JVM垃圾回收(GC)
1. 判斷物件是否可以被回收
-
參考計數法:每個物件有一個參考計數屬性,新增一個參考時計數加1,參考釋放時計數減1,計數為0時可以回收,此方法簡單,但無法解決物件相互回圈參考的問題,
// 回圈參考 Node a=new Node(); Node b=new Node(); a.next=b; b.next=a; -
可達性分析:從GC Roots開始向下搜索,搜索所走過的路徑稱為參考鏈,當一個物件到GC Roots沒有任何參考鏈時,則證明此物件時不可用的,可以被回收,
可以作為GC Roots的物件包括下面幾種:
- 虛擬機堆疊(堆疊幀中的本地變數表)中參考的物件;
- 方法區中類靜態屬性參考的物件;
- 方法區中常量參考的物件;
- 本地方法堆疊中JNI(即一般說的Native方法)參考的物件,
為了避免物件相互回圈參考的問題,JVM中使用可達性分析判斷物件是否可以被回收,
2. 四種參考
2.1 強參考(StrongReference)
大部分參考都是強參考,是使用最普遍的參考,強參考不會被垃圾回收器回收,始終是可達狀態,當記憶體空間不足時,JVM寧可拋出OOM例外,使程式例外終止,也不會通過回收具有強參考的物件來解決記憶體不足的問題,這是造成Java記憶體泄漏的重要原因之一,(聯系ThreadLocal例子)
2.2 軟參考(SoftReference)
對于具有軟參考的物件,當記憶體空間足夠時,垃圾回收器不會回收它,若記憶體空間不夠了,就會回收這些物件的記憶體,軟參考可以用來實作記憶體敏感的高速快取,
2.3 弱參考(WeakReference)
只要垃圾回識訓制運行并發現了具有弱參考的物件,不管當前記憶體空間是否足夠,都會回收該物件的記憶體,垃圾回收執行緒的優先級很低,不一定很快發現只具有弱參考的物件,
2.4 虛參考(PhantomReference)
主要作用是用于跟蹤物件被垃圾回收的活動,不能單獨使用,必須與參考佇列(ReferenceQueue)聯合使用,當垃圾回收器準備回收一個物件時,如果發現它具有虛參考,就會在回收物件的記憶體前把這個虛參考加入到與之關聯的參考佇列中,程式可以通過判斷參考佇列中是否已經加入虛參考來了解被參考的物件是否要被垃圾回收,
3. 判斷廢棄常量和無用的類
廢棄常量:運行時常量池主要回收廢棄常量,如果當前沒有任何物件參考該常量,就說明該常量是廢棄常量,
無用的類:需要同時滿足3個條件,
- 該類的所有實體都已經被回收,即堆中不存在該類的任何實體,
- 加載該類的ClassLoader已經被回收
- 該類對于的java.lang.Class物件沒有在任何地方被參考,無法在任何地方通過反射訪問該類的方法,
4. 垃圾收集演算法
4.1 標記-清除演算法(Mark-Sweep)
原理:首先標記出可以回收的物件,在標記完成后統一回收所有被標記的物件,
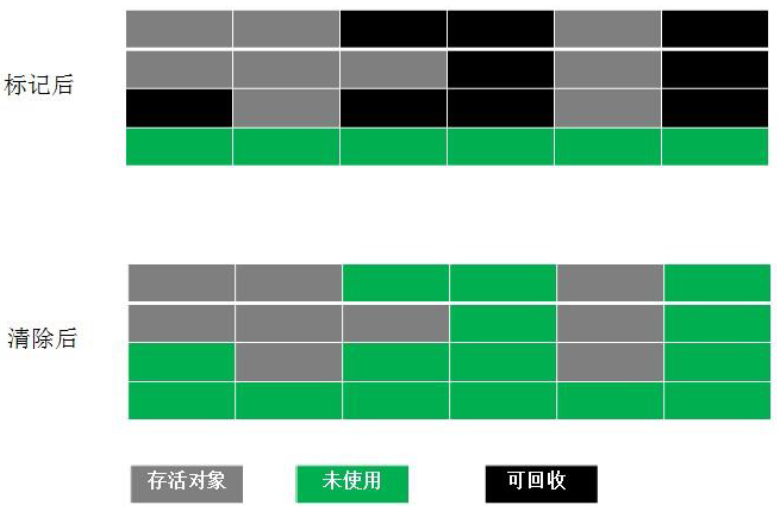
特點:記憶體碎片化嚴重、效率低,
4.2 復制演算法(Copying)
原理:按記憶體容量將記憶體劃分為大小相同的兩塊,每次只使用其中的一塊,當這一塊記憶體滿了之后,將存活的物件復制到未使用的一塊中,然后把使用的那一塊一次清理,
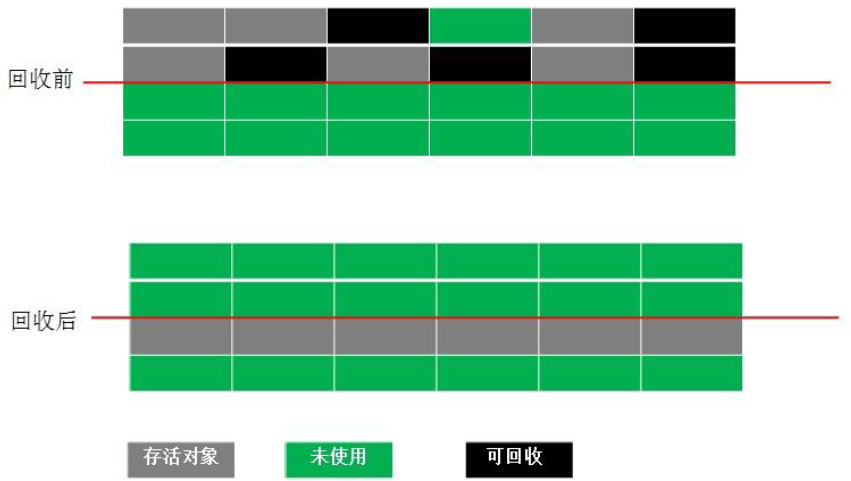
特點:不易產生記憶體隨便,但效率大大降低,
4.3 標記-整理演算法(Mark-Compact)
原理:首先標記出可以回收的物件,然后將存活物件移動至記憶體的一端,然后清除掉邊界外的物件,
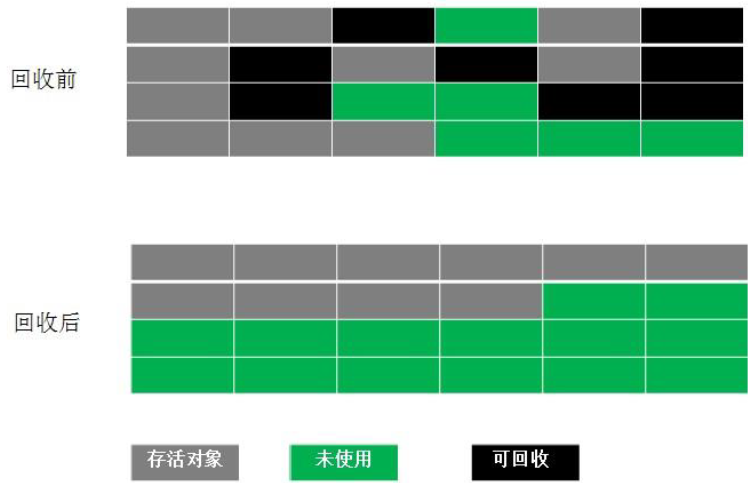
特點:根據老年代特點提出的一種標記演算法,
4.4 分代收集演算法
當前虛擬機的垃圾收集都采用分代收集演算法,
在新生代,每次收集都會有大量物件死去,所以采用復制演算法,只需復出少了物件的復制成本就可以完成每次垃圾收集,
在老年代,物件存活幾率比較高,每次垃圾回收是時只有少量物件需要被回收,因此采用標記-整理演算法進行垃圾收集,
5. 垃圾收集器
JVM針對新生代和老年代分別提供了不同的垃圾收集器,
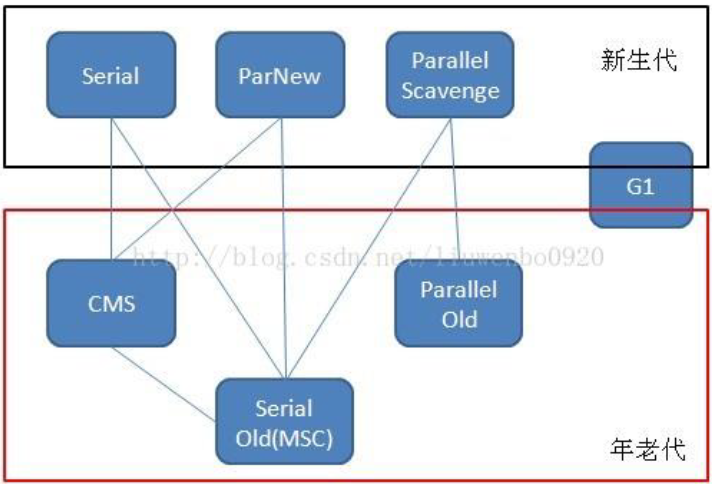
5.1 Serial收集器(單執行緒+復制演算法)
Serial收集器是最基本的垃圾收集器,Serial是單執行緒的收集器,只會使用一條垃圾收集執行緒去完成垃圾收集作業,同時在進行垃圾收集作業時不許暫停其他所有的作業執行緒("Stop the World"),直到收集結束,
新生代采用復制演算法,老年代采用標記-整理演算法,
Serial收集器簡單高效,對于限定單個CPU環境來說沒有執行緒互動的開銷,可以獲得最高的單執行緒垃圾收集效率,因此Serial垃圾收集器時JVM運行在Client模式下默認的新生代垃圾收集器,

5.2 ParNew收集器(Serial+多執行緒)
ParNew收集器是Serial收集器的多執行緒版本(多執行緒并發),除了使用多執行緒進行垃圾收集外,其余行為和Serial收集器完全一樣,
新生代采用復制演算法,老年代采用標記-整理演算法,
ParNew收集器是運行在Server模式下的JVM的首要選擇,除了Serial收集器,只有它能與CMS收集器配合作業,

5.3 Parallel Scavenge收集器
與ParNew收集器類似,但Parallel Scavenge收集器的關注點是吞吐量(高效率地利用CPU),CMS等垃圾收集器地關注點是用戶執行緒的停頓時間(提高用戶體驗),所謂吞吐量就是CPU中用于運行用戶代碼的時間與CPU總消耗時間的比值,
Parallel Scavenge提供了兩個引數用于精確控制吞吐量,分別是控制最大垃圾收集停頓時間的-XX: MaxGCPauseMillis引數以及直接設定吞吐量大小的-XX: GCTimeRatio引數,
5.4 Serial Old收集器(單執行緒+標記-整理演算法)
Serial收集器的老年代版本,它具有兩大用途:一種是在JDK1.5及以前的版本中與Parallel Scavenge收集器搭配使用,另一種是作為CMS收集器的后備方案,
5.5 Parallel Old收集器(多執行緒+標記-整理演算法)
Parallel Scavenge收集器的老年代版本,使用多執行緒和標記-整理演算法,在注重吞吐量和CPU資源的場合,可以優先考慮Parallel Scavenge收集器和Parallel Old收集器,
5.6 CMS收集器(多執行緒+標記-清除演算法)
CMS(Concurrent Mark Sweep)收集器是一種以獲取最短回收停頓時間為目標的收集器,非常符合在注重用戶體驗的應用上使用, CMS收集器是第一款真正意義上的并發收集器,第一次實作了讓垃圾回收執行緒與用戶執行緒(基本上)同時作業,CMS收集器是基于標記-清除演算法的,其運行程序包括四個步驟:

- 初始標記:暫停所有其他執行緒,并記錄下直接與GC Roots相連的物件,速度很快;
- 并發標記:同時開啟GC和用戶執行緒,用一個閉包結構去記錄可達物件,但在這個階段結束,這個閉包結構并不能保證包含當前所有的可達物件,因為用戶執行緒可能會不斷地更新參考域,所以GC執行緒無法保證可達性分析的實時性,因此這個演算法里會跟蹤記錄這些發生參考更新的地方,該階段無需暫停作業執行緒;
- 重新標記:重新標記階段就是為了修正并發標記期間因為用戶程式繼續運行而導致標記產生變動的那一部分物件的標記記錄,這個階段的停頓時間一般會比初始標記階段的時間稍長,遠遠比并發標記近階段的時間短,該階段仍需要暫停所有作業執行緒,;
- 并發清除:開啟用戶執行緒,同時GC執行緒開始清除GC Roots不可達物件,無需暫停作業執行緒,
優點:并發收集、低停頓,
缺點:對CPU資源敏感;無法處理浮動垃圾;使用的"標記-清除"會導致收集結束時產生大量記憶體碎片,
5.7 G1收集器
G1(Garbage First)是面向服務器的垃圾收集器,主要針對配備多核處理器及大容量記憶體的機器,以極高概率滿足GC停頓時間要求的同時還具備高吞吐量性能特征,
特點:
- 并行與并發
- 分代收集:可以獨立管理整個GC堆,但也保留了分代的概念;
- 空間整合:基于標記-整理演算法,不產生記憶體碎片;
- 可預測的停頓:相比于CMS,G1可以能建立可預測的停頓時間模型,在不犧牲吞吐量的前提下實作低停頓的垃圾回收,
G1收集器運行步驟大致分為:初始標記;并發標記;最終標記;篩選回收,
G1收集器避免全區域垃圾收集,把堆記憶體劃分為大小固定的幾個獨立區域,并且跟蹤這些區域的垃圾收集進度,同時在后臺維護一個優先級串列,每次根據所允許的收集時間,優先回收垃圾最多的區域,區域劃分和優先級區域回識訓制,確保G1收集器可以在有限時間獲得最高的垃圾收集效率,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/86677.html
標籤:Java
上一篇:基于注解的DI