背景
最近有個學弟找到我,跟我描述了以下場景:
他們公司內部管理系統上有很多報表,報表資料都有分頁顯示,瀏覽的時候速度還可以,但是每個報表在匯出時間視窗稍微大一點的資料時,就例外緩慢,有時候多人一起匯出時還會出現堆溢位,
他知道是因為資料全部加載到jvm記憶體導致的堆溢位,所以只能對時間視窗做了限制,以避免因匯出過資料過大而引起的堆溢位,最終拍腦袋定下個限制為:匯出的資料時間視窗不能超過1個月,
雖然問題解決了,但是運營小姐姐不開心了,跑過來和學弟說,我要匯出一年的資料,難道要我匯出12次再手工合并起來嗎,學弟心想,這也是,系統是為人服務的,不能為了解決問題而改變其本質,
所以他想問我的問題是:有沒有什么辦法可以從根本上解決這個問題,
所謂從根本上解決這個問題,他提出要達成2個條件
- 比較快的匯出速度
- 多人能并行下載資料集較大的資料
我聽完他的問題后,我想,他的這個問題估計很多其他童鞋在做web頁匯出資料的時候也肯定碰到過,很多人為了保持系統的穩定性,一般在匯出資料時都對匯出條數或者時間視窗作了限制,但需求方肯定更希望一次性匯出任意條件的資料集,
魚和熊掌能否兼得?
答案是可以的,
我堅定的和學弟說,大概7年前我做過一個下載中心的方案,20w資料的匯出大概4秒吧,,,支持多人同時在線匯出,,,
學弟聽完表情有些興奮,但是眉頭又一皺,說,能有這么快,20w資料4秒?
為了給他做例子,我翻出了7年前的代碼,,,花了一個晚上把核心代碼抽出來,剝離干凈,做成了一個下載中心的例子
超快下載方案演示
先不談技術,先看效果,(完整案例代碼文末提供)
資料庫為mysql(理論上此套方案支持任何結構化資料庫),準備一張測驗表t_person,表結構如下:
CREATE TABLE `t_person` (
`id` bigint(20) NOT NULL auto_increment,
`name` varchar(20) default NULL,
`age` int(11) default NULL,
`address` varchar(50) default NULL,
`mobile` varchar(20) default NULL,
`email` varchar(50) default NULL,
`company` varchar(50) default NULL,
`title` varchar(50) default NULL,
`create_time` datetime default NULL,
PRIMARY KEY (`id`)
);
一共9個欄位,我們先創建測驗資料,
案例代碼提供了一個簡單的頁面,點以下按鈕一次性可以創建5w條測驗資料:
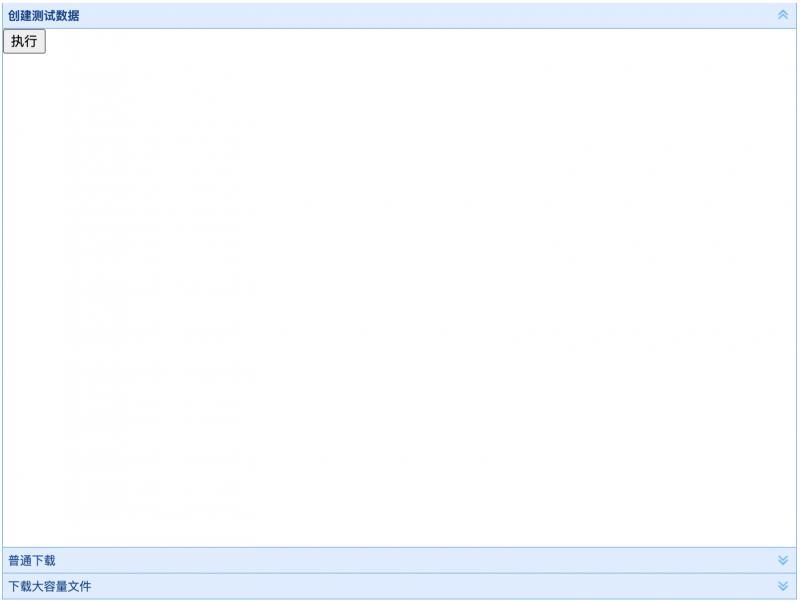
這里我連續點了4下,很快就生成了20w條資料,這里為了展示下資料的大致樣子,我直接跳轉到了最后一頁
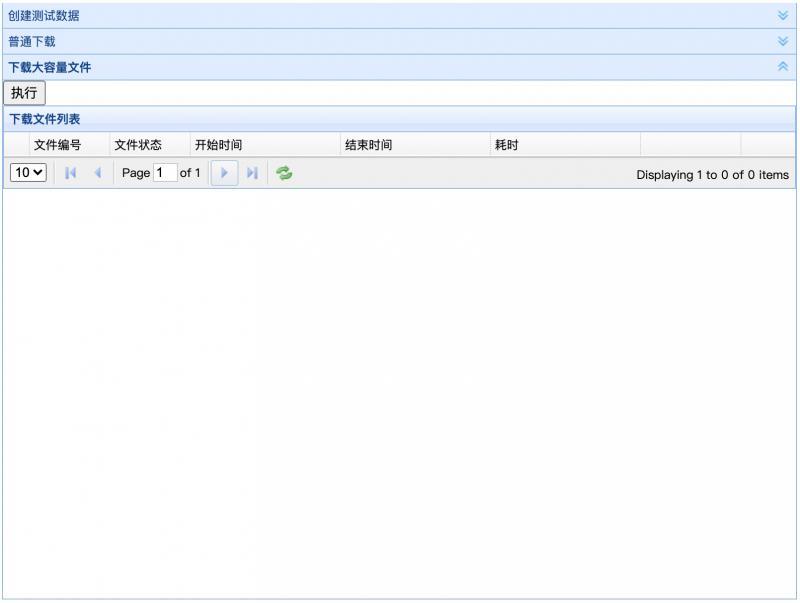
然后點開下載大容量檔案,點擊執行執行按鈕,開始下載t_person這張表里的全部資料
點擊執行按鈕之后,點下方重繪按鈕,可以看到一條異步下載記錄,狀態是P,表示pending狀態,不停重繪重繪按鈕,大概幾秒后,這一條記錄就變成S狀態了,表示Success
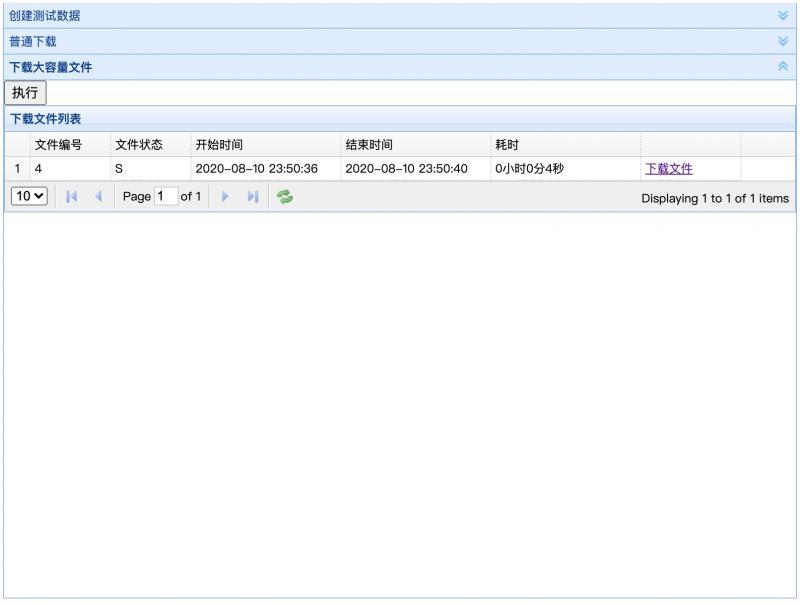
然后你就可以下載到本地,檔案大小大概31M左右

看到這里,很多童鞋要疑惑了,這下載下來是csv?csv其實是文本檔案,用excel打開會丟失格式和精度,這解決不了問題啊,我們要excel格式啊!!
其實稍微會一點excel技巧的童鞋,可以利用excel匯入資料這個功能,資料->匯入資料,根據提示一步步,當中只要選擇逗號分隔就可以了,關鍵列可以定義格式,10秒就能完成資料的匯入
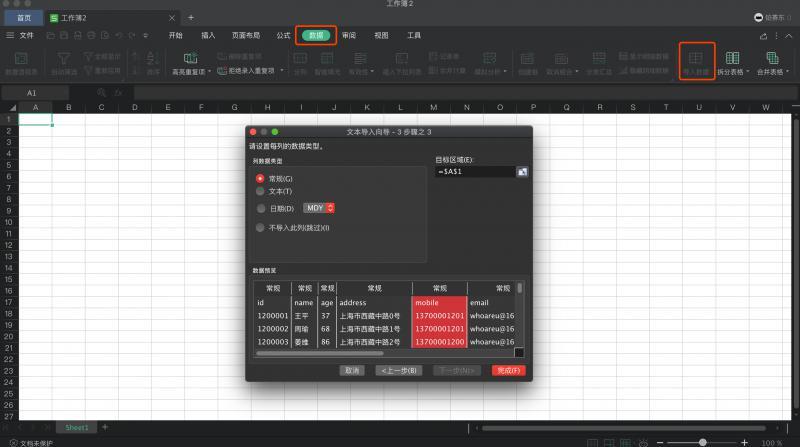
你只要告訴運營小姐姐,根據這個步驟來完成excel的匯入就可以了,而且下載過的檔案,還可以反復下,
是不是從本質上解決了下載大容量資料集的問題?
原理和核心代碼
學弟聽到這里,很興奮的說,這套方案能解決我這里的痛點,快和我說說原理,
其實這套方案核心很簡單,只源于一個知識點,活用JdbcTemplate的這個介面:
@Override
public void query(String sql, @Nullable Object[] args, RowCallbackHandler rch) throws DataAccessException {
query(sql, newArgPreparedStatementSetter(args), rch);
}
sql就是select * from t_person,RowCallbackHandler這個回呼介面是指每一條資料遍歷后要執行的回呼函式,現在貼出我自己的RowCallbackHandler的實作
private class CsvRowCallbackHandler implements RowCallbackHandler{
private PrintWriter pw;
public CsvRowCallbackHandler(PrintWriter pw){
this.pw = pw;
}
public void processRow(ResultSet rs) throws SQLException {
if (rs.isFirst()){
rs.setFetchSize(500);
for (int i = 0; i < rs.getMetaData().getColumnCount(); i++){
if (i == rs.getMetaData().getColumnCount() - 1){
this.writeToFile(pw, rs.getMetaData().getColumnName(i+1), true);
}else{
this.writeToFile(pw, rs.getMetaData().getColumnName(i+1), false);
}
}
}else{
for (int i = 0; i < rs.getMetaData().getColumnCount(); i++){
if (i == rs.getMetaData().getColumnCount() - 1){
this.writeToFile(pw, rs.getObject(i+1), true);
}else{
this.writeToFile(pw, rs.getObject(i+1), false);
}
}
}
pw.println();
}
private void writeToFile(PrintWriter pw, Object valueObj, boolean isLineEnd){
...
}
}
這個CsvRowCallbackHandler做的事就是每次從資料庫取出500條,然后寫入服務器上的本地檔案中,這樣,無論你這條sql查出來是20w潭訓是100w條,記憶體理論上只占用500條資料的存盤空間,等檔案寫完了,我們要做的,只是從服務器把這個生成好的檔案download到本地就可以了,
因為記憶體中不斷重繪的只有500條資料的容量,所以,即便多執行緒下載的環境下,記憶體也不會因此而溢位,這樣,完美解決了多人下載的場景,
當然,太多并行下載雖然不會對記憶體造成溢位,但是會大量占用IO資源,為此,我們還是要控制下多執行緒并行的數量,可以用執行緒池來提交作業
ExecutorService threadPool = Executors.newFixedThreadPool(5);
threadPool.submit(new Thread(){
@Override
public void run() {
下載大資料集代碼
}
}
最后測驗了下50w這樣子的person資料的下載,大概耗時9秒,100w的person資料,耗時19秒,這樣子的下載效率,應該可以滿足大部分公司的報表匯出需求吧,
最后
學弟拿到我的示例代碼后,經過一個禮拜的修改后,上線了頁面匯出的新版本,所有的報表提交異步作業,大家統一到下載中心去進行查看和下載檔案,完美的解決了之前的2個痛點,
但最后學弟還有個疑問,為什么不可以直接生成excel呢,也就是說在在RowCallbackHandler中持續往excel里寫入資料呢?
我的回答是:
1.文本檔案流寫入比較快
2.excel檔案格式好像不支持流持續寫入,反正我是沒有試成功過,
我把剝離出來的案例整理了下,無償提供給大家,希望幫助到碰到類似場景的童鞋們,
關注作者
關注公眾號「元人部落」回復”匯出案例“即可獲得以上完整的案例代碼,直接可以運行起來,頁面上輸入http://127.0.0.1:8080就可以打開文中案例的模擬頁面,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/86693.html
標籤:Java