ElasticSearch 索引設計

在MySQL中資料庫設計非常重要,同樣在ES中資料庫設計也是非常重要的
概述
我們創建索引就像創建表結構一樣,必須非常慎重的,索引如果創建不好后面會出現各種各樣的問題
索引設計的重要性
索引創建后,索引的分片只能通過
_split和_shrink介面對其進行成倍的增加和縮減
主要是因為es的資料是通過_routing分配到各個分片上面的,所以本質上是不推薦去改變索引的分片數量的,因為這樣都會對資料進行重新的移動,
還有就是索引只能新增欄位,不能對欄位進行修改和洗掉,缺乏靈活性,所以每次都只能通過_reindex重建索引了,還有就是一個分片的大小以及所以分片數量的多少嚴重影響到了索引的查詢和寫入性能,所以可想而知,設計一個好的索引能夠減少后期的運維管理和提高不少性能,所以前期對索引的設計是相當的重要的,
基于時間的Index設計
Index設計時要考慮的第一件事,就是基于時間對Index進行分割,即每隔一段時間產生一個新的Index
這樣設計的目的
因為現實世界的資料是隨著時間的變化而不斷產生的,切分管理可以獲得足夠的靈活性和更好的性能
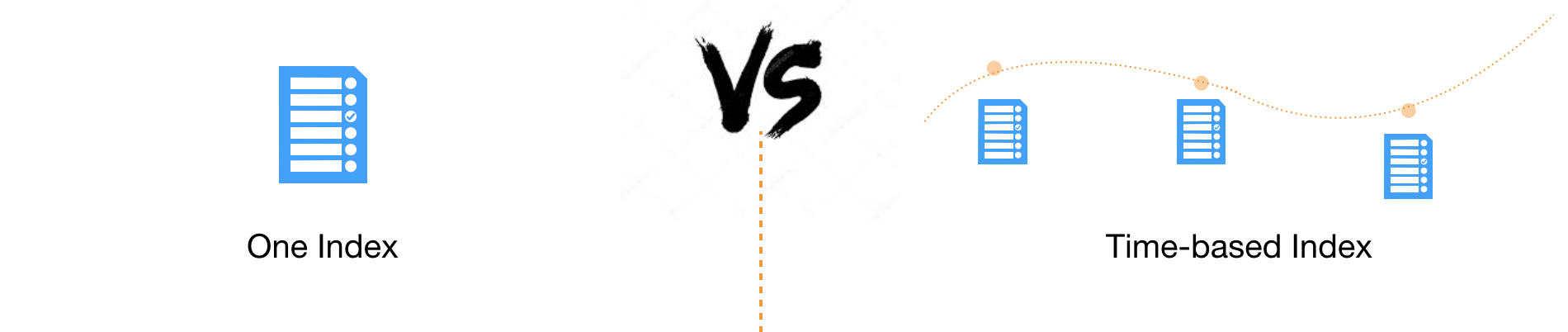
如果資料都存盤在一個Index中,很難進行擴展和調整,因為Elasticsearch中Index的某些設定在創建時就設定好了,是不能更改的,比如Primary Shard的個數,
而根據時間來切分Index,則可以實作一定的靈活性,既可以在資料量過大時及時調整Shard個數,也可以及時回應新的業務需求,
大多數業務場景下,客戶對資料的請求都會命中在最近一段時間上,通過切分Index,可以盡可能的避免掃描不必要的資料,提高性能,
時間間隔
根據上面的分析,自然是時間越短越能保持靈活性,但是這樣做就會導致產生大量的Index,而每個Index都會消耗資源來維護其元資訊的,因此需要在靈活性、資源和性能上做權衡
- 常見的間隔有小時、天、周和月:先考慮總共要存盤多久的資料,然后選一個既不會產生大量Index又能夠滿足一定靈活性的間隔,比如你需要存盤6個月的資料,那么一開始選擇“周”這個間隔就會比較合適,
- 考慮業務增長速度:假如業務增長的特別快,比如上周產生了1億資料,這周就增長到了10億,那么就需要調低這個間隔來保證有足夠的彈性能應對變化,
如何實作分割
切分行為是由客戶端(資料的寫入端)發起的,根據時間間隔與資料產生時間將資料寫入不同的Index中,為了易于區分,會在Index的名字中加上對應的時間標識
創建新Index這件事,可以是客戶端主動發起一個創建的請求,帶上具體的Settings、Mappings等資訊,但是可能會有一個時間錯位,即有新資料寫入時新的Index還沒有建好,Elasticsearch提供了更優雅的方式來實作這個動作,即Index Template
分片設計
所謂分片設計,就是如何設定主分片的個數
看上去只是一個數字而已,也許在很多場景下,即使不設定也不會有問題(ES7默認是1個主分片一個副本分片),但是如果不提前考慮,一旦出問題就可能導致系統性能下降、不可訪問、甚至無法恢復,換句話說,即使使用默認值,也應該是通過足夠的評估后作出的決定,而非拍腦袋定的,
限制分片大小
單個Shard的存盤大小不超過30GB
Elastic專家根據經驗總結出來大家普遍認為30GB是個合適的上限值,實踐中發現單個Shard過大(超過30GB)會導致系統不穩定,
其次,為什么不能超過30GB?主要是考慮Shard Relocate程序的負載,我們知道,如果Shard不均衡或者部分節點故障,Elasticsearch會做Shard Relocate,在這個程序中會搬移Shard,如果單個Shard過大,會導致CPU、IO負載過高進而影響系統性能與穩定性,
評估分片數量
單個Index的
Primary Shard個數 = k * 資料節點個數
在保證第一點的前提下,單個Index的Primary Shard個數不宜過多,否則相關的元資訊與快取會消耗過多的系統資源,這里的k,為一個較小的整數值,建議取值為1,2等,整數倍的關系可以讓Shard更好地均勻分布,可以充分的將請求分散到不同節點上,
小索引設計
對于很小的Index,可以只分配1~2個Primary Shard的
有些情況下,Index很小,也許只有幾十、幾百MB左右,那么就不用按照第二點來分配了,只分配1~2個Primary Shard是可以,不用糾結,
使用索引模板
就是把已經創建好的某個索引的引數設定(settings)和索引映射(mapping)保存下來作為模板,在創建新索引時,指定要使用的模板名,就可以直接重用已經定義好的模板中的設定和映射
Elasticsearch基于與索引名稱匹配的通配符模式將模板應用于新索引,也就是說通過索引進行匹配,看看新建的索引是否符合索引模板,如果符合,就將索引模板的相關設定應用到新的索引,如果同時符合多個索引模板呢,這里需要對引數priority進行比較,這樣會選擇priority大的那個模板進行創建索引,
在創建索引模板時,如果匹配有包含的關系,或者相同,則必須設定priority為不同的值,否則會報錯,索引模板也是只有在新創建的時候起到作用,修改索引模板對現有的索引沒有影響,同樣如果在索引中設定了一些設定或者mapping都會覆寫索引模板中相同的設定或者mapping
索引模板的用途
索引模板一般用在時間序列相關的索引中,
也就是說, 如果你需要每間隔一定的時間就建立一次索引,你只需要配置好索引模板,以后就可以直接使用這個模板中的設定,不用每次都設定settings和mappings.
創建索引模板
COPYPUT _index_template/logstash-village
{
"index_patterns": [
"logstash-village-*" // 可以通過"logstash-village-*"來適配創建的索引
],
"template": {
"settings": {
"number_of_shards": "3", //指定模板分片數量
"number_of_replicas": "2" //指定模板副本數量
},
"aliases": {
"logstash-village": {} //指定模板索引別名
},
"mappings": { //設定映射
"dynamic": "strict", //禁用動態映射
"properties": {
"@timestamp": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis||yyyy-MM-dd HH:mm:ss"
},
"@version": {
"doc_values": false,
"index": "false",
"type": "integer"
},
"name": {
"type": "keyword"
},
"province": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"area": {
"type": "keyword"
},
"addr": {
"type": "text",
"analyzer": "ik_smart"
},
"location": {
"type": "geo_point"
},
"property_type": {
"type": "keyword"
},
"property_company": {
"type": "text",
"analyzer": "ik_smart"
},
"property_cost": {
"type": "float"
},
"floorage": {
"type": "float"
},
"houses": {
"type": "integer"
},
"built_year": {
"type": "integer"
},
"parkings": {
"type": "integer"
},
"volume": {
"type": "float"
},
"greening": {
"type": "float"
},
"producer": {
"type": "keyword"
},
"school": {
"type": "keyword"
},
"info": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
}
模板引數
下面是創建索引模板的一些引數
| 引數名稱 | 引數介紹 |
|---|---|
| index_patterns | 必須配置,用于在創建期間匹配索引名稱的通配符(*)運算式陣列 |
| template | 可選配置,可以選擇包括別名、映射或設定配置 |
| composed_of | 可選配置,組件模板名稱的有序串列,組件模板按指定的順序合并,這意味著最后指定的組件模板具有最高的優先級 |
| priority | 可選配置,創建新索引時確定索引模板優先級的優先級,選擇具有最高優先級的索引模板,如果未指定優先級,則將模板視為優先級為0(最低優先級) |
| version | 可選配置,用于外部管理索引模板的版本號 |
| _meta | 可選配置,關于索引模板的可選用戶元資料,可能有任何內容 |
映射配置
上面我們配置了映射模板,但是我們用到了映射,下面我們說下映射
什么是映射
在創建索引時,可以預先定義欄位的型別(映射型別)及相關屬性
資料庫建表的時候,我們DDL依據一般都會指定每個欄位的存盤型別,例如:varchar、int、datetime等,目的很明確,就是更精確的存盤資料,防止資料型別格式混亂,在Elasticsearch中也是這樣,創建索引的時候一般也需要指定索引的欄位型別,這種方式稱為映射(Mapping)
被動創建(動態映射)
此時欄位和映射型別不需要事先定義,只需要存在檔案的索引,當向此索引添加資料的時候當遇到不存在的映射欄位,ES會根據資料內容自動添加映射欄位定義,
動態映射規則
使用動態映射的時候,根據傳遞請求資料的不同會創建對應的資料型別
| 資料型別 | Elasticsearch 資料型別 |
|---|---|
| null | 不添加任何欄位 |
| true或者false | boolean型別 |
| 浮點資料 | float型別 |
| integer資料 | long型別 |
| object | object型別 |
| array | 取決于陣列中的第一個非空值的型別, |
| string | 如果此內容通過了日期格式檢測,則會被認為是date資料型別 如果此值通過了數值型別檢測則被認為是double或者long資料型別 帶有關鍵字子欄位會被認為一個text欄位 |
禁止動態映射
一般生產環境下需要禁用動態映射,使用動態映射可能出現以下問題
- 造成集群元資料一直變更,導致不穩定;
- 可能造成資料型別與實際型別不一致;
如何禁用動態映射,動態
mapping的dynamic欄位進行配置,可選值及含義如下
- true:支持動態擴展,新增資料有新的欄位屬性時,自動添加對于的mapping,資料寫入成功
- false:不支持動態擴展,新增資料有新的欄位屬性時,直接忽略,資料寫入成功
- strict:不支持動態擴展,新增資料有新的欄位時,報錯,資料寫入失敗
主動創建(顯示映射)
動態映射只能保證最基礎的資料結構的映射
所以很多時候我們需要對欄位除了資料結構定義更多的限制的時候,動態映射創建的內容很可能不符合我們的需求,所以可以使用PUT {index}/mapping來更新指定索引的映射內容,
映射型別
我們要創建映射必須還要知道映射型別,否則就會走默認的映射型別,下面我們看看常用的映射型別
準備作業
我們先創建一個用于測驗映射型別的索引
COPYPUT mapping_demo
字串型別
字串型別是我們最常用的型別之一,我們操作的時候字串型別可以被設定為以下幾種型別
text
當一個欄位是要被全文搜索的,比如Email內容、產品描述,應該使用text型別,text型別會被分詞
設定text型別以后,欄位內容會被分詞,在生成倒排索引以前,字串會被分析器分成一個一個詞項,text型別的欄位不用于排序,很少用于聚合
keyword
keyword型別不會被分詞,常用于關鍵字搜索,比如姓名、email地址、主機名、狀態碼和標簽等
如果欄位需要進行過濾(比如查姓名是張三發布的博客)、排序、聚合,keyword型別的欄位只能通過精確值搜索到,常常被用來過濾、排序和聚合
兩者區別
它們的區別在于
text會對欄位進行分詞處理而keyword則不會進行分詞
也就是說如果欄位是text型別,存入的資料會先進行分詞,然后將分完詞的詞組存入索引,而keyword則不會進行分詞,直接存盤,這樣劃分資料更加節省記憶體,
使用案例
我們先創建一個映射,name是keyword型別,描述是text型別的
COPYPUT mapping_demo/_mapping
{
"properties": {
"name": {
"type": "keyword"
},
"city": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
插入資料
COPYPUT mapping_demo/_doc/1
{
"name":"北京小區",
"city":"北京市昌平區回龍觀街道"
}
對于keyword的name欄位進行精確查詢
COPYGET mapping_demo/_search
{
"query": {
"term": {
"name": "北京小區"
}
}
}
對于text的city進行模糊查詢
COPYGET mapping_demo/_search
{
"query": {
"term": {
"city": "北京市"
}
}
}
數字型別
數字型別也是我們最常用的型別之一,下面我們看下數字型別的使用
| 型別 | 取值范圍 |
|---|---|
| long | -263 ~ 263 |
| integer | -231 ~ 231 |
| short | -215 ~ 215 |
| byte | -27 ~ 27 |
| double | 64位的雙精度 IEEE754 浮點型別 |
| float | 32位的雙精度 IEEE754 浮點型別 |
| half_float | 16位的雙精度 IEEE754 浮點型別 |
| scaled_float | 縮放型別的浮點型別 |
注意事項
- 在滿足需求的情況下,優先使用范圍小的欄位,欄位長度越小,索引和搜索的效率越高,
日期型別
JSON表示日期
JSON沒有表達日期的資料型別,所以在ES里面日期只能是下面其中之一
- 格式化的日期字串,比如:
"2015-01-01"or"2015/01/01 12:10:30" - 用數字表示的從新紀元開始的毫秒數
- 用數字表示的從新紀元開始的秒數(epoch_second)
注意點:毫秒數的值是不能為負數的,如果時間在1970年以前,需要使用格式化的日期表達
ES如何處理日期
在ES的內部,時間會被轉換為UTC時間(如果宣告了時區)并使用從新紀元開始的毫秒數的長整形數字型別的進行存盤,在日期欄位上的查詢,內部將會轉換為使用長整形的毫秒進行范圍查詢,根據與欄位關聯的日期格式,聚合和存盤欄位的結果將轉換回字串
注意點:日期最終都會作為字串呈現,即使最開始初始化的時候是利用JSON檔案的long宣告的
默認日期格式
日期的格式可以被定制化的,如果沒有宣告日期的格式,它將會使用默認的格式:
COPY"strict_date_optional_time||epoch_millis"
這意味著它將會接收帶時間戳的日期,它將遵守strict_date_optional_time限定的格式(yyyy-MM-dd'T'HH:mm:ss.SSSZ 或者 yyyy-MM-dd)或者毫秒數
日期格式示例
COPYPUT mapping_demo/_mapping
{
"properties": {
"datetime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
# 添加資料
PUT mapping_demo/_doc/2
{
"name":"河北區",
"city":"河北省小區",
"datetime":"2022-02-21 11:35:42"
}
日期型別引數
下面表格里的引數可以用在date欄位上面
| 引數 | 說明 |
|---|---|
| doc_values | 該欄位是否按照列式存盤在磁盤上以便于后續進行排序、聚合和腳本操作,可配置 true(默認)或 false |
| format | 日期的格式 |
| locale | 決議日期中時使用了本地語言表示月份時的名稱和/或縮寫,默認是 ROOT locale |
| ignore_malformed | 如果設定為true,則奇怪的數字就會被忽略,如果是false(默認)奇怪的數字就會導致例外并且該檔案將會被拒絕寫入,需要注意的是,如果在腳本引數中使用則該屬性不能被設定 |
| index | 該欄位是否能快速的被查詢,默認是true,date型別的欄位只有在doc_values設定為true時才能被查詢,盡管很慢, |
| null_value | 替代null的值,默認是null |
| on_script_error | 定義在腳本中如何處理拋出的例外,fail(默認)則整個檔案會被拒絕索引,continue:繼續索引 |
| script | 如果該欄位被設定,則欄位的值將會使用該腳本產生,而不是直接從source里面讀取, |
| store | true or false(默認)是否在 _source 之外在獨立存盤一份 |
布爾型別
boolean型別用于存盤檔案中的true/false
范圍型別
顧名思義,范圍型別欄位中存盤的內容就是一段范圍,例如年齡30-55歲,日期在2020-12-28到2021-01-01之間等
型別范圍
es中有六種范圍型別:
- integer_range
- float_range
- long_range
- double_range
- date_range
- ip_range
使用實體
COPYPUT mapping_demo/_mapping
{
"properties": {
"age_range": {
"type": "integer_range"
}
}
}
# 指定年齡范圍,可以使用 gt、gte、lt、lte,
PUT mapping_demo/_doc/3
{
"name":"張三",
"age_range":{
"gt":20,
"lt":30
}
}
分詞器
什么是分詞器
分詞器的主要作用將用戶輸入的一段文本,按照一定邏輯,分析成多個詞語的一種工具
顧名思義,文本分析就是把全文本轉換成一系列單詞(term/token)的程序,也叫分詞,在 ES 中,Analysis 是通過分詞器(Analyzer) 來實作的,可使用 ES 內置的分析器或者按需定制化分析器,
舉一個分詞簡單的例子:比如你輸入 Mastering Elasticsearch,會自動幫你分成兩個單詞,一個是 mastering,另一個是 elasticsearch,可以看出單詞也被轉化成了小寫的,
分詞器構成
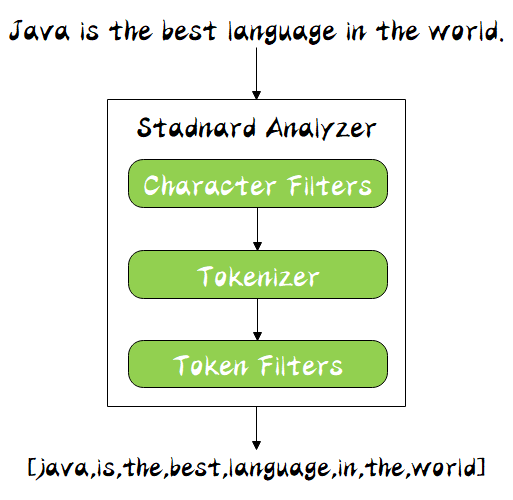
分詞器是專門處理分詞的組件,分詞器由以下三部分組成:
character filter
接收原字符流,通過添加、洗掉或者替換操作改變原字符流
例如:去除文本中的html標簽,或者將羅馬數字轉換成阿拉伯數字等,一個字符過濾器可以有零個或者多個
tokenizer
簡單的說就是將一整段文本拆分成一個個的詞
例如拆分英文,通過空格能將句子拆分成一個個的詞,但是對于中文來說,無法使用這種方式來實作,在一個分詞器中,有且只有一個tokenizeer
token filters
將切分的單詞添加、洗掉或者改變
例如將所有英文單詞小寫,或者將英文中的停詞a洗掉等,在token filters中,不允許將token(分出的詞)的position或者offset改變,同時,在一個分詞器中,可以有零個或者多個token filters,
分詞順序
同時 Analyzer 三個部分也是有順序的,從圖中可以看出,從上到下依次經過 Character Filters,Tokenizer 以及 Token Filters,這個順序比較好理解,一個文本進來肯定要先對文本資料進行處理,再去分詞,最后對分詞的結果進行過濾,
測驗分詞
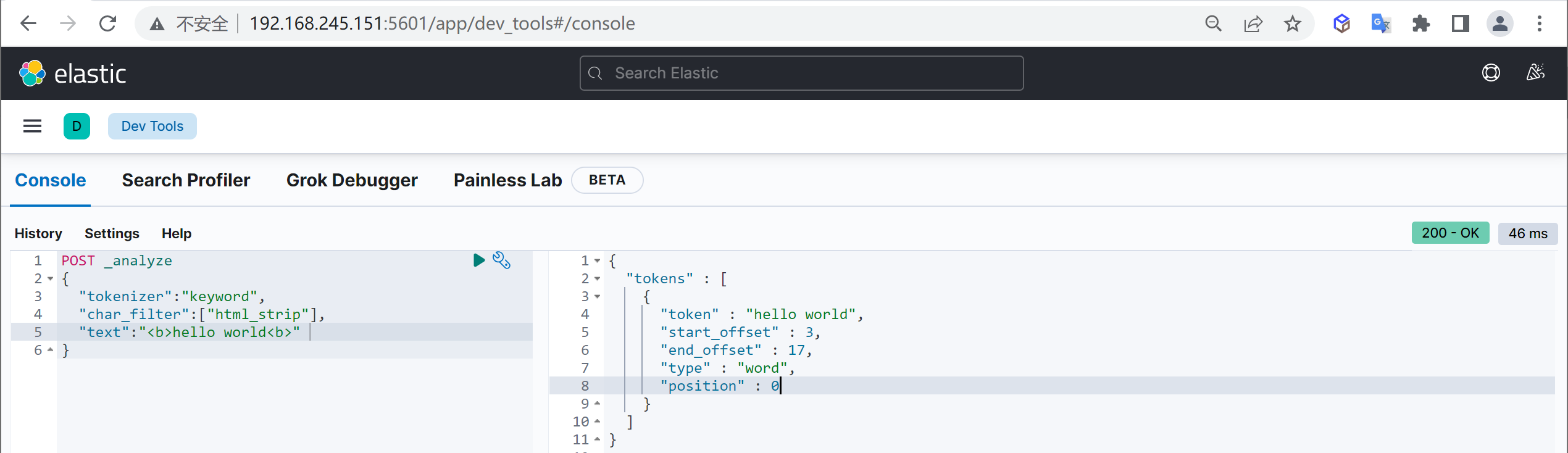
可以通過
_analyzerAPI來測驗分詞的效果,我們使用下面的html過濾分詞
COPYPOST _analyze
{
"text":"<b>hello world<b>" # 輸入的文本
"char_filter":["html_strip"], # 過濾html標簽
"tokenizer":"keyword", #原樣輸出
}
什么時候分詞
文本分詞會發生在兩個地方:
創建索引:當索引檔案字符型別為text時,在建立索引時將會對該欄位進行分詞,搜索:當對一個text型別的欄位進行全文檢索時,會對用戶輸入的文本進行分詞,
創建索引時指定分詞器
如果設定手動設定了分詞器,ES將按照下面順序來確定使用哪個分詞器
- 先判斷欄位是否有設定分詞器,如果有,則使用欄位屬性上的分詞器設定
- 如果設定了
analysis.analyzer.default,則使用該設定的分詞器 - 如果上面兩個都未設定,則使用默認的
standard分詞器
欄位指定分詞器
為addr屬性指定分詞器,這里我們使用的是中文分詞器
COPYPUT my_index
{
"mappings": {
"properties": {
"info": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
設定默認分詞器
COPYPUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
}
}
}
}
}
搜索時指定分詞器
在搜索時,通過下面引數依次檢查搜索時使用的分詞器,這樣我們的搜索陳述句就會先分詞,然后再來進行搜索
- 搜索時指定
analyzer引數 - 創建mapping時指定欄位的
search_analyzer屬性 - 創建索引時指定
setting的analysis.analyzer.default_search - 查看創建索引時欄位指定的
analyzer屬性 - 如果上面幾種都未設定,則使用默認的
standard分詞器,
指定analyzer
搜索時指定analyzer查詢引數
COPYGET my_index/_search
{
"query": {
"match": {
"message": {
"query": "Quick foxes",
"analyzer": "stop"
}
}
}
}
指定欄位analyzer
COPYPUT my_index
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "whitespace",
"search_analyzer": "simple"
}
}
}
}
指定默認default_seach
COPYPUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
},
"default_seach":{
"type":"whitespace"
}
}
}
}
}
內置分詞器
es在索引檔案時,會通過各種型別
Analyzer對text型別欄位做分析
不同的 Analyzer 會有不同的分詞結果,內置的分詞器有以下幾種,基本上內置的 Analyzer 包括 Language Analyzers 在內,對中文的分詞都不夠友好,中文分詞需要安裝其它 Analyzer
| 分析器 | 描述 | 分詞物件 | 結果 |
|---|---|---|---|
| standard | 標準分析器是默認的分析器,如果沒有指定,則使用該分析器,它提供了基于文法的標記化(基于 Unicode 文本分割演算法,如 Unicode 標準附件 # 29所規定) ,并且對大多數語言都有效, | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog’s, bone ] |
| simple | 簡單分析器將文本分解為任何非字母字符的標記,如數字、空格、連字符和撇號、放棄非字母字符,并將大寫字母更改為小寫字母, | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| whitespace | 空格分析器在遇到空白字符時將文本分解為術語 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog’s, bone. ] |
| stop | 停止分析器與簡單分析器相同,但增加了洗掉停止字的支持,默認使用的是 _english_ 停止詞, |
The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ quick, brown, foxes, jumped, over, lazy, dog, s, bone ] |
| keyword | 不分詞,把整個欄位當做一個整體回傳 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone.] |
| pattern | 模式分析器使用正則運算式將文本拆分為術語,正則運算式應該匹配令牌分隔符,而不是令牌本身,正則運算式默認為 w+ (或所有非單詞字符), |
The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| 多種西語系 arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english等等 | 一組旨在分析特定語言文本的分析程式, |
IK中文分詞器
IKAnalyzer
IKAnalyzer是一個開源的,基于java的語言開發的輕量級的中文分詞工具包
從2006年12月推出1.0版開始,IKAnalyzer已經推出了3個大版本,在 2012 版本中,IK 實作了簡單的分詞歧義排除演算法,標志著 IK 分詞器從單純的詞典分詞向模擬語意分詞衍化
中文分詞器演算法
中文分詞器最簡單的是ik分詞器,還有jieba分詞,哈工大分詞器等
| 分詞器 | 描述 | 分詞物件 | 結果 |
|---|---|---|---|
| ik_smart | ik分詞器中的簡單分詞器,支持自定義字典,遠程字典 | 學如逆水行舟,不進則退 | [學如逆水行舟,不進則退] |
| ik_max_word | ik_分詞器的全量分詞器,支持自定義字典,遠程字典 | 學如逆水行舟,不進則退 | [學如逆水行舟,學如逆水,逆水行舟,逆水,行舟,不進則退,不進,則,退] |
ik_smart
原始內容
COPY傳智教育的教學質量是杠杠的
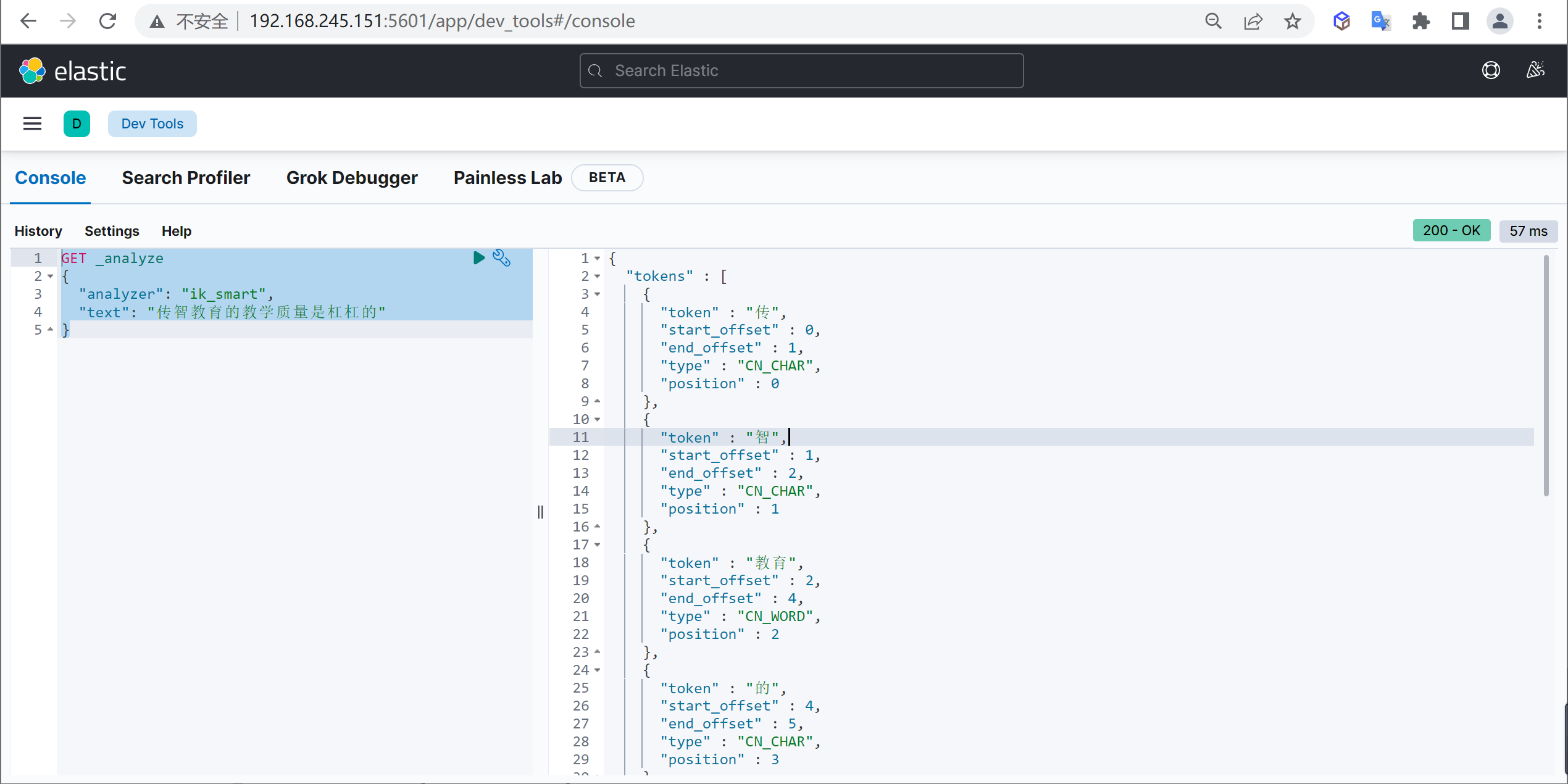
測驗分詞
COPYGET _analyze
{
"analyzer": "ik_smart",
"text": "傳智教育的教學質量是杠杠的"
}
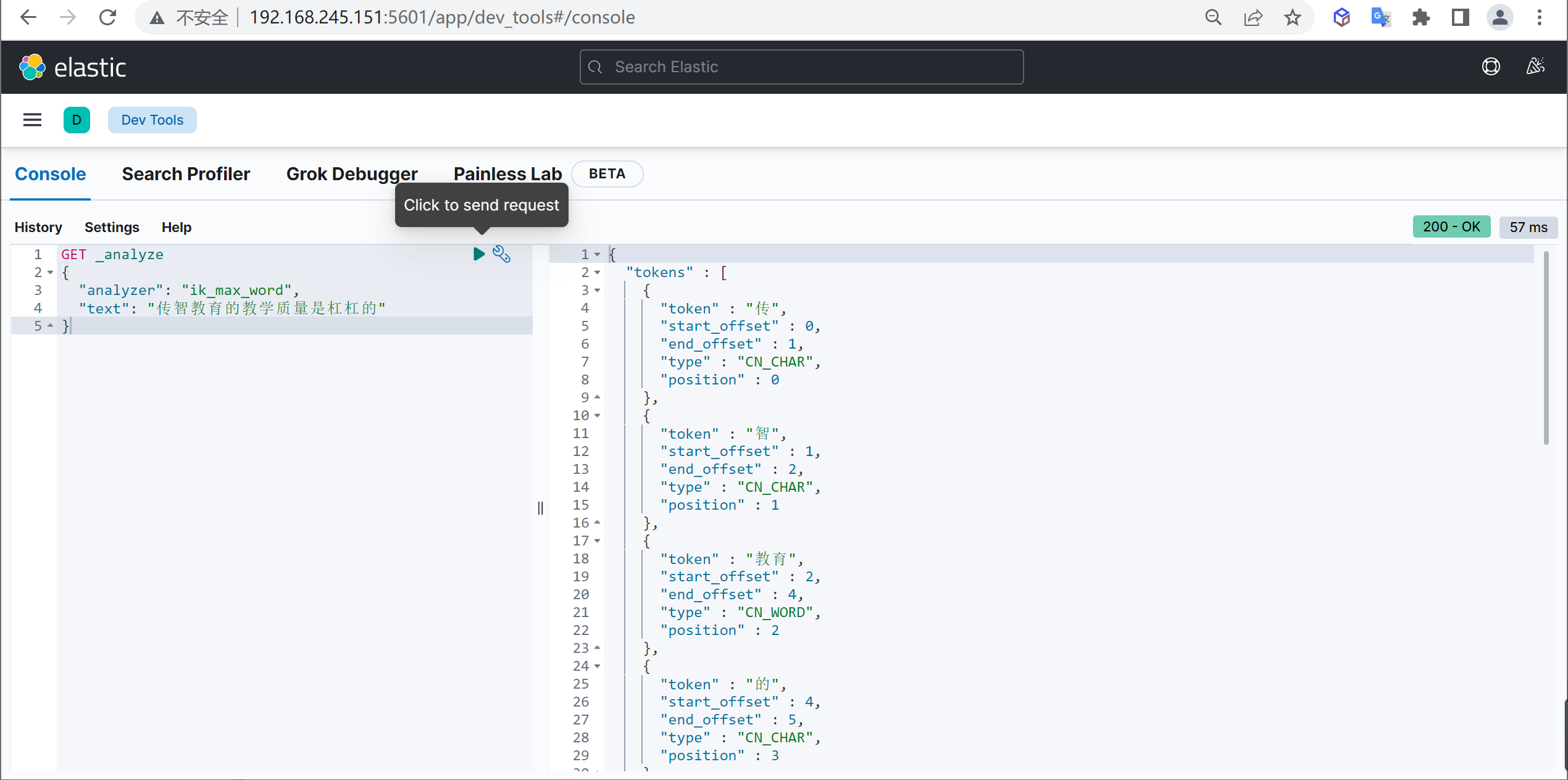
ik_max_word
原始內容
COPY傳智教育的教學質量是杠杠的
測驗分詞
COPYGET _analyze
{
"analyzer": "ik_max_word",
"text": "傳智教育的教學質量是杠杠的"
}
本文由
傳智教育博學谷狂野架構師教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/552198.html
標籤:其他
上一篇:用go設計開發一個自己的輕量級登錄庫/框架吧(專案維護篇)
下一篇:返回列表