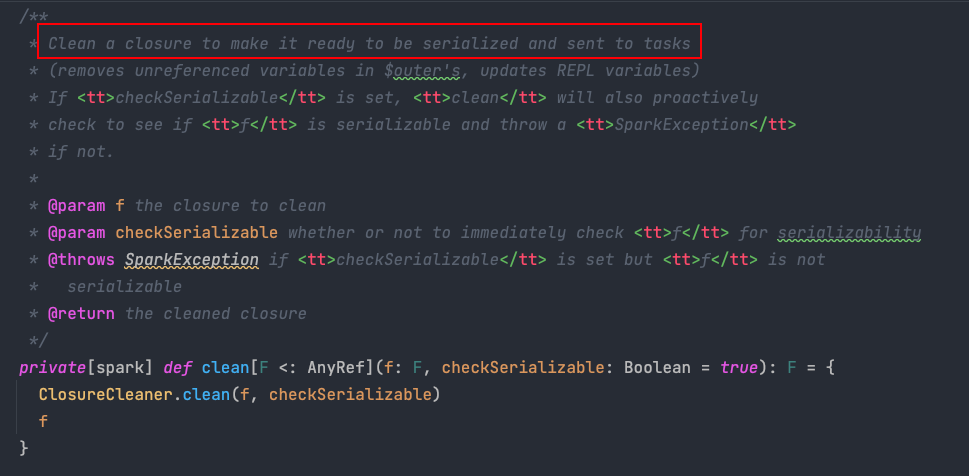
注釋中明確提到了這個函式的功能:clean 整理一個閉包,使其可以序列化并發送到任務.
這里的代碼有些多,大概知道這個函式的功能是這樣就ok了,閉包的問題會在另一篇文章里仔細介紹
2. MapPartitionsRDD
進入到函式后原始碼如下:
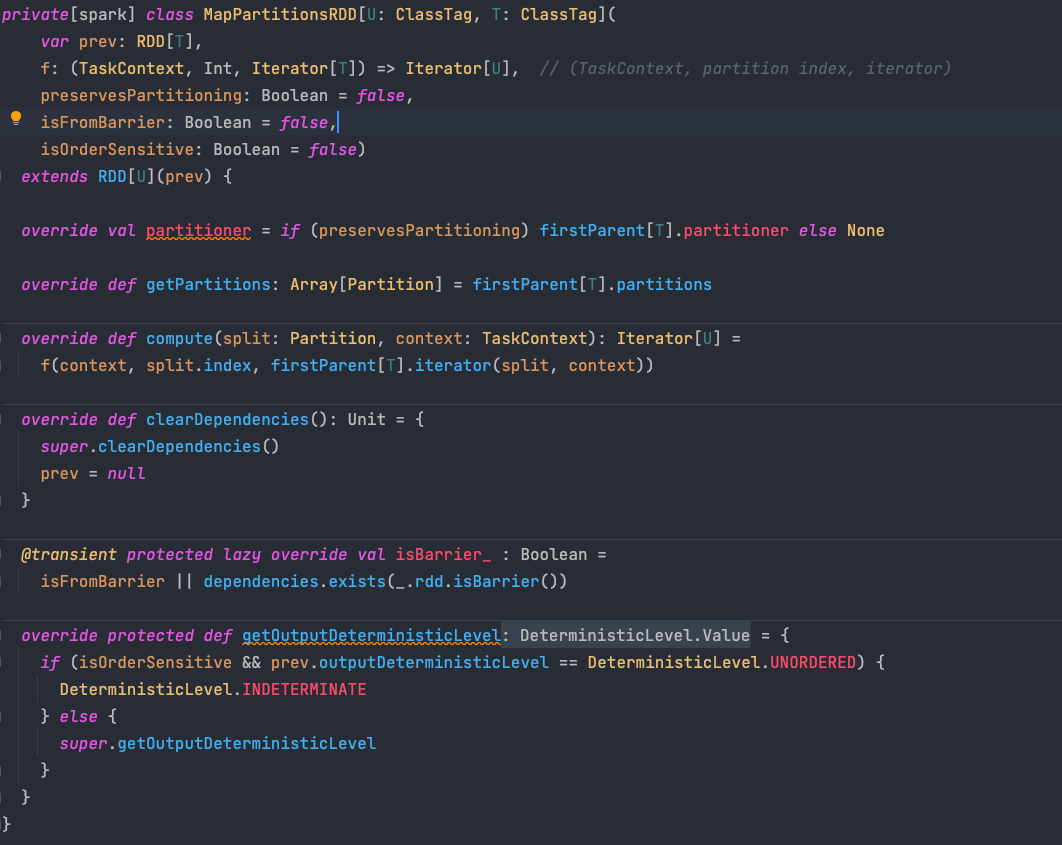
這是一個MapPartitionsRDD,我們仔細看它的構成,從而來理解它是如何描述MapPartitionsRDD的.
2.1 var prev:RDD[T]
這里的 prev 就是父RDD,f 則是Map中傳入的處理函式,除了這兩個就沒有了,也就是說明 RDD中沒有存盤具體的資料本身
這再次印證了轉換不會產生任何資料.它只是單純了記錄父RDD以及如何轉換的程序就完了,不會在轉換階段產生任何資料集
2.2 preservesPartitioning
preservesPartitioning 表示是否保持父RDD的磁區資訊.
如果為false(默認為false),則會對結果重新磁區.也就是Map系默認都會磁區
如果為true,保留磁區. 則按照 firstParent 保留磁區

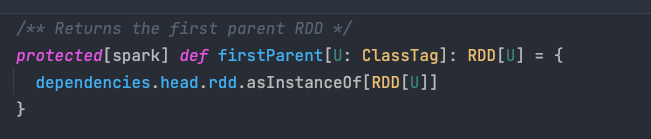
可以看到根據 dependencies 找到其第一個父 RDD
2.3 compute 計算邏輯
2.3.1 compute方法
RDD 抽象類要求其所有子類都必須實作 compute 方法,該方法接受的引數之一是一個Partition 物件,目的是計算該磁區中的資料,
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
可以看到,compute 方法呼叫當前 RDD 內的第一個父 RDD 的 iterator 方法,該方的目的是拉取父 RDD 對應磁區內的資料,
iterator 方法會回傳一個迭代器物件,迭代器內部存盤的每個元素即父 RDD 對應磁區內已經計算完畢的資料記錄,得到的迭代器作為 f 方法的一個引數,f 在 RDD 類的 map 方法中指定,即實際的轉換函式,
compute 方法會將迭代器中的記錄一一輸入 f 方法,得到的新迭代器即為所求磁區中的資料,
其他 RDD 子類的 compute 方法與之類似,在需要用到父 RDD 的磁區資料時候,就會呼叫 iterator 方法,然后根據需求在得到的資料之上執行粗粒度的操作,換句話說,compute 函式負責的是父 RDD 磁區資料到子 RDD 磁區資料的變換邏輯,
2.3.2 iterator方法
此方法的實作在 RDD 這個抽象類中
/**
* Internal method to this RDD; will read from cache if applicable, or otherwise compute it.
* This should ''not'' be called by users directly, but is available for implementers of custom
* subclasses of RDD.
*/
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
interator首先檢查 存盤級別 storageLevel:此處可參考RDD持久化
如果存盤級別不是NONE, 說明磁區的資料說明磁區的資料要么已經存盤在檔案系統當中,要么當前 RDD 曾經執行過 cache、 persise 等持久化操作,此時需要從存盤空間讀取磁區資料,呼叫 getOrCompute 方法
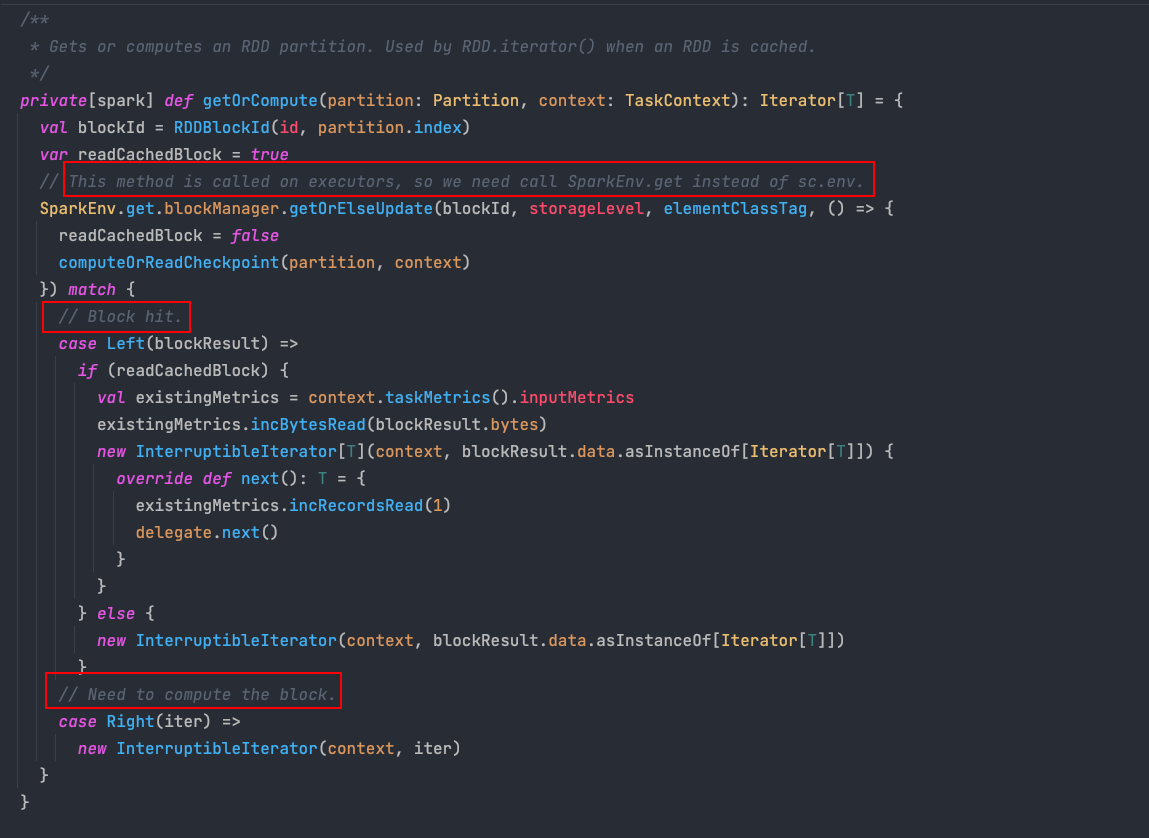
getOrCompute 方法會根據 RDD 編號:id 與 磁區編號:partition.index 計算得到當前磁區在存盤層對應的塊編號:blockId,通過存盤層提供的資料讀取介面提取出塊的資料,
代碼中的這幾句注釋給的非常到位,大致的判斷順序如下:
- 塊命中的情況:也就是資料之前已經成功存盤到介質中,這其中可能是資料本身就在存盤介質中(比如通過讀取HDFS創建的RDD),也可能是 RDD 在經過持久化操作并且經歷了一次計算程序,這個時候我們就能成功讀取資料并將其回傳
- 塊未命中的情況:可能是資料已經丟失,或者 RDD 經過持久化操作,但是是當前磁區資料是第一次被計算,因此會出現拉取得到資料為
None的情況,這就意味著我們需要計算磁區資料,繼續呼叫RDD類computeOrReadCheckpoint方法來計算資料,并將計算得到的資料快取到存盤介質中,下次就無需再重復計算,
如果當前RDD的存盤級別為 None,說明為未經持久化的 RDD,需要重新計算 RDD 內的資料,這時候呼叫 RDD 類的 computeOrReadCheckpoint 方法,該方法也在持久化 RDD 的磁區獲取資料失敗時被呼叫,
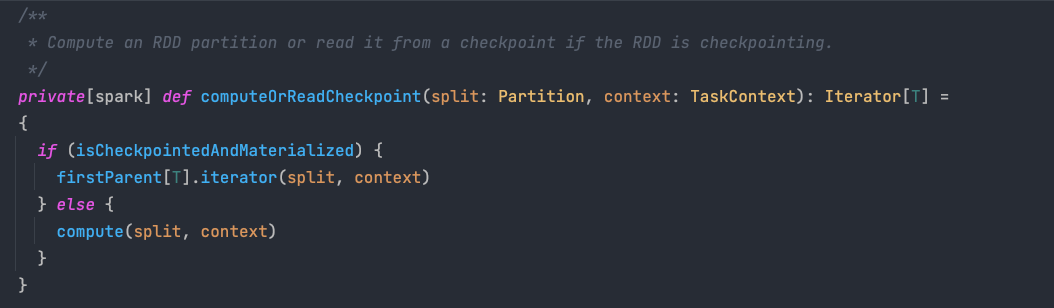
computeOrReadCheckpoint 方法會檢查當前 RDD 是否已經被標記成檢查點,如果未被標記成檢查點,則執行自身的 compute 方法來計算磁區資料,否則就直接拉取父 RDD 磁區內的資料,
需要注意的是,對于標記成檢查點的情況,當前 RDD 的父 RDD 不再是原先轉換操作中提供資料的父 RDD,而是被 Apache Spark 替換成一個 CheckpointRDD 物件,該物件中的資料存放在檔案系統中,因此最終該物件會從檔案系統中讀取資料并回傳給 computeOrReadCheckpoint 方法
參考文章:
Cache 和 Checkpoint
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/548787.html
標籤:其他