作者:Kaito
鏈接:kaito-kidd.com/2020/06/28/redis-vs-memcached/
前言
我們都知道,Redis和Memcached都是記憶體資料庫,它們的訪問速度非常之快,但我們在開發程序中,這兩個記憶體資料庫,我們到底要如何選擇呢?它們的優劣都有哪些?
為什么現在看Redis要比Memcached更火一些?
這篇文章,我們就從各個方面來對比這兩個記憶體資料庫的差異,方便你在使用時,做出最符合業務需要的選擇,
要分析它們的區別,主要從以下幾個方面對比:
-
執行緒模型
-
資料結構
-
淘汰策略
-
管道與事務
-
持久化
-
高可用
-
集群化
執行緒模型
要說性能,必須要分析它們的服務模型,
Memcached處理請求采用多執行緒模型,并且基于IO多路復用技術,主執行緒接收到請求后,分發給子執行緒處理,
這樣做好的好處是,當某個請求處理比較耗時,不會影響到其他請求的處理,
當然,缺點是CPU的多執行緒切換必然存在性能損耗,同時,多執行緒在訪問共享資源時必然要加鎖,也會在一定程度上降低性能,
Redis同樣采用IO多路復用技術,但它處理請求采用是單執行緒模型,從接收請求到處理資料都在一個執行緒中完成,推薦看一下這篇《Redis 到底是單執行緒還是多執行緒?》,
這意味著使用Redis,一旦某個請求處理耗時比較長,那么整個Redis就會阻塞住,直到這個請求處理完成后回傳,才能處理下一個請求,使用Redis時一定要避免復雜的耗時操作,
單執行緒的好處是,少了CPU的背景關系切換損耗,沒有了多執行緒訪問資源的鎖競爭,但缺點是無法利用CPU多核的性能,
由于Redis是記憶體資料庫,它的訪問速度非常地快,所以它的性能瓶頸不在于CPU,而在于記憶體和網路帶寬,這也是作者采用單執行緒模型的主要原因,同時,單執行緒對于程式開發非常友好,除錯起來也很方便,開發多執行緒程式必然會增加一定的除錯難度,
因此,當我們的業務使用key的資料比較大時,Memcached的訪問性能要比Redis好一些,如果key的資料比較小,兩者差別并不大,
嚴格來說,Redis的單執行緒指的是處理請求的執行緒,它本身還有其他執行緒在作業,例如有其他執行緒用來異步處理耗時的任務,
Redis6.0又進一步完善了多執行緒,在接收請求和發送請求時使用多線,進一步提高了處理性能,
資料結構
Memcached支持的資料結構很單一,僅支持string型別的操作,并且對于value的大小限制必須在1MB以下,過期時間不能超過30天,
而Redis支持的資料結構非常豐富,除了常用的資料型別string、list、hash、set、zset之外,還可以使用geo、hyperLogLog資料型別,
使用Memcached時,我們只能把資料序列化后寫入到Memcached中,然后再從Memcached中讀取資料,再反序列化為我們需要的格式,只能“整存整取”,
而Redis對于不同的資料結構可以采用不同的操作方法,非常靈活,
-
list:可以方便的構建一個鏈表,或者當作佇列使用
-
hash:靈活地操作我們需要的欄位,進行“整存零取”、“零存整取”以及“零存零取”
-
set:構建一個不重復的集合,并方便地進行差集、并集運算
-
zset:構建一個排行榜,或帶有權重的串列
-
geo:用于地圖相關的業務,標識兩個地點的坐標,以及計算它們的距離
-
hyperLogLog:使用非常少的記憶體計算UV
總之,Redis正是因為提供了這么豐富的資料結構,近幾年在記憶體資料庫領域大放異彩,為我們的業務開發提供了極大的便利,關注公眾號Java技術堆疊獲取更多資料型別的詳細使用教程,
淘汰策略
Memcached必須設定整個實體的記憶體上限,資料達到上限后觸發LRU淘汰機制,優先淘汰不常用使用的資料,
但它的資料淘汰機制存在一些問題:剛寫入的資料可能會被優先淘汰掉,這個問題主要是它本身記憶體管理設計機制導致的,
Redis沒有限制必須設定記憶體上限,如果記憶體足夠使用,Redis可以使用足夠大的記憶體,推薦看下《Redis 記憶體滿了怎么辦》
同時Redis提供了多種淘汰策略:
-
volatile-lru:從過期key中按LRU機制淘汰
-
allkeys-lru:在所有key中按LRU機制淘汰
-
volatile-random:在過期key中隨機淘汰key
-
allkeys-random:在所有key中隨機淘汰key
-
volatile-ttl:優先淘汰最近要過期的key
-
volatile-lfu:在所有key中按LFU機制淘汰
-
allkeys-lfu:在過期key中按LFU機制淘汰
我們可以針對業務場景,使用不同的資料淘汰策略,
管道與事務
Redis還支持管道功能,客戶端一次性打包發送多條命令到服務端,服務端依次處理客戶端發來的命令,這樣可以減少來回往來的網路IO次數,提供高訪問性能,
另外它還支持事務,這里所說的事務并不是MySQL那樣嚴格的事務模型,這種事務模型是Redis特有的,
一般事務會配合管道一塊使用,客戶端一次性打包發送多條命令到服務端,并且標識這些命令必須嚴格按順序執行,不能被其他客戶端打斷,同時執行事務之前,客戶端可以告訴服務端某個key稍后會進行相關操作,如果這個客戶端在操作這個key之前,有其他客戶端對這個key進行更改,那么當前客戶端在執行這些命令時會放棄整個事務操作,保證一致性,
持久化
Memcached不支持資料的持久化,如果Memcached服務宕機,那么這個節點的資料將全部丟失,
Redis支持將資料持久化磁盤上,提供RDB和AOF兩種方式:
-
RDB:將整個實體中的資料快照到磁盤上,全量持久化
-
AOF:把每一個寫命令持久到磁盤,增量持久化
Redis使用這兩種方式相互配合,完成資料完整性保障,最大程度降低服務宕機導致的資料丟失問題,
高可用
Memcached沒有主從復制架構,只能單節點部署,如果節點宕機,那么該節點資料全部丟失,業務需要對這種情況做兼容處理,當某個節點不可用時,把資料寫入到其他節點以降低對業務的影響,
Redis擁有主從復制架構,兩個節點組成主從架構,從可以實時同步主的資料,提高整個Redis服務的可用性,
同時Redis還提供了哨兵節點,在主節點宕機時,主動把從節點提升為主節點,繼續提供服務,Redis哨兵如何與Spring Boot集成等系列教程可以關注公眾號Java技術堆疊搜索閱讀,
主從兩個節點還可以提供讀寫分離功能,進一步提高程式訪問的性能,
集群化
Memcached和Redis都是由多個節點組成集群對外提供服務,但他們的機制也有所不同,
Memcached的集群化是在客戶端采用一致性哈希演算法向指定節點發送資料,當一個節點宕機時,其他節點會分擔這個節點的請求,
而Redis集群化采用的是每個節點維護一部分虛擬槽位,通過key的哈希計算,將key映射到具體的虛擬槽位上,這個槽位再映射到具體的Redis節點,
同時每個Redis節點都包含至少一個從節點,組成主從架構,進一步提高每個節點的高可用能力,
當增加或下線節點時,需要手動觸發資料遷移,重新進行哈希槽位映射,
Redis官方的集群化解決方案為Redis cluster,它采用無中心化的設計,另外也有第三方的采用中心化設計proxy方式的集群化解決方案,例如Codis、Twemproxy,
總結
從以上幾個方面進行對比分析,總結如下表,
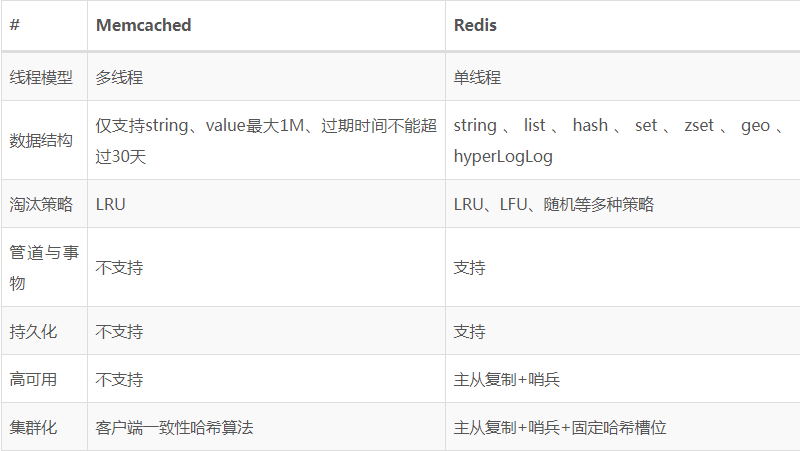
整體來說,Redis提供了非常豐富的功能,而且性能基本上與Memcached相差無幾,這也是它最近這幾年占領記憶體資料庫鰲頭的原因,
如果你的業務需要各種資料結構給予支撐,同時要求資料的高可用保障,那么選擇Redis是比較合適的,
如果你的業務非常簡單,只是簡單的set/get,并且對于記憶體使用并不高,那么使用簡單的Memcached足夠,
如果此文章能給您帶來小小的作業效率提升,不妨在看、轉發一下,以鼓勵我寫出更好的文章!
近期熱文推薦:
1.免費獲取 IntelliJ IDEA 激活碼的 6 種方式!
2.我用 Java 8 寫了一段邏輯,同事直呼看不懂,你試試看,,
3.吊打 Tomcat ,Undertow 性能很炸!!
4.國人開源了一款超好用的 Redis 客戶端,真香!!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/5951.html
標籤:Java