
大資料時代,各行各業對資料采集的需求日益增多,網路爬蟲的運用也更為廣泛,越來越多的人開始學習網路爬蟲這項技術,K哥爬蟲此前已經推出不少爬蟲進階、逆向相關文章,為實作從易到難全方位覆寫,特設【0基礎學爬蟲】專欄,幫助小白快速入門爬蟲,本期為自動化工具 Selenium 的使用,
概述
目前,很多網站都采用 Ajax 等技術進行動態加載資料,想要采集這類網站的資料,需要通過抓包對網站的資料介面進行分析,去尋找想要采集的資料由哪個介面傳輸,而且,就算找到了資料介面,這些介面可能也是被加密過的,想要通過介面獲取資料,需要對加密引數進行逆向分析,這個程序對于初學者來說非常復雜,
為了解決這些問題,能夠更加簡單的進行爬取資料,我們可以使用到一些自動化工具,如 Selenium、playwright、pyppeteer 等,這些工具可以模擬瀏覽器運行,直接獲取到資料加載完成后的網頁原始碼,這樣我們就可以省去復雜的抓包、逆向流程,直接拿到資料,
Selenium 的使用
介紹
Selenium 是一個流行的自動化測驗框架,可用于測驗 Web 應用程式的用戶界面,它支持多種編程語言,如Java、Python、Ruby等,并提供了一系列 API,可以直接操作瀏覽器進行測驗,
安裝
使用 selenium 首先需要下載瀏覽器驅動檔案,這里以谷歌瀏覽器為例,在驅動下載頁面找到與自己瀏覽器版本最為接近的檔案,如我的谷歌瀏覽器版本為 112.0.5615.86,最接近的檔案為 112.0.5615.49,選擇此檔案,下載對應系統版本的壓縮包,將壓縮包中的chromedriver.exe程式放到python目錄中,因為正常情況下Python在安裝時就會被添加到系統環境變數之中,將chromedriver.exe放到Python目錄下它就可以在任意位置被執行,

添加好驅動檔案后需要安裝 Python 的第三方庫 selenium,
pip install selenium
使用
Selenium 支持多種瀏覽器,如谷歌、火狐、Edge、Safari等,這里我們以谷歌瀏覽器為例,
from selenium import webdriver
# 初始化瀏覽器物件
driver = webdriver.Chrome()
# 驅動瀏覽器打開目標網址
driver.get('https://www.baidu.com/')
# 列印當前頁面的源代碼
print(driver.page_source)
# 關閉瀏覽器
driver.quit()
運行代碼后我們會發現自動打開了一個瀏覽器,訪問了目標網址,在控制臺輸出了頁面的源代碼,然后自動關閉,
Selenium 提供了一系列實用的 Api,通過它我們可以實作更多操作,
元素查找
在之前的文章《決議庫的使用》中,我們已經講到了 Xpath、bs4 這兩個庫的使用方法,講到了 Xpath 的路徑運算式和 CSS 選擇器,因此這里主要講解定位方法,路徑運算式與 CSS 選擇器的使用可以去前文中了解,
以京東首頁為例,想要獲取秒殺欄目的商品資訊,我們可以通過多種方法來進行定位,
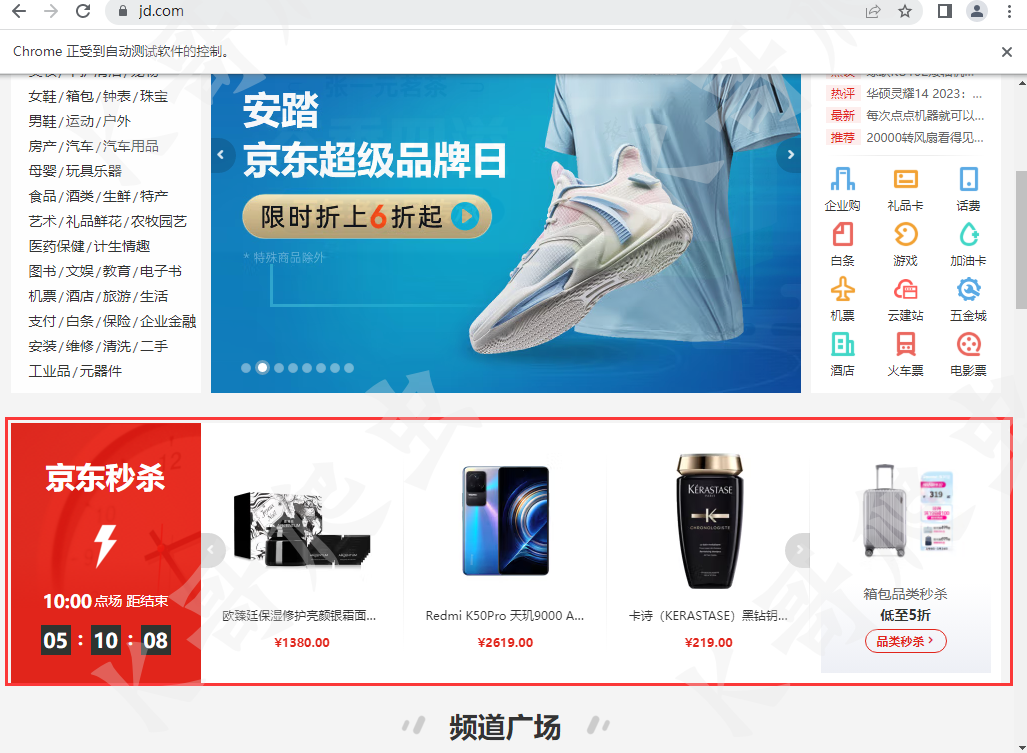
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.jd.com/')
# 根據 Xpath 定位
goods_xpath = driver.find_elements(By.XPATH, '//div[@]/div/a[@]')
# 根據 Css 選擇器定位
goods_css = driver.find_elements(By.CSS_SELECTOR, 'a[]')
# 根據類名定位
goods_class_name = driver.find_elements(By.CLASS_NAME,'seckill-item')
print(goods_xpath)
for goods in goods_xpath:
# 輸出節點的文本資訊
print(goods.text)
driver.quit()
# [<selenium.webdriver.remote.webelement.WebElement(session="f49c1906753e404ca0a017...]
# 歐臻廷保濕修護亮顏銀霜面霜70ml護膚品化妝品乳液滋潤送女友禮物禮盒款
# ¥1380.00
# Redmi K50Pro 天璣9000 AMOLED 2K柔性直屏 OIS光學防抖 120W快充 幻鏡 8GB+256GB 5G智能手機 小米紅米
# ¥2619.00
# 卡詩(KERASTASE)黑鉆鑰源魚子醬洗發水250ml 改善毛躁呵護受損
# ¥219.00
除了示例代碼中的,還有其它定位方法:
driver.find_elements(By.ID,'ID')
driver.find_elements(By.LINK_TEXT,'LINK_TEXT')
driver.find_elements(By.PARTIAL_LINK_TEXT,'PARTIAL_LINK_TEXT')
driver.find_elements(By.TAG_NAME,'TAG_NAME')
元素互動
Selenium 可以實作對頁面中元素的點擊、輸入等操作,
想要采集京東的指定商品資訊,首先需要在輸入框輸入商品名稱,然后點擊搜索按鈕,網頁就會跳轉到搜索頁面,展示我們搜索的商品資訊,這個流程我們也可以通過 Selenium 來模擬實作,
driver.get('https://www.jd.com/')
# 獲取搜索框
search = driver.find_element(By.XPATH,'//div[@role="serachbox"]/input')
# 獲取查詢按鈕
button = driver.find_element(By.XPATH,'//div[@role="serachbox"]/button')
# 在搜索框中輸入 Python
search.send_keys('Python')
# 點擊查詢按鈕
button.click()
等待
在我們使用 Selenium 時會遇到以下兩種情況:
- 頁面未加載完畢,但是我們需要的元素已經加載完畢
- 頁面加載完畢,但是我們需要的元素為加載完畢
Selenium 的 get 方法是默認等待頁面加載完畢后再執行下面的操作,在遇到第一種情況時,要采集的資料已經生成了,但是可能由于某個資源加載緩慢導致頁面一直在加載中狀態,這樣 Selenium 就會一直等待頁面完全加載,造成采集速度緩慢等問題,而情況二,頁面已經加載完成了,但是要采集的資料依舊沒有渲染出來,這就使 Selenium 定位元素失敗導致程式例外,為了避免解決這兩種情況,我們可以設定不等待頁面完全加載,只等待目標元素加載完畢,
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
caps = DesiredCapabilities().CHROME
#不等待頁面加載
caps["pageLoadStrategy"] = "none"
driver = webdriver.Chrome(desired_capabilities=caps)
強制等待
使用 time.sleep() 實作強制等待,不推薦使用,
driver.get('https://www.jd.com/')
# 強制休眠6秒
time.sleep(6)
隱式等待
等待頁面加載的時間,當頁面加載完成后執行下一步,如果加載時間超過設定的時間時直接執行下一步,不推薦使用,
# 隱式等待10秒
driver.implicitly_wait(10)
driver.get('https://www.jd.com/')
顯式等待
等待條件滿足后執行下一步,條件不滿足則一直等待,當超過設定的時間時拋出例外,推薦使用,
from selenium import webdriver
import selenium.common.exceptions
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://www.jd.com/')
try:
WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, 'a[]')
)
)
except selenium.common.exceptions.TimeoutException:
print('元素加載超時')
當 CSS 選擇器指向的元素存在時則執行下一部,不存在則繼續等待,直到超過設定的10秒,拋出超時例外,
Actions
上文中講到了元素互動,其中點擊、輸入行為都是屬于 Selenium 的動作 Api 之中的,除此之外,Selenium還提供了非常豐富的動作 Api,這里只介紹常用的方法,
滑鼠操作
from selenium.webdriver import ActionChains
# 單擊元素并按住
clickable = driver.find_element(By.ID, "clickable")
ActionChains(driver).click_and_hold(clickable).perform()
# 雙擊,將滑鼠移動到元素中心并雙擊
clickable = driver.find_element(By.ID, "clickable")
ActionChains(driver).double_click(clickable).perform()
# 按偏移量移動滑鼠
mouse_tracker = driver.find_element(By.ID, "mouse-tracker")
ActionChains(driver).move_to_element_with_offset(mouse_tracker, 8, 0).perform()
# 按當前指標位置進行偏移,如之前沒有移動滑鼠,則默認在視窗的左上角,(13, 15)為橫縱坐標的偏移值,13為向右移動13,15為向下移動15,負數則反之,
ActionChains(driver).move_by_offset( 13, 15).perform()
# 按偏移拖放,點擊元素并按鈕,移動指定偏移量,然后釋放滑鼠
draggable = driver.find_element(By.ID, "draggable")
start = draggable.location
finish = driver.find_element(By.ID, "droppable").location
ActionChains(driver).drag_and_drop_by_offset(draggable, finish['x'] - start['x'], finish['y'] - start['y']).perform()
滾輪
# 滾動到指定元素
iframe = driver.find_element(By.TAG_NAME, "iframe")
ActionChains(driver).scroll_to_element(iframe).perform()
# 按給定值滾動,(0, delta_y) 為向右和向下滾動的量,負值則反之,
footer = driver.find_element(By.TAG_NAME, "footer")
delta_y = footer.rect['y']
ActionChains(driver).scroll_by_amount(0, delta_y).perform()
反檢測
Selenium 有著非常明顯的缺陷,就是容易被網站檢測到,我們通過 Selenium 打開網頁時會發現,視窗上方會顯示瀏覽器正受到自動測驗軟體的控制,這就說明 Selenium 驅動瀏覽器與用戶正常打開瀏覽器是不同的,它存在著許多 WebDriver 的特征,網站可以通過檢測這些特征來禁止 Selenium 訪問,

我們可以通過一些特征值檢測的網站來對比正常訪問與 Selenium 訪問的區別,
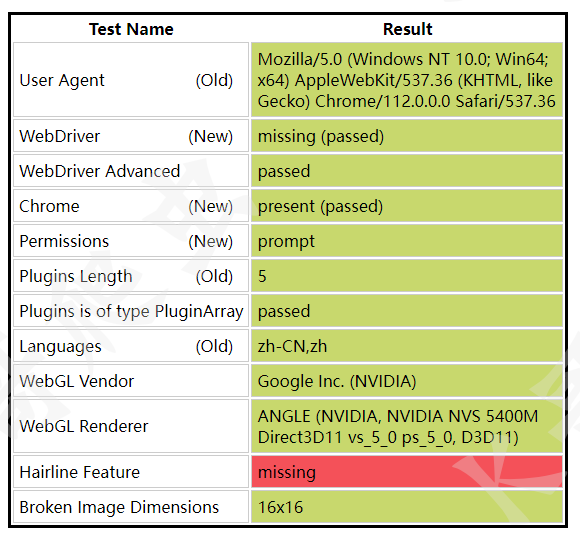
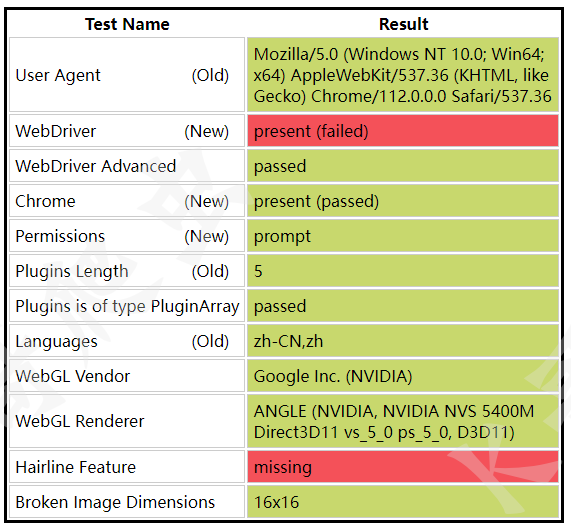
上面是正常訪問,下面是 Selenium 訪問,可以很清晰的看到 WebDriver 一欄標紅了,這就說明 Selenium 被檢測到了,網站的檢測原理主要是通過檢查 window.navigator 物件中是否存在 webdriver 屬性,我們了解到這一點后,可以通過一些操作來修改window.navigator 物件,在頁面未加載時將它的 webdriver 屬性設定為 false,這樣或許就能避開網站的檢測機制,
from selenium import webdriver
from selenium.webdriver import ChromeOptions
options = ChromeOptions()
# 以最高權限運行
options.add_argument('--no-sandbox')
# navigator.webdriver 設定為 false
options.add_argument("--disable-blink-features=AutomationControlled")
# 隱藏"Chrome正在受到自動軟體的控制"提示
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=options)
with open('./stealth.min.js', 'r') as f:
js = f.read()
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {'source': js})
可以看到,我們進行了一些隱藏特征的操作,但在最后我們讀取一個檔案,然后將這個檔案資訊傳入到了execute_cdp_cmd()方法中,這個操作其實也是在隱藏特征,
stealth.min.js 來自于 puppeteer 的一個插件,puppeteer 是一個控制 headless Chrome 的 Node.js API ,puppeteer 有一個插件名為 puppeteer-extra-plugin-stealth,它的開發目的就是為了防止 puppeteer 被檢測,它可以隱藏許多自動化特征,puppeteer-extra 的作者也撰寫了一個腳本,用于將最新的特征隱藏方法puppeteer-extra-stealth 提取到 JS 檔案之中,生成的 JS 檔案可以用于純 CDP 實作,也可以用于測驗開發工具中的檢測規避,而 Selenium 正好支持 CDP 的呼叫,CDP 全稱(Chrome DevTools Protocol),利用它可以在瀏覽器加載之前執行 JS 陳述句,
如果你已經安裝了 node.js ,npx extract-stealth-evasions 執行此命令就可以生成 stealth.min.js 檔案,下圖就隱藏特征后訪問結果,
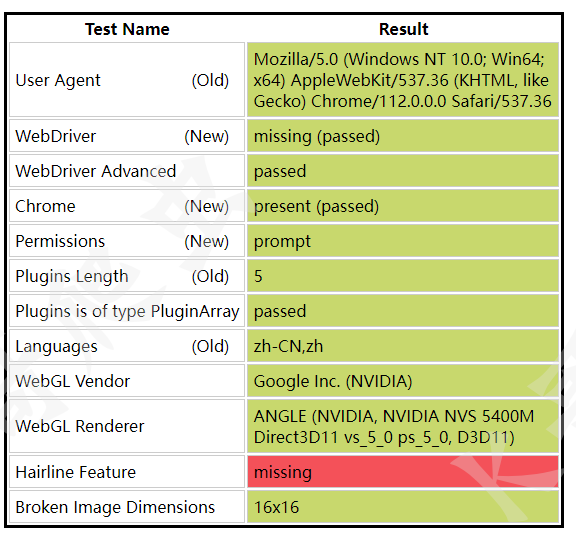
無頭模式
無頭模式下網站運行不會彈出視窗,可以減少一些資源消耗,也避免了瀏覽器視窗運行時對設備正常使用帶來的影響,在服務器上運行需要用到,但是無頭模式下被網站檢測的特征點非常多,因此需要根據自己的應用場景來使用,
options = ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
總結
使用 Selenium 來進行資料的爬取是一種優勢與劣勢都非常明顯的選擇,它的優勢就是簡單,不需要對網站進行除錯,不需要關注資料的來源,大大減少了爬蟲程式的開發時間,它的劣勢有多種:采集效率低,資源占用大,不穩定,容易被檢測,且需要依賴于 WebDriver,當瀏覽器更新后就需要更新對應的 WebDriver,因此 Selenium 適用于那些逆向難度較大,且對采集效率要求不高的場景,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/550629.html
標籤:Python
上一篇:24道Python面試練習題
下一篇:返回列表