快速排序:二十世紀十大演算法之一 !
快速排序的基本實作
快速排序是一種基于交換的高效排序演算法,它采用了分治法的思想,步驟如下:
- 從數列中選出一個數作為基準數(樞軸,Pivot)
- 將陣列進行劃分(Partition),將比基準數大的元素移至樞軸右側,將比基準數小的元素移至樞軸左側,
- 對左右兩區間分別進行第二步的劃分操作,知道每個子區間只有一個元素,
快排最重要的步驟就是劃分了(Partition),劃分的程序用通俗的語言講就是“挖坑”和“填坑”,
圖片較小,請原諒
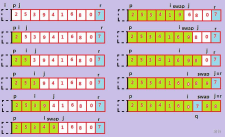
代碼:
int partition(int arr[], int left, int right) //找基準數進行劃分
{
int low = left + 1; //區間下端
int high = right; //區間上端
int pivot = left; //樞軸下標
int cur = pivot+1; //存盤位置下標
for(int i=low; i<=high; i++) //從下端到上端的遍歷
{
if(arr[i] < arr[pivot])
{
swap(arr[i], arr[cur]); //交換現在的值和存盤位置的值
cur++; //將存盤位置變為下一位
}
}
swap(arr[pivot], arr[cur-1]); //將樞軸移至陣列正確位置
return cur-1; //回傳樞軸位置
}
void quick_sort(int arr[], int left, int right)
{
if (left >= right)
return;
int mid = partition(arr, left, right); //獲取樞軸位置
quick_sort(arr, left, mid - 1); //下端區間遞回
quick_sort(arr, mid + 1, right); //上端區間遞回
}
時間復雜度分析
快排的時間復雜度在最壞情況下是 O(n2),平均的時間復雜度是 O(n log n),
怎么理解呢?其實很簡單,假設數列中有n個數,則遍歷一次的時間復雜度為 O(n),需要遍歷至少 log (n + 1)次,最多 n次,
+Q1:為什么最少是 log (n + 1)次?
+A1:快速排序是采用分治法進行遍歷的,所以可以看成一棵二叉樹,它遍歷的次數就是二叉樹的深度,而根據二叉樹的定義,它的深度至少為 log (n + 1),因此快速排序的遍歷次數至少是 log (n + 1)次,
+Q2:為什么最多是 n次遍歷?
+A2:這個應該比較好理解,仍然將快速排序看作一棵二叉樹,二叉樹的最大深度為 n,所以快速排序的遍歷次數最多是 n次,
快速排序的穩定性
快速排序是不穩定的演算法,它不滿足穩定排序演算法的定義, 演算法穩定性:假設在數列中存在 a[i] = a[j],若在排序之前,a[i] 在 a[j] 前面,并且排序后,a[i]仍然在 a[j]前面,則這個排序是穩定的!
That's all!Thank you for watching !
快速排序優化已更新!傳送門
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/61730.html
標籤:C++
上一篇:#《Essential C++》讀書筆記# 第七章 例外處理
下一篇:母牛的故事