每日一句英語學習,每天進步一點點:
- “Action may not always bring happiness; but there is no happiness without action.”
- 「行動不見得一定帶來快樂,但沒有行動就沒有快樂,」
前言
我在閱讀 《Effective C++ (第三版本)》 書時做了不少筆記,從中識訓了非常多,也明白為什么會書中前言的第一句話會說:
對于書中的「條款」這一詞,我更喜歡以「細節」替換,畢竟年輕的我們在打 LOL 或 王者的時,總會說注意細節!細節!細節~ —— 細節也算伴隨我們的青春的字眼
針對書中的前兩個章節,我篩選了 10 個 細節(條款)作為了本文的內容,這些細節也相對基礎且重要,
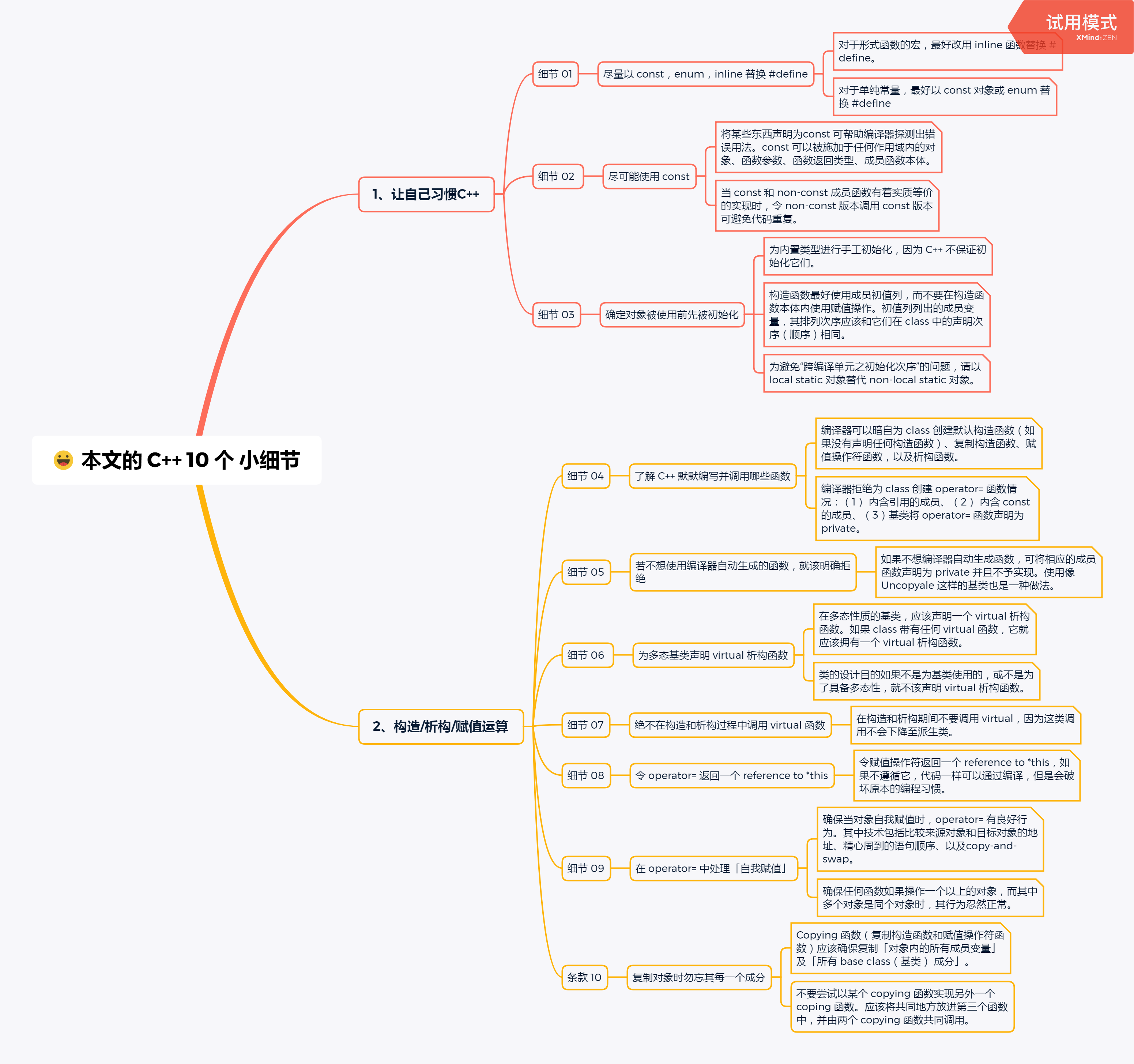
針對這 10 細節我都用較簡潔的例子來加以闡述,同時也把本文所提及細節中的「小結」總結繪畫成了一副思維導圖,便于大家的閱讀,
溫馨提示:本文較長(萬字),建議收藏閱讀,
后續有時間也會繼續分享后面章節的筆記,喜歡的小伙伴「點擊左上角」關注我~
正文
1 讓自己習慣C++
細節 01:盡量以const,enum,inline 替換 #define
#define 定義的常量有什么不妥?
首先我們要清楚程式的編譯重要的三個階段:預處理階段,編譯階段和鏈接階段,
#define 是不被視為語言的一部分,它在程式編譯階段中的預處理階段的作用,就是做簡單的替換,
如下面的 PI 宏定義,在程式編譯時,編譯器在預處理階段時,會先將原始碼中所有 PI 宏定義替換成 3.14:
1#define PI 3.14
程式編譯在預處理階段后,才進行真正的編譯階段,在有的編譯器,運用了此 PI 常量,如果遇到了編譯錯誤,那么這個錯誤資訊也許會提到 3.14 而不是 PI,這就會讓人困惑哪里來的3.14,特別是在專案大的情況下,
解決之道:以 const 定義一個常量替換上述的宏(#define)
作為一個語言變數,下面的 const 定義的常量 Pi 肯定會被編譯器看到,出錯的時候可以很清楚知道,是這個變數導致的問題:
1const doule Pi = 3.14;
如果是定義常量字串,則必須要 const 兩次,目的是為了防止指標所指內容和指標自身不能被改變:
1const char* const myName = "小林coding";
如果是定義常量 string,則只需要在最前面加一次 const,形式如下:
1const std::string myName("小林coding");
#define 不重視作用域,所以對于 class 的專屬常量,應避免使用宏定義,
還有另外一點宏無法涉及的,就是我們無法利用 #define 創建一個 class 專屬常量,因為 #define 并不重視作用域,
對于類里要定義專屬常量時,我們依然使用 static + const,形式如下:
1class Student {
2private:
3 static const int num = 10;
4 int scores[num];
5};
6
7const int Student::num; // static 成員變數,需要進行宣告
如果不想外部獲取到 class 專屬常量的記憶體地址,可以使用 enum 的方式定義常量
enum 會幫你約束這個條件,因為取一個 enum 的地址是不合法的,形式如下:
1class Student {
2private:
3 enum { num = 10 };
4 int scores[num];
5};
#define 實作的函式容易出錯,并且長相丑陋不易閱讀,
另外一個常見的 #define 誤用情況是以它實作宏函式,它不會招致函式呼叫帶來的開銷,但是用 #define 撰寫宏函式容易出錯,如下用宏定義寫的求最大值的函式:
1#define MAX(a, b) ( { (a) > (b) ? (a) : (b); } ) // 求最大值
這般長相的宏有著太的缺點,比如在下面呼叫例子:
1int a = 6, b = 5;
2int max = MAX(a++, b);
3
4std::cout << max << std::endl;
5std::cout << a << std::endl;
輸出結果(以下結果是錯誤的):
17 // 正確的答案是 max 輸出 6
28 // 正確的答案是 a 輸出 7
要解釋出錯的原因很簡單,我們把 MAX 宏做簡單替換:
1int max = ( { (a++) > (b) ? (a++) : (b); } ); // a 被累加了2次!
在上述替換后,可以發現 a 被累加了 2 次,我們可以通過改進 MAX 宏,來解決這個問題:
1#define MAX(a, b) ({ \
2 __typeof(a) __a = (a), __b = (b); \
3 __a > __b ? __a : __b; \
4})
簡單說明下,上述的 __typeof 可以根據變數的型別來定義一個相同型別的變數,如 a 變數是 int 型別,那么 __a 變數的型別也是 int 型別,改進后的 MAX 宏,輸出的是正確的結果,max 輸出 6,a 輸出 7,
雖然改進的后 MAX 宏,解決了問題,但是這種宏的長相就讓人困惑,
解決的方式:用 inline 替換 #define 定義的函式
用 inline 修飾的函式,也是可以解決函式呼叫的帶來的開銷,同時閱讀性較高,不會讓人困惑,
下面用用 template inline 的方式,實作上述宏定義的函式::
1template<typename T>
2inline T max(const T& a, const T& b)
3{
4 return a > b? a : b;
5}
max 是一個真正的函式,它遵循作用域和訪問規則,所以不會出現變數被多次累加的現象,
模板的基礎知識記憶體,可移步到我的舊文進行學習 --> 泛型編程的第一步,掌握模板的特性!
細節 01 小結 - 請記住
- 對于單純常量,最好以 const 物件或 enum 替換 #define;
- 對于形式函式的宏,最好改用 inline 函式替換 #define,
細節 02:盡可能使用 const
const 的一件奇妙的事情是:它允許你告訴編譯器和其他程式員某值應該保持不變,
1. 面對指標,你可以指定指標自身、指標所指物,或兩者都(或都不)是 const:
1char myName[] = "小林coding";
2char *p = myName; // non-const pointer, non-const data
3const char* p = myName; // non-const pointer, const data
4char* const p = myName; // const pointer, non-const data
5const char* const p = myName; // const pointer, const data
- 如果關鍵詞const出現在星號(
*)左邊,表示指標所指物是常量(不能改變 *p 的值); - 如果關鍵詞const出現在星號(
*)右邊,表示指標自身是常量(不能改變 p 的值); - 如果關鍵詞const出現在星號(
*)兩邊,表示指標所指物和指標自身都是常量;
2. 面對迭代器,你也指定迭代器自身或自迭代器所指物不可被改變:
1std::vector<int> vec;
2
3const std::vector<int>::iterator iter = vec.begin(); // iter 的作用像 T* const
4*iter = 10; // 沒問題,可以改變 iter 所指物
5++iter; // 錯誤! 因為 iter 是 const
6
7std::vector<int>::const_iterator cIter = vec.begin(); // cIter 的作用像 const T*
8*cIter = 10; // 錯誤! 因為 *cIter 是 const
9++cIter; // 沒問題,可以改變 cIter
- 如果你希望迭代器自身不可被改動,像指標宣告為
const即可(即宣告一個T* const指標); —— 這個不常用 - 如果你希望迭代器所指的物不可被改動,你需要的是
const_iterator(即宣告一個const T*指標),—— 這個常用
const 最具有威力的用法是面對函式宣告時的應用,在一個函式宣告式內,const 可以和函式回傳值、各引數、成員函式自身產生關聯,
1. 令函式回傳一個常量值,往往可以降低因程式員錯誤而造成的意外,舉個例子:
1class Rational { ... };
2const Rational operator* (const Rational& lhs, const Rational& rhs);
為什么要回傳一個 const 物件呢?原因是如果不這樣,程式員就能實作這一的暴力行為:
1Rational a, b, c;
2if (a * b = c) ... // 做比較時,少了個等號
如果 operator* 回傳的 const 物件,可以預防這個沒意義的賦值動作,
2. 將 const 實施于成員函式的目的,是為了確認該成員函式可作用于 const 物件,理由如下兩個:
理由 1 :
它們使得 class 介面比較容易理解,因為可以得知哪個函式可以改動物件而哪些函式不行,見如下例子:
1class MyString
2{
3public:
4 const char& operator[](std::size_t position) const // operator[] for const 物件
5 { return text[position]; }
6
7 char& operator[](std::size_t position) // operator[] for non-const 物件
8 { return text[position]; }
9private:
10 std::string text;
11};
MyString 的 operator[] 可以被這么使用:
1MyString ms("小林coding"); // non-const 物件
2std::cout << ms[0]; // 呼叫 non-const MyString::operator[]
3ms[0] = 'x'; // 沒問題,寫一個 non-const MyString
4
5const MyString cms("小林coding"); // const 物件
6std::cout << cms[0]; // 呼叫 const MyString::operator[]
7cms[0] = 'x'; // 錯誤! 寫一個 const MyString
注意,上述第 7 行會出錯,原因是 cms 是 const 物件,呼叫的是函式回傳值為 const 型別的 operator[] ,我們是不可以對 const 型別的變數或變數進行修改的,
理由 2 :
它們使操作 const 物件成為可能,這對撰寫高效代碼是個關鍵,因為改善 C++ 程式效率的一個根本的方法是以 pass by referenc-to-const(const T& a) 方式傳遞物件,見如下例子:
1class MyString
2{
3public:
4
5 MyString(const char* str) : text(str)
6 {
7 std::cout << "建構式" << std::endl;
8 }
9
10 MyString(const MyString& myString)
11 {
12 std::cout << "復制建構式" << std::endl;
13 (*this).text = myString.text;
14 }
15
16 ~MyString()
17 {
18 std::cout << "解構式" << std::endl;
19 }
20
21 bool operator==(MyString rhs) const // pass by value 按值傳遞
22 {
23 std::cout << "operator==(MyString rhs) pass by value" << std::endl;
24 return (*this).text == rhs.text;
25 }
26private:
27 std::string text;
28};
operator== 函式是 pass by value, 也就是按值傳遞,我們使用它,看下會輸出什么:
1int main()
2{
3 std::cout << "main()" << std::endl;
4 MyString ms1("小林coding");
5 MyString ms2("小林coding");
6
7 std::cout << ( ms1 == ms2) << std::endl; ;
8 std::cout << "end!" << std::endl;
9 return 0;
10}
輸出結果:
1main()
2建構式
3建構式
4復制建構式
5operator==(MyString rhs) pass by value
61
7解構式
8end!
9解構式
10解構式
可以發現在進入 operator== 函式時,發生了「復制構造函」,當離開該函式作用域后發生了「解構式」,說明「按值傳遞」,在進入函式時,會產生一個副本,離開作用域后就會消耗,說明這里是存在開銷的,
我們把 operator== 函式改成 pass by referenc-to-const 后,可以減少上面的副本開銷:
1bool operator==(const MyString& rhs)
2{
3 std::cout << "operator==(const MyString& rhs)
4 pass by referenc-to-const" << std::endl;
5 return (*this).text == rhs.text;
6}
再次輸出的結果:
1main()
2建構式
3建構式
4operator==(const MyString& rhs) pass by referenc-to-const
51
6end!
7解構式
8解構式
沒有發生復制建構式,說明 pass by referenc-to-const 比 pass by value 性能高,
在 const 和 non-const 成員函式中避免代碼重復
假設 MyString 內的 operator[] 在回傳一個參考前,先執行邊界校驗、列印日志、校驗資料完整性,把所有這些同時放進 const 和 non-const operator[]中,就會導致代碼存在一定的重復:
1class MyString
2{
3public:
4 const char& operator[](std::size_t position) const
5 {
6 ... // 邊界檢查
7 ... // 日志記錄
8 ... // 校驗資料完整性
9 return text[position];
10 }
11
12 char& operator[](std::size_t position)
13 {
14 ... // 邊界檢查
15 ... // 日志記錄
16 ... // 校驗資料完整性
17 return text[position];
18 }
19private:
20 std::string text;
21};
可以有一種解決方法,避免代碼的重復:
1class MyString
2{
3public:
4 const char& operator[](std::size_t position) const // 一如既往
5 {
6 ... // 邊界檢查
7 ... // 日志記錄
8 ... // 校驗資料完整性
9 return text[position];
10 }
11
12 char& operator[](std::size_t position)
13 {
14 return const_cast<char&>(
15 static_cast<const MyString&>(*this)[position]
16 );
17 }
18private:
19 std::string text;
20};
這份代碼有兩個轉型動作:
static_cast(*this)[position],表示將 MyString& 轉換成 const MyString&,可讓其呼叫 const operator[] 兄弟;const_cast<char& style="font-size: inherit; color: inherit; line-height: inherit; margin: 0px; padding: 0px;">( … ),表示將 const char & 轉換為 char &,讓其是 non-const operator[] 的回傳型別,
雖然語法有一點點奇特,但「運用 const 成員函式實作 non-const 孿生兄弟 」的技術是值得了解的,
需要注意的是:我們可以在 non-const 成員函式呼叫 const 成員函式,但是不可以反過來,在 const 成員函式呼叫 non-const 成員函式呼叫,原因是物件有可能因此改動,這會違背了 const 的本意,
細節 02 小結 - 請記住
- 將某些東西宣告為 const 可幫助編譯器探測出錯誤用法,const 可以被施加于任何作用域內的物件、函式引數、函式回傳型別、成員函式本體,
- 當 const 和 non-const 成員函式有著實質等價的實作時,令 non-const 版本呼叫 const 版本可避免代碼重復,
細節 03:確定物件被使用前先被初始化
內置型別初始化
如果你這么寫:
1int x;
在某些語境下 x 保證被初始化為 0,但在其他語境中卻不保證,那么可能在讀取未初始化的值會導致不明確的行為,
為了避免不確定的問題,最佳的處理方法就是:永遠在使用物件之前將它初始化, 例如:
1int x = 0; // 對 int 進行手工初始化
2const char* text = "abc"; // 對指標進行手工初始化
建構式初始化
對于內置型別以外的任何其他東西,初始化責任落在建構式,
規則很簡單:確保每一個建構式都將物件的每一個成員初始化,但是別混淆了賦值和初始化,
考慮用一個表現學生的class,其建構式如下:
1class Student {
2public:
3 Student(int id, const std::string& name, const std::vector<int>& score)
4 {
5 m_Id = id; // 這些都是賦值
6 m_Name = name; // 而非初始化
7 m_Score = score;
8 }
9private:
10 int m_Id;
11 std::string m_Name;
12 std::vector<int> m_Score;
13};
上面的做法并非初始化,而是賦值,這不是最佳的做法,因為 C++ 規定,物件的成員變數的初始化動作發生在進入建構式本體之前,在建構式內,都不算是被初始化,而是被賦值,
初始化的寫法是使用成員初值列,如下:
1 Student(int id,
2 const std::string &name,
3 const std::vector<int> &score)
4 : m_Id(id),
5 m_Name(name), // 現在,這些都是初始化
6 m_Score(score)
7 {} // 現在,建構式本體不必有任何動作
這個建構式和上一個建構式的最終結果是一樣的,但是效率較高,凸顯在:
- 上一個建構式(賦值版本)首先會先自動呼叫
m_Name和m_Score物件的默認建構式作為初值,然后在建構式體內立刻再對它們進行賦值操作,這期間經歷了兩個步驟, - 這個建構式(成員初值列)避免了這個問題,只會發生了一次復制建構式,本例中的
m_Name以name為初值進行復制構造,m_Score以score為初值進行復制構造,
另外一個注意的是初始化次序(順序),初始化次序(順序):
- 先是基類物件,再初始化派生類物件(如果存在繼承關系);
- 在類里成員變數總是以宣告次序被初始化,如本例中
m_Id先被初始化,再是m_Name,最后是m_Score,否則會出現編譯出錯,
避免「跨編譯單元之初始化次序」的問題
現在,我們關系的問題涉及至少兩個以上原始碼檔案,每一個內含至少一個 non-local static 物件,
存在的問題是:如果有一個 non-local static 物件需要等另外一個 non-local static 物件初始化后,才可正常使用,那么這里就需要保證次序的問題,
下面提供一個例子來對此理解:
1class FileSystem
2{
3public:
4 ...
5 std::size_t numDisk() const; // 眾多成員函式之一
6 ...
7};
8
9extern FileSystem tfs; // 預備給其他程式員使用物件
現假設另外一個程式員建立一個class 用以處理檔案系統內的目錄,很自然他們會用上 tfs 物件:
1class Directory
2{
3public:
4 Directory( params )
5 {
6 std::size_t disks = tfs.numDisk(); // 使用 tfs 物件
7 }
8 ...
9};
使用 Directory 物件:
1Directory tempDir( params );
那么現在,初始化次序的重要性凸顯出來了,除非 tfsd 物件在 tempDir 物件之前被初始化,否則 tempDir 的建構式會用到尚未初始化的 tfs, 就會出現未定義的現象,
由于 C++ 對「定義于不同的編譯單元內的 non-local static 物件」的初始化相對次序并無明確定義,但我們可以通過一個小小的設計,解決這個問題,
唯一需要做的是:將每個 non-local static 物件搬到自己的專屬函式內(該物件在此函式內被宣告為 static),這些函式回傳一個參考指向它所含的物件,
沒錯也就是單例模式,代碼如下:
1class FileSystem
2{
3public:
4 ...
5 static FileSystem& getTfs() // 該函式作用是獲取 tfs 物件,
6 {
7 static FileSystem tfs; // 定義并初始化一個 local static 物件,
8 return tfs; // 回傳一個參考指向上述物件,
9 }
10 ...
11};
12
13
14class Directory
15{
16public:
17 ...
18 Directory( params )
19 {
20 std::size_t disks = FileSystem::getTfs().numDisk(); // 使用 tfs 物件
21 }
22 ...
23};
這么修改后,Directory 建構式就會先初始化 tfs 物件,就可以避免次序問題了,雖然內含了 static 物件,但是在 C++11 以上是執行緒安全的,
細節 03 小結 - 請記住
- 為內置型別進行手工初始化,因為 C++ 不保證初始化它們,
- 建構式最好使用成員初值列,而不要在建構式本體內使用賦值操作,初值列列出的成員變數,其排列次序應該和它們在 class 中的宣告次序(順序)相同,
- 為避免“跨編譯單元之初始化次序”的問題,請以 local static 物件替代 non-local static 物件,
2 構造/析構/賦值運算
細節 04:了解 C++ 默默撰寫并呼叫哪些函式
當你寫了如下的空類:
1class Student { };
編譯器就會它宣告,并且這些函式都是 public 且 inline:
- 復制建構式
- 賦值運算子函式
- 解構式
- 默認建構式(如果沒有宣告任何建構式)
就好像你寫下這樣的代碼:
1class Student
2{
3 Student() { ... } // 默認建構式
4 Student(const Student& rhs) { ... } // 復制建構式
5 Student& operator=(const Student& rhs) { ... } // 賦值運算子函式
6 ~Student() { ... } // 解構式
7};
唯有當這些函式被需要呼叫時,它們才會被編譯器創建出來,下面代碼造成上述每一個函式被編譯器產出:
1Student stu1; // 默認建構式
2 // 解構式
3Student stu2(stu1); // 復制建構式
4stu2 = stu1; // 賦值運算子函式
編譯器為我們寫的函式,來說說這些函式做了什么?
- 默認建構式和解構式主要是給編譯器一個地方用來放置隱藏幕后的代碼,像是呼叫基類和非靜態成員變數的建構式和解構式,注意,編譯器產出的解構式是個 non-virtual,除非這個 class 的 base class 自身宣告有 virtual 解構式,
- 復制建構式和賦值運算子函式,編譯器創建的版本只是單純地將來源物件的每一個非靜態成員變數拷貝到目標物件,
編譯器拒絕為 class 生出 operator= 的情況
對于賦值運算子函式,只有當生出的代碼合法且有適當機會證明它有意義,才會生出 operator= ,若萬一兩個條件有一個不符合,則編譯器會拒絕為 class 生出 operator= ,
舉個例子:
1template<class T>
2class Student
3{
4public:
5 Student(std::string & name, const T& id); // 建構式
6 ... // 假設未宣告 operator=
7priavte:
8 std::string& m_Name; // 參考
9 const T m_Id; // const
10};
現考慮下面會發生什么:
1std::string name1("小美");
2std::string name2("小林");
3
4Student<int> p(name1, 1);
5Student<int> s(name2, 2);
6
7p = s; // 現在 p 的成員變數會發生什么?
賦值之前, p.m_Name 和 s.m_Name 都指向 string 物件且不是同一個,賦值之后 p.m_Name 應該指向 s.m_Name 所指的那個 string 嗎?也就是說參考自身可被改動嗎?如果是,那就開辟了新天地,因為 C++ 并不允許「讓參考更改指向不同物件」,
面對這個難題,C++ 的回應是拒絕編譯那一行賦值動作,本例子拒絕生成的 operator= 原因如下:
- 如果你需要在一個「內含參考的成員」(如本例的
m_Name)的class 內支持賦值操作,你必須自己定義賦值操作函式,這種情況是編譯器不會為你自動生成賦值操作函式的, - 還有面對「內含
const成員」(如本例的m_Id)的class,編譯器也是會拒絕生成operator=,因為更改const成員是不合法的,
最后還有一個情況:如果某個基類將 operator= 函式宣告為 private ,編譯器將拒絕為其派生類生成 operator= 函式,
細節 04 小結 - 請記住
- 編譯器可以暗自為 class 創建默認建構式(如果沒有宣告任何建構式)、復制建構式、賦值運算子函式,以及解構式,
- 編譯器拒絕為 class 創建 operator= 函式情況:(1) 內含參考的成員、(2) 內含 const 的成員、(3)基類將 operator= 函式宣告為 private,
細節 05:若不想使用編譯器自動生成的函式,就該明確拒絕
在不允許存在一模一樣的兩個物件的情況下,可以把復制建構式和賦值運算子函式宣告為 private,這樣既可防止編譯器自動生成這兩個函式,如下例子:
1class Student
2{
3public:
4 ...
5private:
6 ...
7 Student(const Student&); // 只有宣告
8 Student& operator=(const Student&); // 只有宣告
9};
這樣的話,Student 物件就無法操作下面的情況了:
1Student stu1;
2Student stu2(stu1); // 錯誤,禁用了 復制建構式
3
4stu2 = stu1; // 錯誤,禁用了 賦值運算子函式
更容易擴展的解決方式是,可以專門寫一個為阻止 copying 動作的基類:
1class Uncopyale
2{
3protect: // 允許派生類物件構造和析構
4 Uncopyale() {}
5 ~Uncopyale() {}
6private: // 禁止派生類物件copying
7 Uncopyale(const Uncopyale&);
8 Uncopyale& operater=(const Uncopyale&);
9};
使用方式很簡單,只需要 private 形式的繼承:
1class Student : private Uncopyale{
2 ... // 派生類不用再宣告復制建構式和賦值運算子函式
3};
那么只要某個類需要禁止 copying 動作,則只需要 private 形式的繼承 Uncopyale 基類即可,
細節 05 小結 - 請記住
- 如果不想編譯器自動生成函式,可將相應的成員函式宣告為 private 并且不予實作,使用像 Uncopyale 這樣的基類也是一種做法,
細節 06:為多型基類宣告 virtual 解構式
多型特性的基礎內容,可移步到我的舊文進行學習 --> 掌握了多型的特性,寫英雄聯盟的代碼更少啦!
多型性質基類需宣告 virtual 解構式
如果在多型性質的基類,沒有宣告一個 virtual 解構式,那么在 delete 基類指標物件的時候,只會呼叫基類的解構式,而不會呼叫派生類的解構式,這就是存在了泄漏記憶體和其他資源的情況,
如下有多型性質基類,沒有宣告一個 virtual 解構式的例子:
1// 基類
2class A
3{
4public:
5 A() // 建構式
6 {
7 cout << "construct A" << endl;
8 }
9
10 ~A() // 解構式
11 {
12 cout << "Destructor A" << endl;
13 }
14};
15
16// 派生類
17class B : public A
18{
19public:
20 B() // 建構式
21 {
22 cout << "construct B" << endl;
23 }
24
25 ~B()// 解構式
26 {
27 cout << "Destructor B" << endl;
28 }
29};
30
31int main()
32{
33 A *pa = new B();
34 delete pa; // 釋放資源
35
36 return 0;
37}
輸出結果:
1construct A
2construct B
3Destructor A
4
從上面的結果,是發現了在 delete 基本物件指標時,沒有呼叫派生類 B 的解構式,問題出在 pa 指標指向派生類物件,而那個物件卻經由一個基類指標被洗掉,而目前的基類沒有 virtual 解構式,
消除這個問題的做法很簡單:為了避免泄漏記憶體和其他資源,需要把基類的解構式宣告為 virtual 解構式,改進如下:
1// 基類
2class A
3{
4public:
5 .... // 如上
6 virtual ~A() // virtual 解構式
7 {
8 cout << "Destructor A" << endl;
9 }
10};
11... // 如上
此后洗掉派生類物件就會如你想要的那般,是的,它會銷毀整個物件,包括所有派生類成份,
非多型性質基類無需宣告 virtual 函式
當類的設計目的不是被當做基類,令其解構式為 virtual 往往是個餿主意,
若類里宣告了 virtual 函式,物件必須攜帶某些資訊,主要用來運行期間決定哪一個 virtual 函式被呼叫,
這份資訊通常是由一個所謂 vptr(virtual table pointer —— 虛函式表指標)指標指出,vptr 指向一個由函式指標構成的陣列,稱為 vtbl(virtual table —— 虛函式表);每一個帶有 virtual 函式的類都有一個相應的 vtbl,當物件呼叫某一 virtual 函式,實際被呼叫的函式取決于該物件的 vptr 所指向的那個 vtbl,接著編譯器在其中尋找適當的函式指標,從而呼叫對應類的函式,
既然內含 virtual 函式的類的物件必須會攜帶資訊,那么必然其物件的體積是會增加的,
- 在 32 位計算機體系結構中將多占用 4個位元組(存放 vptr );
- 在 64 位計算機體系結構則將多占用 8 個位元組(存放 vptr ),
因此,無端地將所有類的解構式宣告為 virtual ,是錯誤的,原因是會增加不必要的體積,
許多人的心得是:只有當 class 內含至少一個 virtual 函式,才為它宣告 virtual 解構式,
細節 06 小結 - 請記住
- 在多型性質的基類,應該宣告一個 virtual 解構式,如果 class 帶有任何 virtual 函式,它就應該擁有一個 virtual 解構式,
- 類的設計目的如果不是為基類使用的,或不是為了具備多型性,就不該宣告 virtual 解構式,
細節 07:絕不在構造和析構程序中呼叫 virtual 函式
我們不該在建構式和解構式體內呼叫 virtual 函式,因為這樣的呼叫不會帶來你預想的結果,
我們看如下的代碼例子,來說明:
1// 基類
2class CFather
3{
4public:
5 CFather()
6 {
7 hello();
8 }
9
10 virtual ~CFather()
11 {
12 bye();
13 }
14
15 virtual void hello() // 虛函式
16 {
17 cout<<"hello from father"<<endl;
18 }
19
20 virtual void bye() // 虛函式
21 {
22 cout<<"bye from father"<<endl;
23 }
24};
25
26// 派生類
27class CSon : public CFather
28{
29public:
30 CSon() // 建構式
31 {
32 hello();
33 }
34
35 ~CSon() // 解構式
36 {
37 bye();
38 }
39
40 virtual void hello() // 虛函式
41 {
42 cout<<"hello from son"<<endl;
43 }
44
45 virtual void bye() // 虛函式
46 {
47 cout<<"bye from son"<<endl;
48 }
49};
現在,當以下這行被執行時,會發生什么事情:
1CSon son;
先列出輸出結果:
1hello from father
2hello from son
3bye from son
4bye from father
無疑地會有一個 CSon(派生類) 建構式被呼叫,但首先 CFather(基類) 建構式一定會更早被呼叫, CFather(基類) 建構式體力呼叫 virtual 函式 hello,這正是引發驚奇的起點,這時候被呼叫的 hello 是 CFather 內的版本,而不是 CSon 內的版本,
說明,基類構造期間 virtual 函式絕不會下降到派生類階層,取而代之的是,物件的作為就像隸屬于基型別別一樣,
非正式的說法或許比較傳神:在基類構造期間,virtual 函式不是 virtual 函式,
相同的道理,也適用于解構式,
細節 07 小結 - 請記住
- 在構造和析構期間不要呼叫 virtual,因為這類呼叫不會下降至派生類,
細節 08:令 operator= 回傳一個 reference to *this
關于賦值,又去的是你可以把它們寫成連鎖形式:
1int x, y, z;
2x = y = z = 15; // 賦值連鎖形式
同樣有趣的是,賦值采用右結合律,所以上述連鎖賦值被決議為:
1x = (y = ( z = 15 ));
這里 15 先被賦值給 z,然后其結果再被賦值給 y,然后其結果再賦值給 x ,
為了實作「連鎖賦值」,賦值操作必須回傳一個 reference (參考)指向運算子的左側實參,這是我們為 classes 實作賦值運算子時應該遵循的協議:
1class A
2{
3public:
4...
5 A& operator=(const A& rhs) // 回傳型別是一個參考,指向當前物件,
6 {
7 ...
8 return *this; // 回傳左側物件
9 }
10...
11};
這個協議不僅適用于以上標準賦值形式,也適用于所有賦值相關運算(+=, -=, *=, 等等),例如:
1class A
2{
3public:
4...
5 A& operator+=(const A& rhs) // 這個協議適用于 +=, -=, *=, 等等,
6 {
7 ...
8 return *this;
9 }
10...
11};
注意,這只是個協議,并無強制性,如果不遵循它,代碼一樣可以通過編譯,但是會破壞原本的編程習慣,
細節 08 小結 - 請記住
- 令賦值運算子回傳一個 reference to *this,
細節 09:在 operator= 中處理「自我賦值」
「自我賦值」發生在物件被賦值給自己時:
1class A { ... };
2A a;
3...
4a = a; // 賦值給自己
這看起來有點愚蠢,但它合法,所以不要認定我們自己絕對不會那么做,
此外賦值動作并不總是那么一眼被識別出來,例如:
1a[i] = a[j]; // 潛在的自我賦值
如果 i 和 j 有相同的值,這便是個自我賦值,再看:
1*px = *py; // 潛在自我賦值
如果 px 和 py 剛好指向同一個東西,這也是自我賦值,這些都是并不明顯的自我賦值,
考慮到我們的類內含指標成員變數:
1class B { ... };
2class A
3{
4...
5private:
6 B * pb; // 指標,指向一個從堆分配而得的物件
7}
下面是operator = 實作代碼,表面上看起來合理,但自我賦值出現時并不安全:
1A& A::operator=(const A& rhs) // 一份不安全的operator = 實作版本
2{
3 delete pb; // 釋放舊的指標物件
4 pb = new B(*rhs.pb); // 生成新的地址
5 return *this;
6}
這里的自我賦值的問題是, operator= 函式內的 *this(賦值的目的端)和 rhs 有可能是同一個物件,果真如此 delete 就不只是銷毀當前物件的 pb,它也銷毀 rhs 的 pb,
相當于發生了自我銷毀(自爆/自滅)程序,那么此時 A 類物件持有了一個指向一個被銷毀的 B 類物件,非常的危險,請勿模仿!
下面來說說如何規避這種問題的方式,
方式一:比較來源物件和目標物件的地址
要想阻止這種錯誤,傳統的做法是在 operator= 函式最前面加一個 if 判斷,判斷是否是自己,不是才進行賦值操作:
1A& A::operator=(const A& rhs)
2{
3 if(this == &rhs)
4 return *this; // 如果是自我賦值,則不做任何事情,
5
6 delete pb; // 釋放舊的指標物件
7 pb = new B(*rhs.pb); // 生成新的地址
8 return *this;
9}
這樣錯雖然行得通,但是不具備自我賦值的安全性,也不具備例外安全性:
- 如果「 new B 」這句發生了例外(申請堆記憶體失敗的情況),A 最侄訓持有一個指標指向一塊被洗掉的 B,這樣的指標是有害的,
我舊文里《C++ 賦值運算子'='的多載(淺拷貝、深拷貝)》在規避這個問題試,就采用的是方式 一,這個方式是不合適的,
方式二:精心周到的陳述句順序
把代碼的順序重新編排以下就可以避免此問題,例如一下代碼,我們只需之一在賦值 pb 所指東西之前別刪掉 pb :
1A& A::operator=(const A& rhs)
2{
3 A* pOrig = pb; // 記住原先的pb
4 pb = new B(*rhs.pb); // 令 pb 指向 *pb的一個副本
5 delete pOrig; // 洗掉原先的pb
6 return *this;
7}
現在,如果「 new B 」這句發生了例外,pb 依然保持原狀,即使沒有加 if 自我判斷,這段代碼還是能夠處理自我賦值,因為我們對原 B 做了一份副本、洗掉原 B 、然后回傳參考指向新創造的那個副本,
它或許不是處理自我賦值的最高效的方法,但它行得通,
方式三:copy and swap
更高效的方式使用所謂的 copy and swap 技術,實作方法如下:
1class A
2{
3...
4void swap(A& rhs) // 交換*this 和 rhs 的資料
5{
6 using std::swap;
7 swap(pb, rhs.pb);
8}
9...
10private:
11 B * pb; // 指標,指向一個從堆分配而得的物件
12}
13};
14
15A& A::operator=(const A& rhs)
16{
17 A temp(rhs); // 為 rhs 制作一份復件(副本)
18 swap(tmp); // 將 *this 資料和上述復件的資料交換,
19 return *this;
20}
當類里 operator= 函式被宣告為「以 by value 方式接受實參」,那么由于 by value 方式傳遞東西會造成一份復件(副本),則直接 swap 交換即可,如下:
1A& A::operator=(A rhs) // rhs是被傳物件的一份復件
2{
3 swap(rhs); // 將 *this 資料和復件的資料交換,
4 return *this;
5}
細節 09 小結 - 請記住
- 確保當物件自我賦值時,operator= 有良好行為,其中技術包括比較來源物件和目標物件的地址、精心周到的陳述句順序、以及 copy-and-swap,
- 確保任何函式如果操作一個以上的物件,而其中多個物件是同個物件時,其行為忍然正常,
細節 10:復制物件時勿忘其每一個成分
在以下我把復制建構式和賦值運算子函式,稱為「copying 函式」,
如果你宣告自己的 copying 函式,那么編譯器就不會創建默認的 copying 函式,但是,當你在實作 copying 函式,遺漏了某個成分沒被 copying,編譯器卻不會告訴你,
確保物件內的所有成員變數 copying
考慮用一個 class 用來表示學生,其中自實作 copying 函式,如下:
1class Student
2{
3public:
4 ...
5 Student(const Student& rhs);
6 Student& operator=(const Student& rhs);
7 ...
8private:
9 std:: string name;
10}
11
12Student::Student(const Student& rhs)
13 : name(rhs.name) // 復制 rhs 的資料
14{ }
15
16Student& Student::operator=(const Student& rhs)
17{
18 name = rhs.name; // 復制 rhs 的資料
19 return *this;
20}
這里的每一件事情看起來都很好,直到另一個成員變數加入戰局:
1class Student
2{
3public:
4 ... // 同前
5private:
6 std:: string name;
7 int score;
8}
這時候遺漏對新成員變數的 copying,大多數編譯器對此不做任何報錯,
結論很明顯:如果你為 class 添加一個成員變數,你必須同時修改 copying 函式,
確保所有 base class (基類) 成分 copying
一旦存在繼承關系的類,可能會造成此一主題最黑暗肆意的一個潛在危機,試考慮:
1class CollegeStudent : public Student // 繼承 Student
2{
3public:
4...
5 CollegeStudent(const CollegeStudent& rhs);
6 CollegeStudent& operator=(const CollegeStudent& rhs);
7...
8private:
9 std::string major;
10};
11
12CollegeStudent::CollegeStudent(const CollegeStudent& rhs)
13 : major(rhs.major)
14{ }
15
16CollegeStudent& CollegeStudent::operator=(const CollegeStudent& rhs)
17{
18 major = rhs.major;
19 return *this;
20}
CollegeStudent 的 copying 函式看起來好像復制了 CollegeStudent 內的每一樣東西,但是請再看一眼,是的,它們復制了 CollegeStudent 宣告的成員變數,但每個 CollegeStudent 還內含所繼承的 Student 成員變數復件(副本),而哪些成員變數卻未被復制,
所以任何時候只要我們承擔起「為派生類撰寫 copying 函式」的重則大任,必須很小心地也復制其 base class 成分:
1CollegeStudent::CollegeStudent(const CollegeStudent& rhs)
2 : Student(rhs), // 呼叫 base class 的 copy建構式
3 major(rhs.major)
4{ }
5
6CollegeStudent& CollegeStudent::operator=(const CollegeStudent& rhs)
7{
8 Student::operator=(rhs); // 對 base class 成分進行賦值動作
9 major = rhs.major;
10 return *this;
11}
所以我們不僅要確保復制所有類里的成員變數,還要呼叫所有 base classes 內的適當的 copying 函式,
消除 copying 函式之間的重復代碼
還要一點需要注意的:不要令復制「建構式」呼叫「賦值運算子函式」,來減少代碼的重復,這么做也是存在危險的,假設呼叫賦值運算子函式不是你期望的,—— 錯誤行為,
同樣也不要令「賦值運算子函式」呼叫「建構式」,
如果你發現你的「復制建構式和賦值運算子函式」有近似的代碼,消除重復代碼的做法是:建立一個新的成員函式給兩者呼叫,
細節 10 小結 - 請記住
- Copying 函式(復制建構式和賦值運算子函式)應該確保復制「物件內的所有成員變數」及「所有 base class(基類) 成分」,
- 不要嘗試以某個 copying 函式實作另外一個 coping 函式,應該將共同地方放進第三個函式中,并由兩個 copying 函式共同呼叫,
最后
能看完或滑到這里的小伙伴不容易,給你們點贊,感謝你們!
送上你們要的的思維導圖:
關注公眾號,后臺回復「我要學習」,即可免費獲取精心整理「服務器 Linux C/C++ 」成長路程(書籍資料 + 思維導圖)

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/64994.html
標籤:C++
上一篇:lost cows