基于回歸分析的波士頓房價分析
專案實作步驟:
1.專案結構
2.處理資料
3.處理繪圖
4.對資料進行分析
5.結果展示
一.專案結構

二.處理資料
from sklearn import datasets
import pandas as pd
"""
sklearn1.2版本后不在保留load_boston資料集,
可用
"""
def get_data():
# 獲取波士頓資料
# data_url = "http://lib.stat.cmu.edu/datasets/boston"
# raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
# print(raw_df)
# # 輸入
# boston_x = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
# # 輸出
# boston_y= raw_df.values[1::2, 2]
# # 自作資料集
# boston=pd.DataFrame(boston_x)
# print(boston)
boston=datasets.load_boston()
# 輸入
boston_x=boston.data
# 輸出
boston_y=boston.target
# 自制資料集
boston_new=pd.DataFrame(boston_x)
boston_new.columns=boston["feature_names"]
boston_new['PRICE']=boston_y
# 保存資料
# boston_new.to_csv('./models/Data/boston.csv')
return boston_new
使用sklearn的datasets時,對應的波士頓房價資料已經被“移除”,在獲取資料時,會出現

,此時,在該提示的下方會有相關的解決方法
不建議使用提供的方法,對應方法的資料與具體實作專案的資料有誤差
三.處理繪圖
1.繪圖前準備
import numpy as np
def get_request(request,data):
# 要處理的資料
# 設定初始值
control={
'CRIM':'城鎮人均犯罪率',
'ZN':'占地面接超過5萬平方米英尺的住宅用地面積',
'INDUS':'城鎮非零售業務的比例',
'CHAS':'查爾斯河虛擬變數',
'NOX':'一訊訓碳濃度',
'RM':'平均每個居民擁有的房數',
'AGE':'在1940年前建成的所有者占用單位的比例',
'DIS':'與五個波士頓就業中心的加權距離',
'TAX':'每10000美元的全額物業說率',
'PTRATIO':'城鎮師生比',
'B':'城鎮黑人比例',
'LSTAT':'低收入人口所占比例',
'PRICE':'房價'
}
if request in control.keys():
# 獲取價格的最大值和最小值
max=np.max(data['PRICE'])
min=np.min(data['PRICE'])
# 存盤最大值和最小值,對應的x軸標簽,y軸的標簽
request_data=https://www.cnblogs.com/prettyspider/p/list((max,min,control[request],control['PRICE']))
return request_data
else:
print('你輸入的資料不存在,請查看相關的檔案,查看你想要的資料型別')
用于處理繪圖前的準備作業,獲取對應的資料和標簽
繪圖
import matplotlib
import matplotlib.pyplot as plt
from models.chart.beforedraw import beforedraw
from models.CleanData.resolvedata import resolve_data
# 畫圖類
class draw:
def __init__(self,request):
self.data=https://www.cnblogs.com/prettyspider/p/resolve_data.get_data()
matplotlib.rc('font',family='SimHei')
plt.rcParams['axes.unicode_minus']=False
before_draw=beforedraw.get_request(request,self.data)
self.x_ticks_max=before_draw[0]
self.x_ticks_min=before_draw[1]
self.x_label=before_draw[2]
self.y_label=before_draw[3]
self.request=request
def draw_sactter(self):
plt.scatter(self.data['PRICE'],self.data[self.request])
plt.title(f'{self.x_label}與{self.y_label}的散點圖')
plt.xlabel(self.x_label)
plt.ylabel(self.y_label)
plt.xticks((range(int(self.x_ticks_min),int(self.x_ticks_max),10)))
plt.grid()
plt.show()
def draw_polt(self,title,x_data,y_data,x_label=None,y_label=None):
plt.plot(x_data,y_data)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.show()
def draw_bar(self,title,x_data,y_data,x_label=None,y_label=None):
plt.bar(x_data,y_data)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.show()
將繪圖封裝成類,便于后期的繪圖
四.對資料進行分析
分別實作房價與各引數的線性回歸分析,繪制出房價的預測值;蠶蛹邏輯回歸分析,對是否居住在河邊進行邏輯回歸分析
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from models.CleanData.resolvedata import resolve_data
from models.chart.draw import draw
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LinearRegression
# 回歸/分類模型的評價方法
from sklearn.metrics import mean_squared_error #MSE
from sklearn.metrics import mean_absolute_error #MAE
# 分類
from sklearn.linear_model import LogisticRegression
class Learning():
def __init__(self):
self.data=https://www.cnblogs.com/prettyspider/p/resolve_data.get_data()
self.values=self.data.values
self.columns=self.data.columns
self.x_train =''
self.x_test = ''
self.y_train = ''
self.y_test = ''
self.train_test_split_linear()
self.draw=draw.draw("ZN")
self.fill_nan()
self.log()
# 切分資料集
def train_test_split_linear(self):
self.x_train,self.x_test,self.y_train,self.y_test=train_test_split(self.values[:,0:-1],self.values[:,-1],test_size=0.2)
# 彌補缺失值
def fill_nan(self,):
if sum(self.data.isnull().sum())!=0:
simple_imp=SimpleImputer(missing_values=np.nan,strategy='mean')
self.data=https://www.cnblogs.com/prettyspider/p/simple_imp.fit(self.data)
self.standard_scaler()
# 歸一化
def standard_scaler(self):
scaler=StandardScaler()
# fit_transform()一般用于訓練集,transform一般用于測驗集
self.x_train=scaler.fit_transform(self.x_train)
self.x_test=scaler.transform(self.x_test)
self.linear()
# 線性回歸
def linear(self):
linear=LinearRegression()
self.models_1=linear.fit(self.x_train,self.y_train)
# 對模型進行打分
# print(self.models.score(self.x_test,self.y_test))
self.linear_metrics()
def linear_metrics(self):
# MSE均方誤差
linear_MSE=mean_squared_error(self.y_train,self.models_1.predict(self.x_train))
# RMSE均方根誤差 MSE的開方
linear_RMSE=mean_squared_error(self.y_train,self.models_1.predict(self.x_train))**0.5
# MAE平均絕對誤差
linear_MAE=mean_absolute_error(self.y_train,self.models_1.predict(self.x_train))
# 誤差
print(f'MSE均方誤差:{linear_MSE},RMSE均方根誤差{linear_RMSE},MAE平均絕對誤差{linear_MAE}')
# 房價預測值
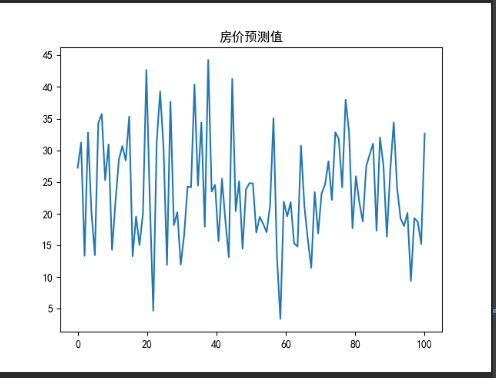
self.draw.draw_polt("房價預測值",np.linspace(0,100,102),self.models_1.predict(self.x_test))
# 分類
def log(self):
# 測驗集
x_log_l=self.values[:,0:1]
x_log_r=self.values[:,4:]
y_log=self.values[:,3]
x_log=np.hstack((x_log_l,x_log_r))
log=LogisticRegression()
x_train,x_test,y_train,y_test=train_test_split(x_log,y_log,test_size=0.3)
models_2=log.fit(x_train,y_train)
# 預測值
print(x_test,models_2.predict(x_test))
# 評分
print(models_2.score(x_test,y_test))
# 權重
print(models_2.coef_)
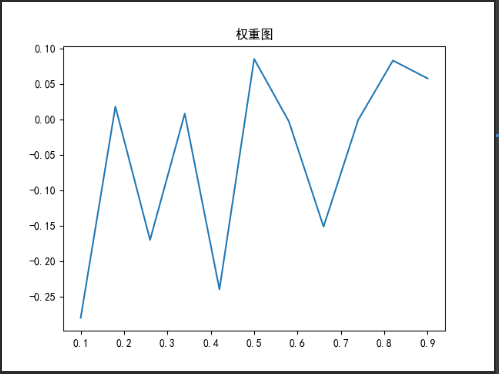
self.draw.draw_polt("權重圖",np.linspace(0.1,0.9,11),models_2.coef_[0],'','')
one_array=[]
zero_array=[]
for item in models_2.predict(x_test):
if item==0:
zero_array.append(item)
else:
one_array.append(item)
self.draw.draw_bar("預測值計較",['0','1'],[len(zero_array),len(one_array)])
五.結構展示
線性回歸的誤差分析結果

線性回歸的房價預測
邏輯回歸的權重圖
邏輯回歸的預測圖
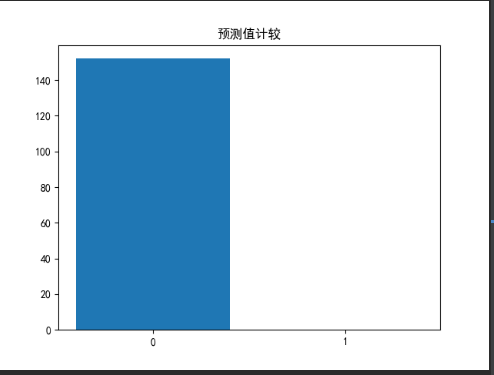
在邏輯回歸中,各闡述對于是否居住于河邊的影響大,對應的評分在80%以上
專案完成!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/555436.html
標籤:Python
下一篇:返回列表