1、安裝ES和Kibana
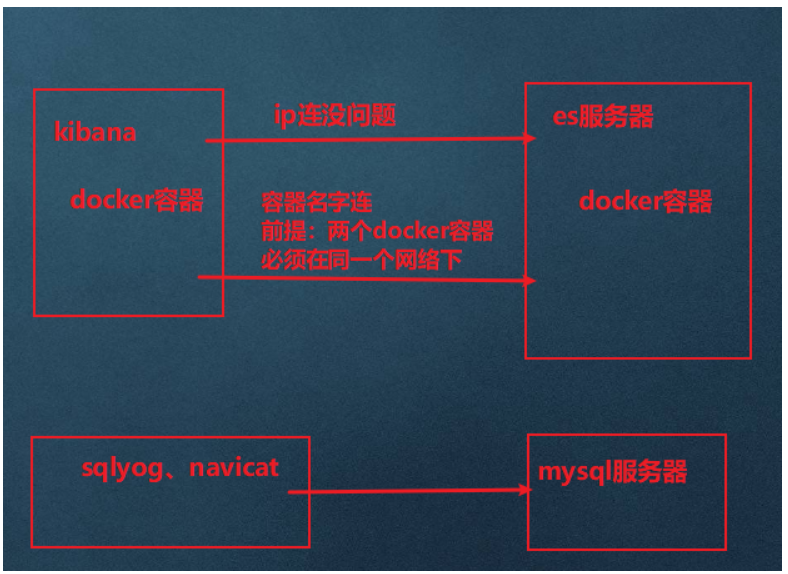
kibana和ES的關系
ES安裝
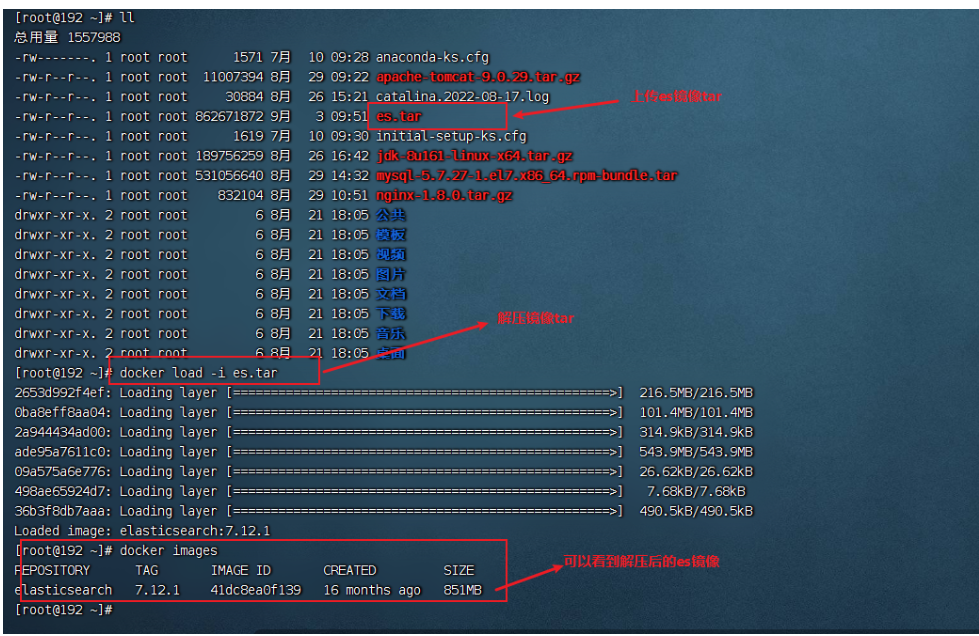
可以自己使用docker pull拉取鏡像,但是因為ES比較大,可能比較慢,這里建議大家用解壓包的方式獲得鏡像
獲取鏡像
啟動容器
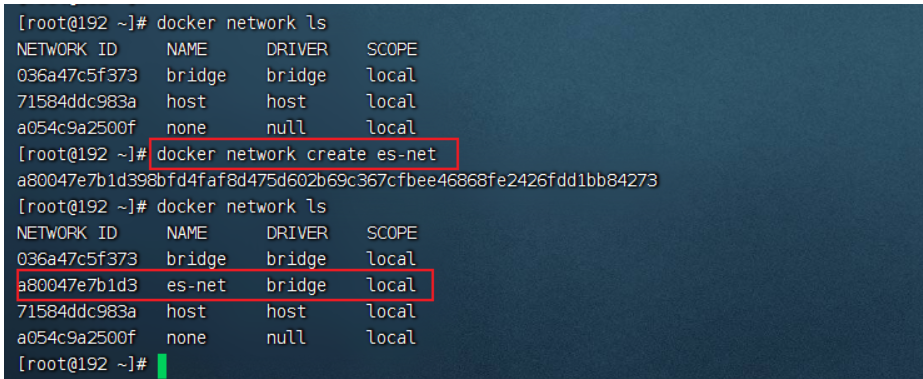
- 創建網卡(方便kibana通過es容器名連接)
- 啟動容器
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
命令解釋:
-e "cluster.name=es-docker-cluster":設定集群名稱-e "http.host=0.0.0.0":監聽的地址,可以外網訪問-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":記憶體大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:掛載邏輯卷,系結es的資料目錄-v es-logs:/usr/share/elasticsearch/logs:掛載邏輯卷,系結es的日志目錄-v es-plugins:/usr/share/elasticsearch/plugins:掛載邏輯卷,系結es的插件目錄--privileged:授予邏輯卷訪問權--network es-net:加入一個名為es-net的網路中-p 9200:9200:埠映射配置

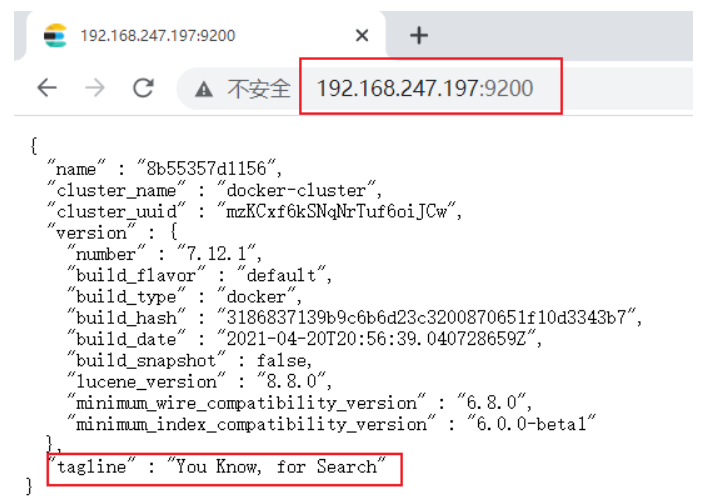
瀏覽器訪問檢測
啟動會有點慢,需要耐心等待下,另外虛擬機的記憶體最少設定為2G,否則記憶體不夠用
Kibana安裝
獲取鏡像
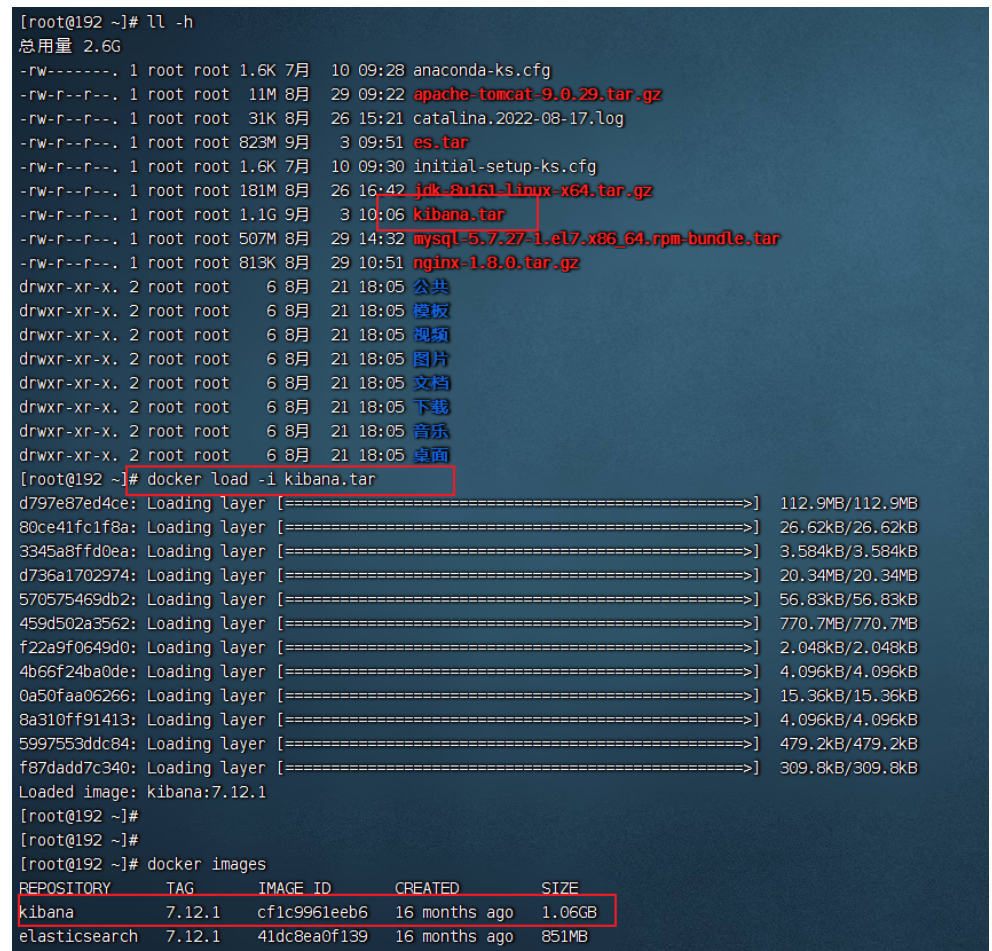
啟動容器
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
命令解釋
--network es-net:加入一個名為es-net的網路中,與elasticsearch在同一個網路中-e ELASTICSEARCH_HOSTS=http://es:9200":設定elasticsearch的地址,因為kibana已經與elasticsearch在一個網路,因此可以用容器名直接訪問elasticsearch-p 5601:5601:埠映射配置
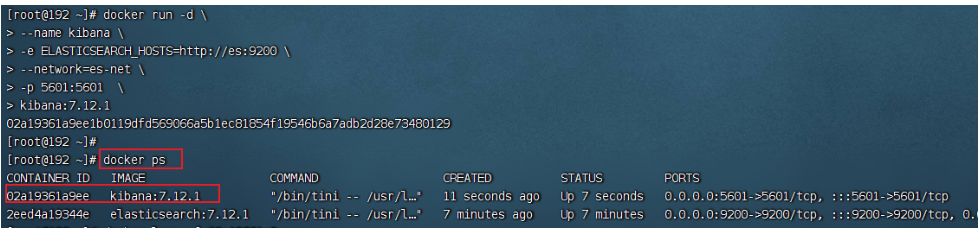
瀏覽器訪問檢測
ik分詞器安裝
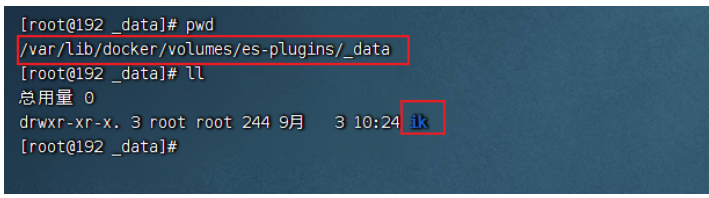
查看es插件掛在的資料卷目錄
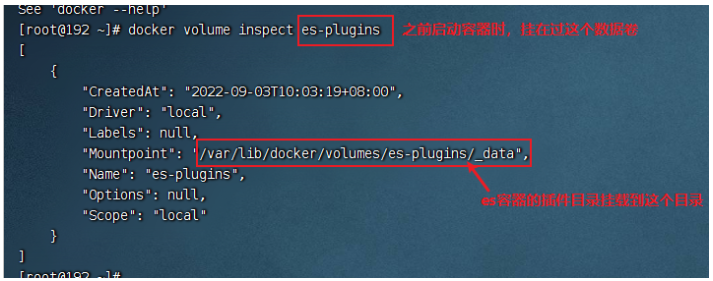
上傳ik插件到掛在的目錄
將資料中的ik壓縮包解壓后,上傳
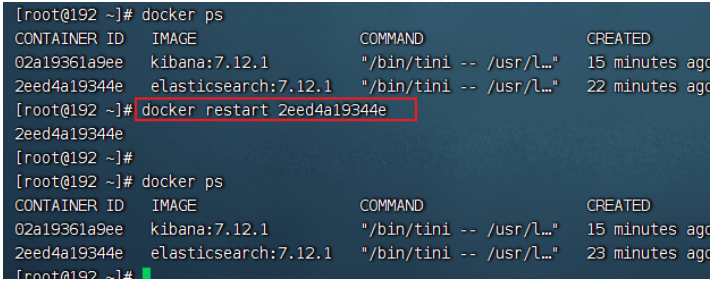
重啟es容器
配置自己的擴展詞&忽略詞
- 修改配置,增加擴展詞&忽略詞配置
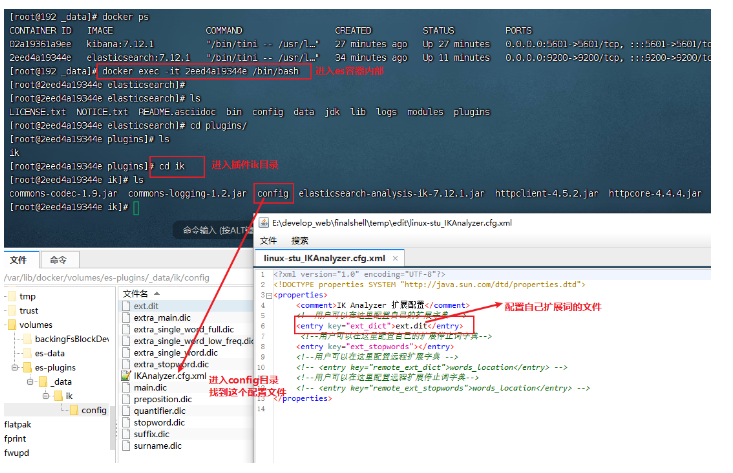
- 配置自己的擴展詞
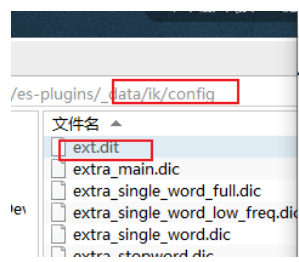
- 重啟es容器,再次測驗觀察結果
5、索引庫操作(DSL)
mapping映射屬性
mapping是對索引庫中檔案的約束,常見的mapping屬性包括:
- type:欄位資料型別,常見的簡單型別有:
- 字串:text(可分詞的文本)、keyword(精確值,例如:品牌、國家、ip地址)
- 數值:long、integer、short、byte、double、float、
- 布爾:boolean
- 日期:date
- 物件:object
- index:是否創建索引,默認為true
- analyzer:使用哪種分詞器
- properties:該欄位的子欄位
例如下面的json檔案:
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "營養師",
"email": "[email protected]",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "云",
"lastName": "趙"
}
}
對應的每個欄位映射(mapping):
- age:型別為 integer;參與搜索,因此需要index為true;無需分詞器
- weight:型別為float;參與搜索,因此需要index為true;無需分詞器
- isMarried:型別為boolean;參與搜索,因此需要index為true;無需分詞器
- info:型別為字串,需要分詞,因此是text;參與搜索,因此需要index為true;分詞器可以用ik_smart
- email:型別為字串,但是不需要分詞,因此是keyword;不參與搜索,因此需要index為false;無需分詞器
- score:雖然是陣列,但是我們只看元素的型別,型別為float;參與搜索,因此需要index為true;無需分詞器
- name:型別為object,需要定義多個子屬性
- name.firstName;型別為字串,但是不需要分詞,因此是keyword;參與搜索,因此需要index為true;無需分詞器
- name.lastName;型別為字串,但是不需要分詞,因此是keyword;參與搜索,因此需要index為true;無需分詞器
創建索引(PUT)

獲取索引(GET)
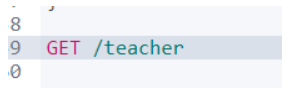
修改索引(PUT)
注意,不能改變原來索引的映射,因為倒排索引構建非常消耗時間,所以不允許修改,
但是可以在原來映射的基礎上,新增欄位,

洗掉索引(DELETE)
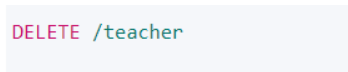
6、檔案操作(DSL)
創建檔案(POST)
POST /teacher/_doc/1
{
"age": 18,
"info": "營養師幫助人們健康飲食,很好",
"email": "[email protected]",
"name": {
"firstName": "張",
"lastName": "三"
}
}
POST /teacher/_doc/2 /*指定id創建*/
{
"age": 28,
"info": "營養師幫助人們健康飲食",
"email": "[email protected]",
"name": {
"firstName": "王",
"lastName": "五"
}
}
POST /teacher/_doc /*不指定id創建,會隨機自動生成*/
{
"age": 38,
"info": "營養師幫助健康飲食",
"email": "[email protected]",
"name": {
"firstName": "李",
"lastName": "四"
}
}
洗掉檔案(DELETE)
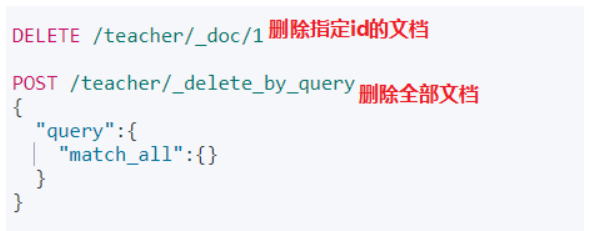
修改檔案(POST)
/*修改--全量修改(當id對應的檔案存在,洗掉原檔案,新建現在的檔案)*/
POST /teacher/_doc/2 /*_doc和新增檔案語法一致, 如果該id存在,是更新操作,如果該id不存在,就是新增操作*/
{
"age": 28,
"info": "營養師幫助人們健康飲食",
"email": "[email protected]",
"name": {
"firstName": "王",
"lastName": "五"
}
}
/*修改--增量(部分)修改*/
POST /teacher/_update/2 /*_update,在原有檔案記錄的基礎上個,新增新的內容*/
{
"doc":{
"email": "[email protected]"
}
}
查詢檔案(GET)
簡單查詢
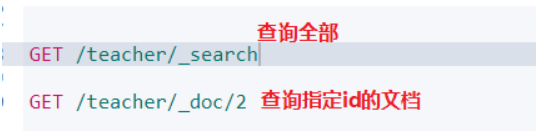
全文檢索-單欄位匹配
/*全文檢索 -單欄位檢索 飲食 --> 飲食,飲,食*/
GET /teacher/_search
{
"query":{
"match":{
"info":"飲食"
}
}
}
全文檢索-多欄位匹配
/*全文檢索 -多欄位檢索
檢索info或者name.lastname中包含的*/
GET /teacher/_search
{
"query":{
"multi_match":{
"query":"飲食",
"fields":["info","name.lastname"]
}
}
}
精準查詢-term
/*精準查詢 -term查詢
term查詢中關鍵詞是不會分詞的,info中必須包含上述這個詞的資訊*/
GET /teacher/_search
{
"query":{
"term":{
"info":{
"value":"飲食"
}
}
}
}
精準查詢-range
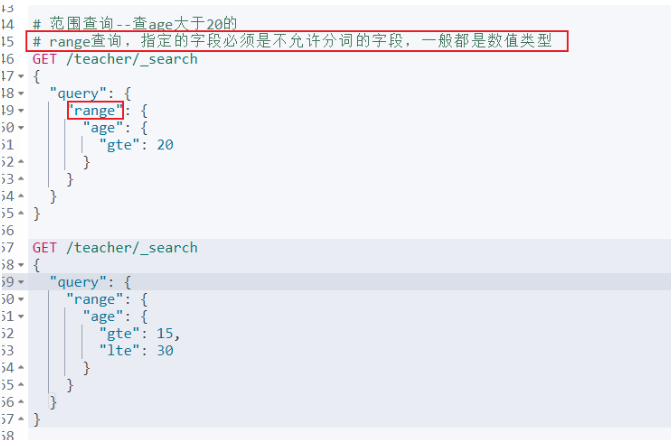
布爾查詢-多條件查詢
must
/*查詢中info包含飲食,且年齡大于20
must必須的,多個條件之間是and關系*/
GET /teacher/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"info":"飲食"
}
},
{
"range":{
"age":{
"gte":20
}
}
}
]
}
}
}
shoud
/*查詢中info包含飲食,且年齡大于20
must可選的,多個條件之間是or關系*/
GET /teacher/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"info":"飲食"
}
},
{
"range":{
"age":{
"gte":20
}
}
}
]
}
}
}
must_not
/*查詢中info包含飲食,但fistname不可以是 李
must_not 不允許,對條件進行取反操作,一般用來過濾*/
GET /teacher/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"info":"飲食"
}
}
],
"must_not":[
{
"term":{
"name.firstname":{
"value":"李"
}
}
}
]
}
}
}
filter
/*查詢中info包含飲食,且年齡大于20
filter過濾,在原本資料的基礎上進行一些過濾,過濾條件是不參與算分的,所以在進行條件過濾時,使用filter效率會提高*/
GET /teacher/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"info":"飲食"
}
}
],
"filter":[
{
"range":{
"age":{
"gte":20
}
}
}
]
}
}
}
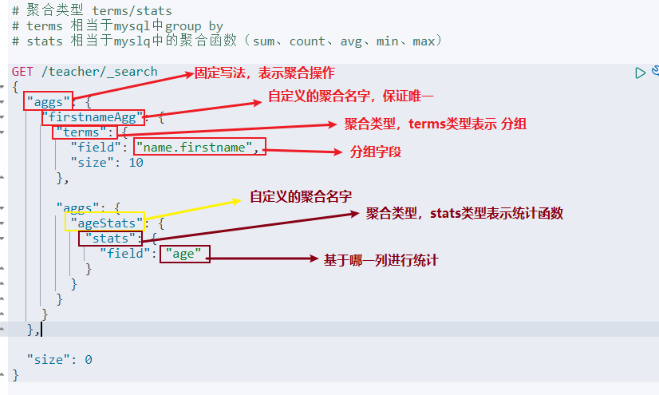
聚合查詢
- 分組聚合
相當于: select avg(age),sum(age),... from teacher group by firstname;
查詢陳述句
查詢結果

- 不分組全檔案聚合
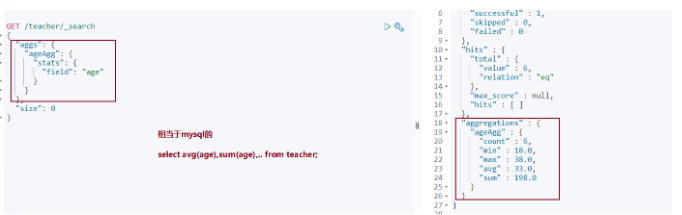
- 不分組帶條件聚合
查詢結果處理
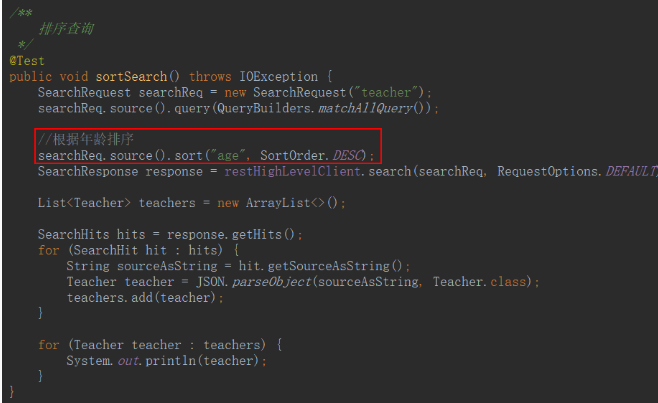
排序

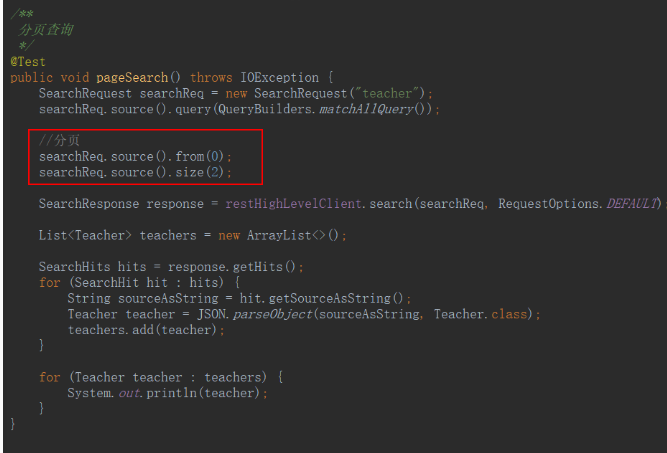
分頁
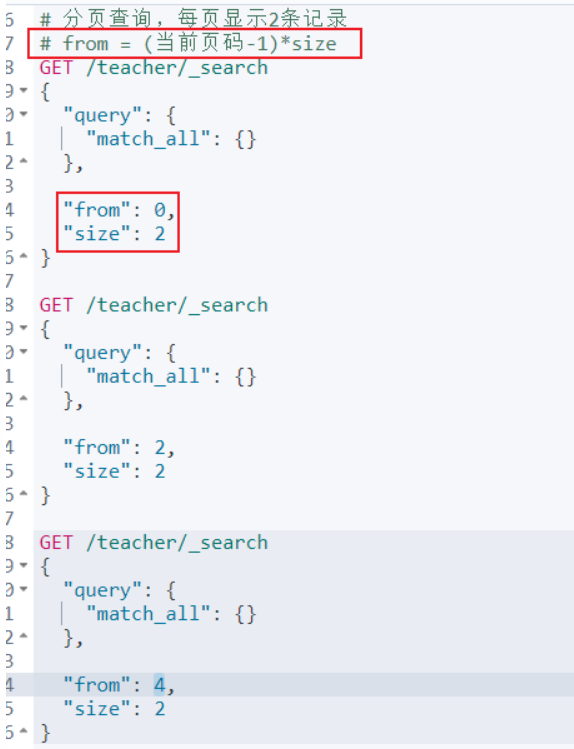
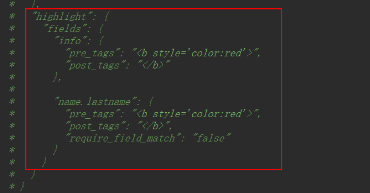
高亮

7、索引操作(JAVA)
集成es環境
- 引入依賴
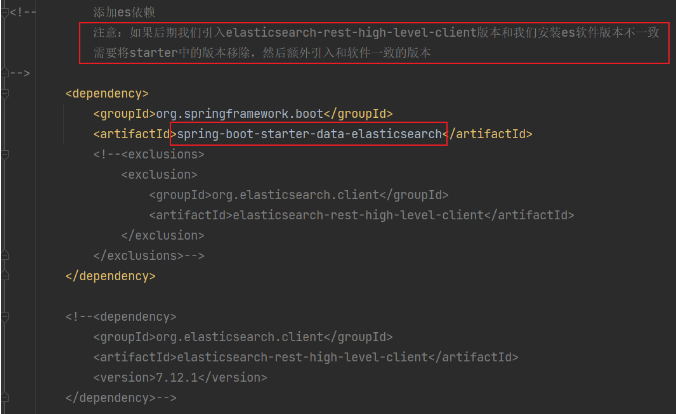
- 撰寫配置
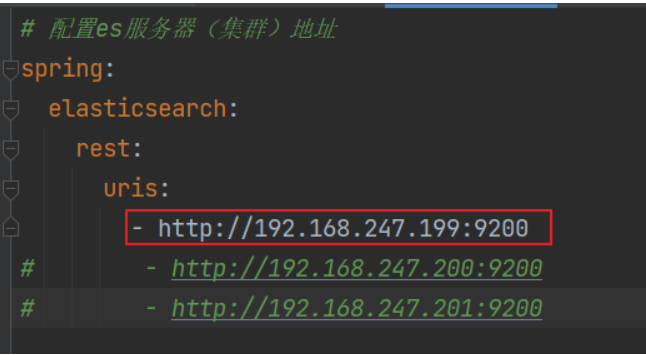
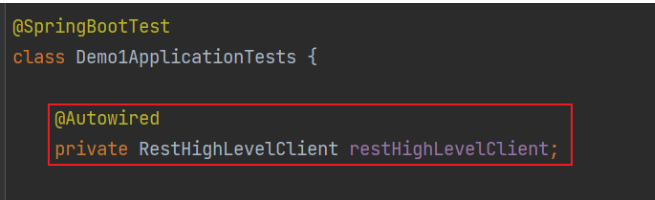
- 注入核心物件,執行操作
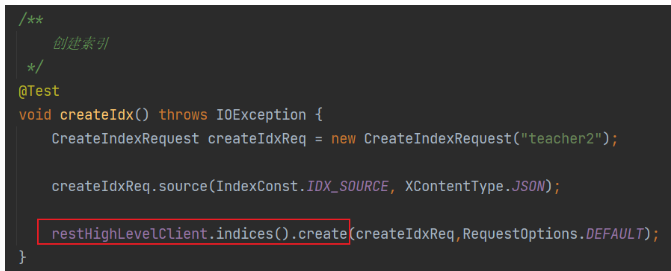
創建索引
洗掉索引
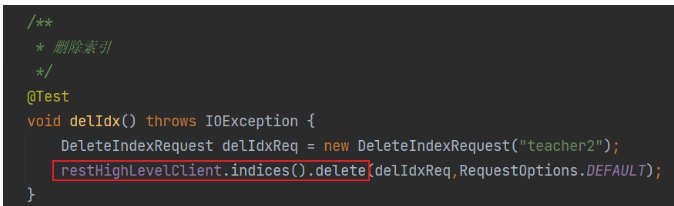
修改索引(沒有)
查詢索引
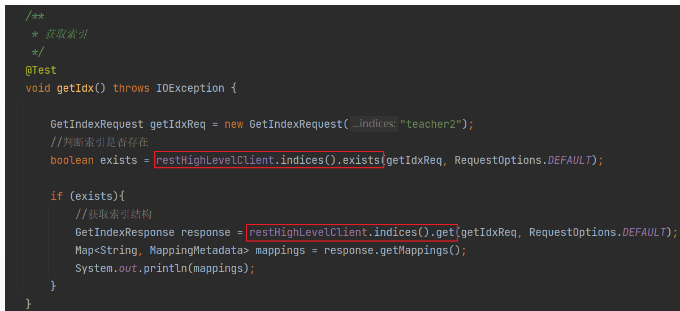
8、檔案操作(JAVA)
創建檔案
/*
新增檔案
*/
@Test
void createDoc() throws IOException {
IndexRequest idxReq = new IndexRequest("teacher").id("11");
Teacher teacher = new Teacher();
teacher.setAge(48);
teacher.setInfo("營養師");
teacher.setEmail("[email protected]");
Name name = new Name();
name.setFirstname("陳");
name.setLastname("飛");
teacher.setName(name);
idxReq.source(JSON.toJSONString(teacher),XContentType.JSON);
restHighLevelClient.index(idxReq,RequestOptions.DEFAULT);
}
洗掉檔案
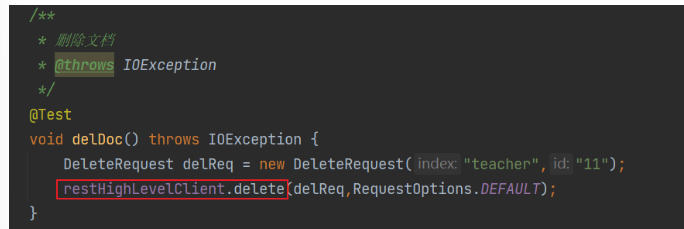
修改檔案
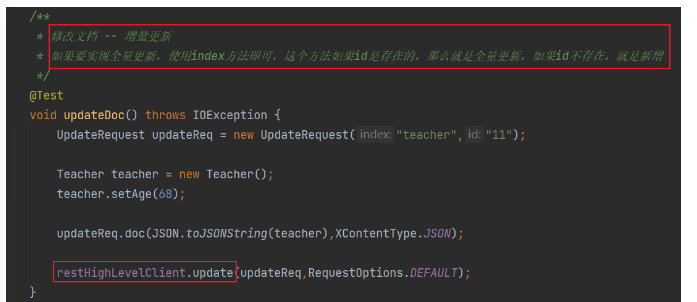
查詢檔案
簡單查詢
- 查詢單個檔案
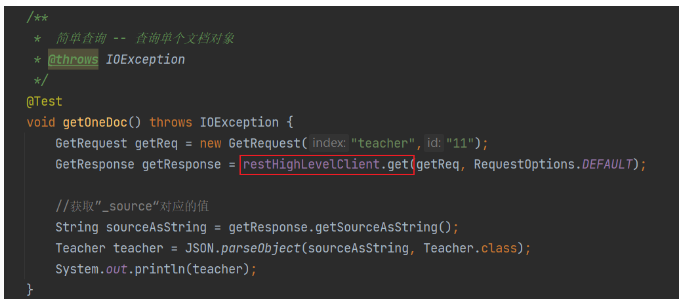
)
- 查詢所有檔案
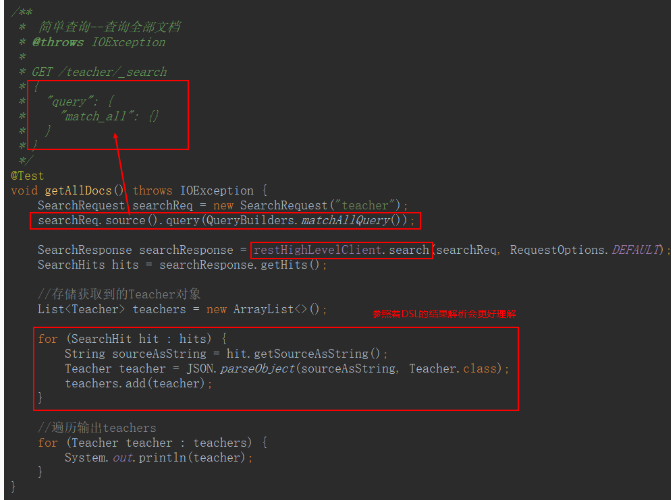
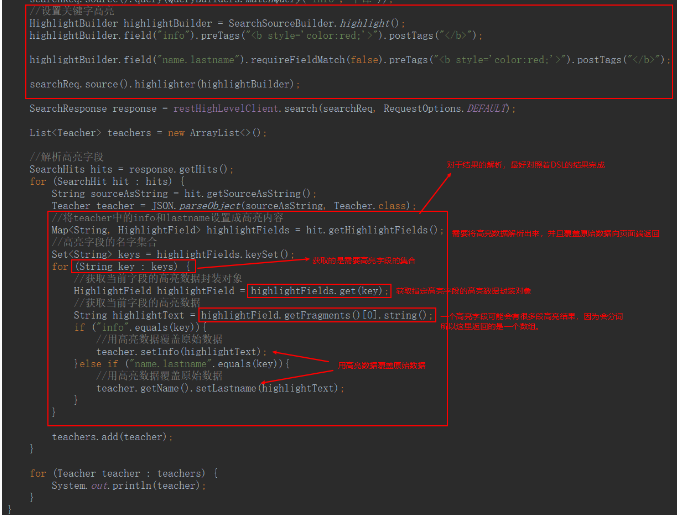
全文檢索-單欄位匹配
/*
全文檢索 -單欄位檢索
GET /teacher/_search
*/
@Test
void matchSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("teacher");
searchRequest.source().query(QueryBuilders.matchQuery("info","飲食"));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
List<Teacher> teachers = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
Teacher teacher = JSON.parseObject(sourceAsString,Teacher.class);
teachers.add(teacher);
}
teachers.forEach(System.out::println);
}
全文檢索-多欄位匹配
/*
全文檢索 -多欄位匹配
GET /teacher/_search
*/
@Test
void multiMatchSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("teacher");
searchRequest.source().query(QueryBuilders.multiMatchQuery("飲食","info","name.lastname"));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
List<Teacher> teachers = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
Teacher teacher = JSON.parseObject(sourceAsString,Teacher.class);
teachers.add(teacher);
}
teachers.forEach(System.out::println);
}
精準查詢-term
/*
-精確查詢-term
GET /teacher/_search
*/
@Test
void termSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("teacher");
searchRequest.source().query(QueryBuilders.termQuery("info","飲食"));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
List<Teacher> teachers = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
Teacher teacher = JSON.parseObject(sourceAsString,Teacher.class);
teachers.add(teacher);
}
teachers.forEach(System.out::println);
}
精準查詢-range
/*
-精確查詢-range
GET /teacher/_search
*/
@Test
void rangeSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("teacher");
searchRequest.source().query(QueryBuilders.rangeQuery("age".gte(20)));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
List<Teacher> teachers = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
Teacher teacher = JSON.parseObject(sourceAsString,Teacher.class);
teachers.add(teacher);
}
teachers.forEach(System.out::println);
}
布爾查詢-多條件查詢
/*
布爾條件查詢
GET /teacher/_search
*/
@Test
void matchSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("teacher");
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
List<QueryBuilder> should = boolQuery.should();
should.add(QueryBuilders.rangeQuery("age".gte(20)));
should.aad(QueryBuilders.termQuery("name.firstname","李"));
searchRequest.source().query(boolQuery);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
List<Teacher> teachers = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
Teacher teacher = JSON.parseObject(sourceAsString,Teacher.class);
teachers.add(teacher);
}
teachers.forEach(System.out::println);
}
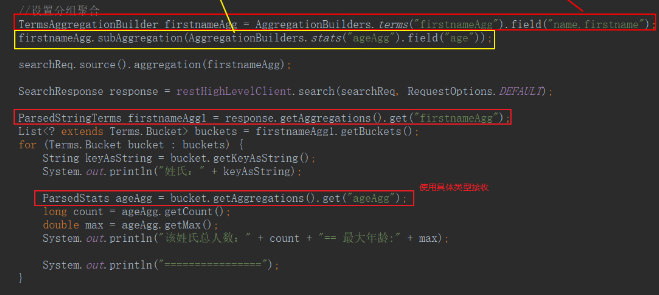
聚合查詢
- 分組聚合統計
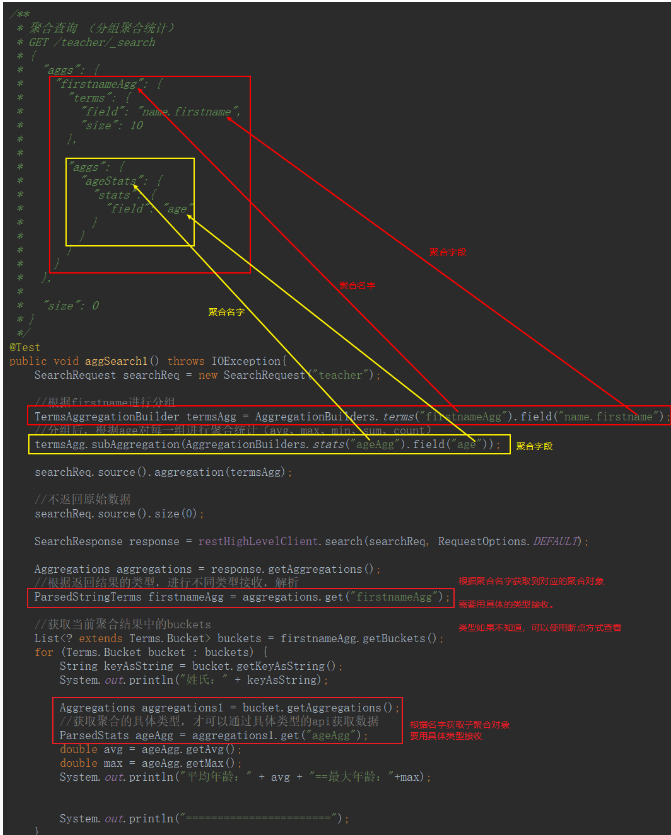
- 全索引聚合統計
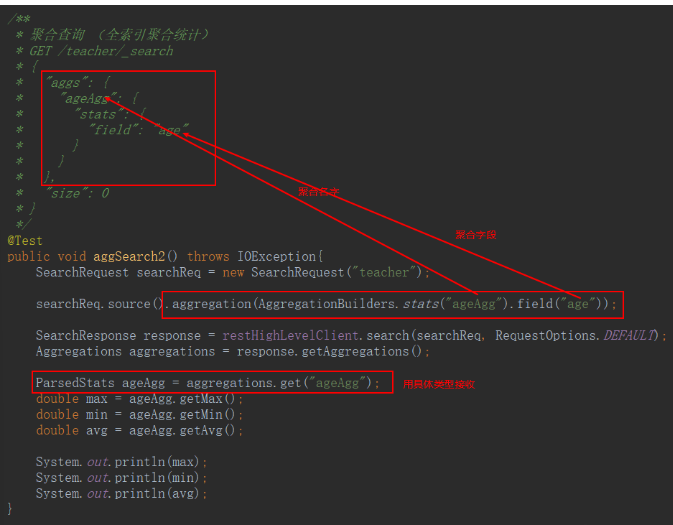
- 條件篩選后聚合統計
/*
聚合查詢 條件過濾后聚合統計
GET /teacher/_search
*/
@Test
void aggSearch3() throws IOException {
SearchRequest searchReq = new SearchRequest("teacher");
//設定查詢條件
searchReq.source().query(QueryBuilders.matchQuery("info","飲食"));
查詢結果處理
排序
分頁
高亮
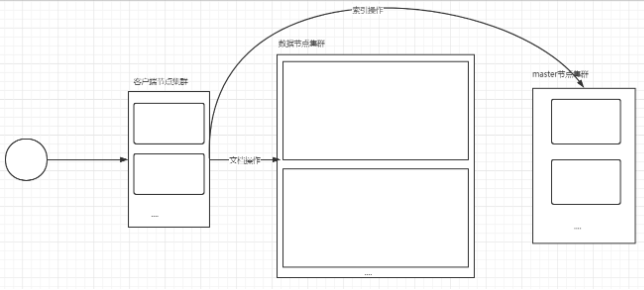
節點型別
Master節點:管理索引:索引創建、索引洗掉;DataNode節點中分片管理:分片資訊記錄、分片劃分;不負責資料的寫入和檢索,這類節點記憶體可以小一些,但是服務器要穩定
DataNode節點:負責資料的寫入和檢索,所有DataNode節點沒有主從節點的關系,但是節點上會存在主從分片,這類節點要求記憶體大
客戶端節點:不負責任何資料存盤操作,這類節點主要用來接收客戶端的請求,實作負載均衡
在實際部署es集群時,上述三類節點都需要部署,而且這三類節點要求分開部署
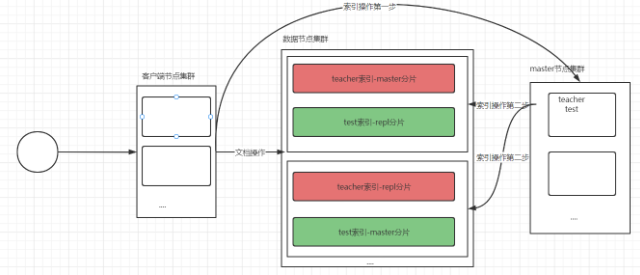
集群中寫一條資料的程序
- 資料節點分片含義
- 寫一條檔案資料
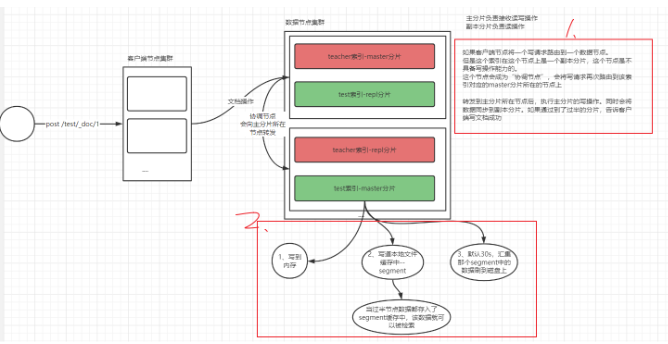
es洗掉檔案機制
es中檔案是不可以修改不可洗掉,當我們在洗掉檔案時,檔案資料并不是真的從es中被刪掉,有一個惰性洗掉效果,
在每個segment檔案中會維護一個.del檔案,當我們洗掉檔案時,會在.del檔案中記錄這個被洗掉檔案的id,當我們檢索資料時,這個被記錄的id檔案是不會被檢索出來的,
當segment大小達到一定程度,為了提升讀取資料效率,會對segment進行合并,在合并成新的segment檔案時,原本被記錄在.del中的資料是不參與合并,此時這個檔案資料才會被真正洗掉,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/555663.html
標籤:其他
上一篇:java~二進制補碼的用途
下一篇:返回列表