目錄
- 指標概念
- 一切都是地址
- 指標變數
- 定義指標變數
- 通過指標變數取得資料
- 關于 * 和 & 的謎題
- 對星號*的總結
- 指標變數的運算
- 陣列指標
- 1) 使用下標
- 2) 使用指標
- 關于陣列指標的謎題
- 字串指標
- 指標作為函式引數
- 用陣列作函式引數
- 指標作為回傳值
- 二級指標
- 指標陣列
- 指標與二維陣列
- 指標陣列和二維陣列指標的區別
- 函式指標
- 總結
這里對 C 語言的指標進行比較詳細的整理總結,參考網路上部分資料整理如下,
指標概念
計算機中所有的資料都必須放在記憶體中,不同型別的資料占用的位元組數不一樣,例如 int 占用4個位元組,char 占用1個位元組,為了正確地訪問這些資料,必須為每個位元組都編上號碼,就像門牌號、身份證號一樣,每個位元組的編號是唯一的,根據編號可以準確地找到某個位元組,
我們將記憶體中位元組的編號稱為地址(Address)或指標(Pointer),地址從 0 開始依次增加,對于 32 位環境,程式能夠使用的記憶體為 4GB,最小的地址為 0,最大的地址為 0XFFFFFFFF,
輸出一個地址:
int a = 100;
char str[20] = "tanweime.com";
printf("%#X, %p\n", &a, str);
---
運行結果:
0XE42523AC, 0XE4252390
%#X 和 %p 表示以十六進制形式輸出,并附帶前綴0X,a 是一個變數,用來存放整數,需要在前面加&來獲得它的地址;str 本身就表示字串的首地址,不需要加&,
C語言中有一個控制符
%p,專門用來以十六進制形式輸出地址,不過 %p 的輸出格式并不統一,有的編譯器帶0x前綴,有的不帶
一切都是地址
C語言用變數來存盤資料,用函式來定義一段可以重復使用的代碼,它們最終都要放到記憶體中才能供 CPU 使用,
資料和代碼都以二進制的形式存盤在記憶體中,計算機無法從格式上區分某塊記憶體到底存盤的是資料還是代碼,當程式被加載到記憶體后,作業系統會給不同的記憶體塊指定不同的權限,擁有讀取和執行權限的記憶體塊就是代碼,而擁有讀取和寫入權限(也可能只有讀取權限)的記憶體塊就是資料,
CPU 只能通過地址來取得記憶體中的代碼和資料,程式在執行程序中會告知 CPU 要執行的代碼以及要讀寫的資料的地址,如果程式不小心出錯,或者開發者有意為之,在 CPU 要寫入資料時給它一個代碼區域的地址,就會發生記憶體訪問錯誤,這種記憶體訪問錯誤會被硬體和作業系統攔截,強制程式崩潰,程式員沒有挽救的機會,
CPU 訪問記憶體時需要的是地址,而不是變數名和函式名!變數名和函式名只是地址的一種助記符,當源檔案被編譯和鏈接成可執行程式后,它們都會被替換成地址,編譯和鏈接程序的一項重要任務就是找到這些名稱所對應的地址,
指標變數
資料在記憶體中的地址也稱為指標,如果一個變數存盤了一份資料的指標,我們就稱它為指標變數,
在C語言中,允許用一個變數來存放指標,這種變數稱為指標變數,指標變數的值就是某份資料的地址,這樣的一份資料可以是陣列、字串、函式,也可以是另外的一個普通變數或指標變數,
現在假設有一個 char 型別的變數 c,它存盤了字符 'K'(ASCII碼為十進制數 75),并占用了地址為 0X11A 的記憶體(地址通常用十六進制表示),另外有一個指標變數 p,它的值為 0X11A,正好等于變數 c 的地址,這種情況我們就稱 p 指向了 c,或者說 p 是指向變數 c 的指標,
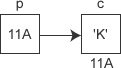
定義指標變數
定義指標變數與定義普通變數非常類似,不過要在變數名前面加星號*,格式為:
datatype *name;
或者
datatype *name = value;
*表示這是一個指標變數,datatype表示該指標變數所指向的資料的型別 ,例如:
int *p1;
p1 是一個指向 int 型別資料的指標變數,至于 p1 究竟指向哪一份資料,應該由賦予它的值決定,再如:
int a = 100;int *p_a = &a;
在定義指標變數 p_a 的同時對它進行初始化,并將變數 a 的地址賦予它,此時 p_a 就指向了 a,值得注意的是,p_a 需要的一個地址,a 前面必須要加取地址符&,否則是不對的,
和普通變數一樣,指標變數也可以被多次寫入,只要你想,隨時都能夠改變指標變數的值,請看下面的代碼:
//定義普通變數
float a = 99.5, b = 10.6;char c = '@', d = '#';
//定義指標變數
float *p1 = &a;char *p2 = &c;
//修改指標變數的值
p1 = &b;p2 = &d;
*是一個特殊符號,表明一個變數是指標變數,定義 p1、p2 時必須帶*,而給 p1、p2 賦值時,因為已經知道了它是一個指標變數,就沒必要多此一舉再帶上*,后邊可以像使用普通變數一樣來使用指標變數,也就是說,定義指標變數時必須帶*,給指標變數賦值時不能帶*,
指標變數也可以連續定義,例如:
int *a, *b, *c; //a、b、c 的型別都是 int*
注意每個變數前面都要帶*,如果寫成下面的形式,那么只有 a 是指標變數,b、c 都是型別為 int 的普通變數:
int *a, b, c;
通過指標變數取得資料
指標變數存盤了資料的地址,通過指標變數能夠獲得該地址上的資料,格式為:
*pointer;
這里的*稱為指標運算子,用來取得某個地址上的資料,請看下面的例子:
#include <stdio.h>
int main(){
int a = 15;
int *p = &a;
printf("%d, %d\n", a, *p); //兩種方式都可以輸出a的值
return 0;}
運行結果:
15, 15
假設 a 的地址是 0X1000,p 指向 a 后,p 本身的值也會變為 0X1000,p 表示獲取地址 0X1000 上的資料,也即變數 a 的值,從運行結果看,p 和 a 是等價的,
上節我們說過,CPU 讀寫資料必須要知道資料在記憶體中的地址,普通變數和指標變數都是地址的助記符,雖然通過 *p 和 a 獲取到的資料一樣,但它們的運行程序稍有不同:a 只需要一次運算就能夠取得資料,而 *p 要經過兩次運算,多了一層“間接”,
假設變數 a、p 的地址分別為 0X1000、0XF0A0,它們的指向關系如下圖所示:
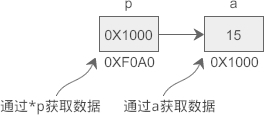
程式被編譯和鏈接后,a、p 被替換成相應的地址,使用 *p 的話,要先通過地址 0XF0A0 取得變數 p 本身的值,這個值是變數 a 的地址,然后再通過這個值取得變數 a 的資料,前后共有兩次運算;而使用 a 的話,可以通過地址 0X1000 直接取得它的資料,只需要一步運算,
也就是說,使用指標是間接獲取資料,使用變數名是直接獲取資料,前者比后者的代價要高,
指標除了可以獲取記憶體上的資料,也可以修改記憶體上的資料,例如:
int a = 15, b = 99, c = 222;
int *p = &a; //定義指標變數
*p = b; //通過指標變數修改記憶體上的資料
c = *p; //通過指標變數獲取記憶體上的資料
printf("%d, %d, %d, %d\n", a, b, c, *p);
運行結果:
99, 99, 99, 99
*p 代表的是 a 中的資料,它等價于 a,可以將另外的一份資料賦值給它,也可以將它賦值給另外的一個變數,
*在不同的場景下有不同的作用:*可以用在指標變數的定義中,表明這是一個指標變數,以和普通變數區分開;使用指標變數時在前面加*表示獲取指標指向的資料,或者說表示的是指標指向的資料本身,
也就是說,定義指標變數時的*和使用指標變數時的*意義完全不同,以下面的陳述句為例:
int *p = &a;*p = 100;
第1行代碼中*用來指明 p 是一個指標變數,第2行代碼中*用來獲取指標指向的資料,
需要注意的是,給指標變數本身賦值時不能加*,修改上面的陳述句:
int *p;p = &a;*p = 100;
第2行代碼中的 p 前面就不能加*,
指標變數也可以出現在普通變數能出現的任何運算式中,例如:
int x, y, *px = &x, *py = &y;
y = *px + 5; //表示把x的內容加5并賦給y,*px+5相當于(*px)+5
y = ++*px; //px的內容加上1之后賦給y,++*px相當于++(*px)
y = *px++; //相當于y=(*px)++
py = px; //把一個指標的值賦給另一個指標
關于 * 和 & 的謎題
假設有一個 int 型別的變數 a,pa 是指向它的指標,那么*&a和&*pa分別是什么意思呢?
*&a可以理解為*(&a),&a表示取變數 a 的地址(等價于 pa),*(&a)表示取這個地址上的資料(等價于 *pa),繞來繞去,又回到了原點,*&a仍然等價于 a,
&*pa可以理解為&(*pa),*pa表示取得 pa 指向的資料(等價于 a),&(*pa)表示資料的地址(等價于 &a),所以&*pa等價于 pa,
對星號*的總結
在我們目前所學到的語法中,星號*主要有三種用途:
- 表示乘法,例如
int a = 3, b = 5, c; c = a * b;,這是最容易理解的, - 表示定義一個指標變數,以和普通變數區分開,例如
int a = 100; int *p = &a;, - 表示獲取指標指向的資料,是一種間接操作,例如
int a, b, *p = &a; *p = 100; b = *p;,
指標變數的運算
指標變數保存的是地址,本質上是一個整數,可以進行部分運算,例如加法、減法、比較等,請看下面的代碼:
#include <stdio.h>
int main(){
int a = 10, *pa = &a, *paa = &a;
double b = 99.9, *pb = &b;
char c = '@', *pc = &c;
//最初的值
printf("&a=%#X, &b=%#X, &c=%#X\n", &a, &b, &c);
printf("pa=%#X, pb=%#X, pc=%#X\n", pa, pb, pc);
//加法運算
pa++; pb++; pc++;
printf("pa=%#X, pb=%#X, pc=%#X\n", pa, pb, pc);
//減法運算
pa -= 2; pb -= 2; pc -= 2;
printf("pa=%#X, pb=%#X, pc=%#X\n", pa, pb, pc);
//比較運算
if(pa == paa){
printf("%d\n", *paa);
}else{
printf("%d\n", *pa);
}
return 0;
}
--------
運行結果:
&a=0X28FF44, &b=0X28FF30, &c=0X28FF2B
pa=0X28FF44, pb=0X28FF30, pc=0X28FF2B
pa=0X28FF48, pb=0X28FF38, pc=0X28FF2C
pa=0X28FF40, pb=0X28FF28, pc=0X28FF2A
2686784
從運算結果可以看出:pa、pb、pc 每次加 1,它們的地址分別增加 4、8、1,正好是 int、double、char 型別的長度;減 2 時,地址分別減少 8、16、2,正好是 int、double、char 型別長度的 2 倍,
我們知道,陣列中的所有元素在記憶體中是連續排列的,如果一個指標指向了陣列中的某個元素,那么加 1 就表示指向下一個元素,減 1 就表示指向上一個元素,這樣指標的加減運算就具有了現實的意義,
陣列指標
陣列(Array)是一系列具有相同型別的資料的集合,每一份資料叫做一個陣列元素(Element),陣列中的所有元素在記憶體中是連續排列的,整個陣列占用的是一塊記憶體,以int arr[] = { 99, 15, 100, 888, 252 };為例,該陣列在記憶體中的分布如下圖所示:

定義陣列時,要給出陣列名和陣列長度,陣列名可以認為是一個指標,它指向陣列的第 0 個元素,在C語言中,我們將第 0 個元素的地址稱為陣列的首地址,以上面的陣列為例,下圖是 arr 的指向:

#include <stdio.h>
int main(){
int arr[] = { 99, 15, 100, 888, 252 };
int len = sizeof(arr) / sizeof(int); //求陣列長度
int i;
for(i=0; i<len; i++){
printf("%d ", *(arr+i) ); //*(arr+i)等價于arr[i]
}
printf("\n");
return 0;
}
----
運行結果:
99 15 100 888 252
第 5 行代碼用來求陣列的長度,sizeof(arr) 會獲得整個陣列所占用的位元組數,sizeof(int) 會獲得一個陣列元素所占用的位元組數,它們相除的結果就是陣列包含的元素個數,也即陣列長度,
第 8 行代碼中我們使用了*(arr+i)這個運算式,arr 是陣列名,指向陣列的第 0 個元素,表示陣列首地址, arr+i 指向陣列的第 i 個元素,*(arr+i) 表示取第 i 個元素的資料,它等價于 arr[i],
arr 是
int*型別的指標,每次加 1 時它自身的值會增加 sizeof(int),加 i 時自身的值會增加 sizeof(int) * i
我們也可以定義一個指向陣列的指標,例如:
int arr[] = { 99, 15, 100, 888, 252 };int *p = arr;
arr 本身就是一個指標,可以直接賦值給指標變數 p,arr 是陣列第 0 個元素的地址,所以int *p = arr;也可以寫作int *p = &arr[0];,也就是說,arr、p、&arr[0] 這三種寫法都是等價的,它們都指向陣列第 0 個元素,或者說指向陣列的開頭,
如果一個指標指向了陣列,我們就稱它為陣列指標(Array Pointer),
陣列指標指向的是陣列中的一個具體元素,而不是整個陣列,所以陣列指標的型別和陣列元素的型別有關,上面的例子中,p 指向的陣列元素是 int 型別,所以 p 的型別必須也是int *,
反過來想,p 并不知道它指向的是一個陣列,p 只知道它指向的是一個整數,究竟如何使用 p 取決于程式員的編碼,
更改上面的代碼,使用陣列指標來遍歷陣列元素:
#include <stdio.h>
int main(){
int arr[] = { 99, 15, 100, 888, 252 };
int i, *p = arr, len = sizeof(arr) / sizeof(int);
for(i=0; i<len; i++){
printf("%d ", *(p+i) );
}
printf("\n");
return 0;
}
引入陣列指標后,我們就有兩種方案來訪問陣列元素了,一種是使用下標,另外一種是使用指標,
1) 使用下標
也就是采用 arr[i] 的形式訪問陣列元素,如果 p 是指向陣列 arr 的指標,那么也可以使用 p[i] 來訪問陣列元素,它等價于 arr[i],
2) 使用指標
也就是使用 *(p+i) 的形式訪問陣列元素,另外陣列名本身也是指標,也可以使用 *(arr+i) 來訪問陣列元素,它等價于 *(p+i),
關于陣列指標的謎題
假設 p 是指向陣列 arr 中第 n 個元素的指標,那么 p++、++p、(*p)++ 分別是什么意思呢?
*p++ 等價于 *(p++),表示先取得第 n 個元素的值,再將 p 指向下一個元素,上面已經進行了詳細講解,
*++p 等價于 *(++p),會先進行 ++p 運算,使得 p 的值增加,指向下一個元素,整體上相當于 *(p+1),所以會獲得第 n+1 個陣列元素的值,
(*p)++ 就非常簡單了,會先取得第 n 個元素的值,再對該元素的值加 1,假設 p 指向第 0 個元素,并且第 0 個元素的值為 99,執行完該陳述句后,第 0 個元素的值就會變為 100,
字串指標
C語言中沒有特定的字串型別,我們通常是將字串放在一個字符陣列中:
#include <stdio.h>
#include <string.h>
int main(){
char str[] = "tanweime";
int len = strlen(str), i;
//直接輸出字串
printf("%s\n", str);
//每次輸出一個字符
for(i=0; i<len; i++){
printf("%c", str[i]);
}
printf("\n");
return 0;
}
除了字符陣列,C語言還支持另外一種表示字串的方法,就是直接使用一個指標指向字串,例如:
char *str = "tanweime";
或者:
char *str;str = "tanweime";
字串中的所有字符在記憶體中是連續排列的,str 指向的是字串的第 0 個字符;我們通常將第 0 個字符的地址稱為字串的首地址,字串中每個字符的型別都是char,所以 str 的型別也必須是char *,
下面的例子演示了如何輸出這種字串:
#include <stdio.h>
#include <string.h>
int main(){
char *str = "tanweime";
int len = strlen(str), i;
//直接輸出字串
printf("%s\n", str);
//使用*(str+i)
for(i=0; i<len; i++){
printf("%c", *(str+i));
}
printf("\n");
//使用str[i]
for(i=0; i<len; i++){
printf("%c", str[i]);
}
printf("\n");
return 0;
}
這一切看起來和字符陣列是多么地相似,它們都可以使用%s輸出整個字串,都可以使用*或[ ]獲取單個字符,這兩種表示字串的方式是不是就沒有區別了呢?
有!它們最根本的區別是在記憶體中的存盤區域不一樣,字符陣列存盤在全域資料區或堆疊區,第二種形式的字串存盤在常量區,全域資料區和堆疊區的字串(也包括其他資料)有讀取和寫入的權限,而常量區的字串(也包括其他資料)只有讀取權限,沒有寫入權限,
記憶體權限的不同導致的一個明顯結果就是,字符陣列在定義后可以讀取和修改每個字符,而對于第二種形式的字串,一旦被定義后就只能讀取不能修改,任何對它的賦值都是錯誤的,
我們將第二種形式的字串稱為字串常量,意思很明顯,常量只能讀取不能寫入,
指標作為函式引數
在C語言中,函式的引數不僅可以是整數、小數、字符等具體的資料,還可以是指向它們的指標,用指標變數作函式引數可以將函式外部的地址傳遞到函式內部,使得在函式內部可以操作函式外部的資料,并且這些資料不會隨著函式的結束而被銷毀,
像陣列、字串、動態分配的記憶體等都是一系列資料的集合,沒有辦法通過一個引數全部傳入函式內部,只能傳遞它們的指標,在函式內部通過指標來影響這些資料集合,
有的時候,對于整數、小數、字符等基本型別資料的操作也必須要借助指標,一個典型的例子就是交換兩個變數的值,
#include <stdio.h>
void swap(int *p1, int *p2){
int temp; //臨時變數
temp = *p1;
*p1 = *p2;
*p2 = temp;
}
int main(){
int a = 66, b = 99;
swap(&a, &b);
printf("a = %d, b = %d\n", a, b);
return 0;
}
呼叫 swap() 函式時,將變數 a、b 的地址分別賦值給 p1、p2,這樣 p1、p2 代表的就是變數 a、b 本身,交換 p1、p2 的值也就是交換 a、b 的值,函式運行結束后雖然會將 p1、p2 銷毀,但它對外部 a、b 造成的影響是“持久化”的,不會隨著函式的結束而“恢復原樣”,
需要注意的是臨時變數 temp,它的作用特別重要,因為執行*p1 = *p2;陳述句后 a 的值會被 b 的值覆寫,如果不先將 a 的值保存起來以后就找不到了,
這就好比拿來一瓶可樂和一瓶雪碧,要想把可樂倒進雪碧瓶、把雪碧倒進可樂瓶里面,就必須先找一個杯子,將兩者之一先倒進杯子里面,再從杯子倒進瓶子里面,這里的杯子,就是一個“臨時變數”,雖然只是倒倒手,但是也不可或缺,
用陣列作函式引數
陣列是一系列資料的集合,無法通過引數將它們一次性傳遞到函式內部,如果希望在函式內部操作陣列,必須傳遞陣列指標,下面的例子定義了一個函式 max(),用來查找陣列中值最大的元素:
#include <stdio.h>
int max(int *intArr, int len){
int i, maxValue = https://www.cnblogs.com/veeupup/p/intArr[0]; //假設第0個元素是最大值
for(i=1; i引數 intArr 僅僅是一個陣列指標,在函式內部無法通過這個指標獲得陣列長度,必須將陣列長度作為函式引數傳遞到函式內部,陣列 nums 的每個元素都是整數,scanf() 在讀取用戶輸入的整數時,要求給出存盤它的記憶體的地址,nums+i就是第 i 個陣列元素的地址,
用陣列做函式引數時,引數也能夠以“真正”的陣列形式給出,例如對于上面的 max() 函式,它的引數可以寫成下面的形式:
int max(int intArr[], int len){
int i, maxValue = https://www.cnblogs.com/veeupup/p/intArr[0]; //假設第0個元素是最大值
for(i=1; iint intArr[]雖然定義了一個陣列,但沒有指定陣列長度,好像可以接受任意長度的陣列,
實際上這兩種形式的陣列定義都是假象,不管是int intArr[6]還是int intArr[]都不會創建一個陣列出來,編譯器也不會為它們分配記憶體,實際的陣列是不存在的,它們最侄訓是會轉換為int *intArr這樣的指標,這就意味著,兩種形式都不能將陣列的所有元素“一股腦”傳遞進來,大家還得規規矩矩使用陣列指標,
int intArr[6]這種形式只能說明函式期望用戶傳遞的陣列有 6 個元素,并不意味著陣列只能有 6 個元素,真正傳遞的陣列可以有少于或多于 6 個的元素,
需要強調的是,不管使用哪種方式傳遞陣列,都不能在函式內部求得陣列長度,因為 intArr 僅僅是一個指標,而不是真正的陣列,所以必須要額外增加一個引數來傳遞陣列長度,
C語言為什么不允許直接傳遞陣列的所有元素,而必須傳遞陣列指標呢?
引數的傳遞本質上是一次賦值的程序,賦值就是對記憶體進行拷貝,所謂記憶體拷貝,是指將一塊記憶體上的資料復制到另一塊記憶體上,
對于像 int、float、char 等基本型別的資料,它們占用的記憶體往往只有幾個位元組,對它們進行記憶體拷貝非常快速,而陣列是一系列資料的集合,資料的數量沒有限制,可能很少,也可能成千上萬,對它們進行記憶體拷貝有可能是一個漫長的程序,會嚴重拖慢程式的效率,為了防止技藝不佳的程式員寫出低效的代碼,C語言沒有從語法上支持資料集合的直接賦值,
除了C語言,C++、Java、Python 等其它語言也禁止對大塊記憶體進行拷貝,在底層都使用類似指標的方式來實作,
指標作為回傳值
C語言允許函式的回傳值是一個指標(地址),我們將這樣的函式稱為指標函式,下面的例子定義了一個函式 strlong(),用來回傳兩個字串中較長的一個
#include <stdio.h>
#include <string.h>
char *strlong(char *str1, char *str2){
if(strlen(str1) >= strlen(str2)){
return str1;
}else{
return str2;
}
}
int main(){
char str1[30], str2[30], *str;
gets(str1);
gets(str2);
str = strlong(str1, str2);
printf("Longer string: %s\n", str);
return 0;
}
用指標作為函式回傳值時需要注意的一點是,函式運行結束后會銷毀在它內部定義的所有區域資料,包括區域變數、區域陣列和形式引數,函式回傳的指標請盡量不要指向這些資料,C語言沒有任何機制來保證這些資料會一直有效,它們在后續使用程序中可能會引發運行時錯誤,請看下面的例子:
#include <stdio.h>
int *func(){
int n = 100;
return &n;
}
int main(){
int *p = func(), n;
n = *p;
printf("value = https://www.cnblogs.com/veeupup/p/%d/n", n);
return 0;
}
前面我們說函式運行結束后會銷毀所有的區域資料,這個觀點并沒錯,大部分C語言教材也都強調了這一點,但是,這里所謂的銷毀并不是將區域資料所占用的記憶體全部抹掉,而是程式放棄對它的使用權限,棄之不理,后面的代碼可以隨意使用這塊記憶體,對于上面的兩個例子,func() 運行結束后 n 的記憶體依然保持原樣,值還是 100,如果使用及時也能夠得到正確的資料,如果有其它函式被呼叫就會覆寫這塊記憶體,得到的資料就失去了意義,
二級指標
指標可以指向一份普通型別的資料,例如 int、double、char 等,也可以指向一份指標型別的資料,例如 int *、double *、char * 等,
如果一個指標指向的是另外一個指標,我們就稱它為二級指標,或者指向指標的指標,
假設有一個 int 型別的變數 a,p1是指向 a 的指標變數,p2 又是指向 p1 的指標變數,它們的關系如下圖所示:

將這種關系轉換為C語言代碼:
int a =100;
int *p1 = &a;
int **p2 = &p1;
指標變數也是一種變數,也會占用存盤空間,也可以使用&獲取它的地址,C語言不限制指標的級數,每增加一級指標,在定義指標變數時就得增加一個星號*,p1 是一級指標,指向普通型別的資料,定義時有一個*;p2 是二級指標,指向一級指標 p1,定義時有兩個*,
如果我們希望再定義一個三級指標 p3,讓它指向 p2,那么可以這樣寫:
int ***p3 = &p2;
四級指標也是類似的道理:
int ****p4 = &p3;
實際開發中會經常使用一級指標和二級指標,幾乎用不到高級指標,
想要獲取指標指向的資料時,一級指標加一個*,二級指標加兩個*,三級指標加三個*,以此類推,請看代碼:
#include <stdio.h>
int main(){
int a =100;
int *p1 = &a;
int **p2 = &p1;
int ***p3 = &p2;
printf("%d, %d, %d, %d\n", a, *p1, **p2, ***p3);
printf("&p2 = %#X, p3 = %#X\n", &p2, p3);
printf("&p1 = %#X, p2 = %#X, *p3 = %#X\n", &p1, p2, *p3);
printf(" &a = %#X, p1 = %#X, *p2 = %#X, **p3 = %#X\n", &a, p1, *p2, **p3);
return 0;
}
------
100, 100, 100, 100
&p2 = 0XE19322F8, p3 = 0XE19322F8
&p1 = 0XE1932300, p2 = 0XE1932300, *p3 = 0XE1932300
&twa = 0XE193230C, p1 = 0XE193230C, *p2 = 0XE193230C, **p3 = 0XE193230C
以三級指標 p3 為例來分析上面的代碼,***p3等價于*(*(*p3)),p3 得到的是 p2 的值,也即 p1 的地址;(p3) 得到的是 p1 的值,也即 a 的地址;經過三次“取值”操作后,((p3)) 得到的才是 a 的值,
假設 a、p1、p2、p3 的地址分別是 0X00A0、0X1000、0X2000、0X3000,它們之間的關系可以用下圖來描述:

方框里面是變數本身的值,方框下面是變數的地址,
指標陣列
如果一個陣列中的所有元素保存的都是指標,那么我們就稱它為指標陣列,指標陣列的定義形式一般為:
dataType *arrayName[length];
[ ]的優先級高于*,該定義形式應該理解為:
dataType *(arrayName[length]);
括號里面說明arrayName是一個陣列,包含了length個元素,括號外面說明每個元素的型別為dataType *,
除了每個元素的資料型別不同,指標陣列和普通陣列在其他方面都是一樣的,下面是一個簡單的例子:
#include <stdio.h>
int main(){
int a = 16, b = 932, c = 100;
//定義一個指標陣列
int *arr[3] = {&a, &b, &c};//也可以不指定長度,直接寫作 int *parr[]
//定義一個指向指標陣列的指標
int **parr = arr;
printf("%d, %d, %d\n", *arr[0], *arr[1], *arr[2]);
printf("%d, %d, %d\n", **(parr+0), **(parr+1), **(parr+2));
return 0;
}
------
運行結果:
16, 932, 100
16, 932, 100
指標陣列還可以和字串陣列結合使用,請看下面的例子:
#include <stdio.h>
int main(){
char *str[3] = {
"tanwei",
"譚巍",
"C Language"
};
printf("%s\n%s\n%s\n", str[0], str[1], str[2]);
return 0;
}
需要注意的是,字符陣列 str 中存放的是字串的首地址,不是字串本身,字串本身位于其他的記憶體區域,和字符陣列是分開的,
也只有當指標陣列中每個元素的型別都是char *時,才能像上面那樣給指標陣列賦值,其他型別不行,
為了便于理解,可以將上面的字串陣列改成下面的形式,它們都是等價的,
#include <stdio.h>
int main(){
char *str0 = "tanwei";
char *str1 = "譚巍";
char *str2 = "C Language";
char *str[3] = {str0, str1, str2};
printf("%s\n%s\n%s\n", str[0], str[1], str[2]);
return 0;
}
指標與二維陣列
二維陣列在概念上是二維的,有行和列,但在記憶體中所有的陣列元素都是連續排列的,它們之間沒有“縫隙”,以下面的二維陣列 a 為例:
int a[3][4] = { {0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9, 10, 11} };
從概念上理解,a 的分布像一個矩陣:
0 1 2 3
4 5 6 7
8 9 10 11
但在記憶體中,a 的分布是一維線性的,整個陣列占用一塊連續的記憶體:

C語言中的二維陣列是按行排列的,也就是先存放 a[0] 行,再存放 a[1] 行,最后存放 a[2] 行;每行中的 4 個元素也是依次存放,陣列 a 為 int 型別,每個元素占用 4 個位元組,整個陣列共占用 4×(3×4) = 48 個位元組,
C語言允許把一個二維陣列分解成多個一維陣列來處理,對于陣列 a,它可以分解成三個一維陣列,即 a[0]、a[1]、a[2],每一個一維陣列又包含了 4 個元素,例如 a[0] 包含 a[0][0]、a[0][1]、a[0][2]、a[0][3],
假設陣列 a 中第 0 個元素的地址為 1000,那么每個一維陣列的首地址如下圖所示:
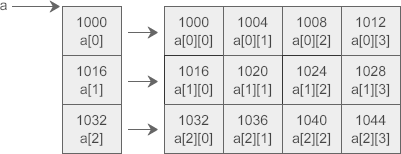
為了更好的理解指標和二維陣列的關系,我們先來定義一個指向 a 的指標變數 p:
int (*p)[4] = a;
括號中的*表明 p 是一個指標,它指向一個陣列,陣列的型別為int [4],這正是 a 所包含的每個一維陣列的型別,
[ ]的優先級高于*,( )是必須要加的,如果赤裸裸地寫作int *p[4],那么應該理解為int *(p[4]),p 就成了一個指標陣列,而不是二維陣列指標,
對指標進行加法(減法)運算時,它前進(后退)的步長與它指向的資料型別有關,p 指向的資料型別是int [4],那么p+1就前進 4×4 = 16 個位元組,p-1就后退 16 個位元組,這正好是陣列 a 所包含的每個一維陣列的長度,也就是說,p+1會使得指標指向二維陣列的下一行,p-1會使得指標指向陣列的上一行,
陣列名 a 在運算式中也會被轉換為和 p 等價的指標!
下面我們就來探索一下如何使用指標 p 來訪問二維陣列中的每個元素,按照上面的定義:
-
p指向陣列 a 的開頭,也即第 0 行;p+1前進一行,指向第 1 行, -
*(p+1)表示取地址上的資料,也就是整個第 1 行資料,注意是一行資料,是多個資料,不是第 1 行中的第 0 個元素,下面的運行結果有力地證明了這一點:
#include <stdio.h>
int main(){
int a[3][4] = { {0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9, 10, 11} };
int (*p)[4] = a;
printf("%d\n", sizeof(*(p+1)));
return 0;
}
---
16
*(p+1)+1表示第 1 行第 1 個元素的地址,如何理解呢?
*(p+1)單獨使用時表示的是第 1 行資料,放在運算式中會被轉換為第 1 行資料的首地址,也就是第 1 行第 0 個元素的地址,因為使用整行資料沒有實際的含義,編譯器遇到這種情況都會轉換為指向該行第 0 個元素的指標;就像一維陣列的名字,在定義時或者和 sizeof、& 一起使用時才表示整個陣列,出現在運算式中就會被轉換為指向陣列第 0 個元素的指標,
*(*(p+1)+1)表示第 1 行第 1 個元素的值,很明顯,增加一個 * 表示取地址上的資料,
根據上面的結論,可以很容易推出以下的等價關系:
a+i == p+i
a[i] == p[i] == *(a+i) == *(p+i)
a[i][j] == p[i][j] == *(a[i]+j) == *(p[i]+j) == *(*(a+i)+j) == *(*(p+i)+j)
#include <stdio.h>
int main(){
int a[3][4]={0,1,2,3,4,5,6,7,8,9,10,11};
int(*p)[4];
int i,j;
p=a;
for(i=0; i<3; i++){
for(j=0; j<4; j++) printf("%2d ",*(*(p+i)+j));
printf("\n");
}
return 0;
}
指標陣列和二維陣列指標的區別
指標陣列和二維陣列指標在定義時非常相似,只是括號的位置不同:
int *(p1[5]); //指標陣列,可以去掉括號直接寫作 int *p1[5];int (*p2)[5]; //二維陣列指標,不能去掉括號
指標陣列和二維陣列指標有著本質上的區別:指標陣列是一個陣列,只是每個元素保存的都是指標,以上面的 p1 為例,在32位環境下它占用 4×5 = 20 個位元組的記憶體,二維陣列指標是一個指標,它指向一個二維陣列,以上面的 p2 為例,它占用 4 個位元組的記憶體,
函式指標
一個函式總是占用一段連續的記憶體區域,函式名在運算式中有時也會被轉換為該函式所在記憶體區域的首地址,這和陣列名非常類似,我們可以把函式的這個首地址(或稱入口地址)賦予一個指標變數,使指標變數指向函式所在的記憶體區域,然后通過指標變數就可以找到并呼叫該函式,這種指標就是函式指標,
函式指標的定義形式為:
returnType (*pointerName)(param list);
returnType 為函式回傳值型別,pointerNmae 為指標名稱,param list 為函式引數串列,引數串列中可以同時給出引數的型別和名稱,也可以只給出引數的型別,省略引數的名稱,這一點和函式原型非常類似,
注意( )的優先級高于*,第一個括號不能省略,如果寫作returnType *pointerName(param list);就成了函式原型,它表明函式的回傳值型別為returnType *,
#include <stdio.h>
//回傳兩個數中較大的一個
int max(int a, int b){
return a>b ? a : b;
}
int main(){
int x, y, maxval;
//定義函式指標
int (*pmax)(int, int) = max; //也可以寫作int (*pmax)(int a, int b)
printf("Input two numbers:");
scanf("%d %d", &x, &y);
maxval = (*pmax)(x, y);
printf("Max value: %d\n", maxval);
return 0;
}
總結
指標(Pointer)就是記憶體的地址,C語言允許用一個變數來存放指標,這種變數稱為指標變數,指標變數可以存放基本型別資料的地址,也可以存放陣列、函式以及其他指標變數的地址,
程式在運行程序中需要的是資料和指令的地址,變數名、函式名、字串名和陣列名在本質上是一樣的,它們都是地址的助記符:在撰寫代碼的程序中,我們認為變數名表示的是資料本身,而函式名、字串名和陣列名表示的是代碼塊或資料塊的首地址;程式被編譯和鏈接后,這些名字都會消失,取而代之的是它們對應的地址,
| 定 義 | 含 義 |
|---|---|
| int *p; | p 可以指向 int 型別的資料,也可以指向類似 int arr[n] 的陣列, |
| int **p; | p 為二級指標,指向 int * 型別的資料, |
| int *p[n]; | p 為指標陣列,[ ] 的優先級高于 *,所以應該理解為 int *(p[n]); |
| int (*p)[n]; | p 為二維陣列指標, |
| int *p(); | p 是一個函式,它的回傳值型別為 int *, |
| int (*p)(); | p 是一個函式指標,指向原型為 int func() 的函式, |
-
指標變數可以進行加減運算,例如
p++、p+i、p-=i,指標變數的加減運算并不是簡單的加上或減去一個整數,而是跟指標指向的資料型別有關, -
給指標變數賦值時,要將一份資料的地址賦給它,不能直接賦給一個整數,例如
int *p = 1000;是沒有意義的,使用程序中一般會導致程式崩潰, -
使用指標變數之前一定要初始化,否則就不能確定指標指向哪里,如果它指向的記憶體沒有使用權限,程式就崩潰了,對于暫時沒有指向的指標,建議賦值
NULL, -
兩個指標變數可以相減,如果兩個指標變數指向同一個陣列中的某個元素,那么相減的結果就是兩個指標之間相差的元素個數,
-
陣列也是有型別的,陣列名的本意是表示一組型別相同的資料,在定義陣列時,或者和 sizeof、& 運算子一起使用時陣列名才表示整個陣列,運算式中的陣列名會被轉換為一個指向陣列的指標,
歡迎訪問我的博客和github!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/59735.html
標籤:C++
上一篇:C++中的多型及虛函式大總結
下一篇:C++常用函式