前言:
深入學習JAVA前,程式猿需要了解一些相關的硬體底層知識,這一篇專門來講一講CPU和JAVA相關的知識
因為學習內容里有些不那么重要的知識點,往往就是截圖或者少量文字帶過,個人筆記不會記錄那么多細節,詳細資料請讀者自己查詢,見諒,
簡易的計算機組成:
CPU從PC中拿到下一條指令的地址,從記憶體或別的IO設備中讀取資料,把資料暫時存放在Registers中,根據指令要求,在ALU中對Registers中的資料進行運算,然后把結果回傳到指定的記憶體區域,
CPU的基本組成:
- Registers -> 暫時存盤CPU計算需要用到的資料
- ALU -> Arithmetic & Logic Unit 運算單元
- CU -> Control Unit 控制單元
- MMU -> Memory Management Unit 記憶體管理單元
- cache -> 多級快取
CPU的多執行緒結構:
ALU可以快速切換Registers,以快速處理多個執行緒
多核CPU結構:
CPU快取:
為了讓CPU更快速的讀取資料(比從記憶體讀取還快),就在CPU中設計了多級快取
讀取速度參考值:
按塊讀取規則
根據程式區域性原理(一個程式存盤的資料一般在記憶體中是連續的),往往讀取資料都是按照一個個資料塊進行讀取的,以此來提高IO效率,
cache line (快取行)
上面是個多核的CPU的記憶體讀取模型
CPU讀取資料時,會就近原則取資料,取不到最后會從記憶體中再一步步存回L1快取
CPU->L1->L2->L3->MEMORY->L3->L2->L1->CPU
cache line 為 快取行 ,每次讀取資料都會讀取一個快取行,而不是單個資料大小的內容,
快取行越大,區域性空間效率越高,但讀取時間慢
快取行越小,區域性空間效率越低,但讀取時間快
取一個折中值,目前CPU快取行大多使用:64位元組
多個CPU讀取同一快取行內的資料存在資料一致性問題:
對于這個問題,不同的CPU使用不同的快取一致性協議,單位都是以快取行讀取的,
Intel:MESI協議 www.cnblogs.com/z00377750/p…
- M:Modified
- E:Exclusive
- S:Shared
- I:Invalid
快取行對齊:
因為有快取行的存在,就出現了一種編程設計方式,叫做快取行對齊!
對于有些特別敏感的數字,會存在執行緒高競爭的訪問,為了保證不發生偽共享,就可以使用快取航對齊的編程方式
JDK7中,很多采用long padding提高效率(就是一個資料的前后塞滿Long型別,一個Long占8位元組)
JDK8,加入了@Contended注解(實驗)需要加上:JVM -XX:-RestrictContended
CPU的亂序執行特性:

當CPU得到的多個指令間沒有依賴關系,那么CPU會在等待某條指令操作時優先執行另一條指令,上圖有個很好的例子,燒開水的時候,人可以去洗茶杯茶壺,這樣就可以提高喝茶的整體效率了~
但是,當在多執行緒場景中,CPU亂序執行可能就會出現問題
這里簡單快速的解釋一下(主要跟JVM有關)
1、由于JAVA創建物件時,有個中間態,處于中間態時,物件并沒有完成全部的初始化,
2、如果此時,在中間態時,發生了CPU亂序執行,初始化物件指令還未執行,物件就被另一個執行緒使用,就會導致拿到沒有初始化完成的物件,
(DCL單例就是解決這個問題,所以DCL單例必須使用volatile修飾物件, volatile可以禁止重排序,并且執行緒透明)
禁止亂序執行:
CPU層面上,要如何禁止指令的重排序呢?答案就是記憶體屏障,,對某部分記憶體做操作前后做出記憶體屏障,屏障前后指令不可亂序執行,
Intel CPU可以使用三種原語( lfence sfence mfence ),或者Lock指令來實作,
1、lfence -> loadfence 在lfence指令前的讀操作必須在lfence指令后的讀操作前執行,sfence -> storefence 在sfence指令前的寫操作必須在sfence指令后的寫操作前執行, mfence -> mixedfence 在mfence指令前的讀寫操作必須在mfence指令后的讀寫操作前執行
2、Lock指令比較狠,它屬于X86 CPU指令,它會直接鎖住記憶體總線(Memory BUS)
JVM層面上,JVM規范了他的記憶體屏障實作
1、loadload屏障 loadload屏障前的load1指令必須先于loadload屏障后的load2指令前完成,不可互換
2、storestore屏障 ,,,,,,類推
3、loadstore屏障 loadstore屏障前的load1指令必須先于loadload屏障后的store2指令前完成,不可互換
4、storeload屏障 ,,,,,,類推
舉個栗子:JVM對volatile的實作,保證了可見性和禁止亂序
store1
storestore (等前面的store1寫指令完成后才能開始volatile的寫指令)
volatile寫指令
storeload (等前面的volatile寫指定完成后才能做后面的讀指令)
load1
loadload (等前面的load1寫指令完成后才能開始volatile的讀指令 )
volatile讀指令
loadstore (等前面的volatile讀指令完成后才能做后面的寫指令)
JVM同時也規定了指令重排序的必須遵守的8條規則,稱之為Happens-Before規則(這個知道就好,不用細扣)
Happens-Before的規則包括:
- 程式順序規則
- 鎖定規則
- volatile變數規則
- 執行緒啟動規則
- 執行緒結束規則
- 中斷規則
- 終結器規則
- 傳遞性規則
as-if-serial:不管硬體什么順序,單執行緒執行的結果不變,看上去好像是serial順序執行
SingleThreadPool 可以實作單執行緒的佇列任務
WC - Write Combining 合并寫技術
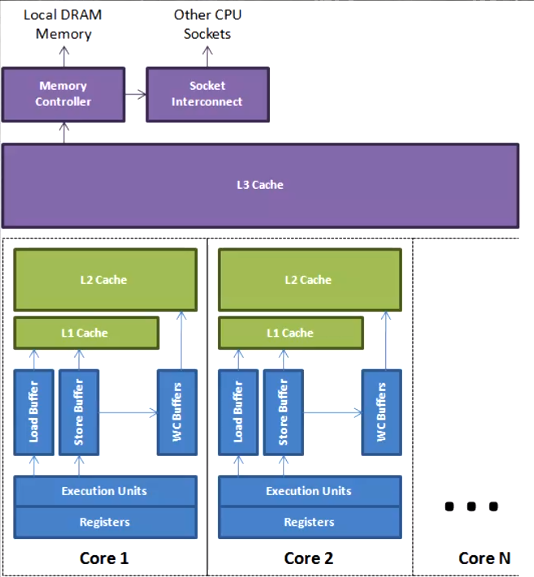
為了提高寫效率,CPU在寫入L1快取時,同時用WC寫入L2快取
Registers和L1快取間存在極小空間的緩沖區,Load Buffer, Store Buffer
但是還有一個直接通向L2快取,那就是WC Buffer,這塊緩沖區一般大小為4個位元組,在寫入L1快取的同時,寫入一個WC BUFFER,寫滿該快取區后,直接更新到L2快取
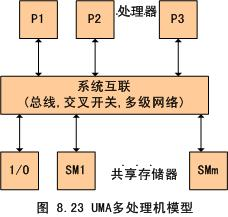
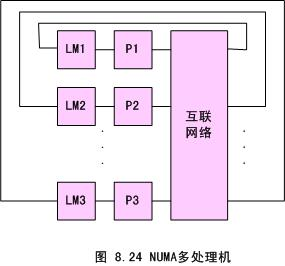
UMA 和 NUMA
均勻存盤器存取(Uniform-Memory-Access,簡稱UMA)模型、非均勻存盤器存取(Nonuniform-Memory-Access,簡稱NUMA)模型,這些模型的區別在于存盤器和外圍資源如何共享或分布,
https://blog.csdn.net/tiangwan2011/article/details/7298785
結束語
CPU相關的知識就記錄到這,總的來說,一些知識點解釋了JVM的一些底層細節,也非常有趣,作為以后了解JVM原理時的基礎知識,還是非常有學習意義的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/65080.html
標籤:Java