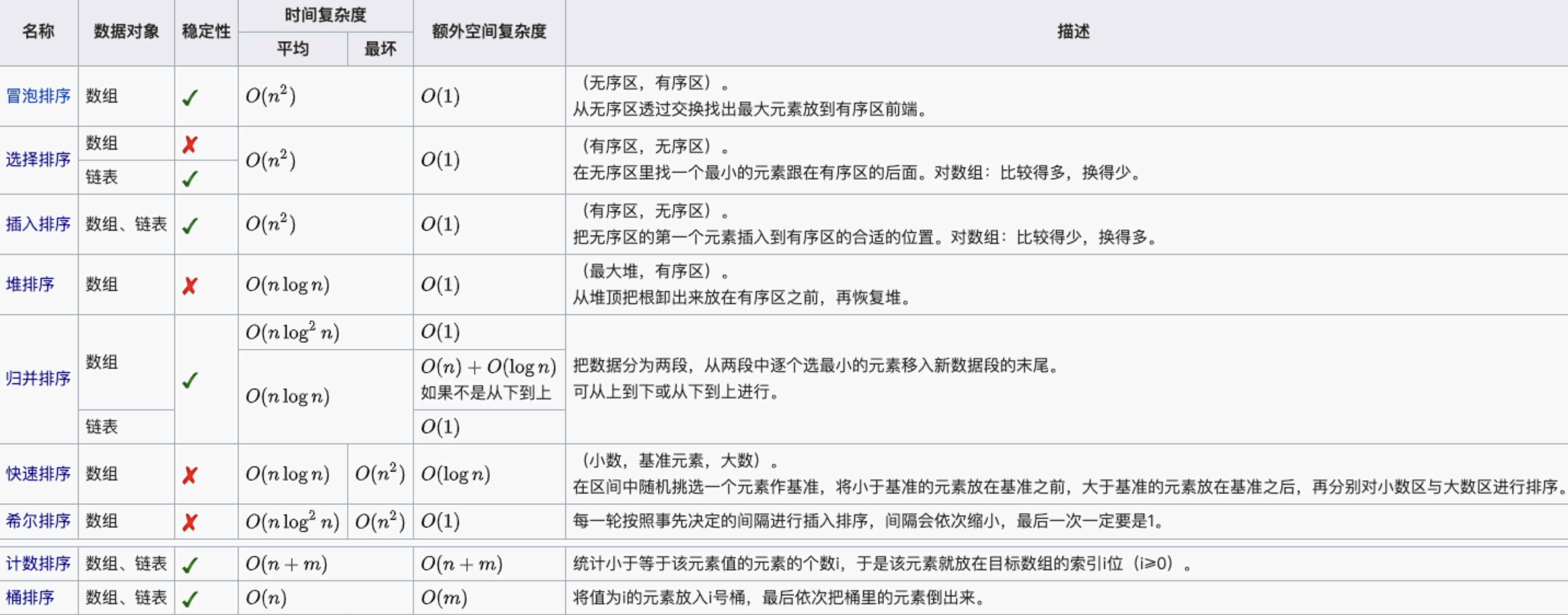
python實作各種排序
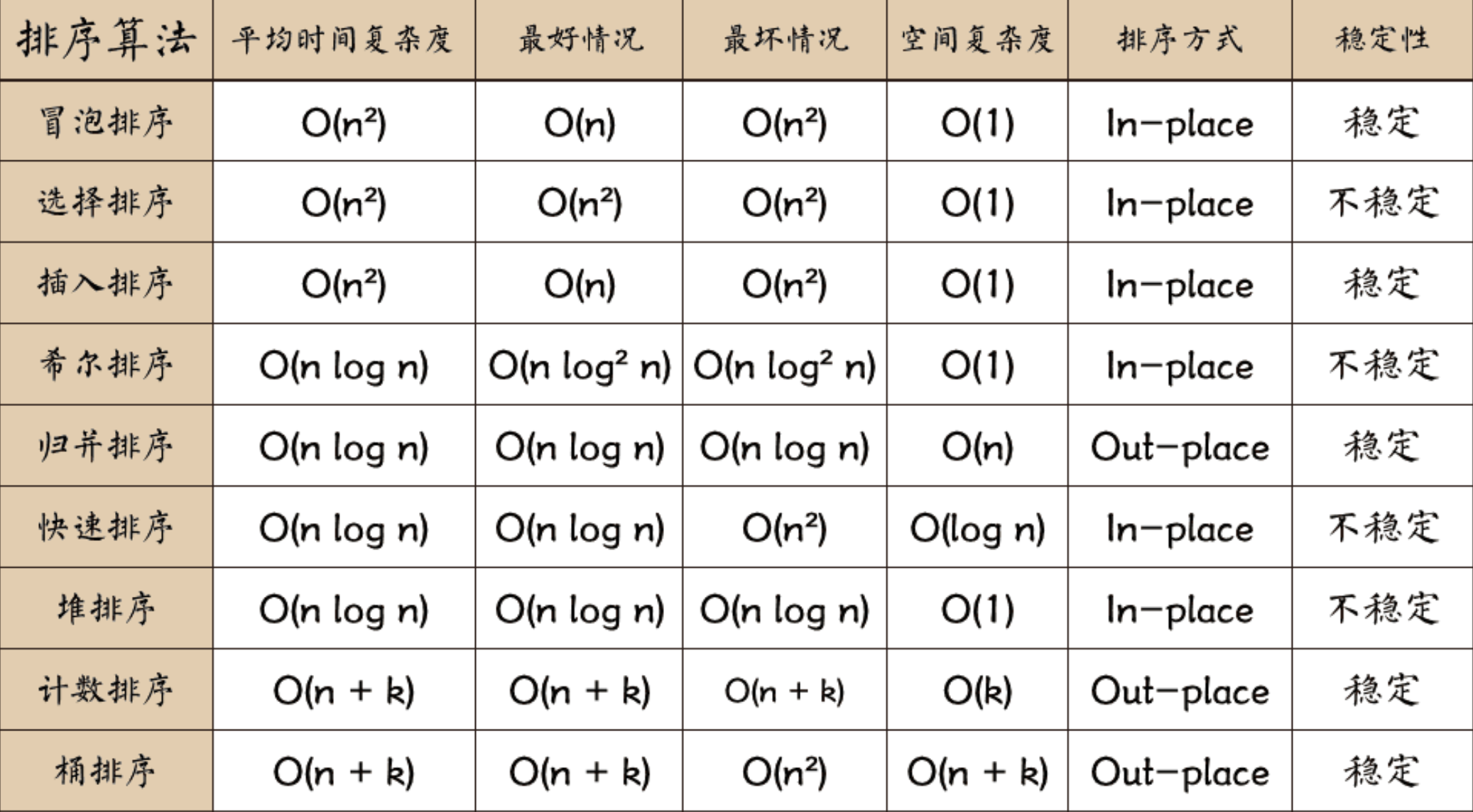
1. 快速排序
1:首先取序列第一個元素為基準元素pivot=R[low],i=low,j=high,
2:從后向前掃描,找小于等于pivot的數,如果找到,R[i]與R[j]交換,i++,
3:從前往后掃描,找大于pivot的數,如果找到,R[i]與R[j]交換,j--,
4:重復2~3,直到i=j,回傳該位置mid=i,該位置正好為pivot元素, 完成一趟排序后,以mid為界,將序列分為兩部分,左序列都比pivot小,有序列都比pivot大,然后再分別對這兩個子序列進行快速排序,
以序列(30,24,5,58,16,36,12,42,39)為例,進行演示:
1、初始化,i=low,j=high,pivot=R[low]=30:
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 30 | 24 | 5 | 58 | 16 | 26 | 12 | 41 | 39 |
2、從后往前找小于等于pivot的數,找到R[j]=12
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 30 | 24 | 5 | 58 | 16 | 26 | 12 | 41 | 39 |
- R[i]與R[j]交換,i++
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 58 | 16 | 26 | 30 | 41 | 39 |
3、從前往后找大于pivot的數,找到R[i]=58
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 58 | 16 | 26 | 30 | 41 | 39 |
- R[i]與R[j]交換,j--
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 30 | 16 | 26 | 58 | 41 | 39 |
4、從后往前找小于等于pivot的數,找到R[j]=16
| i | j | |||||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 30 | 16 | 26 | 58 | 41 | 39 |
- R[i]與R[j]交換,i++
| i,j | ||||||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 16 | 30 | 26 | 58 | 41 | 39 |
5、從前往后找大于pivot的數,這時i=j,第一輪排序結束,回傳i的位置,mid=i
| Low | mid-1 | mid | mid+1 | High | ||||
|---|---|---|---|---|---|---|---|---|
| 12 | 24 | 5 | 16 | 30 | 26 | 58 | 41 | 3 |
此時已mid為界,將原序列一分為二,左子序列為(12,24,5,18)元素都比pivot小,右子序列為(36,58,42,39)元素都比pivot大,然后在分別對兩個子序列進行快速排序,最后即可得到排序后的結果,
def quicksort(low,high,li):
if low >= high:
return li
i = low
j= high
pivot = li[low]
while i<j:
while i<j and li[j]>pivot:
j -= 1
li[i] = li[j]
while i<j and li[i]<pivot:
i += 1
li[j] = li[i]
li[j] = pivot
quicksort(low,i-1,li)
quicksort(i+1,high,li)
return li
lists=[30,24,5,58,18,36,12,42,39]
print("排序前的序列為:")
for i in lists:
print(i,end =" ")
print("\n排序后的序列為:")
for i in quicksort(0,len(lists)-1,lists):
print(i,end=" ")
2. 冒泡排序
冒泡排序(英語:Bubble Sort)是一種簡單的排序演算法,它重復地遍歷要排序的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來,遍歷數列的作業是重復地進行直到沒有再需要交換,也就是說該數列已經排序完成,這個演算法的名字由來是因為越小的元素會經由交換慢慢“浮”到數列的頂端,
冒泡排序演算法的運作如下:
- 比較相鄰的元素,如果第一個比第二個大(升序),就交換他們兩個,
- 對每一對相鄰元素作同樣的作業,從開始第一對到結尾的最后一對,這步做完后,最后的元素會是最大的數,
- 針對所有的元素重復以上的步驟,除了最后一個,
- 持續每次對越來越少的元素重復上面的步驟,直到沒有任何一對數字需要比較,
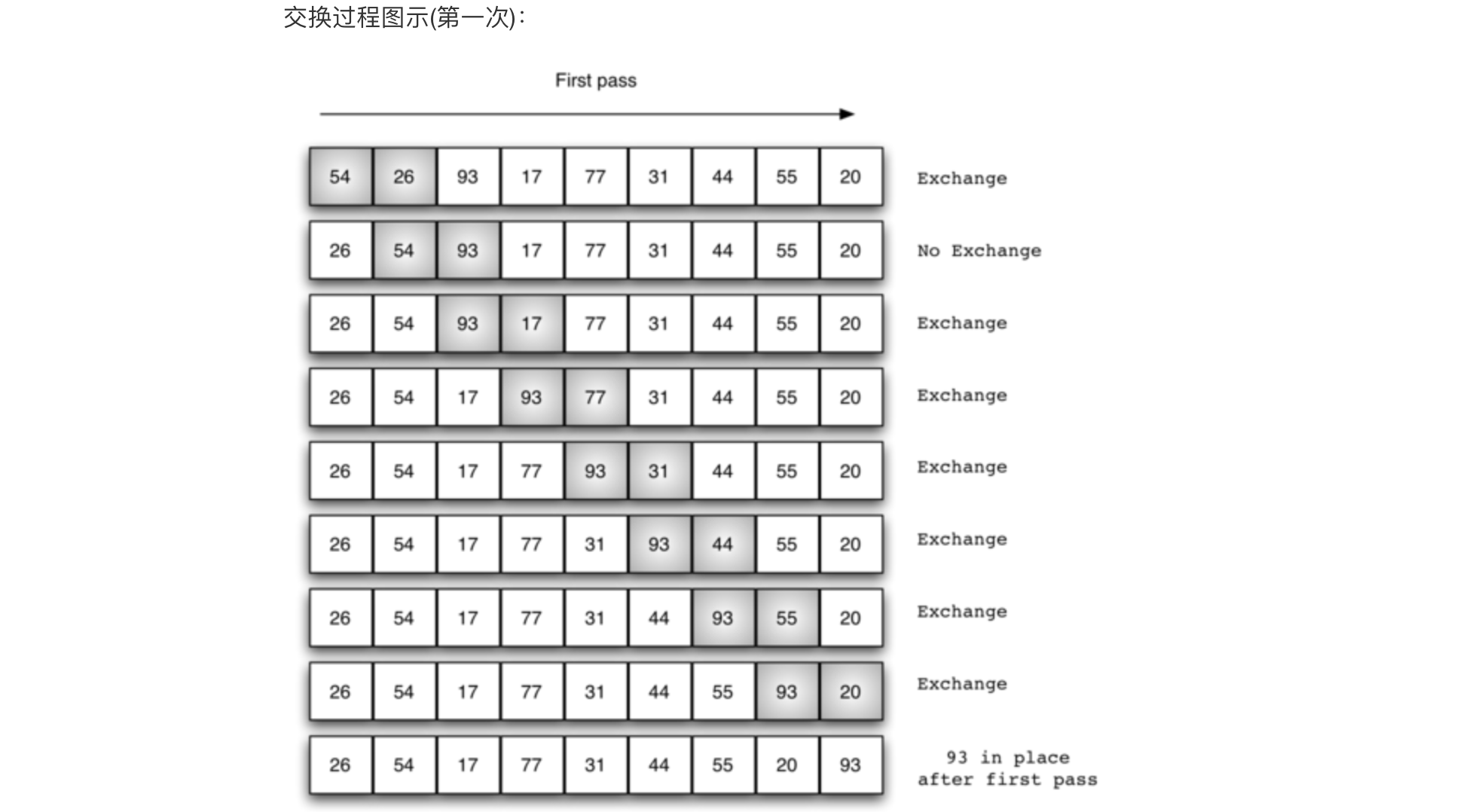
def bubblesort(li):
for i in range(len(li)-1,0,-1):
for j in range(1,i):
if li[j-1]>li[j]:
li[j-1],li[j] = li[j],li[j-1]
return li
li = [54,26,93,17,77,31,44,55,20]
print(bubblesort(li))
3. 插入排序
插入排序(Insertion Sort)是一種簡單直觀的排序演算法,它的作業原理是:通過構建有序序列,對于未排序資料,在已排序序列中從后向前掃描,找到相應位置并插入,
- 從第一個元素開始,該元素可以認為已經被排序;
- 取出下一個元素,在已經排序的元素序列中從后向前掃描;
- 如果該元素(已排序)大于新元素,將該元素移到下一位置;
- 重復步驟3,直到找到已排序的元素小于或者等于新元素的位置;
- 將新元素插入到該位置后;
- 重復步驟2~5,
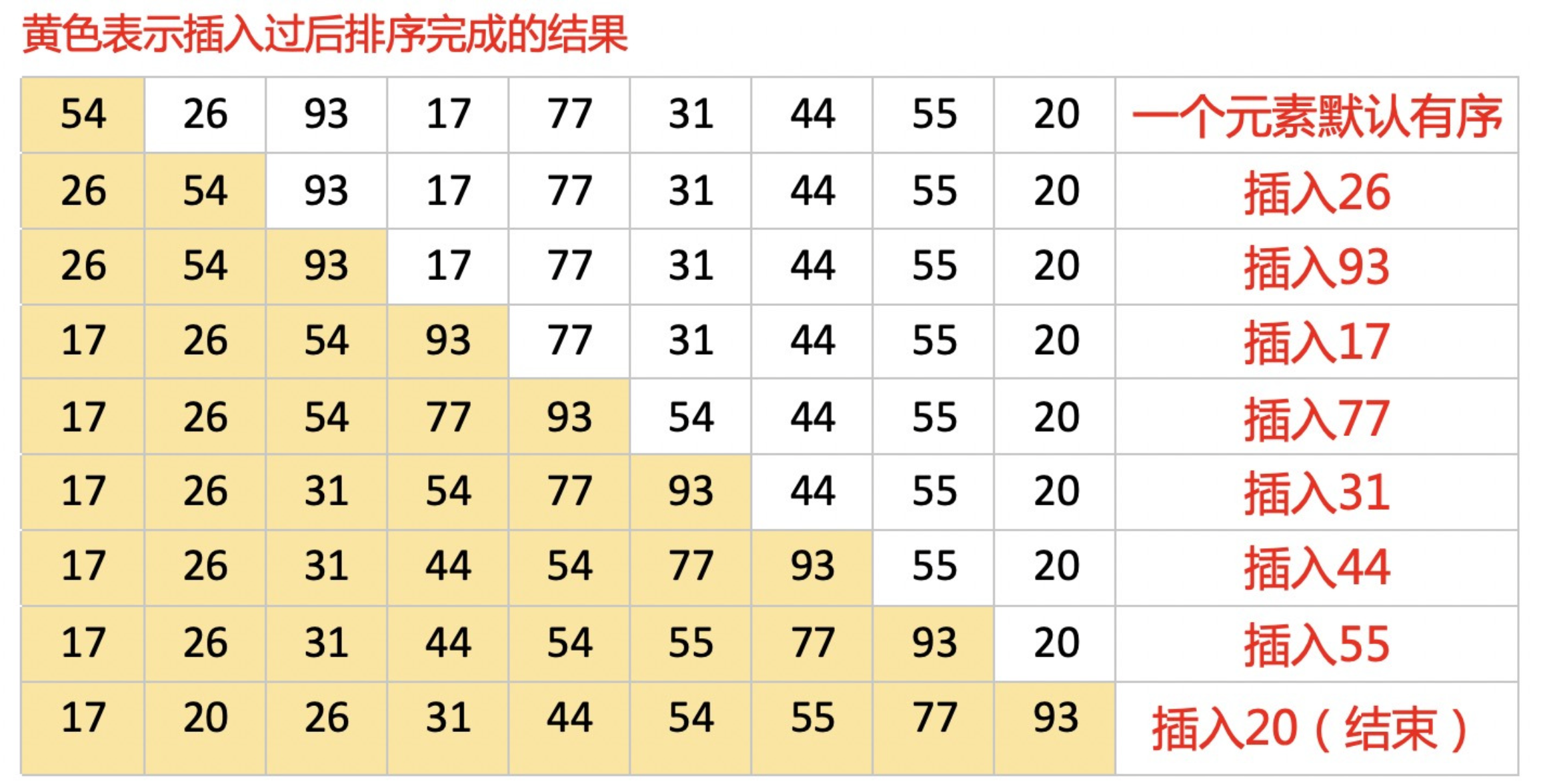
這個演算法和冒泡排序有點類似,都是兩層for回圈,一個是從正面挨個比,一個是倒著比
def insertsort(li):
for i in range(1,len(li)):
for j in range(i,0,-1):
if li[j-1]>li[j]:
li[j-1],li[j] = li[j],li[j-1]
return li
li = [54,26,93,17,77,31,44,55,20]
print(insertsort(li))
4. 希爾排序
希爾排序是先取一個小于待排序串列長度的正整數d1,把所有距離為d1的資料看成一組,在組內進行插入排序,然后取一個小于d1的正整數d2,繼續用d2分組和進行組內插入排序,每次取的分組距離越來越小,組內的資料越來越多,直到di=1,所有資料被分成一組,再進行插入排序,則串列排序完成,
希爾排序是基于插入排序進行優化的排序演算法,在插入排序中,如果資料幾乎已經排好序時,效率是很高的(想一下抓牌和插牌),時間復雜度為 O(n) ,但資料的初始狀態并不一定是“幾乎已經排好序”的,用插入排序每步只能將待插入資料往前移動一位,而希爾排序將資料分組后,每次可以往前移動di位,在di>1時進行的分組和組內排序可以將資料變成“幾乎排好序”的狀態,此時再進行最后一次插入排序,提高效率,
希爾排序的原理如下:
-
選擇小于待排序串列長度 n 的正整數序列 d1,d2,...,di,其中 n>d1, d(i-1)>di, di=1 ,作為資料的間隔距離對串列進行分組,這里對 di 的取值和個數沒有要求,只要是整數,d1<n,依次變小即可,
-
依次用 d1, ..., di 作為資料的距離對串列進行分組和組內插入排序,一共需要進行 i 輪排序,
-
在最后一輪排序前,串列中的資料達到了“幾乎排好序”的狀態,此時進行最后一輪插入排序,
以串列 [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21] 進行升序排列為例,
要進行升序排列,則分組后所有組內插入排序都進行升序排列,本例中以串列長度的length/3作為初始的分組距離 d1 ,d1=4,
-
從串列的開頭開始,對所有資料按 d1 作為距離進行分組,分組只保證資料的間隔距離相等,不保證每組的資料個數一樣,只是本例中剛好每組資料一樣多,本例的資料可以分為4組,也就是第1,5,9作為排序物件,然后2,6,10;3,7,11;4,8,12.一共要排序4次,排完序為
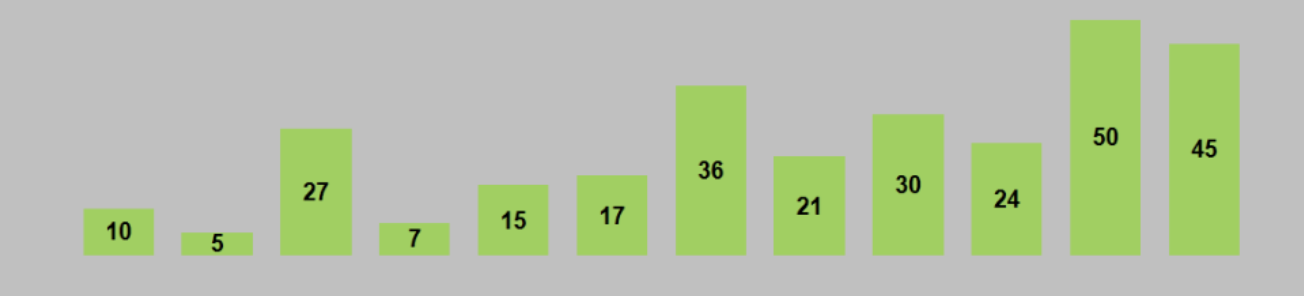
-
第二次排序的話,這個距離為4//3 = 1,也就是最后一輪排序,這也和直接插入排序完全一樣了,先將第一個資料作為已排序序列,后面的資料作為未排序序列,然后依次將未排序序列中的資料插入到已排序序列中,
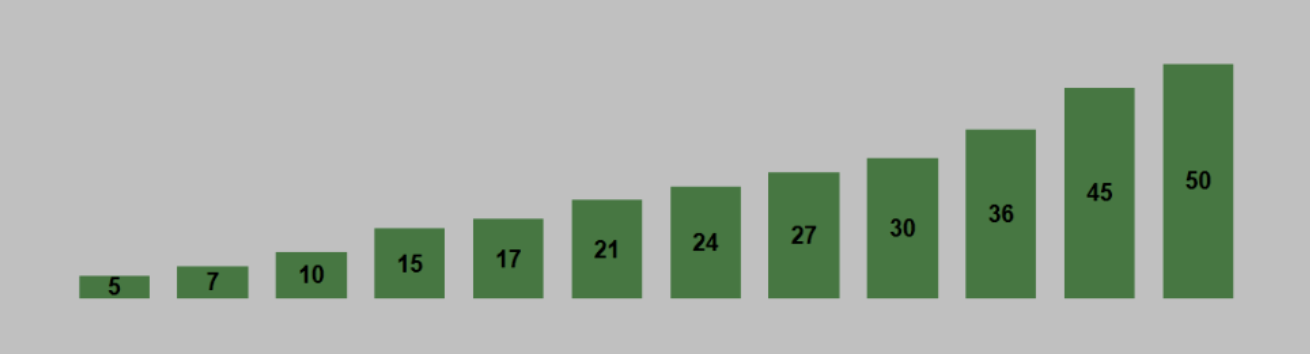
def shellsort(li):
n = len(li)
gap = n//3
while gap > 0:
for i in range(gap,n):
j = i
while j>=gap and li[j-gap]>li[j]:
li[j-gap],li[j] = li[j],li[j-gap]
j -= gap
gap = gap//3
alist = [54,26,93,17,77,31,44,55,20]
shellsort(alist)
print(alist)
5. 歸并排序
將原問題劃分成 n 個規模較小而結構與原問題相似的子問題;遞回地解決這些問題,然后再合并其結果,就得到原問題的解,從上圖看分解后的數列很像一個二叉樹,
歸并排序采用分而治之的原理:
- 將一個序列從中間位置分成兩個序列;
- 在將這兩個子序列按照第一步繼續二分下去;
- 直到所有子序列的長度都為1,也就是不可以再二分截止,這時候再兩兩合并成一個有序序列即可,

def merge(left,right):
r,l = 0,0
res = []
while r < len(right) and l < len(left):
if left[l] < right[r]: # 排序,小于等于的放左邊
res.append(left[l])
l += 1
else:
res.append(right[r]) # 排序,大的放右邊
r += 1
res +=(left[l:])
res +=(right[r:])
return res
def mergesort(li):
if(len(li)) <2:
return li
mid = len(li)//2
left = mergesort(li[:mid])
right = mergesort(li[mid:])
return merge(left,right)
li = [8,0,4,3,6,2]
print(mergesort(li))
6. 選擇排序
選擇排序(Selection sort)是一種簡單直觀的排序演算法,它的作業原理如下,首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再從剩余未排序元素中繼續尋找最小(大)元素,然后放到已排序序列的末尾,以此類推,直到所有元素均排序完畢,
選擇排序的主要優點與資料移動有關,如果某個元素位于正確的最終位置上,則它不會被移動,選擇排序每次交換一對元素,它們當中至少有一個將被移到其最終位置上,因此對n個元素的表進行排序總共進行至多n-1次交換,在所有的完全依靠交換去移動元素的排序方法中,選擇排序屬于非常好的一種,

def selection_sort(alist):
n = len(alist)
# 需要進行n-1次選擇操作
for i in range(n-1):
# 記錄最小位置
min_index = i
# 從i+1位置到末尾選擇出最小資料
for j in range(i+1, n):
if alist[j] < alist[min_index]:
min_index = j
# 如果選擇出的資料不在正確位置,進行交換
if min_index != i:
alist[i], alist[min_index] = alist[min_index], alist[i]
alist = [54,226,93,17,77,31,44,55,20]
selection_sort(alist)
print(alist)
7. 堆排序
堆排序(Heap Sort)是利用堆這種資料結構而設計的一種排序演算法,是一種選擇排序,
堆是具有以下性質的完全二叉樹:每個結點的值都大于或等于其左右孩子結點的值,稱為大頂堆;或者每個結點的值都小于或等于其左右孩子結點的值,稱為小頂堆,
堆排序思路為: 將一個無序序列調整為一個堆,就能找出序列中的最大值(或最小值),然后將找出的這個元素與末尾元素交換,這樣有序序列元素就增加一個,無序序列元素就減少一個,對新的無序序列重復操作,從而實作排序,
演算法實作步驟
- 構造初始堆,將給定無序序列構造成一個大頂堆(一般升序采用大頂堆,降序采用小頂堆);
- 將堆頂元素與末尾元素進行交換,使末尾元素最大,然后繼續調整堆,再將堆頂元素與末尾元素交換,得到第二大元素;
- 重新調整結構,使其滿足堆定義,然后繼續交換堆頂元素與當前末尾元素;
- 如此反復進行交換、重建、交換,直到整個序列有序,
def heap_sort(array):
first = len(array) // 2 - 1
for start in range(first, -1, -1):
# 從下到上,從右到左對每個非葉節點進行調整,回圈構建成大頂堆
big_heap(array, start, len(array) - 1)
for end in range(len(array) - 1, 0, -1):
# 交換堆頂和堆尾的資料
array[0], array[end] = array[end], array[0]
# 重新調整完全二叉樹,構造成大頂堆
big_heap(array, 0, end - 1)
return array
def big_heap(array, start, end):
root = start
# 左孩子的索引
child = root * 2 + 1
while child <= end:
# 節點有右子節點,并且右子節點的值大于左子節點,則將child變為右子節點的索引
if child + 1 <= end and array[child] < array[child + 1]:
child += 1
if array[root] < array[child]:
# 交換節點與子節點中較大者的值
array[root], array[child] = array[child], array[root]
# 交換值后,如果存在孫節點,則將root設定為子節點,繼續與孫節點進行比較
root = child
child = root * 2 + 1
else:
break
if __name__ == '__main__':
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
print(heap_sort(array))
8. 計數排序
計數排序(Counting Sort)是一種不比較資料大小的排序演算法,是一種犧牲空間換取時間的排序演算法,
計數排序適合資料量大且資料范圍小的資料排序,如對人的年齡進行排序,對考試成績進行排序等,
計數排序先找到待排序串列中的最大值 k,開辟一個長度為 k+1 的計數串列,計數串列中的所有初始值都為 0,走訪待排序串列,如果走訪到的元素值為 i,則計數串列中索引 i 的值加1,走訪完整個待排序串列,就可以統計出待排序串列中每個值的數量,然后創建一個新串列,根據計數串列中統計的數量,依次在新串列中添加對應數量的 i ,得到排好序的串列,
def counting_sort(array):
if len(array) < 2:
return array
max_num = max(array)
count = [0] * (max_num + 1)
for num in array:
count[num] += 1
new_array = list()
for i in range(len(count)):
for j in range(count[i]):
new_array.append(i)
return new_array
if __name__ == '__main__':
array = [5, 7, 3, 7, 2, 3, 2, 5, 9, 5, 7, 6]
print(counting_sort(array))
9. 桶排序
桶排序(Bucket sort)是一種通過分桶和合并實作的排序演算法,又被稱為箱排序,
桶排序先將資料分到有限數量的桶里,然后對每一個桶內的資料進行排序(桶內排序可以使用任何一種排序演算法,如快速排序),最后將所有排好序的桶合并成一個有序序列,串列排序完成,
桶排序需要占用很多額外的空間,對桶內資料進行排序,選擇哪種排序演算法對于性能的影響至關重要,桶排序適用的場景并不多,用得多一點的是基于桶排序思想的計數排序和基數排序,
桶排序的原理如下:
-
求出待排序串列中的最大值和最小值,得到資料的范圍,
-
根據資料的范圍,選擇一個適合的值構建有限數量的桶,確定每個桶的資料范圍,如資料范圍是[0,100),將資料分成10個桶,第一個桶為[0,10),第二個桶為[10,20),以此類推,
-
將待排序串列中的資料分配到對應的桶中,
-
對每一個桶內的資料進行排序,這里可以采用任意一種排序演算法,建議采用時間復雜度小的排序演算法,
-
將所有桶中的資料依次取出,添加到一個新的有序序列中,串列排序完成,
# coding=utf-8
def bucket_sort(array):
min_num, max_num = min(array), max(array)
bucket_num = (max_num-min_num)//3 + 1
buckets = [[] for _ in range(int(bucket_num))]
for num in array:
buckets[int((num-min_num)//3)].append(num)
new_array = list()
for i in buckets:
for j in sorted(i):
new_array.append(j)
return new_array
if __name__ == '__main__':
array = [5, 7, 3, 7, 2, 3, 2, 5, 9, 5, 7, 8]
print(bucket_sort(array))
本文來自博客園,作者:ivanlee717,轉載請注明原文鏈接:https://www.cnblogs.com/ivanlee717/p/17292751.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/549270.html
標籤:Python