pylightxl 比較小,沒有依賴,對python2、3都支持
- https://pylightxl.readthedocs.io/en/latest/index.html pylightxl 的檔案,可以自己去查看
- 支持的檔案后綴:.xlsx, .xlsm 和.csv
* 不支持.xls檔案(Microsoft Excel 2003 和更早的檔案)
* 不支持單元格資料以外的任何內容(不支持圖形、影像、宏、格式)
* 不支持超過 536,870,912 個單元格的作業表單元格資料(32 位串列限制),如果需要更多資料存盤,請使用 64 位,
-
安裝
pip install pylightxl -
讀取excel檔案
import pylightxl as xl
strExcelFilePath = "C:\\Users\\Administrator\\Desktop\\LogTestFile\\1111.xlsx"
db = xl.readxl(strExcelFilePath)
#當然了有更多的方式去讀取
import pylightxl as xl
strExcelFilePath = "C:\\Users\\Administrator\\Desktop\\LogTestFile\\1111.xlsx"
db = xl.readxl(strExcelFilePath , ws="Sheet1")#這里的ws是excel里面的作業簿
當excel檔案里面的內容為:
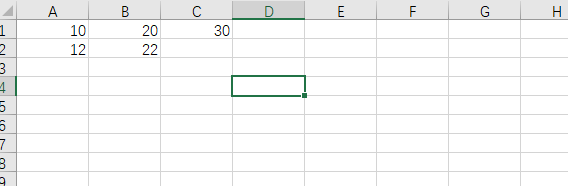
db.ws(ws='Sheet1').address(address='A1')
db.ws(ws='Sheet1').index(row=1,col=1)
#這兩句代表的意思都是一樣的,是去讀取A1位置上的資料是多少
#如果A1這個位置上沒有資料,就會回傳一個空,回傳的值:**''**
執行結果:

db.ws(ws='Sheet1').address(address='C1', output='f')#如果單元格有公式就輸出公式
db.ws(ws='Sheet1').address(address='C2', output='c')#如果有注釋就輸出注釋
db.ws(ws='Sheet1').set_emptycell(val=0)#將所有沒有資料的單元格都寫上0
db.ws(ws='Sheet1').range(address='A1:C2')#指定一個范圍進行輸出,回傳值是一個串列
db.ws(ws='Sheet1').range(address='A1:B1', output='f')#指定一個范圍查看公式,沒有公式的單元格會回傳一個"=",這個回傳也是串列哦
db.ws(ws='Sheet1').row(row=1)#獲取整行的資料,回傳串列
db.ws(ws='Sheet1').col(col=1)#獲取整列的資料,回傳串列
- 更新資料,也可以叫寫入資料
db.ws(ws='Sheet1').update_range(address='A1:B1', val=10)#更新資料,也可以叫寫入資料
db.ws(ws='Sheet1').update_address(address='A1', val=100)#也可以這樣寫入,也可以叫寫入資料
db.ws(ws='Sheet1').update_index(row=1, col=1, val=10)#還可以使用這樣的方式寫入資料
db.ws(ws='Sheet1').update_address(address='C1', val='=B1+100')#更新單元格公式,寫入公式
db.ws(ws='Sheet1').update_index(row=1, col=3, val='=B1+100')#更新單元格公式,寫入公式
- 指定一個區域,只對這個區域做操作
db.add_nr(name='name1', ws='Sheet1', address='A1:B2') #name 可以隨便寫,ws是作業簿的名字,address是范圍,這里不能用index(row 、col)
db.nr(name='name1')#獲取定義這個范圍里面的內容
db.nr_loc(name='name1')#查看定義這個范圍是那些
db.update_nr(name='name1', val=10)#更新一個范圍內的值
db.nr_names #查看定義了多少個范圍
db.remove_nr(name='name1')#洗掉一個范圍
- 保存,有沒有發現上面的陳述句更新了資料,但是我們打開excel檔案還是之前的東西,那是因為沒有進行寫入
xl.writexl(db=db, fn='你要保存的excel檔案位置,可以是之前的excel檔案,也可以是一個新的excel檔案')#寫入資料
import pylightxl as xl
# take this list for example as our input data that we want to put in column A
mydata = https://www.cnblogs.com/zytlk/p/[10,20,30,40]
# create a blank db
db = xl.Database()
# add a blank worksheet to the db
db.add_ws(ws="Sheet1")
# loop to add our data to the worksheet
for row_id, data in enumerate(mydata, start=1):
db.ws(ws="Sheet1").update_index(row=row_id, col=1, val=data)
# write out the db
xl.writexl(db=db, fn=strExcelFilePath2)
API
3.1. readxl
pylightxl.pylightxl.readxl(fn, ws=None)
Reads an xlsx or xlsm file and returns a pylightxl database
Parameters:
fn (Union[str, pathlib.Path]) – Excel file path, also supports Pathlib.Path object, as well as file-like object from with/open
ws (Union[str,List[str]], optional) – sheetnames to read into the database, if not specified - all sheets are read entry support single ws name (ex: ws=’sh1’) or multi (ex: ws=[‘sh1’, ‘sh2’]), defaults to None
Returns:
pylightxl Database
Return type:
Database
3.2. writexl
pylightxl.pylightxl.writexl(db, fn)
Writes an excel file from pylightxl.Database
Parameters:
db (Database) – database contains sheetnames, and their data
fn (Union[str, pathlib.path]) – file output path
3.3.1. Database Class
classpylightxl.pylightxl.Database
add_nr(name, ws, address)
Add a NamedRange to the database. There can not be duplicate name or addresses. A named range that overlaps either the name or address will overwrite the database’s existing NamedRange
Parameters:
name (str) – NamedRange name
ws (str) – worksheet name
address (str) – range of address (single cell ex: “A1”, range ex: “A1:B4”)
add_ws(ws, data=https://www.cnblogs.com/zytlk/p/None)
Logs worksheet name and its data in the database
Parameters:
ws (str) – worksheet name
data (dict, optional) – dictionary of worksheet cell values (ex: {‘A1’: {‘v’:10,’f’:’’,’s’:’’, ‘c’: ‘’}, ‘A2’: {‘v’:20,’f’:’’,’s’:’’, ‘c’: ‘’}}), defaults to None
nr(name, formula=False, output='v')
Returns the contents of a name range in a nest list form [row][col]
Parameters:
name (str) – NamedRange name
formula (bool, optional) – flag to return the formula of this cell, defaults to False
output (str, optional) – output request “v” for value, “f” for formula, “c” for comment, defaults to ‘v’
Returns:
nest list form [row][col]
Return type:
List[list]
nr_loc(name)
Returns the worksheet and address loction of a named range
Parameters: name (str) – NamedRange name
Returns: [worksheet, address]
Return type: List[str]
nr_names
Returns the dictionary of named ranges ex: {unique_name: unique_address, …}
Returns: {unique_name: unique_address, …}
Return type: Dict[str, str]
remove_nr(name)
Removes a Named Range from the database
Parameters: name (str) – NamedRange name
remove_ws(ws)
Removes a worksheet and its data from the database
Parameters: ws (str) – worksheet name
rename_ws(old, new)
Renames an existing worksheet. Caution, renaming to an existing new worksheet name will overwrite
Parameters:
old (str) – old name
new (str) – new name
set_emptycell(val)
Custom definition for how pylightxl returns an empty cell
Parameters: val (Union[str,int,float]) – (default=’’) empty cell value
update_nr(name, val)
Updates a NamedRange with a single value. Raises UserWarning if name not in workbook.
Parameters:
name (str) – NamedRange name
val (Union[int,float,str]) – cell value; equations are string and must being with “=”
ws(ws)
Indexes worksheets within the database
Parameters: ws (str) – worksheet name
Returns: pylightxl.Database.Worksheet class object
Return type: Worksheet
ws_names
Returns a list of database stored worksheet names
Returns: list of worksheet names
Return type: List[str]
3.3.2. Worksheet Class
classpylightxl.pylightxl.Worksheet(data=https://www.cnblogs.com/zytlk/p/None)
address(address, formula=False, output='v')
Takes an excel address and returns the worksheet stored value
Parameters:
address (str) – Excel address (ex: “A1”)
formula (bool, optional) – flag to return the formula of this cell, defaults to False
output (str, optional) – output request “v” for value, “f” for formula, “c” for comment, defaults to ‘v’
Returns:
cell value
Return type:
Union[int, float, str, bool]
col(col, formula=False, output='v')
Takes a col index input and returns a list of cell data
Parameters:
col (int) – col index (start at 1 that corresponds to column “A”)
formula (bool, optional) – flag to return the formula of this cell, defaults to False
output (str, optional) – output request “v” for value, “f” for formula, “c” for comment, defaults to ‘v’
Returns:
list of cell data
Return type:
List[Union[int, float, str, bool]]
cols
Returns a list of cols that can be iterated through
Returns: list of cols-lists (ex: [[11,21],[12,22],[13,23]] for 2 rows with 3 columns of data
Return type: Iterable[List[Union[int, float, str, bool]]]
index(row, col, formula=False, output='v')
Takes an excel row and col starting at index 1 and returns the worksheet stored value
Parameters:
row (int) – row index (starting at 1)
col (int) – col index (start at 1 that corresponds to column “A”)
formula (bool, optional) – flag to return the formula of this cell, defaults to False
output (str, optional) – output request “v” for value, “f” for formula, “c” for comment, defaults to ‘v’
Returns:
cell value
Return type:
Union[int, float, str, bool]
keycol(key, keyindex=1)
Takes a column key value (value of any cell within keyindex row) and returns the entire column, no match returns an empty list
Parameters:
key (Union[str,int,float,bool]) – any cell value within keyindex row (type sensitive)
keyindex (int, optional) – option keyrow override. Must be >0 and smaller than worksheet size, defaults to 1
Returns:
list of the entire matched key column data (only first match is returned)
Return type:
List[Union[str,int,float,bool]]
keyrow(key, keyindex=1)
Takes a row key value (value of any cell within keyindex col) and returns the entire row, no match returns an empty list
Parameters:
key (Union[str,int,float,bool]) – any cell value within keyindex col (type sensitive)
keyindex (int, optional) – option keyrow override. Must be >0 and smaller than worksheet size, defaults to 1
Returns:
list of the entire matched key row data (only first match is returned)
Return type:
List[Union[str,int,float,bool]]
range(address, formula=False, output='v')
Takes a range (ex: “A1:A2”) and returns a nested list [row][col]
Parameters:
address (str) – cell range (ex: “A1:A2”, or “A1”)
formula (bool, optional) – returns the values if false, or formulas if true of cells, defaults to False
output (str, optional) – output request “v” for value, “f” for formula, “c” for comment, defaults to ‘v’
Returns:
nested list [row][col] regardless if range is a single cell or a range
Return type:
_type_
row(row, formula=False, output='v')
Takes a row index input and returns a list of cell data
Parameters:
row (int) – row index (starting at 1)
formula (bool, optional) – flag to return the formula of this cell, defaults to False
output (str, optional) – output request “v” for value, “f” for formula, “c” for comment, defaults to ‘v’
Returns:
list of cell data
Return type:
List[Union[int, float, str, bool]]
rows
Returns a list of rows that can be iterated through
Returns: list of rows-lists (ex: [[11,12,13],[21,22,23]] for 2 rows with 3 columns of data
Return type: Iterable[List[Union[int, float, str, bool]]]
set_emptycell(val)
Custom definition for how pylightxl returns an empty cell
Parameters: val (Union[int, float, str]) – (default=’’) empty cell value
size
Returns the size of the worksheet (row/col)
Returns: list of [maxrow, maxcol]
Return type: List[int]
ssd(keyrows='KEYROWS', keycols='KEYCOLS')
Runs through the worksheet and looks for “KEYROWS” and “KEYCOLS” flags in each cell to identify the start of a semi-structured data. A data table is read until an empty header is found by row or column. The search supports multiple tables.
Parameters:
keyrows (str, optional) – a flag to indicate the start of keyrow’s cells below are read until an empty cell is reached, defaults to ‘KEYROWS’
keycols (str, optional) – a flag to indicate the start of keycol’s cells to the right are read until an empty cell is reached, defaults to ‘KEYCOLS’
Returns:
list of data dict in the form of [{‘keyrows’: [], ‘keycols’: [], ‘data’: [[], …]}, {…},]
Return type:
List[Dict[str,list]]
update_address(address, val)
Update worksheet data via address
Parameters:
address (str) – excel address (ex: “A1”)
val (Union[int, float, str, bool]) – cell value; equations are strings and must begin with “=”
update_index(row, col, val)
Update worksheet data via index
Parameters:
row (int) – row index
col (int) – column index
val (Union[int, float, str, bool]) – cell value; equations are strings and must begin with “=”
update_range(address, val)
Update worksheet data via address range with a single value
Parameters:
address (str) – excel address (ex: “A1:B3”)
val (Union[int, float, str, bool]) – cell value; equations are strings and must begin with “=”
3.3.3. Support Functions
pylightxl.pylightxl.utility_address2index(address)
Convert excel address to row/col index
Parameters: address (str) – Excel address (ex: “A1”)
Returns: list of [row, col]
Return type: List[int]
pylightxl.pylightxl.utility_index2address(row, col)
Converts index row/col to excel address
Parameters:
row (int) – row index (starting at 1)
col (int) – col index (start at 1 that corresponds to column “A”)
Returns:
str excel address
Return type:
str
pylightxl.pylightxl.utility_columnletter2num(text)
Takes excel column header string and returns the equivalent column count
Parameters: text (str) – excel column (ex: ‘AAA’ will return 703)
Returns: int of column count
Return type: int
pylightxl.pylightxl.utility_num2columnletters(num)
Takes a column number and converts it to the equivalent excel column letters
Parameters: num (int) – column number
Returns: excel column letters
Return type: str
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/552657.html
標籤:Python
上一篇:Spring Cloud開發實踐(五): Consul - 服務注冊的另一個選擇
下一篇:返回列表