一、寫在前面
其實早就該寫這一篇博客了,為什么一直沒有寫呢?還不是因為忙不過來(實際上只是因為太懶了),不過好了,現在終于要開始寫這一篇博客了,在看這篇博客之前,可能需要你對 Go 這門語言有些基本的了解,比如基礎語法之類的,話不多說,進入正題,
二、Go 環境配置
1.安裝配置
在學習一門語言時,第一步就是環境配置了,Go 也不例外,下面就是 Windows 下 Go 開發環境的配置程序了,
首先你需要下載 Go 的安裝包,可以打開 Go 語言中文網下載,地址為:https://studygolang.com/dl,
下載完成后打開安裝(例如安裝到 E:\Go 目錄),然后配置環境變數,將安裝目錄下的 bin 目錄路徑加入環境變數中,這一步完成后打開命令列,輸入 go version,若出現版本資訊則表明配置成功,
2.配置 GOPATH 和 GOROOT
除了要將 bin 目錄加入到環境變數中,還要配置 GOPATH 和 GOROOT,步驟如下:
在用戶變數中新建變數 GOPATH:
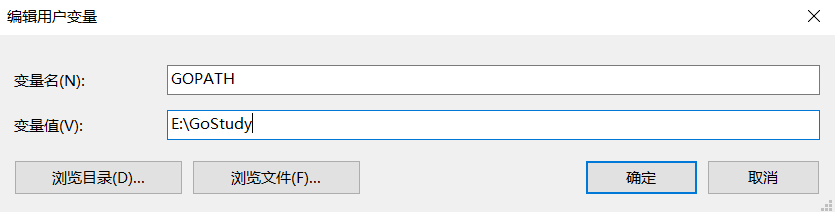
在系統變數中新建變數 GOROOT:
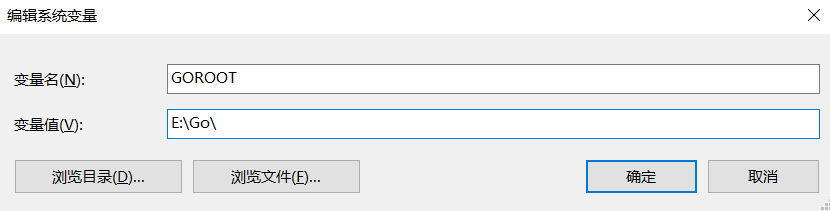
3. 選擇 IDE
在 IDE 的選擇上,我比較推薦使用 jetbrains 家的 GoLand,功能強大,使用起來也很方便,
三、下載網頁
下載網頁使用的是 Go 中原生的 http 庫,在使用前需要導包,和 Python 一樣用 import 匯入即可,如果要發送 GET 請求,可以直接使用 http 中的 Get() 方法,例如:
1 package main 2 3 import ( 4 "fmt" 5 "net/http" 6 ) 7 8 func main () { 9 html, err := http.Get("https://www.baidu.com/") 10 if err != nil { 11 fmt.Println(err) 12 } 13 fmt.Println(html) 14 }
Get() 方法有兩個回傳值,html 表示請求的結果,err 表示錯誤,這里必須對 err 做判斷,Go 語言的錯誤機制就是這樣,這里不多做解釋,
這么用起來確實很簡單,但是不能自己設定請求頭,如果要構造請求頭的話可以參考下面的例子:
1 req, _ := http.NewRequest("GET", url, nil) 2 // Set User-Agent 3 req.Header.Add("UserAgent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36") 4 client := &http.Client{} 5 resp, err := client.Do(req)
四、決議網頁
1.決議庫選擇
Go 語言中可以用來決議網頁的庫也是很齊全的,XPath、CSS 選擇器和正則運算式都能用,這里我用的是 htmlquery,這個庫使用的是 Xpath 選擇器,htmlquery 是用于 HTML 的 XPath 資料提取庫,可通過 XPath 運算式從 HTML 檔案中提取資料,Xpath 語法就不提了,畢竟用 Python 寫爬蟲的時候沒少用,
先說下 htmlquery 的安裝吧,一般會推薦你使用如下命令安裝:
go get github.com/antchfx/htmlquery
但是你懂的,出于某些原因就下載不下來,怎么辦呢?對于這種能在 GitHub 上找到的庫直接 clone 到本地就行了,記得要復制到你的 GOAPTH 下,
2.使用 htmlquery
在使用 htmlquery 這個庫的時候,可能會報錯說缺少 golang.org\x\text,和上面的解決辦法一樣,去 GitHub 上找,然后 clone 下來,
下面是 htmlquery 中經常使用的方法及相應含義:
func Parse(r io.Reader) (*html.Node, error): 回傳給定 Reader 的 HTML 的決議樹,
func Find(top *html.Node, expr string) []*html.Node: 搜索與指定 XPath 運算式匹配的 html.Node,
func FindOne(top *html.Node, expr string) *html.Node: 搜索與指定 XPath 運算式匹配的 html.Node,并回傳匹配的第一個元素,可簡單理解為FindOne = Find[0],
func InnerText(n *html.Node) string: 回傳物件的開始和結束標記之間的文本,
func SelectAttr(n *html.Node, name string) (val string): 回傳指定名稱的屬性值,
func OutputHTML(n *html.Node, self bool) string: 回傳包含標簽名稱的文本,
下面是使用 htmlquery 決議網頁的代碼:
1 // Used to parse html 2 func parse(html string) { 3 // Parse html 4 root, _ := htmlquery.Parse(strings.NewReader(html)) 5 titleList := htmlquery.Find(root, `//*[@id="post_list"]/div/div[2]/h3/a/text()`) 6 hrefList := htmlquery.Find(root, `//*[@id="post_list"]/div/div[2]/h3/a/@href`) 7 authorList := htmlquery.Find(root, `//*[@id="post_list"]/div/div[2]/div/a/text()`) 8 9 // Traverse the result 10 for i := range titleList { 11 blog := BlogInfo{} 12 blog.title = htmlquery.InnerText(titleList[i]) 13 blog.href =https://www.cnblogs.com/TM0831/p/ htmlquery.InnerText(hrefList[i]) 14 blog.author = htmlquery.InnerText(authorList[i]) 15 fmt.Println(blog) 16 } 17 }
需要注意的是由于在 Go 語言中不支持使用單引號來表示字串,而要使用反引號“`”和雙引號來表示字串,然后因為 Find() 方法回傳的是一個陣列,因而需要遍歷其中每一個元素,使用 for 回圈遍歷即可,在 for 回圈中使用到的 BlogInfo 是一個結構體,表示一個博客的基本資訊,定義如下:
1 // Used to record blog information 2 type BlogInfo struct { 3 title string 4 href string 5 author string 6 }
五、Go 并發
在 Go 語言中使用 go 關鍵字開啟一個新的 go 程,也叫 goroutine,開啟成功之后,go 關鍵字后的函式就將在開啟的 goroutine 中運行,并不會阻塞當前行程的執行,所以要用 Go 來寫并發還是很容易的,例如:
1 baseUrl := "https://www.cnblogs.com/" 2 for i := 2; i < 4; i ++ { 3 url := baseUrl + "#p" + strconv.Itoa(i) 4 // fmt.Println(url) 5 go request(url) 6 } 7 8 // Wait for goroutine 9 time.Sleep(2 * time.Second) 10 request(baseUrl)
這里除了在主行程中有一個 request(),還開啟了兩個 go 程來執行 request(),不過要注意的是,一旦主行程結束,其余 Go 程也會結束,所以我這里加了一個兩秒鐘的等待時間,用于讓 Go 程先結束,
六、體驗總結
由于我本身才剛開始學習 Go,就還有很多東西沒有學到,所以這個初體驗其實還有很多沒寫到的地方,比如資料保存,去重問題等等,后面會去多看看 Go 的官方檔案,當然了,對我來說,要寫爬蟲的話還是會用 Python 來寫的,不過還是得花時間學習新知識,比如使用 Go 做開發,熟悉掌握 Go 語言就是我的下一目標了,
完整代碼已上傳到 GitHub!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/63353.html
標籤:Go