mysql磁區型別
日常開發中我們經常會遇到大表的情況,所謂的大表是指存盤了百萬級乃至千萬級條記錄的表,這樣的表過于龐大,導致資料庫在查詢和插入的時候耗時太長,性能低下,如果涉及聯合查詢的情況,性能會更加糟糕,分表和表磁區的目的就是減少資料庫的負擔,提高資料庫的效率,通常點來講就是提高表的增刪改查效率,
磁區,partition,磁區是將資料分段劃分在多個位置存放,可以是同一塊磁盤也可以在不同的機器,磁區后,表面上還是一張表,但資料散列到多個位置了,app讀寫的時候操作的還是大表名字,db自動去組織磁區的資料,
-- 查看是否支持磁區 show variables like "%PARTITION%"; --EXPLAIN PARTITIONS查看用的哪個磁區的資料 EXPLAIN PARTITIONS SELECT test_partition_list.schoolId FROM test_partition_list WHERE test_partition_list.schoolId = 2
Tip:磁區與存盤引擎無關,是MySQL邏輯層完成的,


mysql磁區型別有:
- list磁區:基于列舉出的值串列磁區;
- range磁區:基于給定的一個連續范圍,把資料分配到不同的磁區;
- hash磁區:基于給定的磁區個數,把資料分配到不同的磁區;
- key磁區:類似HASH磁區
無論哪種MySQL磁區型別,要么磁區表上沒有主鍵/唯一鍵 要么磁區表的主鍵/唯一鍵必須包含磁區鍵 ,不能使用主鍵/唯一鍵欄位之外的其他欄位磁區
list磁區:
按照串列值磁區(in (值串列)
--表上的每一個唯一性索引必須用于磁區表的運算式上(其中包括主鍵索引);言外之意就是如果有多個欄位要建立唯一性索引可以:PRIMARY KEY ( `id`, `schoolId` )或者UNIQUE KEY (`id`, `schoolId`)
1 CREATE TABLE `test`.`test_partition_list` ( 2 `id` INT ( 11 ) NOT NULL, 3 `name` VARCHAR ( 255 ) NOT NULL, 4 `age` INT ( 3 ) NOT NULL, 5 `schoolId` INT ( 11 ) NOT NULL, 6 PRIMARY KEY ( `id`, `schoolId` ), 7 INDEX `name` ( `name` ) USING BTREE 8 ) ENGINE = INNODB CHARACTER 9 SET = utf8 COLLATE = utf8_unicode_ci PARTITION BY LIST ( schoolId ) ( 10 PARTITION `p0`VALUES IN ( 1, 5, 9, 10, 12, 15 ), 11 PARTITION `p1`VALUES IN ( 2, 4, 6, 8, 13, 11 ), 12 PARTITION `p2`VALUES IN ( 3, 7, 14, 16, 18 ), 13 PARTITION `p3`VALUES IN ( 19, 21, 23, 25, 27 ), 14 PARTITION `p4`VALUES IN ( 20, 22, 24, 26, 28 ) 15 );
對于不同的存盤引擎,磁區后生成的檔案也不一樣的;myisam是這樣的:
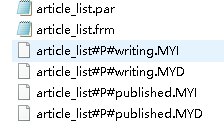
innodb是這樣的:

range磁區:
條件運算子(less than)
1 CREATE TABLE rc1 ( 2 a INT, 3 b INT, 4 PRIMARY KEY (a,b) 5 ) 6 PARTITION BY RANGE COLUMNS ( a,b ) ( 7 PARTITION p0 VALUES LESS THAN (10,5), 8 PARTITION p1 VALUES LESS THAN (20,15), 9 PARTITION p2 VALUES LESS THAN (30,25), 10 PARTITION p3 VALUES LESS THAN (40,30), 11 PARTITION p4 VALUES LESS THAN (50,40), 12 PARTITION p5 VALUES LESS THAN (MAXVALUE,MAXVALUE) 14 );
HASH磁區:
主要用來分散熱點讀 確保資料在預先確定個數的磁區中盡可能平均分布
對一個表執行HASH磁區時候 MySQL會對磁區鍵應用一個散列函式 確定資料應當放在N個磁區中的哪個磁區中
支持兩種HASH磁區:常規HASH磁區 線性HASH磁區(LINEAR HASH磁區)
CREATE TABLE emp ( id INT NOT NULL, ename VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job VARCHAR(30) NOT NULL, store_id INT NOT NULL )PARTITION BY HASH (store_id) PARTITIONS 4;
磁區按照MOD(store_id,4) 取模運算,磁區名p0-3
常規HASH會出現的問題:如果增加磁區或者合并磁區的時候 取模演算法需要改變 所有資料需要重新計算 為了降低磁區管理的代價 提供線性HASH磁區 磁區函式是一個線性2的冪運算
Key磁區
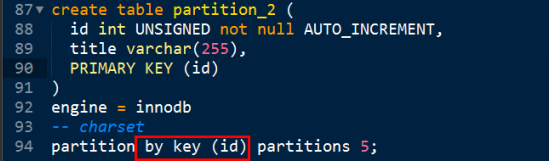
分成5個區,就是對5取余,將id對5取余,
注意:Key,hash都是取余演算法,要求磁區引數(括號里的),回傳的資料必須為整數,
磁區中的NULL值
MySQL資料庫允許對NULL值做磁區,但是處理的方法和Oracle資料庫完全不同,MYSQL資料庫的磁區總是把NULL值視為小于任何一個非NULL值,這和MySQL資料庫中對于NULL的ORDER BY的排序是一樣的,因此對于不同的磁區型別,MySQL資料庫對于NULL值的處理是不一樣的,
對于RANGE磁區,如果對于磁區列插入了NULL值,則MySQL資料庫會將該值放入最左邊的磁區(這和Oracle資料庫完全不同,Oracle資料庫會將NULL值放入MAXVALUE磁區中),例如:
create table t_range( a int, b int )engine=innodb partition by range(b)( partition p0 values less than(10), partition p1 values less than(20), partition p2 values less than maxvalue );
接著往表中插入(1,1)和(1,NULL)兩條資料,并觀察每個磁區中記錄的數量:
insert into t_range select 1,1; insert into t_range select 1,NULL; select * from t_range\G; select table_name,partition_name,table_rows from information_schema.PARTITIONS where table_schema=database() and table_name='t_range'\G;
RANGE磁區下,NULL值會放入最左邊的磁區中,另外需要注意的是,如果洗掉p0這個磁區,你洗掉的是小于10的記錄,并且還有NULL值的記錄,這點非常重要,
LIST磁區下要使用NULL值,則必須顯式地指出哪個磁區中放入NULL值,否則會報錯,如:
create table t_list( a int, b int)engine=innodb partition by list(b)( partition p0 values in (1,3,5,7,9), partition p1 values in (0,2,4,6,8) ); insert into t_list select 1,NULL; ERROR 1526(HY000):Table has no partition for value NULL
若p0磁區允許NULL值,則插入不會報錯:
create table t_list( a int, b int)engine=innodb partition by list(b)( partition p0 values in (1,3,5,7,9,NULL), partition p1 values in (0,2,4,6,8) ); insert into t_list select 1,NULL; select table_name,partition_name,table_rows from information_schema.PARTITIONS where table_schema=database() and table_name='t_list';
HASH和KEY磁區對于NULL的處理方式,和RANGE磁區、LIST磁區不一樣,任何磁區函式都會將含有NULL值的記錄回傳為0,如:
create table t_hash( a int, b int)engine=innodb partition by hash(b) partitions 4; insert into t_hash select 1,0; insert into t_hash select 1,NULL; select table_name,partition_name,table_rows from information_schema.PARTITIONS where table_schema=database() and table_name='t_hash';
***************************1.row***************************
table_name:t_hash
partition_name:p0
table_rows:2
磁區管理
洗掉磁區:
- 在key和hash領域洗掉磁區不會造成資料丟失,而是把資料正和到剩余磁區中;
- 在list和range領域洗掉磁區后,會造成資料丟失,
求余方式(key / hash)
-- 求余方式洗掉磁區的語法 alter table 表名 coalesce partition 數量
范圍方式(list / range)
-- 范圍方式 alter table 表名 drop partition 磁區表名稱

-
磁區和性能
常聽到開發人員說“對表做個磁區,然后資料庫的查詢就會快了”,但是這是真的嗎?實際中可能你根本感覺不到查詢速度的提升,甚至是查詢速度急劇的下降,因此,在合理使用磁區之前,必須了解磁區的使用環境,
資料庫的應用分為兩類:
- 一類是OLTP(在線事務處理),如博客、電子商務、網路游戲等;
- 一類是OLAP(在線分析處理),如資料倉庫、資料集市,
在一個實際的應用環境中,可能既有OLTP的應用,也有OLAP的應用,如網路游戲中,玩家操作的游戲資料庫應用就是OLTP的,但是游戲廠商可能需要對游戲產生的日志進行分析,通過分析得到的結果來更好地服務于游戲、預測玩家的行為等,而這卻是OLAP的應用,
對于OLAP的應用,磁區的確可以很好地提高查詢的性能,因為OLAP應用的大多數查詢需要頻繁地掃描一張很大的表,假設有一張1億行的表,其中有一個時間戳屬性列,你的查詢需要從這張表中獲取一年的資料,如果按時間戳進行磁區,則只需要掃描相應的磁區即可,
對于OLTP的應用,磁區應該非常小心,在這種應用下,不可能會獲取一張大表中10%的資料,大部分都是通過索引回傳幾條記錄即可,而根據B+樹索引的原理可知,對于一張大表,一般的B+樹需要2~3次的磁盤IO(到現在我都沒看到過4層的B+樹索引),因此B+樹可以很好地完成操作,不需要磁區的幫助,并且設計不好的磁區會帶來嚴重的性能問題,
很多開發團隊會認為含有1000萬行的表是一張非常巨大的表,所以他們往往會選擇采用磁區,如對主鍵做10個HASH的磁區,這樣每個磁區就只有100萬行的資料了,因此查詢應該變得更快了,如SELECT * FROM TABLE WHERE PK=@pk,但是有沒有考慮過這樣一個問題:100萬行和1000萬行的資料本身構成的B+樹的層次都是一樣的,可能都是2層?那么上述走主鍵磁區的索引并不會帶來性能的提高,是的,即使1000萬行的B+樹的高度是3,100萬行的B+樹的高度是2,那么上述走主鍵磁區的索引可以避免1次IO,從而提高查詢的效率,嗯,這沒問題,但是這張表只有主鍵索引,而沒有任何其他的列需要查詢?如果還有類似如下的陳述句SQL:SELECT * FROM TABLE WHERE KEY=@key,這時對于KEY的查詢需要掃描所有的10個磁區,即使每個磁區的查詢開銷為2次IO,則一共需要20次IO,而對于原來單表的設計,對于KEY的查詢還是2~3次IO,
如下表Profile,根據主鍵ID進行了HASH磁區,HASH磁區的數量為10,表Profile有接近1000萬行的資料:
CREATE TABLE 'Profile'( 'id' int(11) NOT NULL AUTO_INCREMENT, 'nickname' varchar(20) NOT NULL DEFAULT'', 'password' varchar(32) NOT NULL DEFAULT'', 'sex' char(1)NOT NULL DEFAULT'', 'rdate' date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY('id'), KEY 'nickname' ('nickname') )ENGINE=InnoDB partition by hash(id) partitions 10; select count(nickname)from Profile; count(1):9999248
因為是根據HASH磁區的,因此每個區分的記錄數大致是相同的,即資料分布比較均勻:
select table_name,partition_name,table_rows from information_schema.PARTITIONS where table_schema=database() and table_name='Profile';
注意:即使是根據自增長主鍵進行的HASH磁區,也不能保證磁區資料的均勻,因為插入的自增長ID并非總是連續的,如果該主鍵值因為某種原因被回滾了,則該值將不會再次被自動使用,
如果進行主鍵的查詢,可以發現磁區的確是有意義的:
explain partitions select * from Profile where id=1\G;
可以發現只尋找了p1磁區,
但是對于表Profile中nickname列索引的查詢,EXPLAIN PARTITIONS則會得到如下的結果:
explain partitions select * from Profile where nickname='david'\G;
可以看到,MySQL資料庫會搜索所有磁區,因此查詢速度會慢很多,比較上述的陳述句:
select * from Profile where nickname='david'\G;
上述簡單的索引查找陳述句竟然需要1.05秒,這顯然是因為搜索所有磁區的關系,實際的IO執行了20~30次,在未磁區的同樣結構和大小的表上執行上述SQL陳述句,只需要0.26秒,
因此對于使用InnoDB存盤引擎作為OLTP應用的表,在使用磁區時應該十分小心,設計時要確認資料的訪問模式,否則在OLTP應用下磁區可能不僅不會帶來查詢速度的提高,反而可能會使你的應用執行得更慢,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/55108.html
標籤:PHP
上一篇:SynEdit使用的兩個問題(注釋和多陳述句執行SQL查詢)
下一篇:delphi Tchromium