介紹分代收集理論和幾種垃圾收集演算法的思想及其發展程序,
分代收集理論
當前商業虛擬機的垃圾收集器,大多數都遵循了 “分代收集”(Generational Collection)的理論進行設計,分代收集名為理論,實質是一套符合大多數程式運行實際情況的經驗法則,分代收集理論它建立在兩個分代假說之上:
- 弱分代假說(Weak Generational Hypothesis):絕大多數物件都是朝生夕滅的,
- 強分代假說(Strong Generational Hypothesis):熬過越多次垃圾收集程序的物件就越難以消亡,
這兩個分代假說共同奠定了多款常用的垃圾收集器的一致的設計原則:垃圾收集器應該將 Java 堆劃分出不同的區域,然后將回收物件依據其年齡(年齡即物件熬過垃圾收集程序的次數)分配到不同的區域之中存盤,顯而易見:
- 如果一個區域中大多數物件都是朝生夕滅,難以熬過垃圾收集程序的話,那么把它們集中放在一起,每次回收時只關注如何保留少量存活而不是去標記那些大量將要被回收的物件,就能以較低的代價回收到大量的空間;
- 如果剩下的都是難以消亡的物件,那把它們集中放在一起,虛擬機便可以使用較低的頻率來回收這個區域,
- 這就同時兼顧了垃圾收集的時間開銷和記憶體的空間有效利用,
在 Java 堆劃分出不同的區域之后,垃圾收集器才可以每次只回收其中某一個或者某些部分的區域,因而才有了 “Minor GC”、“Major GC”、“Full GC” 這樣的回收型別的劃分;也才能夠針對不同的區域 安排與里面存盤物件存亡特征相匹配的垃圾收集演算法,因而發展出了 “標記-清除演算法”、“標記-復制演算法”、“標記-整理演算法” 等針對性的垃圾收集演算法,
把分代收集理論具體放到現在的商用 Java 虛擬機里,設計者一般至少會把 Java 堆劃分為新生代(Young Generation) 和老年代(Old Generation)兩個區域,顧名思義,在新生代中,每次垃圾收集時都會發現有大批物件死去,而每次回收后存活的少量物件,將會逐步晉升到老年代中存放,
分代收集并非只是簡單劃分一下記憶體區域那么容易,它至少存在一個明顯的困難:物件不是孤立的,物件之間會存在跨代參考,假如現在要進行一次只局限于新生代區域內的垃圾收集(Minor GC),但新生代中的物件是完全有可能被老年代所參考的,為了找出該區域中的存活物件,不得不在固定的 GC Roots 之外,再額外遍歷整個老年代中所有的物件來確保可達性分析結果的正確性,反過來也是一樣,
遍歷整個老年代中所有物件的方案雖然理論上可行,但無疑會為記憶體回收帶來很大的性能負擔,為了解決這個問題,就需要對分代收集理論添加第三條經驗法則:跨代參考假說(Intergenerational Reference Hypothesis):跨代參考相對于同代參考來說僅占極少數,
這其實是可根據前兩條假說邏輯推理得出的隱含推論:存在互相參考關系的兩個物件,是應該傾向于同時生存或者同時消亡的,舉個例子,如果某個新生代物件存在跨代參考,由于老年代物件難以消亡,該參考會使得新生代物件在垃圾收集時同樣得以存活,進而在年齡增長之后晉升到老年代中,這時跨代參考也隨即被消除了,
依據這條假說,我們就不應再為了少量的跨代參考去掃描整個老年代,也不必浪費空間專門記錄每一個物件是否存在及存在哪些跨代參考,只需在新生代上建立一個全域的資料結構(該結構被稱為“記憶集”, Remembered Set),這個結構把老年代劃分成若干小塊,標識出老年代的哪一塊記憶體會存在跨代參考,此后當發生 Minor GC 時,只有包含了跨代參考的小塊記憶體里的物件才會被加入到 GC Roots 進行掃描,雖然這種方法需要在物件改變參考關系(如將自己或者某個屬性賦值)時維護記錄資料的正確性,會增加一些運行時的開銷,但比起垃圾收集時掃描整個老年代來說仍然是劃算的,
標記-清除演算法
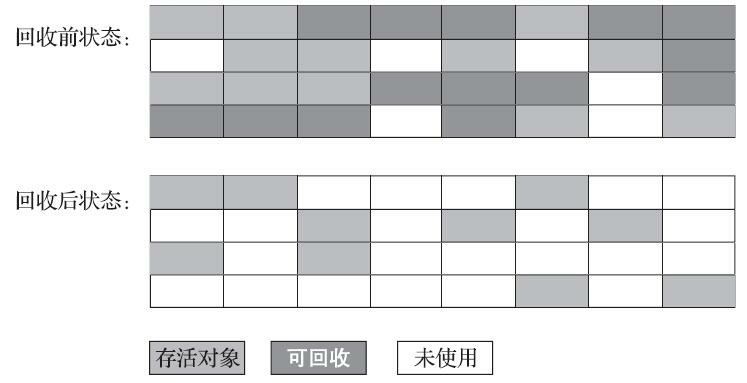
最早出現也是最基礎的垃圾收集演算法是 “標記-清除”(Mark-Sweep)演算法,“標記-清除” 演算法分為 “標記” 和 “清除” 兩個階段:首先標記出所有需要回收的物件,在標記完成后,統一回收掉所有被標記的物件,也可以反過來,標記出所有存活的物件,在標記完成后,統一回收掉所有未被標記的物件,
之所以說 “標記-清除” 演算法是最基礎的收集演算法,是因為后續的垃圾收集演算法大多是以 “標記-清除” 演算法為基礎,對 “標記-清除” 演算法的缺點進行改進而得到的,“標記-清除” 演算法的主要缺點有兩個:
- 第一個是:執行效率不穩定,如果 Java 堆中包含大量的物件,而且其中大部分是需要被回收的,這時必須進行大量標記和清除的動作,導致標記和清除這兩個程序的執行效率都隨物件數量增長而降低;
- 第二個是:記憶體空間的碎片化問題,標記、清除之后會產生大量不連續的記憶體碎片,記憶體碎片太多可能會導致程式運行的程序中需要分配較大物件時,無法找到足夠的連續記憶體而不得不提前觸發另一次垃圾收集動作,
“標記-清除” 演算法的執行程序如圖所示,
標記-復制演算法
“標記-復制” 演算法常被簡稱為復制演算法,
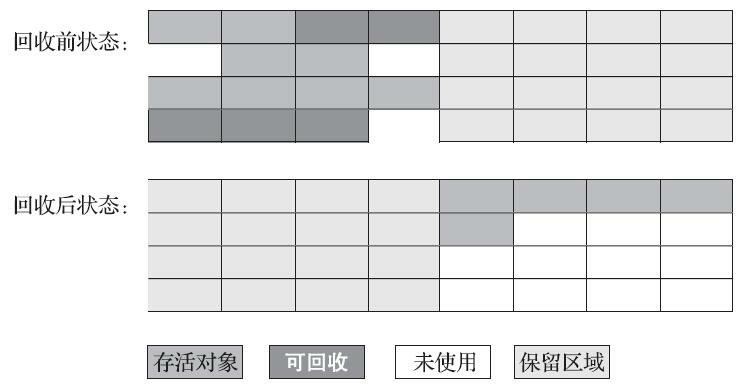
為了解決 “標記-清除” 演算法面對大量可回收物件時執行效率低的問題,1969 年 Fenichel 提出了一種被稱為 “半區復制”(Semispace Copying)的垃圾收集演算法,它將可用記憶體按容量劃分為大小相等的兩塊,每次只使用其中的一塊,當這一塊記憶體用完時,就將還存活著的物件復制到另外一塊記憶體上,然后再將已使用過的記憶體空間一次清理掉,
“標記-復制” 演算法的優劣局限:
- 如果記憶體中多數物件都是存活的,“標記-復制” 演算法將會產生大量的記憶體間復制的開銷,但對于多數物件都是可回收的情況,演算法需要復制的就是占少數的存活物件,而且每次都是針對整個半區進行記憶體回收,分配記憶體時也就不用考慮有空間碎片的復雜情況,只要移動堆頂指標,按順序分配即可,
- “標記-復制” 演算法的實作簡單,運行高效,不過其缺陷也顯而易見,“標記-復制” 演算法的代價是將可用記憶體縮小為了原來的一半,空間浪費有點多,
“標記-復制” 演算法的執行程序如圖所示,
標記-整理演算法
“標記-復制” 演算法在物件存活率較高時就要進行較多的復制操作,效率將會降低,更關鍵的是,如果不想浪費 50% 的空間,就需要有額外的空間進行分配擔保,以應對被使用的記憶體中所有物件都 100% 存活的極端情況,所以在老年代一般不能直接選用 “標記-復制” 演算法,
針對老年代物件的存亡特征,1974 年 Edward Lueders 提出了一種有針對性的 “標記-整理”(Mark-Compact)演算法, “標記-整理” 演算法的標記程序仍然與 “標記-清除” 演算法一樣,但后續的步驟不是直接對可回收物件進行清理, 而是讓所有存活的物件都向記憶體空間的一端移動,然后直接清理掉邊界以外的記憶體,
“標記-整理” 演算法的執行程序如圖所示,
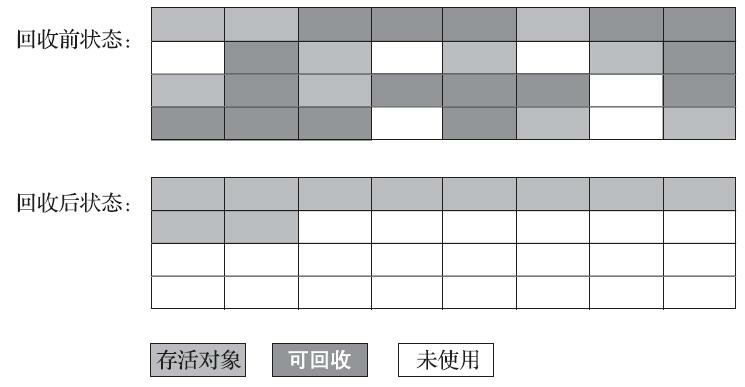
“標記-清除” 演算法與 “標記-整理” 演算法的本質差異在于 “標記-清除” 演算法是一種非移動式的回收演算法,而 “標記-整理” 演算法是一種移動式的回收演算法,是否移動回收后的存活物件是一項優缺點并存的風險決策:
- 如果移動存活物件,尤其是在老年代這種每次回收都有大量物件存活區域,移動存活物件并更新所有參考這些物件的地方將會是一種極為負重的操作,而且這種物件移動操作必須全程暫停用戶應用程式才能進行,這就更加讓使用者不得不小心翼翼地權衡其弊端了,像這樣的停頓被最初的虛擬機設計者形象地描述為 “Stop The World”,
- 但如果跟 “標記-清除” 演算法那樣完全不考慮移動和整理存活物件的話,彌散于 Java 堆中的存活物件導致的記憶體碎片化問題就只能依賴更為復雜的記憶體分配器和記憶體訪問器來解決,譬如通過 “磁區空閑分配鏈表” 來解決記憶體分配問題(計算機硬碟存盤大檔案就不要求物理連續的磁盤空間, 能夠在碎片化的硬碟上存盤和訪問就是通過硬碟磁區表實作的) ,記憶體的訪問是用戶程式最頻繁的操作,甚至都沒有之一,假如在記憶體訪問這個環節上增加了額外的負擔,勢必會直接影回應用程式的吞吐量,
基于以上兩點,是否移動物件都存在弊端,移動物件則記憶體回收時會更復雜,不移動物件則記憶體分配時會更復雜,從垃圾收集的停頓時間來看,不移動物件停頓時間會更短,甚至可以不需要停頓,但是從整個程式的吞吐量來看,移動物件會更劃算,即使不移動物件會使得收集器的效率提升一些, 但因記憶體分配和訪問相比垃圾收集的頻率要高得多,這部分的耗時增加,總吞吐量仍然是下降的,HotSpot 虛擬機里面關注吞吐量的 Parallel Scavenge 收集器是基于 “標記-整理” 演算法的,而關注延遲的 CMS 收集器則是基于 “標記-清除” 演算法的,這也從側面印證了這一點,
此語境中,吞吐量的實質是賦值器(Mutator,可以理解為使用垃圾收集的用戶程式,本書為便于理解,多數地方用 “用戶程式” 或 “用戶執行緒” 代替)與收集器的效率總和,
另外, 還有一種 “和稀泥式” 的解決方案可以不在記憶體分配和訪問上增加太大的額外負擔,做法是讓虛擬機平時多數時間都采用 “標記-清除” 演算法,暫時容忍記憶體碎片的存在,直到記憶體空間的碎片化程度已經大到影響物件分配時,再采用 “標記-整理” 演算法收集一次,以獲得規整的記憶體空間,前面提到的基于 “標記-清除” 演算法的 CMS 收集器面臨記憶體碎片過多時采用的就是這種處理辦法,
總結
分代收集理論
分代收集理論建立在兩個分代假說之上:
- 弱分代假說(Weak Generational Hypothesis):絕大多數物件都是朝生夕滅的,
- 強分代假說(Strong Generational Hypothesis):熬過越多次垃圾收集程序的物件就越難以消亡,
這兩個分代假說共同奠定了多款常用的垃圾收集器的一致的設計原則:垃圾收集器應該將 Java 堆劃分出不同的區域,然后將回收物件依據其年齡(年齡即物件熬過垃圾收集程序的次數)分配到不同的區域之中存盤,
在 Java 堆劃分出不同的區域之后,垃圾收集器才可以每次只回收其中某一個或者某些部分的區域,因而才有了 “Minor GC”、“Major GC”、“Full GC” 這樣的回收型別的劃分;也才能夠針對不同的區域 安排與里面存盤物件存亡特征相匹配的垃圾收集演算法,因而發展出了 “標記-清除演算法”、“標記-復制演算法”、“標記-整理演算法” 等針對性的垃圾收集演算法,
把分代收集理論具體放到現在的商用 Java 虛擬機里,設計者一般至少會把 Java 堆劃分為新生代(Young Generation) 和老年代(Old Generation)兩個區域,顧名思義,在新生代中,每次垃圾收集時都會發現有大批物件死去,而每次回收后存活的少量物件,將會逐步晉升到老年代中存放,
垃圾收集演算法
“標記-清除” 演算法
“標記-清除” 演算法分為 “標記” 和 “清除” 兩個階段:首先標記出所有需要回收的物件,在標記完成后,統一回收掉所有被標記的物件,也可以反過來,標記出所有存活的物件,在標記完成后,統一回收掉所有未被標記的物件,
后續的垃圾收集演算法大多是以 “標記-清除” 演算法為基礎,對 “標記-清除” 演算法的缺點進行改進而得到的,
“標記-復制” 演算法
“標記-清除” 演算法在有大量物件需要回收時,要進行大量的清除操作,垃圾收集的效率將會降低,為了解決這個問題,有一個人提出了 “標記-復制” 演算法,也被稱為 “半區復制”,“標記-復制” 演算法將可用記憶體按容量劃分為大小相等的兩塊,每次只使用其中的一塊,當這一塊記憶體用完時,就將還存活著的物件復制到另外一塊記憶體上,然后再將已使用過的記憶體空間一次清理掉,
“標記-整理” 演算法
“標記-復制” 演算法在物件存活率較高(多數物件都是存活的,幾乎沒有物件需要回收)時,要進行大量的復制操作,垃圾收集的效率將會降低,為了解決這個問題,有一個人提出了 “標記-整理” 演算法, “標記-整理” 演算法的標記程序仍然與 “標記-清除” 演算法一樣,但后續的步驟不是直接對可回收物件進行清理, 而是讓所有存活的物件都向記憶體空間的一端移動,然后直接清理掉邊界以外的記憶體,
不同演算法的優劣局限
不同垃圾收集演算法的優劣局限,
“標記-清除” 演算法的優劣局限:
- 第一個是:存在記憶體空間的碎片化問題,標記、清除之后會產生大量不連續的記憶體碎片,記憶體碎片太多可能會導致程式運行的程序中需要分配較大物件時,無法找到足夠的連續記憶體而不得不提前觸發另一次垃圾收集動作,
- 第二個是:執行效率不穩定,在有大量物件需要回收時,要進行大量的清除操作,垃圾收集的效率將會降低,
“標記-復制” 演算法的優劣局限:
- 第一個是:不存在記憶體空間的碎片化問題,當一塊記憶體用完時,就將還存活著的物件復制到另外一塊記憶體上,分配記憶體時也就不用考慮有空間碎片的復雜情況,只要移動堆頂指標,按順序分配即可,
- 第二個是:執行效率不穩定,在物件存活率較高(多數物件都是存活的,幾乎沒有物件需要回收)時,要進行大量的復制操作,垃圾收集的效率將會降低,
- 第三個是:空間浪費,“標記-復制” 演算法的代價是將可用記憶體縮小為了原來的一半,空間浪費有點多
“標記-整理” 演算法的優劣局限:
- 第一個是:不存在記憶體空間的碎片化問題,垃圾收集時,讓所有存活的物件都向記憶體空間的一端移動,然后直接清理掉邊界以外的記憶體,不存在記憶體空間的碎片化問題,
- 第二個是:停頓時間較長,垃圾收集時,需要移動存活的物件并更新所有參考這些物件的地方,這種物件移動操作必須全程暫停用戶應用程式才能進行,停頓時間較長,
“標記-清除” 演算法與 “標記-整理” 演算法的本質差異在于 “標記-清除” 演算法是一種非移動式的回收演算法,而 “標記-整理” 演算法是一種移動式的回收演算法,是否移動回收后的存活物件是一項優缺點并存的風險決策,
- 移動回收后的存活物件,不存在記憶體空間的碎片化問題,但記憶體回收時會更復雜(需要移動存活的物件并更新所有參考這些物件的地方);
- 不移動回收后的存活物件,記憶體回收時的停頓時間會更短,甚至可以不需要停頓,但是記憶體分配時會更復雜(需要考慮記憶體空間的碎片化問題),
參考資料
《深入理解 Java 虛擬機》第 3 章:垃圾收集器與記憶體分配策略 3.3 垃圾收集演算法
本文來自博客園,作者:真正的飛魚,轉載請注明原文鏈接:https://www.cnblogs.com/feiyu2/p/17289007.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/549214.html
標籤:其他
上一篇:C語言結構體大小分析
下一篇:逍遙自在學C語言 | 關系運算子