一致性哈希演算法是1997年由麻省理工的幾位學者提出的用于解決分布式快取中的熱點問題,大家有沒有發現,我們之前介紹的例如快排之類的演算法是更早的六七十年代,此時分布式還沒有發展起來,
大家往往還在提高單機性能,但是九十年代開始,逐漸需要用分布式集群來解決大型問題,相應的演算法研究也就應運而生,
在說到一致性哈希演算法,我們還是得先從快取的發展談起:
快取,我們一般是用來提速的,當規模或者說資料量小時,我們往往用單機來部署一套快取系統即可,如下圖:
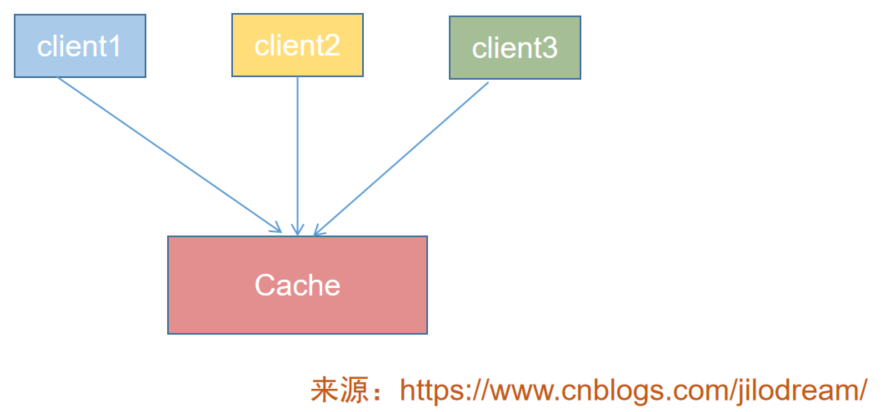
多臺客戶端在查詢資料時,只要根據key進入快取服務器查詢到自己想要的內容即可,
但是隨著業務的發展,單一的快取服務器往往無法支撐住我們的業務需要,比如快取資料太大,多城多活的網路部署等,
我們就需要多臺快取服務器來支撐,如下圖:
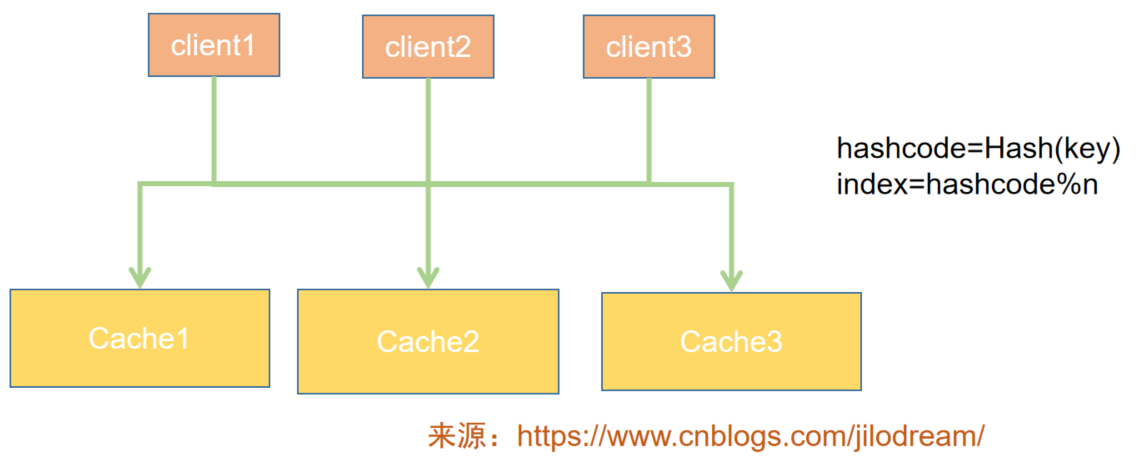
客戶端需要查詢快取時,先根據哈希演算法,講key進行計算,得到哈希值,然后通過哈希值對機器數取模(%n)來判定落在哪臺機器上,
這個架構很簡單,也很易實作,我們就不多說了,
但是這里會存在一個快取服務器伸縮的問題:什么意思呢?比如目前是三臺,我們由于業務的需要,需要變為四臺,或者變為兩臺,那么我們需要調整一遍所有資料所處的服務器位置,因為他們存在的位置都有可能改變,
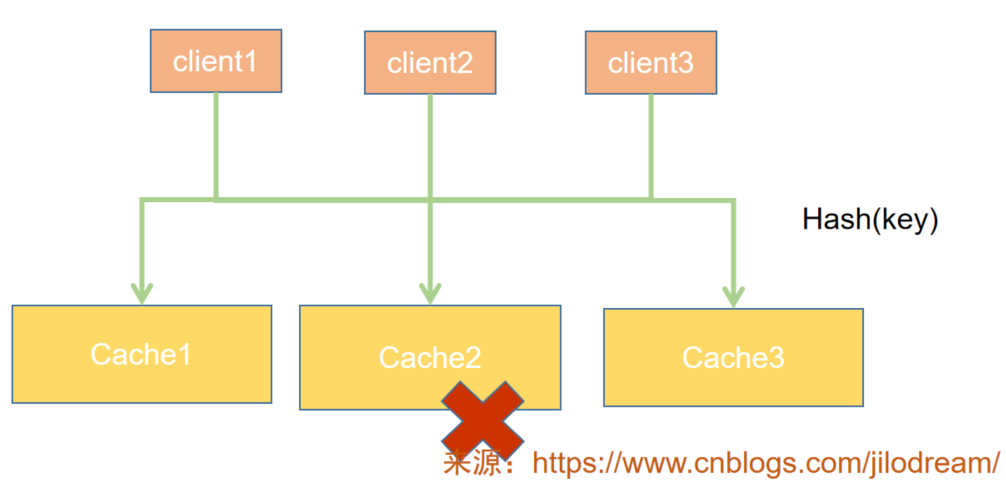
分布式快取本來就是為了解決大資料量問題的,此時重新調整,勢必會極度影響可用性,那么如何解決呢?
來看看一致性哈希演算法的思路:
我們假設存在一個虛擬環,這個環足夠大,上邊存在2^32個節點,三臺器機器呢,我們根據id計算出他們在環中所處的位置,如圖所示:

當我們計算資料所處的快取位置,不再是根據n來取模,而是根據2^32來取模,此時會有相當多的資料并沒有落在快取服務器所處的節點上,
那怎么辦呢?我們按照順時針方向計算,將資料落在下一個最*的順時針節點上,
如下圖所示:
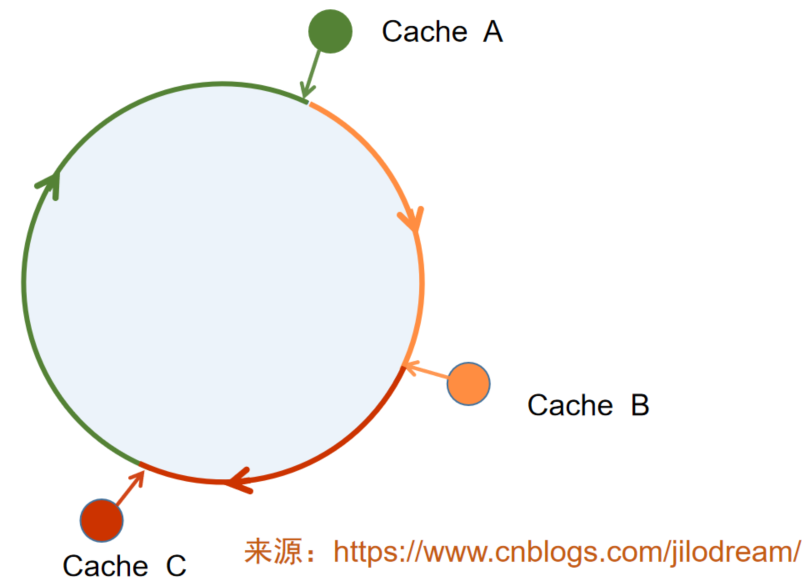
這樣當我們新增或者洗掉節點時,只會影響有限的節點上的資料,極大的縮小了受影響的節點和資料,我們只需要重新計算受影響的資料即可,但是這樣還會存在新的問題:
1、快取服務器計算出的位置不均勻,導致覆寫的節點數差異明顯;
2、資料并不均衡:資料經過哈希和取模運算后,可能落在集中的一片區域中,造成對應的快取服務器的資料特別大,
以上問題我們稱之為資料傾斜,資料傾斜的程度明顯后,可能會導致所解決的問題再次出現(前文中的紅字部分),
那如何解決這種問題呢?很簡單,加節點,只要節點足夠多,那么就會越來越趨*于*均,資料傾斜的情況就會越不突出,但是快取服務器是有限的,并不是想加多少都可以的,
那怎么辦呢?
我們可以采用虛擬快取節點的形式解決問題,什么是虛擬快取節點,就是并不實際存在的快取節點,只是一個虛擬的點,
每個真實的快取服務器對應多個虛擬快取節點,兩者是一對多的關系,如下圖所示:
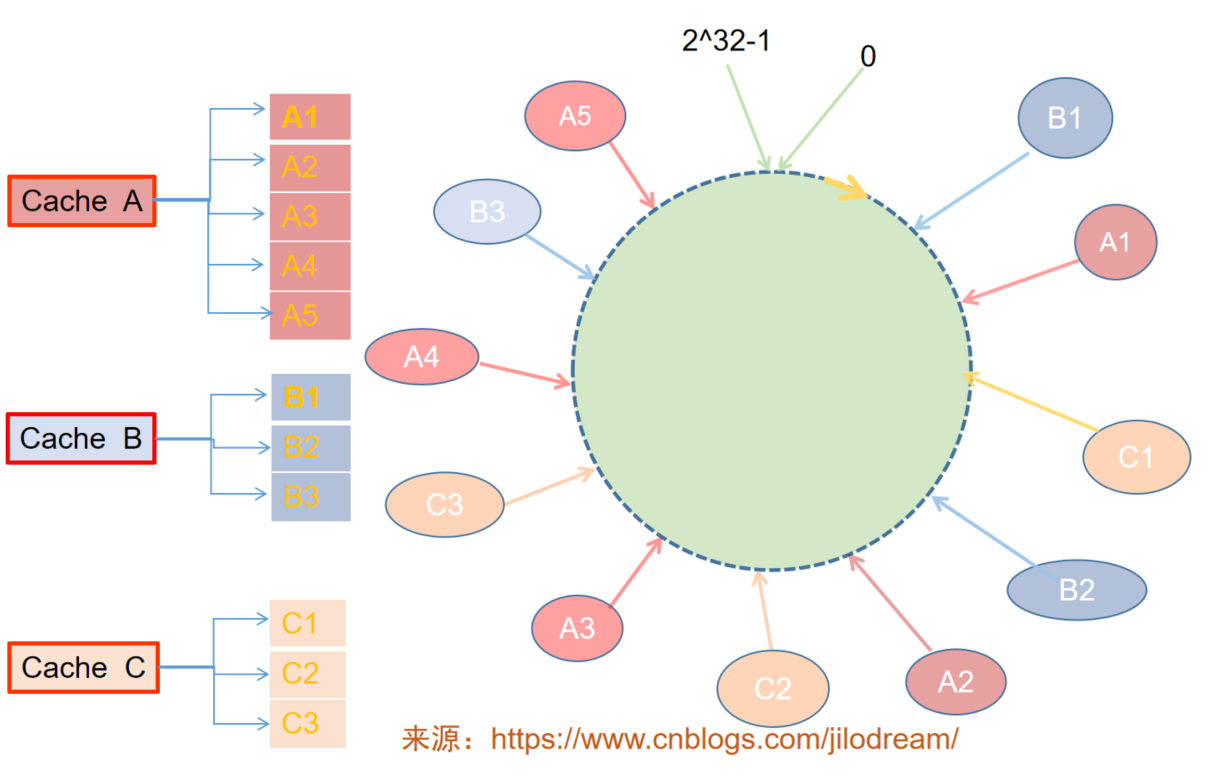
虛擬節點--圖中連接在環上的就是虛擬快取節點,
真實快取節點--Cache
每個Cache對應若干的虛擬節點,當增減Cache時,我們只要調整對應的虛擬節點所對應的資料即可,
如果你覺得寫的不錯,歡迎轉載和點贊, 轉載時請保留作者署名jilodream/王若伊_恩賜解脫(博客鏈接:http://www.cnblogs.com/jilodream/
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/554123.html
標籤:Java
下一篇:返回列表