必收藏的Java面試題
目錄
Java 面試題
一. 容器部分
二. 多執行緒部分
三. SpringMvc部分
四. Mybatis部分
五. MySQL部分
六. Redis部分
七. RabbitMQ部分
八. JVM虛擬機部分
九. 演算法知識部分
十. 其他面試部分
更新
- 時間:
2020/08/10- 內容: JVM虛擬機部分
- 預更: 演算法部分
容器部分面試題
Java 容器都有哪些
Collection的子類List、SetList的子類ArrayList、LinkedList等Set的子類HashSet、TreeSet等Map的子類HashMap、TreeMao等
Collecion 和 Collections 有什么區別
java.util,Collection是一個集合的頂級介面,它提供了對集合物件進行基本操作的通用介面方法,Collection 介面的意義是為各種具體的集合提供了最大化的統一操作方式,其直接繼承介面的有 List 和 Setjava.util.Collections是一個包裝類(工具類),它包含了各種有關集合操作的靜態多型方法,此類不能被實體化,用于對集合中元素進行排序、搜索以及執行緒安全等各種操作,服務于 Java 的 Collection 框架
List、Set、Map 之間的區別
- List、Set 都繼承 Collection 介面,而 Map 則不是
- List 是一個有序集合,元素可重復,可有多個NULL值,可以使用各種回圈遍歷集合,因為它是有序的
- Set 是一個無序集合,元素不可重復,重復元素會被覆寫掉(注意:元素雖然無放入順序,但元素在 Set 中的位置是由該元素的 HashCode 決定的,其位置是固定的,加入 Set 的 Object 必須定義
equals()方法),Set 只能用迭代,因為它是無序的- Map 是由一系列鍵值對組成的集合,提供了 key 和 value 的映射,在 Map 中保證 key 與 value 一一對應的關系,一個 key 對應一個 value ,不能存在相同的 key,但 value 可以相同
- Set 與 List 相比較
- Set 檢索元素效率較低,洗掉和插入效率高,因為洗掉和插入不會引起元素的位置變化
- List 可動態增長,查找元素效率高,但是洗掉和插入效率低,因為洗掉或插入一條元素,會引起其他元素位置變化
- Map 適合存盤鍵值對的資料
HashMap 和 HashTable 的區別
- 繼承的父類不同,但二者都實作了 Map介面
- HashTable 繼承自
Dictionary類- HashMap 繼承自
AbstractMap類
- 執行緒安全不同
- HashMap 在預設的情況下是非Synchronize的
- HashTable 的方法是Synchronize的
- 在多執行緒下直接使用 HashTable 不需要自己為它的方法實作同步,但使用 HashMap 時需要手動增加同步處理
Map m = Collections.synchronizeMap(hashMap);
- 是否提供 contains() 方法
- HashMap 把 HashTable 的 contains() 方法去掉了,改成了 containsValue() 和 containsKey(),因為 contains 容易讓人誤解
- HashTable 則保留了 contains()、containsValue()、containsKey() 三個方法,其中 contains() 與 containsValue() 功能相同
- key 和 value 是否可以為 null 值
- HashTable 中,key 和 value 都不能為 null 值
- HashMap 中,null 作為鍵,但這樣的鍵只有一個,可以有多個 value 為 null 值的鍵,當 get() 方式回傳 null 有可能是 HashMap 中沒有該鍵,也有可能回傳的 value 為 null,所以 HashMap 用
containsKey()方法判斷是否存在鍵
- 遍歷方式不同
- HashTable 與 HashMap 都是使用 Iterator 迭代器遍歷,而由于歷史的原因,HashTable 還使用了
Enumeration的方式
- hash 值不同
- 哈希值的使用不同,HashTable直接使用物件的HashCode,而 HashMap 重新計算哈希值
- hashCode是jdk根據物件的地址或者字串或者數字算出來的int型別的數值
- HashTable 使用的取模運算
- HashMap 使用的與運算,先用
hash & 0x7FFFFFFF后,再對 length 取模,&0x7FFFFFFF的目的是為了將負的 hash 值轉化為正值,因為 hash 值有可能為負數,而&0x7FFFFFFF后,只有符號外改變,而后面的位都不變
- 內部實作使用的陣列初始化和擴容方式不同
- HashTable 在不指定容量的情況下默認是11,而 HashMap 為16,HashTable 不要求底層陣列的容量一定要是2的整數次冪,而 HashMap 底層陣列則一定為2的整數次冪
- HashTable 擴容時,將容量變成原來的2倍+1 (old * 2 + 1),而 HashMap 則直接改為原來的2倍 (old * 2)
如何決定使用 HashMap 還是 TreeMap
- 如果需要得到一個有序的 Map 集合就應該使用 TreeMap (因為 HashMap 的排序順序不是固定的)除此之外,由于 HashMap 有比 TreeMap 更好的性能,在不需要使用排序的情況下使用 HashMap 會更好
HashMap 的實作原理
- 利用key的hashCode重新hash計算出當前物件的元素在陣列中的下標
存盤時,如果出現hash值相同的key,此時有兩種情況,(1)如果key相同,則覆寫原始值;(2)如果key不同(出現沖突),則將當前的key-value放入鏈表中
獲取時,直接找到hash值對應的下標,在進一步判斷key是否相同,從而找到對應值,
理解了以上程序就不難明白HashMap是如何解決hash沖突的問題,核心就是使用了陣列的存盤方式,然后將沖突的key的物件放入鏈表中,一旦發現沖突就在鏈表中做進一步的對比,
HashSet 的實作原理
- HashSet 實際上是一個
HashMap實體,都是一個存放鏈表的陣列,它不保證存盤元素的迭代順序;此類允許使用 null 元素,HashSet 中不允許有重復元素,這是因為 HashSet 是基于 HashMap 實作的,HashSet 中的元素都存放在 HashMap 的 key 上面,而 value 中的值都是統一的一個固定物件private static final Object PRESENT = new Object();- HashSet 中 add() 方法呼叫的是底層 HashMap 中的 put() 方法,而如果是在 HashMap 中呼叫 put() ,首先會判斷 key 是否存在,如果 key 存在則修改 value 值,如果 key 不存在這插入這個 key-value,而在 set 中,因為 value 值沒有用,也就不存在修改 value 值的說法,因此往 HashSet 中添加元素,首先判斷元素(也就是key)是否存在,如果不存在這插入,如果存在著不插入,這樣 HashSet 中就不存在重復值,所以判斷 key 是否存在就要重寫元素的類的 equals() 和 hashCode() 方法,當向 Set 中添加物件時,首先呼叫此物件所在類的 hashCode() 方法,計算次物件的哈希值,此哈希值決定了此物件在Set中存放的位置;若此位置沒有被存盤物件則直接存盤,若已有物件則通過物件所在類的 equals() 比較兩個物件是否相同,相同則不能被添加,
ArrayList 與 LinkList 的區別是什么
- AarrayList 是動態陣列構成 LinkList 是鏈表組成
- AarrayList 常用于經常查詢的集合,因為 LinkList 是線性存盤方式,需要移動指標從前往后查找
- LinkList 常用于新增和洗掉的集合,因為 ArrayList 是陣列構成,洗掉某個值會對下標影響,需要進行資料的移動
- AarrayList 自由度較低,需要手動設定固定的大小,但是它的操作比較方便的,①直接創建②添加物件③根據下標進行使用
- LinkList 自由度較高,能夠動態的隨陣列的資料量而變化
- ArrayList 主要開銷在List需要預留一定空間
- LinkList 主要開銷在需要存盤結點資訊以及結點指標資訊
如何實作陣列與 List 之間的轉換
- List to Array : 可以使用 List 的
toArray()方法,傳入一個陣列的型別例如Stirng[] strs = strList.toArray(new String[strList.size()]);- Array to List : 可以使用
java.util.Arrays的asList()方法 例如List<String> strList = Arrays.asList(strs);
ArrayList 與 Vector 的區別是什么
- ArrayList 是非執行緒安全的,而 Vector 使用了
Synchronized來實作執行緒同步的- ArrayList 在性能方面要優于 Vector
- ArrayList 和 Vector 都會根據實際情況來動態擴容的,不同的是 ArrayList 擴容到原大小的1.5倍,而 Vector 擴容到原大小的2倍
Array 與 ArrayList 有什么區別
- Array 是陣列,當定義陣列時,必須指定資料型別及陣列長度
- ArrayList 是動態陣列,長度可以動態改變,會自動擴容,不使用泛型的時候,可以添加不同型別元素
在 Queue 中 poll() 與 remove() 有什么區別
- poll() 和 remove() 都是從佇列頭洗掉一個元素,如果佇列元素為空,remove() 方法會拋出
NoSuchElementException例外,而 poll() 方法只會回傳 null
哪些集合類是執行緒安全的
- Vector :比 ArrayList 多了同步化機制(執行緒安全)
- HashTable :比 HashMap 多了執行緒安全
- ConcurrentHashMap :是一種高效但是執行緒安全的集合
- Stack :堆疊,繼承于 Vector 也是執行緒安全
迭代器 Iterator 是什么
Iterator是集合專用的遍歷方式Iterator<E> iterator(): 回傳此集合中元素的迭代器,通過集合的iterator()方法得到,所以Iterator是依賴于集合而存在的
Iterator 怎么使用 ? 有什么特點
Iterator 的使用方法
java.lang.Iterable介面被java.util.Collection介面繼承,java.util.Collection介面的iterator()方法回傳一個Iterator物件next()方法獲取集合中下一個元素hasNext()方法檢查集合中是否還有元素remove()方法將迭代器新回傳的元素洗掉
Iterator 的特點
- Iterator 遍歷集合程序中不允許執行緒對集合元素進行修改
- Iterator 遍歷集合程序中可以用
remove()方法來移除元素,移除的元素是上一次Iterator.next()回傳的元素- Iterator 的
next()方法是通過游標指向的形式回傳Iterator下一個元素
Iterator 與 LinkIterator 有什么區別
- 使用范圍不同
- Iterator 適用于所有集合, Set、List、Map以及這些集合的子型別,而 ListIterator 只適用于 List 及其子型別
- ListIterator 有 add() 方法,可以向 List 中添加元素,而 Iterator 不能
- ListIterator 和 Iterator 都有 hasNext() 和 next() 方法,來實作順序向后遍歷,而 ListIterator 有 hasPrevious() 和 previous() 方法,可以實作逆向遍歷,但是 Iterator 不能
- ListIterator 可以使用 nextIdnex() 和 previousIndex() 方法定位到當前索引位置,而 Iterator 不能
- 它們都可以實作 remove() 洗掉操作,但是 ListIterator 可以使用 set() 方法實作物件修改,而 Iterator 不能
怎么確保一個集合不能被修改
- 可以采用
java.util.Collections工具類Collections.unmodifiableMap(map)Collections.unmodifiableList(list)Collections.unmodifiableSet(set)- 如諾修改則會報錯
java.lang.UnsupportedOperationException
多執行緒部分面試題
并發和并行有什么區別
- 并發:不同的代碼塊交替執行
- 并行:不同的代碼塊同時執行
- 個人理解
- 并發就是放下手頭的任務A去執行另外一個任務B,執行完任務B后,再回來執行任務A,就比如說吃飯時來電話了,去接電話,打完電話后又回來吃飯
- 并行就是執行A的同時,接受到任務B,然后我一起執行,就比如說吃飯時來電話了,一邊吃飯一邊打電話
執行緒和行程的區別
- 根本區別 :行程是作業系統資源分配的基本單位,而執行緒是任務調度和執行的基本單位
- 在作業系統中能同時運行多個行程,行程中會執行多個執行緒
- 執行緒是作業系統能夠進行運算調度的最小單位
守護執行緒是什么
- JVM內部的實作是如果運行的程式只剩下守護執行緒的話,程式將終止運行,直接結束,所以守護執行緒是作為輔助執行緒存在的
創建執行緒有哪幾種方式
- 繼承Thread類創建執行緒類
- 定義
Thread類的子類,并重寫該類的run()方法- 創建
Thread子類的實體,即創建了執行緒物件- 呼叫執行緒物件的
start()方法來啟動該執行緒
- 實作Runnable介面創建執行緒類
- 創建
runnable介面的實作類,并重寫該介面的run()方法- 創建
Runnable實作類的實體,并依此實體作為Thread的target來創建Thread物件,該Thread物件才是真正的執行緒物件- 呼叫執行緒物件的
start()方法來啟動該執行緒
- 通過 Callable 和 Future 創建執行緒
- 創建
Callable介面的實作類,并重寫call()方法,該call()方法將作為執行緒執行體,并且有回傳值- 創建
Callable實作類的實體,使用FutureTask類來包裝Callable物件,該FutureTask物件封裝了該Callable物件的call()方法的回傳值- 使用
FutureTask物件作為Thread物件的target創建并啟動新執行緒- 呼叫
FutureTask物件的get()方法來獲得子執行緒執行結束后的回傳值
runnable 和 callable 有什么區別
- 相同點
- 都是介面
- 都可以撰寫多執行緒程式
- 都是采用
Thread.start()啟動執行緒
- 不同點
Runnable沒有回傳值,Callable可以回傳執行結果,是個泛型和Future、FutureTask配合可以用來獲取異步執行的結果Callable介面的call()方法允許拋出例外,Runnable的run()方法例外只能在內部消化,不能往上繼續拋注意
Callalble介面支持回傳執行結果,需要呼叫FutureTask.get()得到,此方法會阻塞主行程的繼續往下執行,如果不呼叫不會阻塞
執行緒有哪些狀態
- 新建 就緒 運行 阻塞 死亡
sleep() 和 wait() 的區別
- 最大區別是sleep() 休眠時不釋放同步物件鎖,其他執行緒無法訪問 而wait()休眠時,釋放同步物件鎖其他執行緒可以訪問
- sleep() 執行完后會自動恢復運行不需要其他執行緒喚起.而 wait() 執行后會放棄物件的使用權,其他執行緒可以訪問到,需要其他執行緒呼叫 Monitor.Pulse() 或者 Monitor.PulseAll() 來喚醒或者通知等待佇列
執行緒的 run() 和 start() 的區別
- start() 是來啟動執行緒的
- run() 只是 Thread 類中一個普通方法,還是在主執行緒中執行
notify() 和 notifyAll() 有什么區別
notify()方法隨機喚醒物件的等待池中的一個執行緒,進入鎖池notifyAll()喚醒物件的等待池中的所有執行緒,進入鎖池,
創建執行緒池有哪幾種方式
- 利用
Executors創建執行緒池
newCachedThreadPool(),它是用來處理大量短時間作業任務的執行緒池newFixedThreadPool(int nThreads),重用指定數目nThreads的執行緒newSingleThreadExecutor(),它的特點在于作業執行緒數目限制為1newSingleThreadScheduledExecutor()和newScheduledThreadPool(int corePoolSize),創建的是個ScheduledExecutorService,可以進行定時或周期性的作業調度,區別在于單一作業執行緒還是多個作業執行緒,newWorkStealingPool(int parallelism),這是一個經常被人忽略的執行緒池,Java 8才加入這個創建方法,其內部會構建ForkJoinPool,利用Work-Stealing演算法,并行地處理任務,不保證處理順序
執行緒池都有哪些狀態
- 運行 RUNNING:執行緒池一旦被創建,就處于
RUNNING狀態,任務數為 0,能夠接收新任務,對已排隊的任務進行處理- 關閉 SHUTDOWN:不接收新任務,但能處理已排隊的任務,呼叫執行緒池的
shutdown()方法,執行緒池由RUNNING轉變為SHUTDOWN狀態- 停止 STOP:不接收新任務,不處理已排隊的任務,并且會中斷正在處理的任務,呼叫執行緒池的
shutdownNow()方法,執行緒池由(RUNNING或SHUTDOWN) 轉變為STOP狀態- 整理 TIDYING:
SHUTDOWN狀態下,任務數為 0, 其他所有任務已終止,執行緒池會變為 TIDYING 狀態,會執行terminated()方法,執行緒池中的terminated()方法是空實作,可以重寫該方法進行相應的處理- 執行緒池在
SHUTDOWN狀態,任務佇列為空且執行中任務為空,執行緒池就會由 SHUTDOWN 轉變為TIDYING狀態- 執行緒池在
STOP狀態,執行緒池中執行中任務為空時,就會由STOP轉變為TIDYING狀態
- 終止 TERMINATED:執行緒池徹底終止,執行緒池在 TIDYING 狀態執行完 terminated() 方法就會由 TIDYING 轉變為
TERMINATED狀態
執行緒池中的 submit() 和 execute() 有什么區別
- 兩個方法都可以向執行緒池提交任務
execute()方法的回傳型別是void,它定義在Executor介面中- 而
submit()方法可以回傳持有計算結果的Future物件,它定義在ExecutorService介面中
在Java程式中怎么確保多執行緒運行安全
- 使用synchronied關鍵字
- 使用volatile 關鍵字,防止指令重排,所有對該變數讀寫都是直接操作共享記憶體
- lock鎖機制
lock()與unlock()- 使用執行緒安全的類 比如
StringBuffer、HashTable、Vector等執行緒安全問題主要是:原子性,可見性,有序性
synchronized 和 volatile 的作用什么?有什么區別
- 作用
- synchronized 表示只有一個執行緒可以獲取作用物件的鎖,執行代碼,阻塞其他執行緒
- volatile 表示變數在
CPU的暫存器中是不確定的,必須從主存中讀取,保證多執行緒環境下變數的可見性,禁止指令重排序
- 區別
synchronized可以作用于變數、方法、物件,volatile只能作用于變數synchronized可以保證執行緒間的有序性、原子性和可見性,volatile只保證了可見性和有序性,無法保證原子性synchronized執行緒阻塞,volatile執行緒不阻塞
synchronized 和 Lock 有什么區別
synchronized是一個Java關鍵字,在jvm層面上,而Lock是一個類synchronized以獲取鎖的執行緒執行完同步代碼,釋放鎖,如果執行緒中發生例外,jvm會讓執行緒釋放鎖,而Lock必須在finally中釋放鎖,否則容易造成執行緒死鎖Lock可以查看鎖的狀態,而synchronized不能- 在性能上來說,如果競爭資源不激烈,兩者的性能是差不多的,而當競爭資源非常激烈時(即有大量執行緒同時競爭),此時
Lock的性能要遠遠優于synchronized,所以說,在具體使用時要根據適當情況選擇synchronized是非公平鎖,而Lock是可公平鎖
Spring Mvc面試題部分
為什么要是使用 Spring
- 輕量
非侵入型框架- 控制反轉
IOC,促進了松耦合- 面向切面編程
AOP- 容器 采用Java Bean 代替 沉重的
EJB容器- 方便集成 可以和很多框架相互集成如
Mybatis、Shiro- 豐富的功能 Spring 已經寫好了很多常的模板如
JDBC抽象類、事務管理、JMS、JMX、Web Service...等
解釋一下什么是 aop
AOP是面向切面編程,是OOP編程的有效補充AOP包括Aspect切面,Join Point連接點,Advice通知,Ponitcut切點其中
Advice通知包括5中模式
Before advice:方法執行前‘增強’After returning advice:方法執行后‘增強’After throwing advice:方法執行中拋出例外時‘增強’After finally advice:方法執行完后‘增強’Around advice:環繞增強‘以上四種的整合’
解釋一下什么是 ioc
- IOC是控制反轉,是將代碼本身的控制權移到外部Spring容器中進行集中管理,也是為了達到松耦合
Spring 主要有哪些模塊
- Spring Core
- 框架基礎部分,提供了
IOC容器,對Bean進行集中管理
- Spring Context
- 基于
Bean,提供背景關系資訊
- Spring Dao
- 提供了
JDBC的抽象層,它可消除冗長的JDBC編碼,提供了宣告性事務管理方法
- Spring ORM
- 提供了
物件/關系映射常用的API集成層,如Mybatis、Hibernate等
- Spring Aop
- 提供了
AOP面向切面的編程實作
- Spring Web
- 提供了
Web開發的資訊背景關系,可與其他的Web集成開發
- Spring Web Mvc
- 提供了
Web應用的Model - View - Controller全功能的實作
Spring 常用的注入方式有哪些
- 構造方法注入
- Setter方法注入
不過值得一提的是:Setter注入時如果寫了帶參構造方法,那么無參構造方法必須也要寫上,否則注入失敗
- 基于注解得注入
基本上有五種常用注冊
Bean的注解
@Component:通用注解@Controller:注冊控制層Bean@Service:注冊服務層Bean@Repository:注冊Dao層Bean@Configuration:注冊配置類
Spring 中的 bean 是執行緒安全的嗎
- 執行緒不安全
- Spring容器中的Bean是否執行緒安全,容器本身并沒有提供Bean的執行緒安全策略,因此可以說Spring容器中的Bean本身不具備執行緒安全的特性
Spring 支持幾種 bean 的作用域
singleton:單例,默認的作用域prototype:原型,每次都會創建新物件request:請求,每次Http請求都會創建一個新物件session:會話,同一個會話創建一個實體,不同會話使用不同實體global-session:全域會話,所有會話共享一個實體
- 后面三種只有在Web應用中使用Spring才有效
Spring 自動裝配 bean 有哪些方式
Spring 事務實作方式有哪些
- 編程式事務管理對基于
POJO的應用來說是唯一選擇,我們需要在代碼中呼叫beginTransaction()、commit()、rollback()等事務管理相關的方法,這就是編程式事務管理- 基于 TransactionProxyFactoryBean的宣告式事務管理
- 基于 @Transactional 的宣告式事務管理
- 基于Aspectj AOP配置事務
Spring 的事務隔離是什么
Spring Mvc 的運行流程
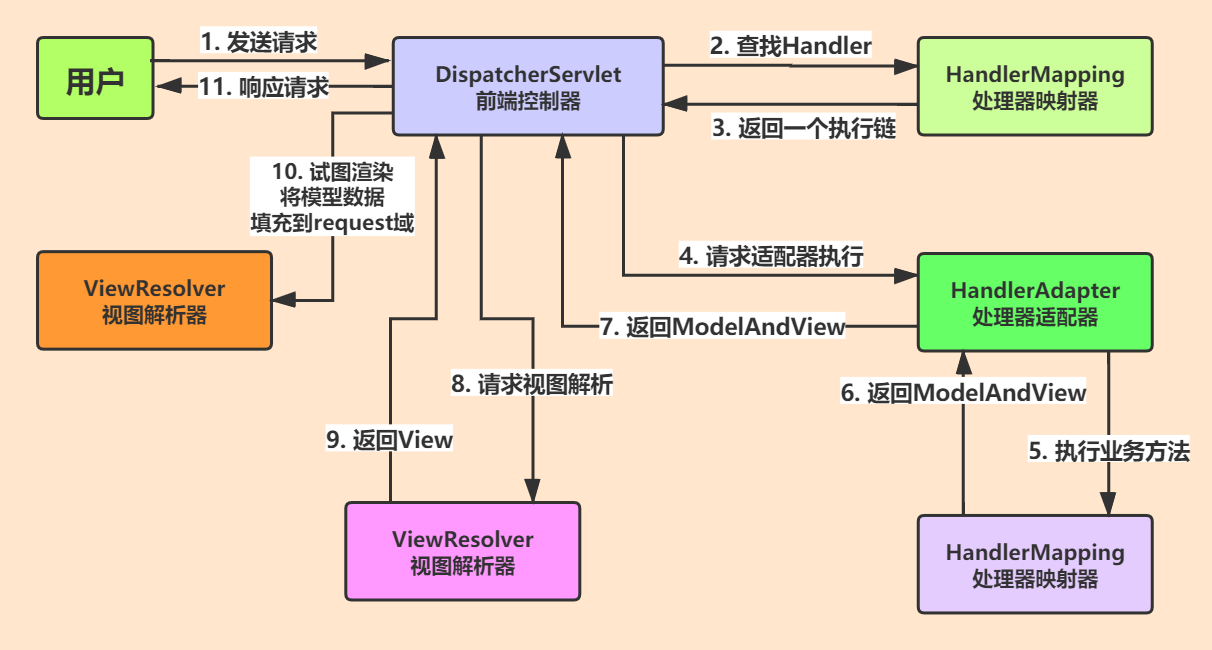
- 用戶發送一個請求至前端控制器
DispatcherServletDispatcherServlet收到請求呼叫處理器映射器HandlerMapping- 處理器映射器根據請求
url找到具體的處理器,生成處理器執行鏈HandlerExecutionChain(包括處理器物件和處理器攔截器)一并回傳給DispatcherServletDispatcherServlet根據處理器Handler獲取處理器配接器HandlerAdapter執行HandlerAdapter處理一系列的操作- 執行處理器
Handler(Controller,也叫頁面控制器)Handler執行完成回傳ModelAndView到HandlerAdapterHandlerAdapter將Handler執行結果ModelAndView回傳到DispatcherServletDispatcherServlet``將ModelAndView傳給ViewReslover視圖決議器ViewReslover決議后回傳具體ViewDispatcherServlet對View進行渲染視圖(即將模型資料model填充至視圖中)DispatcherServlet回應用戶
Spring Mvc 有哪些組件
DispatcherServlet:前端控制器HandlerMapping:處理器映射器HandlerAdapter:處理器配接器HandlerInterceptor:攔截器ViewResolver:視圖決議器MultipartResolver:檔案上傳處理器HandlerExceptionResolver:例外處理器DataBinder:資料轉換HttpMessageConverter:訊息轉換器FlashMapManager:頁面跳轉引數管理器HandlerExecutionChain:處理程式執行鏈RequestToViewNameTranslator:請求轉視圖翻譯器ThemeResolver:LocaleResolver:語言環境處理器
@RequestMapping 的作用是什么
@RequestMapping是一個注解,用來標識http請求地址與Controller類的方法之間的映射- 指定 http 請求的型別使用
GET, HEAD, POST, PUT, PATCH, DELETE, OPTIONS, TRACE
@Autowired 與 @Resource 的區別
@Autowired為Spring提供的注解,需要匯入包org.springframework.beans.factory.annotation.Autowired,采取的策略為按照型別注入@Resource注解由J2EE提供,需要匯入包javax.annotation.Resource,默認按照ByName自動注入
Mybatis部分面試題
Mybatis 中 #{} 和 ${} 的區別
- #{} 表示一個占位符
可以有效的防止SQL注入
- ${} 表示拼接SQL串
可以用于動態判斷欄位
order by ${field} desc可以動態修改fieId來達到動態根據欄位降序查詢
Mybatis 有幾種分頁方式
- 原始分割
取出資料后,進行手動分割
- LIMIT關鍵字
修改執行SQL陳述句
- RowBounds實作分頁
將
PageInfo資訊封裝成RowBounds,呼叫DAO層方法
- Mybatis的Interceptor實作
原理就是執行SQL陳述句前,在原SQL陳述句后加上limit關鍵字,不用自己去手動添加
RowBounds 是一次性查詢全部結果嗎?為什么
RowBounds表面是在“所有”資料中檢索資料,其實并非是一次性查詢出所有資料,因為 MyBatis 是對 jdbc 的封裝,在 jdbc 驅動中有一個 Fetch Size 的配置,它規定了每次最多從資料庫查詢多少條資料,假如你要查詢更多資料,它會在你執行 next()的時候,去查詢更多的資料,就好比你去自動取款機取 10000 元,但取款機每次最多能取 2500 元,所以你要取 4 次才能把錢取完,只是對于 jdbc 來說,當你呼叫 next()的時候會自動幫你完成查詢作業,這樣做的好處可以有效的防止記憶體溢位,
Mybatis 邏輯分頁和物理分頁的區別是什么
- 邏輯分頁是一次性查詢很多資料,然后再在結果中檢索分頁的資料,這樣做弊端是需要消耗大量的記憶體、有記憶體溢位的風險、對資料庫壓力較大,
- 物理分頁是從資料庫查詢指定條數的資料,彌補了一次性全部查出的所有資料的種種缺點,比如需要大量的記憶體,對資料庫查詢壓力較大等問題
Myabtis 是否支持延遲加載,延遲加載的原理是什么
- MyBatis 支持延遲加載,設定
lazyLoadingEnabled=true即可- 延遲加載的原理的是呼叫的時候觸發加載,而不是在初始化的時候就加載資訊,比如呼叫
a.getB().getName(),這個時候發現a.getB()的值為null,此時會單獨觸發事先保存好的關聯 B 物件的 SQL,先查詢出來 B,然后再呼叫a.setB(b),而這時候再呼叫a.getB(). getName()就有值了,這就是延遲加載的基本原理
Mybatis 一級快取和二級快取
- 一級快取
- 基于
PerpetualCache的HashMap本地快取,它的宣告周期是和SQLSession一致的,有多個SQLSession或者分布式的環境中資料庫操作,可能會出現臟資料- 當
Session flush或close之后,該Sessio中的所有Cache就將清空,默認一級快取是開啟的
- 二級快取
- 也是基于
PerpetualCache的HashMap本地快取,不同在于其存盤作用域為Mapper級別的,如果多個SQLSession之間需要共享快取,則需要使用到二級快取- 二級快取可自定義存盤源,如 Ehcache,默認不打開二級快取,要開啟二級快取,使用二級快取屬性類需要實作
Serializable序列化介面(可用來保存物件的狀態)
- 擴展
- 開啟二級快取后的查詢流程:
二級快取 -> 一級快取 -> 資料庫- 快取更新機制:當某一個作用域(一級快取 Session/二級快取 Mapper)進行了C/U/D 操作后,默認該作用域下所有 select 中的快取將被 clear
Mybatis 和 Hibernate 有哪些區別
- Mybatis 更加靈活,可以自己寫SQL陳述句
- 也正是自己寫了很多SQL陳述句,所以移植性比較差
- Mybatis 入門比較簡單,使用門檻也低
- hibernate 可以自行把二級快取更換為第三方的
Mybatis 有哪些執行器
SimpleExecutor:每執行一次UPDATE\SELECT就開啟一個Statement物件,用完后立即關閉ReuseExecutor:執行 UPDATE\SELECT,以 SQL 作為 key 查找Statement物件,存在就使用,不存在就創建,用完后不關閉Statement物件,而是放置于 Map 內供下一次使用,簡言之,就是重復使用Statement`物件BatchExecutor:執行UPDATE(沒有 select,jdbc 批處理不支持 select),將所有 SQL 都添加到批處理中addBatch(),等待統一執行executeBatch(),它快取了多個Statement物件,每個Statement物件都是addBatch()完畢后,等待逐一執行executeBatch()批處理,與 jdbc 批處理相同
Mybatis 分頁插件的實作原理是什么
- 分頁插件的基本原理是使用 MyBatis 提供的插件介面,實作自定義插件,在插件的攔截方法內攔截待執行的 SQL,然后重寫 SQL,根據 dialect 方言,添加對應的物理分頁陳述句和物理分頁引數
Mybatis 如何撰寫一個自定義插件
MyBatis 自定義插件針對 MyBatis 四大物件(Executor、StatementHandler、ParameterHandler、ResultSetHandler)進行攔截
- Executor:攔截內部執行器,它負責呼叫 StatementHandler 操作資料庫,并把結果集通過 ResultSetHandler 進行自動映射,另外它還處理了二級快取的操作
. StatementHandler:攔截 SQL 語法構建的處理,它是 MyBatis 直接和資料庫執行 SQL 腳本的物件,另外它也實作了 MyBatis 的一級快取- ParameterHandler:攔截引數的處理
- ResultSetHandler:攔截結果集的處理
MyBatis 插件要實作 Interceptor 介面
- setProperties 方法是在 MyBatis 進行配置插件的時候可以配置自定義相關屬性,即:介面實作物件的引數配置
- plugin 方法是插件用于封裝目標物件的,通過該方法我們可以回傳目標物件本身,也可以回傳一個它的代理,可以決定是否要進行攔截進而決定要回傳一個什么樣的目標物件,官方提供了示例:return Plugin. wrap(target, this)
- intercept 方法就是要進行攔截的時候要執行的方法
public interface Interceptor {
Object intercept(Invocation invocation) throws Throwable;
Object plugin(Object target);
void setProperties(Properties properties);
}
官方插件實作:
@Intercepts({@Signature(type = Executor. class, method = "query",
args = {MappedStatement. class, Object. class, RowBounds. class, ResultHandler. class})})
public class TestInterceptor implements Interceptor {
public Object intercept(Invocation invocation) throws Throwable {
Object target = invocation. getTarget(); //被代理物件
Method method = invocation. getMethod(); //代理方法
Object[] args = invocation. getArgs(); //方法引數
// do something . . . . . . 方法攔截前執行代碼塊
Object result = invocation. proceed();
// do something . . . . . . . 方法攔截后執行代碼塊
return result;
}
public Object plugin(Object target) {
return Plugin. wrap(target, this);
}
}
具體案例請看 Mybatis 實作自定義插件 通俗易懂
MySQL部分面試題
資料庫的三范式是什么
- 第一范式:又稱1NF,它指的bai是在一個應du用中的資料都可以組織zhi成由行和列的表格形式,且表格的任意一dao個行列交叉點即單元格,都不可再劃分為行和列的形式,實際上任意一張表格都滿足1NF
- 第二范式:又稱2NF,它指的是在滿足1NF的基礎上,一張資料表中的任何非主鍵欄位都全部依賴于主鍵欄位,沒有任何非主鍵欄位只依賴于主鍵欄位的一部分,即,可以由主鍵欄位來唯一的確定一條記錄,比如學號+課程號的聯合主鍵,可以唯一的確定某個成績是哪個學員的哪門課的成績,缺少學號或者缺少課程號,都不能確定成績的意義
- 第三范式:又稱3NF,它是指在滿足2NF的基礎上,資料表的任何非主鍵欄位之間都不產生函式依賴,即非主鍵欄位之間沒有依賴關系,全部只依賴于主鍵欄位,例如將學員姓名和所屬班級名稱放在同一張表中是不科學的,因為學員依賴于班級,可將學員資訊和班級資訊單獨存放,以滿足3NF
如何獲取當前資料庫的版本
- 進入MySQL輸入
select version();- 進入cmd輸入
mysql -V
說一下 ACID 是什么
- ACID,是指在可靠資料庫管理系統(DBMS)中,事務(transaction)所應該具有的四個特性:
原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、持久性(Durability)
- 原子性:意味著資料庫中的事務執行是作為原子,即不可再分,整個陳述句要么執行,要么不執行
- 一致性:即在事務開始之前和事務結束以后,資料庫的完整性約束沒有被破壞
- 隔離性:事務的執行是互不干擾的,一個事務不可能看到其他事務運行時,中間某一時刻的資料
- 持久性,意味著在事務完成以后,該事務所對資料庫所作的更改便持久的保存在資料庫之中,并不會被回滾
char 和 varchar 的區別
- 長度不同
- char 長度設定后不可變
- varchar 長度可動態改變
- 效率不同
- char 型別每次修改的資料長度相同,效率更高
- varchar 型別每次修改的資料長度不同,效率更低
- 存盤不同
- char 型別存盤的時候是初始預計字串再加上一個記錄字串長度的位元組,占用空間較大
- varchar 型別存盤的時候是實際字串再加上一個記錄字串長度的位元組,占用空間較小
float 和 double 的區別
- 在資料庫中的所有計算都是使用雙精度完成的,使用float(單精度)會有誤差,出現意想不到的結果
- MySQL浮點型和定點型可以用型別名稱后加(M,D)來表示,M表示該值的總共長度,D表示小數點后面的長度,M和D又稱為精度和標度,如float(7,4)的可顯示為-999.9999,MySQL保存值時進行四舍五入,如果插入999.00009,則結果為999.0001,FLOAT和DOUBLE在不指定精度時,默認會按照實際的精度來顯示,而DECIMAL在不指定精度時,默認整數為10,小數為0
MySQL 內連接、左連接、右連接有什么區別
inner join ... on內連接:只顯示兩表中有關聯的資料left join ... on左連接:顯示左表所有資料,右表沒有對應的資料用NULL補齊,多了的資料洗掉right join ... on右連接:顯示右表所有資料,左表沒有對應的資料用NULL對齊,多了的資料洗掉
MySQL 的索引是怎么實作的
- 由于B+Tree資料結構的優勢,目前mysql基本都采用B+Tree方式實作索引
- MySQL索引實作的資料結構:兩種存盤引擎都使用B+Tree(B-Tree的變種)作為索引結構
- MyISAM索引葉子節點存放的是資料的地址,主鍵索引與輔助索引除了值得唯一性在結構上完全一樣,InnoDB索引葉子節點存放的內容因索引型別不同而不同,主鍵索引葉子節點存放的是資料本身,輔助索引葉子節點上存放的是主鍵值
MySQL 索引設計原則
- 適合索引的列是出現在where子句中的列,或者連接子句中指定的列
- 基數較小的類,索引效果較差,沒有必要在此列建立索引
- 使用短索引,如果對長字串列進行索引,應該指定一個前綴長度,這樣能夠節省大量索引空間
- 不要過度索引,索引需要額外的磁盤空間,并降低寫操作的性能,在修改表內容的時候,索引會進行更新甚至重構,索引列越多,這個時間就會越長,所以只保持需要的索引有利于查詢即可
怎么驗證 MySQL 的索引是否滿足需求
- 使用explain函式驗證索引是否有效
事務的隔離級別
- Read uncommitted (讀未提交):最低級別
- Read committed (讀已提交):讀已提交,可避免臟讀情況發生,
- Repeatable Read(可重復讀):確保事務可以多次從一個欄位中讀取相同的值,在此事務持續期間,禁止其他事務對此欄位的更新,可以避免臟讀和不可重復讀,仍會出現幻讀問題
- Serializable (串行化):最嚴格的事務隔離級別,要求所有事務被串行執行,不能并發執行,可避免臟讀、不可重復讀、幻讀情況的發生
MySQL 常用的引擎
InnoDB 和 Myisam 都是用 B+Tree 來存盤資料的
- InnoDB 支持事務,且支持四種隔離級別(讀未提交、讀已提交、可重復讀、串行化),默認的為可重復讀.
- Myisam 只支持表鎖,且不支持事務.Myisam 由于有單獨的索引檔案,在讀取資料方面的性能很高.
MySQL 的行鎖、表鎖、頁鎖
- 行級鎖
是Mysql中鎖定粒度最細的一種鎖,表示只針對當前操作的行進行加鎖,行級鎖能大大減少資料庫操作的沖突,其加鎖粒度最小,但加鎖的開銷也最大,行級鎖分為共享鎖 和 排他鎖,
- 行級鎖的特點
開銷大,加鎖慢;會出現死鎖;鎖定粒度最小,發生鎖沖突的概率最低,并發度也最高,
- 表級鎖
表級鎖是MySQL中鎖定粒度最大的一種鎖,表示對當前操作的整張表加鎖,它實作簡單,資源消耗較少,被大部分MySQL引擎支持,最常使用的MYISAM與INNODB都支持表級鎖定,表級鎖定分為表共享讀鎖(共享鎖)與表獨占寫鎖(排他鎖)
- 表級鎖的特點
開銷小,加鎖快;不會出現死鎖;鎖定粒度大,發出鎖沖突的概率最高,并發度最低,
- 頁級鎖
頁級鎖是MySQL中鎖定粒度介于行級鎖和表級鎖中間的一種鎖,表級鎖速度快,但沖突多,行級沖突少,但速度慢,所以取了折衷的頁級,一次鎖定相鄰的一組記錄,BDB支持頁級鎖
- 頁級鎖的特點
開銷和加鎖時間界于表鎖和行鎖之間;會出現死鎖;鎖定粒度界于表鎖和行鎖之間,并發度一般
- 擴展
- MyISAM和MEMORY采用表級鎖(tabl-level locking)
- BDB采用頁面鎖(page-level locking)或表級鎖,默認為頁面鎖
- InnoDB支持行級鎖(row-level locking)和表級鎖,默認為行級鎖
樂觀鎖和悲觀鎖
- 樂觀鎖認為一般情況下資料不會造成沖突,所以在資料進行提交更新時才會對資料的沖突與否進行檢測,如果沒有沖突那就OK;如果出現沖突了,則回傳錯誤資訊并讓用戶決定如何去做.常見的做法有兩種:版本號控制及時間戳控制
- 悲觀鎖,正如其名,它指的是對資料被外界(包括當前系統的其它事務,以及來自外部系統的事務處理)修改持保守態度,因此,在整個資料處理程序中,將資料處于鎖定狀態,悲觀鎖的實作,往往依靠資料庫提供的鎖機制(也只有資料庫層提供的鎖機制才能真正保證資料訪問的排它性,否則,即使在本系統中實作了加鎖機制,也無法保證外部系統不會修改資料)常見做法:
select ... for update悲觀鎖語法鎖住記錄 兩個事務同時修改的話,事務A先執行事務B就會被阻塞,事務A執行update完后,事務B就會看到事務A執行完后更新的結果
MySQL 問題排查都有哪些手段
- 使用 show processlist 命令查看當前所有連接資訊
- 使用 explain 命令查詢 SQL 陳述句執行計劃
- 開啟慢查詢日志,查看慢查詢的 SQL
如何做 MySQL 的性能優化
- 創建索引 盡量避免全盤掃描 首先考慮在 where 和 order by 涉及的列上創建索引
- 避免在索引上使用計算 注意就是IN關鍵字不走索引,它是走全盤掃描
- 使用預編譯防止 sql 注入
- 盡量將多條 SQL陳述句壓縮到一條 SQL 陳述句中
- 最最最好的就是少用 * , 應該寫成要查詢的欄位名,盡量避免在 where 條件中判斷 null
- 盡量不用like 的前置百分比
- 對于連續的數值,能用 between 就不要用 in
- 在新建臨時表時,如果一次性插入資料量較大.可以用 select into 代替 create table
- 選擇正確的存盤引擎
- 垂直/水平分割、分庫分表、讀寫分離
Redis部分面試題
Redis 是什么?有什么優點?都有哪些使用場景
- Reids 是完全開源免費的,用C語言撰寫的,遵守BSD協議,
是一個高性能的(key/value)分布式記憶體資料庫,基于記憶體運行
并支持持久化的NoSQL資料庫,是當前最熱門的NoSql資料庫之一,
也被人們稱為資料結構服務器- 優點
- Redis支持資料的持久化,可以將記憶體中的資料保持在磁盤中,重啟的時候可以再次加載進行使用
- Redis不僅僅支持簡單的key-value型別的資料,同時還提供list,set,zset,hash等資料結構的存盤
- Redis支持資料的備份,即master-slave模式的資料備份
- 應用場景
- 記憶體存盤和持久化:redis支持異步將記憶體中的資料寫到硬碟上,同時不影響繼續服務
- 取最新N個資料的操作,如:可以將最新的10條評論的ID放在Redis的List集合里面
- 模擬類似于HttpSession這種需要設定過期時間的功能
- 發布、訂閱訊息系統
- 定時器、計數器
Redis 為什么是單執行緒的
- Redis是基于記憶體的操作,CPU不是Redis的瓶頸,Redis的瓶頸最有可能是機器記憶體的大小或者網路帶寬,既然單執行緒容易實作,而且CPU不會成為瓶頸
Redis 的快取預熱
- 在專案組態檔中生命自定義的
key,在專案啟動時會判斷redis是否存在key,如果沒有就會創建一個key傳入null值- 資料加熱的含義就是在正式部署之前,我先把可能的資料先預先訪問一遍,這樣部分可能大量訪問的資料就會加載到快取中
redis 快取雪崩是什么,怎么解決 ?
快取雪崩是指,快取層出現了錯誤,不能正常作業了.于是所有的請求都會達到存盤層,存盤層的呼叫量會暴增,造成存盤層也會掛掉的情況.
解決方案
- redis 高可用 就是搭建 redis 集群,其中一臺redis掛掉后 可以使用其他的 redis
- 限流降級 就是每一個 key 只能一個執行緒來查詢資料和快取,其他執行緒等待
- 資料預熱 資料加熱的含義就是在正式部署之前,我先把可能的資料先預先訪問一遍,這樣部分可能大量訪問的資料就會加載到快取中.在即將發生大并發訪問前手動觸發加載快取不同的 key ,設定不同的過期時間,讓快取失效的時間點盡量均勻.*
快取穿透是什么?如何解決
就是訪問redis資料庫,查不到資料,就是沒有命中,會去持久化資料庫查詢,還是沒有查到.假如高并發的情況下,持久化資料庫一下增加了很大壓力,就相當于出現了快取穿透
解決方案
- 快取空物件 在存盤層命中失敗后,即使回傳空物件也將其快取,并設定一個過期時間,之后訪問的這個資料將會從快取中取出,很好的保護了后端資料源,這樣也會有出現問題 例如空值被快取也就會增加大量的快取空間,設定了過期時間還是會存在快取層和存盤層的資料會有一段時間視窗的不一致,這對于需要保持一致性的業務會有影響
- 布隆過濾器 對所有可能查詢的引數以 hash 形式存盤,查詢時發現值不存在就直接丟棄,不會去持久層查詢
Redis 支持的資料型別有哪些
- String、List、Set、Hash、ZSet這5種
Redis 支持的 Java 客戶端有哪些
- Redisson、Jedis、lettuce 等等,官方推薦使用 Redisson
Jedis 與 Redisson 有哪些區別
- Jedis 和 Redisson 都是Java中對Redis操作的封裝,Jedis 只是簡單的封裝了 Redis 的API庫,可以看作是Redis客戶端,它的方法和Redis 的命令很類似,Redisson 不僅封裝了 redis ,還封裝了對更多資料結構的支持,以及鎖等功能,相比于Jedis 更加大,但Jedis相比于Redisson 更原生一些,更靈活
怎么保證快取與資料庫資料的一致性
- 對洗掉快取進行重試,資料的一致性要求越高,我越是重試得快,
- 定期全量更新,簡單地說,就是我定期把快取全部清掉,然后再全量加載,
- 給所有的快取一個失效期
Redis 持久化有幾種方式
- 快照方式(RDB, Redis DataBase)將某一個時刻的記憶體資料,以二進制的方式寫入磁盤
- 檔案追加方式(AOF, Append Only File),記錄所有的操作命令,并以文本的形式追加到檔案中
- 混合持久化方式,Redis 4.0 之后新增的方式,混合持久化是結合了 RDB 和 AOF 的優點,在寫入的時候,先把當前的資料以 RDB 的形式寫入檔案的開頭,再將后續的操作命令以 AOF 的格式存入檔案,這樣既能保證 Redis 重啟時的速度,又能簡單資料丟失的風險
Redis 怎么實作分布式鎖
SET key value [EX seconds] [PX milliseconds] [NX|XX]
EX second:設定鍵的過期時間為second秒PX millisecond:設定鍵的過期時間為millisecond毫秒NX:只在鍵不存在時,才對鍵進行設定操作XX:只在鍵已經存在時,才對鍵進行設定操作- SET操作成功完成時,回傳
OK,否則回傳nil
Redis 分布式鎖有什么缺陷
- 死鎖
- 設定鎖的過期時間,且需要保證setNx和設定過期時間操作的原子性
- 錯位解鎖
- 加鎖時記錄當前執行緒ID,解鎖時判斷ID是否一致
- 解鎖時,查詢redis里記錄鎖的ID,以及洗掉redis中鎖的記錄,這兩步操作可以使用lua腳本保持原子性
- 業務并發執行問題
- 加鎖成功后開啟守護執行緒,當臨近過期時間,業務還未完成時,開始續時,重復此步驟直到業務完成
Redis 如何做記憶體優化
- 縮減鍵值物件:滿足業務要求下 key 越短越好;value 值進行適當壓縮
- 共享物件池:即 Redis 內部維護[0-9999]的整數物件池,開發中在滿足需求的前提下,盡量使用整數物件以節省記憶體
- 盡可能使用散串列(hashes)
- 編碼優化,控制編碼型別
- 控制 key 的數量
Redis 淘汰策略有哪些
noeviction: 不洗掉策略, 達到最大記憶體限制時, 如果需要更多記憶體, 直接回傳錯誤資訊, 大多數寫命令都會導致占用更多的記憶體(有極少數會例外, 如 DEL )allkeys-lru: 所有key通用; 優先洗掉最近最少使用(less recently used ,LRU) 的 keyvolatile-lru: 只限于設定了expire的部分; 優先洗掉最近最少使用(less recently used ,LRU) 的 keyallkeys-random: 所有key通用; 隨機洗掉一部分 keyvolatile-random: 只限于設定了 expire 的部分; 隨機洗掉一部分 keyvolatile-ttl: 只限于設定了 expire 的部分; 優先洗掉剩余時間(time to live,TTL) 短的key
Redis 常見的問題有哪些? 該如何解決
- 快取和資料庫雙寫一致性問題
- 就是如果對資料有強一致性要求,不能放快取,我們所做的一切,只能保證最終一致性
- 采取正確更新策略,先更新資料庫,再刪快取,其次,因為可能存在洗掉快取失敗的問題,提供一個補償措施即可,例如利用訊息佇列
- 快取穿透問題
- 利用互斥鎖,快取失效的時候,先去獲得鎖,得到鎖了,再去請求資料庫,沒得到鎖,則休眠一段時間重試
- 采用異步更新策略,無論 Key 是否取到值,都直接回傳,Value 值中維護一個快取失效時間,快取如果過期,異步起一個執行緒去讀資料庫,更新快取,需要做快取預熱(專案啟動前,先加載快取)操作
- 提供一個能迅速判斷請求是否有效的攔截機制,比如,利用布隆過濾器,內部維護一系列合法有效的 Key,迅速判斷出,請求所攜帶的 Key 是否合法有效,如果不合法,則直接回傳
- 快取雪崩問題
- 給快取的失效時間,加上一個隨機值,避免集體失效
- 使用互斥鎖,但是該方案吞吐量明顯下降
- 雙快取,我們有兩個快取,快取 A 和快取 B,快取 A 的失效時間為 20 分鐘,快取 B 不設失效時間,自己做快取預熱操作(從A中讀不到,就去B讀,回傳資料時需要異步啟動一個更新執行緒,更新執行緒同時更新快取 A 和快取 B)
- 快取的并發競爭問題
- 如果對這個 Key 操作,不要求順序
- 這種情況下,準備一個分布式鎖,大家去搶鎖,搶到鎖就做 set 操作即可,比較簡單,
- 如果對這個 Key 操作,要求順序
- 假設有一個 key1,系統 A 需要將 key1 設定為 valueA,系統 B 需要將 key1 設定為 valueB,系統 C 需要將 key1 設定為 valueC
- 期望按照 key1 的 value 值按照 valueA > valueB > valueC 的順序變化,這種時候我們在資料寫入資料庫的時候,需要保存一個時間戳,
- 系統A key 1 {valueA 3:00}
- 系統B key 1 {valueB 3:05}
- 系統C key 1 {valueC 3:10}
- 那么,假設這會系統 B 先搶到鎖,將 key1 設定為{valueB 3:05},接下來系統 A 搶到鎖,發現自己的 valueA 的時間戳早于快取中的時間戳,那就不做 set 操作了,以此類推,
- 其他方法,比如利用佇列,將 set 方法變成串行訪問也可以,總之,靈活變通,
RabbitMQ部分面試題
RabbitMq 的使用場景有哪些
- 多個應用之間的耦合
- 跨系統的異步通信
- 流量削峰
- 比如:注冊用戶、發送激活郵箱、訂單下單等
RabbitMq 有哪些重要的角色
- 生產者:訊息的創建者,負責創建和推送資料到訊息服務器
- 消費者:訊息的接收方,負責處理資料和確認訊息
- 代理:就是RabbiMQ本身,不生產不消費,只是快遞訊息
RabbitMq 有哪些重要的組件
- ConnectionFactory(連接管理器):應用程式與Rabbit之間建立連接的管理器,程式代碼中使用
- Channel(信道):訊息推送使用的通道
- Exchange(交換器):用于接受、分配訊息
- Queue(佇列):用于存盤生產者的訊息
- RoutingKey(路由鍵):用于把生成者的資料分配到交換器上
- BindingKey(系結鍵):用于把交換器的訊息系結到佇列上
RabbitMQ的訊息存盤方式
RabbitMQ 對于 queue 中的 message 的保存方式有兩種方式:disc 和 ram.如果采用disc,則需要對 exchange/queue/delivery mode 都要設定成 durable 模式. Disc 方式的好處是當 RabbitMQ 失效了, message 仍然可以在重啟之后恢復.而使用 ram 方式, RabbitMQ 處理 message 的效率要高很多, ram 和 disc 兩種方式的效率比大概是 3:1.所以如果在有其它 HA 手段保障的情況下,選用 ram 方式是可以提高訊息佇列的作業效率的.
RabbitMq 中 vhost 的作用是什么
- vhost本質上是一個mini版的RabbitMQ服務器,擁有自己的佇列、系結、交換器和權限控制
- 從 RabbitMQ 的全域角度 vhost可以作為不同權限隔離的手段(一個典型的例子,不同的應用可以跑在不同的vhost中)
RabbitMq 的訊息是怎么發送的
- 生產者把生產的小心通過channel發送到Exchange上,Exchange通過系結的router key來選擇Queue,消費者監聽到Queue上有新的訊息,就消費調此訊息
RabbitMq 怎么保證訊息的穩定性
- 提供了事務的功能,通過將 channel 設定為 confirm(確認模式)
RabbitMq 怎么避免丟失訊息
- 訊息持久化
- 消費端的ack簽識訓制
- 設定集群鏡像模式
- 訊息補償機制
要保證訊息持久化成功的條件有哪些
- 宣告佇列必須設定持久化 durable 設定為 true
- 訊息推送投遞模式必須設定持久化,deliveryMode 設定為 2(持久)
- 訊息已經到達持久化交換器
- 訊息已經到達持久化佇列
以上四個條件都滿足才能保證訊息持久化成功
RabbitMq 持久化有什么缺點
- 持久化的缺點就是降低了服務器的吞吐量,因為使用的是磁盤而非記憶體存盤,從而降低了吞吐量,可盡量使用 ssd 硬碟來緩解吞吐量的問題
RabbitMq 有幾種廣播方式
fanout廣播模式:所有bind到此exchange的queue都可以接收訊息direct直接交換:通過routingKey和exchange決定的那個唯一的queue可以接收訊息topic通配符模式:所有符合routingKey(此時可以是一個運算式)的routingKey所bind的queue可以接收訊息
RabbitMq 怎么實作延遲訊息佇列
- 通過訊息過期后進入死信交換器,再由交換器轉發到延遲消費佇列,實作延遲功能
- 使用 RabbitMQ-delayed-message-exchange 插件實作延遲功能,
RabbitMq 集群有什么用
- 高可用:某個服務器出現問題,整個 RabbitMQ 還可以繼續使用
- 高容量:集群可以承載更多的訊息量,
RabbitMq 節點的型別有哪些
- 磁盤節點:訊息會存盤到磁盤
- 記憶體節點:訊息都存盤在記憶體中,重啟服務器訊息丟失,性能高于磁盤型別
RabbitMq 集群搭建需要注意哪些問題
- 各節點之間使用
–link連接,此屬性不能忽略- 各節點使用的 erlang cookie 值必須相同,此值相當于
秘鑰的功能,用于各節點的認證- 整個集群中必須包含一個磁盤節點
RabbitMq 每個節點是其他節點的完整拷貝嗎
不是
- 如果每個節點都擁有所有佇列的完全拷貝,這樣新增節點,不但沒有新增存盤空間,反而增加了更多的冗余資料
- 如果每條訊息都需要完整拷貝到每一個集群節點,那新增節點并沒有提升處理訊息的能力,最多是保持和單節點相同的性能甚至是更糟
RabbitMq 集群中唯一一個磁盤節點崩潰了會發生什么
- 唯一磁盤節點崩潰了,集群是可以保持運行的,但不能更改任何東西
- 不能創建佇列
- 不能創建交換器
- 不能創建系結
- 不能添加用戶
- 不能更改權限
- 不能添加和洗掉集群節點
RabbitMq 對集群停止順序有要求嗎
- RabbitMQ 對集群的停止的順序是有要求的,應該先關閉記憶體節點,最后再關閉磁盤節點,如果順序恰好相反的話,可能會造成訊息的丟失
JVM部分面試題
JVM 主要的組成部分?及其作用
類加載器(Class Loader):加載類檔案到記憶體,Class loader只管加載,只要符合檔案結構就加載,至于能否運行,它不負責,那是有Exectution Engine 負責的執行引擎(Execution Engine):也叫解釋器,負責解釋命令,交由作業系統執行本地庫介面(Native Interface):本地介面的作用是融合不同的語言為java所用- 運行時資料區(Runtime Data Area)
JVM 運行時資料區是什么
堆是java物件的存盤區域,任何用new欄位分配的java物件實體和陣列,都被分配在堆上,java堆可用-Xms和-Xmx進行記憶體控制,常量池:運行時常量池是方法區的一部分,Class檔案中除了有類的版本、欄位、方法、介面等描述資訊外,還有一項資訊是常量池,用于存放編譯期生成的各種字面量和符號參考,這部分內容將在類加載后進入方法區的運行時常量池中存放,jdk1.7以后,運行時常量池從方法區移到了堆上方法區:用于存盤已被虛擬機加載的類資訊,常量,靜態變數,即是編譯器編譯后的代碼等資料虛擬機堆疊:虛擬機堆疊中執行每個方法的時候,都會創建一個堆疊楨用于存盤區域變數表,運算元堆疊,動態鏈接,方法出口等資訊本地方法堆疊:與虛擬機發揮的作用相似,相比于虛擬機堆疊為Java方法服務,本地方法堆疊為虛擬機使用的Native方法服務,執行每個本地方法的時候,都會創建一個堆疊幀用于存盤區域變數表,運算元堆疊,動態鏈接,方法出口等資訊程式計數器:指示Java虛擬機下一條需要執行的位元組碼指令
堆和堆疊的區別
- 堆疊記憶體用來存盤區域變數和方法呼叫
- 而堆記憶體用來存盤 Java 中的物件.無論是成員變數,區域變數,還是類變數.,它們指向的物件都存盤在堆記憶體中.
- 堆疊記憶體歸屬單個執行緒,一個堆疊對應一個執行緒,其中儲存的變數只能在該執行緒中可以訪問到,也可以理解為私有記憶體
- 而堆記憶體中的物件 所有執行緒均可見,堆記憶體中物件可以被所有執行緒訪問到
- 堆疊記憶體要遠小于堆記憶體
佇列和堆疊是什么?有什么區別
- 佇列和堆疊是兩種不同的資料結構
- 操作名稱不同
- 佇列的插入稱為入隊,佇列的洗掉稱為出隊,堆疊的插入稱為進堆疊,堆疊的洗掉稱為出堆疊
- 可操作的方式不同
- 佇列是在隊尾入隊,隊頭出隊,即兩邊都可操作,而堆疊的進堆疊和出堆疊都是在堆疊頂進行的,無法對堆疊底直接進行操作,
- 佇列先進先出 FIFO,堆疊是后進先出 LIFO
類加載器有哪些?什么是雙親委派模型
- 啟動類加載器 Bootstrap ClassLoader:加載<JAVA_HOME>\lib目錄下核心庫
- 擴展類加載器 Extension ClassLoader:加載<JAVA_HOME>\lib\ext目錄下擴展包
- 應用程式類加載器 Application ClassLoader: 加載用戶路徑(classpath)上指定的類別庫
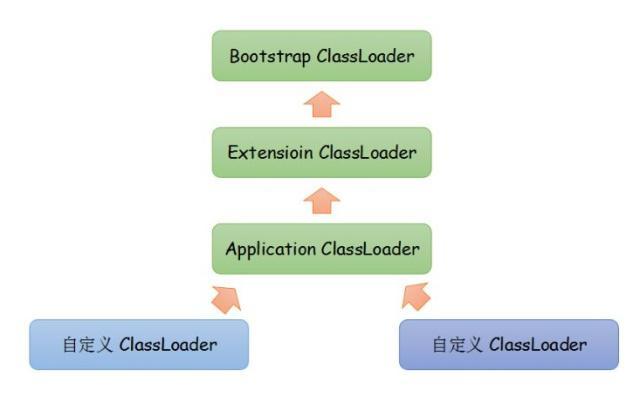
雙親委派的意思是如果一個類加載器需要加載類,那么首先它會把這個類請求委派給父類加載器去完成,每一層都是如此,一直遞回到頂層,當父加載器無法完成這個請求時,子類才會嘗試去加載,這里的雙親其實就指的是父類,沒有mother,父類也不是我們平日所說的那種繼承關系,只是呼叫邏輯是這樣
類加載的執行程序
- 加載
- 加載指的是把class位元組碼檔案從各個來源通過類加載器裝載入記憶體中
- 位元組碼來源:一般的加載來源包括從本地路徑下編譯生成的.class檔案,從jar包中的.class檔案,從遠程網路,以及動態代理實時編譯類加載器,一般包括啟動類加載器,擴展類加載器,應用類加載器,以及用戶的自定義類加載器
- 鏈接
- 驗證
主要是為了保證加載進來的位元組流符合虛擬機規范,不會造成安全錯誤,包括對于檔案格式的驗證
- 準備
主要是為類變數(注意,不是實體變數)分配記憶體,并且賦予初值,特別需要注意,初值,不是代碼中具體寫的初始化的值,而是Java虛擬機根據不同變數型別的默認初始值:8種基本型別的初值,默認為0;參考型別的初值則為null;
- 決議
將常量池內的符號參考替換為直接參考的程序,在決議階段,虛擬機會把所有的類名,方法名,欄位名這些符號參考替換為具體的記憶體地址或偏移量,也就是直接參考
- 初始化
這個階段主要是對類變數初始化,是執行類構造器的程序
怎么判斷物件是否可以識訓
- 參考計數演算法
- 判斷物件的參考數量
- 通過判斷物件的參考數量來決定物件是否可以被回收
- 每個物件實體都有一個參考計數器,被參考則+1,完成參考則-1
- 任何參考計數為0的物件實體可以被當作垃圾收集
- 優缺點
- 優點:執行效率高,程式執行受影響較小
- 缺點:無法檢測出回圈參考的情況,導致記憶體泄漏
- 可達性分析演算法
- 通過判斷物件的參考鏈是否可達來決定物件是否可以被回收
- 可以作為GC Root物件的物件有
- 虛擬機堆疊中參考的物件(堆疊幀中的本地變數表)
- 方法區中的常量參考物件
- 方法區中類靜態屬性參考物件
- 本地方法堆疊中JNI(Native方法)的參考物件
- 活躍執行緒中的參考物件
Java 中有哪些參考型別
- 強參考(strongreference)
就是指在程式代碼之中普遍存在的,類似“Object obj=new Object()” 這類的參考,只要強參考還存在,垃圾收集器永遠不會回收掉被參考的物件實體
- 軟參考(softreference)
是用來描述一些還有用但并非必需的物件,對于軟參考關聯著的物件, 在系統將要發生記憶體溢位例外之前,將會把這些物件實體列進回收范圍之中進行 第二次回收,如果這次回識訓沒有足夠的記憶體,才會拋出記憶體溢位例外,在 JDK 1.2 之后,提供了
SoftReference類來實作軟參考
- 弱參考(weakreference)
也是用來描述非必需物件的,但是它的強度比軟參考更弱一些,被弱 參考關聯的物件實體只能生存到下一次垃圾收集發生之前,當垃圾收集器作業時, 無論當前記憶體是否足夠,都會回收掉只被弱參考關聯的物件實體,在 JDK 1.2 之 后,提供了
WeakReference類來實作弱參考
- 虛參考(phantomreference)
也稱為幽靈參考或者幻影參考,它是最弱的一種參考關系,一個物件實體是否有虛參考的存在,完全不會對其生存時間構成影響,也無法通過虛參考 來取得一個物件實體,為一個物件設定虛參考關聯的唯一目的就是能在這個物件 實體被收集器回收時收到一個系統通知,在 JDK 1.2 之后,提供了 PhantomReference 類來實作虛參考
JVM 中垃圾回收演算法
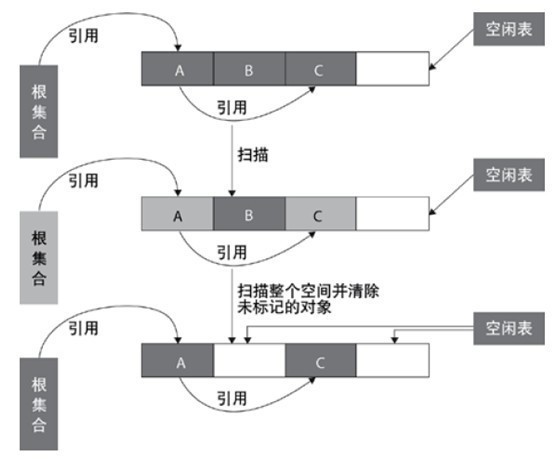
- 標記-清除演算法
標記-清除演算法采用從根集合(GC Roots)進行掃描,對存活的物件進行標記,標記完畢后,再掃描整個空間中未被標記的物件,進行回收,如下圖所示,標記-清除演算法不需要進行物件的移動,只需對不存活的物件進行處理,在存活物件比較多的情況下極為高效,但由于標記-清除演算法直接回收不存活的物件,因此會造成記憶體碎片
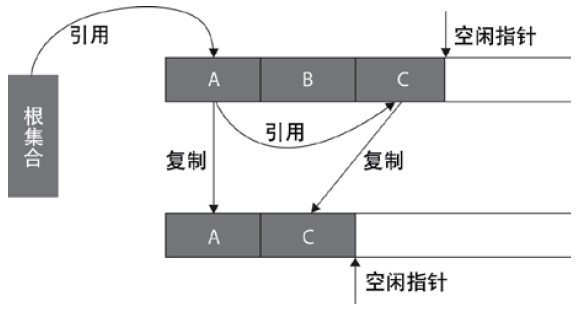
- 復制除演算法
復制演算法的提出是為了克服句柄的開銷和解決記憶體碎片的問題,它開始時把堆分成 一個物件 面和多個空閑面, 程式從物件面為物件分配空間,當物件滿了,基于copying演算法的垃圾 收集就從根集合(GC Roots)中掃描活動物件,并將每個 活動物件復制到空閑面(使得活動物件所占的記憶體之間沒有空閑洞),這樣空閑面變成了物件面,原來的物件面變成了空閑面,程式會在新的物件面中分配記憶體
- 標記-整理(壓縮)演算法
標記-整理演算法采用標記-清除演算法一樣的方式進行物件的標記,但在清除時不同,在回收不存活的物件占用的空間后,會將所有的存活物件往左端空閑空間移動,并更新對應的指標,標記-整理演算法是在標記-清除演算法的基礎上,又進行了物件的移動,因此成本更高,但是卻解決了記憶體碎片的問題
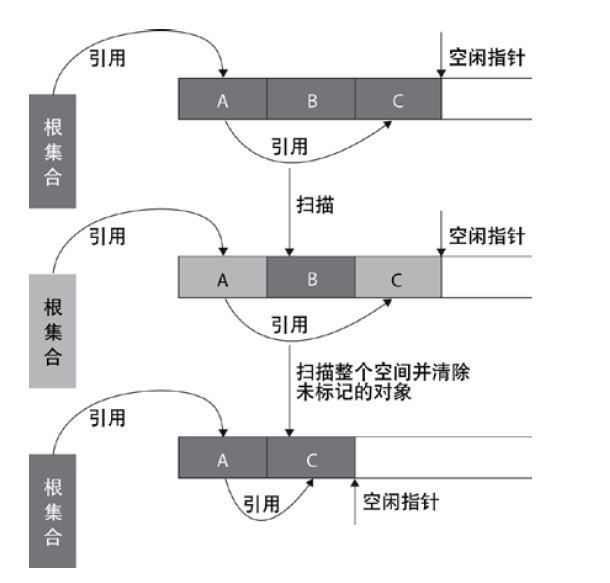
JVM 有哪些垃圾回收器
- 新生代收集器:Serial、ParNew、Parallel Scavenge
- 老年代收集器:CMS、Serial Old、Parallel Old
- 整堆收集器: G1
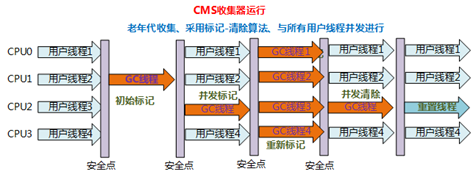
介紹一下 CMS 垃圾回收器
- CMS收集器 :一種以獲取最短回收停頓時間為目標的收集器
- 特點:基于標記-清除演算法實作,并發收集、低停頓
- 應用場景:適用于注重服務的回應速度,希望系統停頓時間最短,給用戶帶來更好的體驗等場景下,如web程式、b/s服務
- CMS收集器的運行程序分為下列4步:
- 初始標記:標記GC Roots能直接到的物件,速度很快但是仍存在Stop The World問題
- 并發標記:進行GC Roots Tracing 的程序,找出存活物件且用戶執行緒可并發執行
- 重新標記:為了修正并發標記期間因用戶程式繼續運行而導致標記產生變動的那一部分物件的標記記錄,仍然存在Stop The World問題
- 并發清除:對標記的物件進行清除回收
- CMS收集器的記憶體回收程序是與用戶執行緒一起并發執行的
- CMS收集器的缺點:
- 對CPU資源非常敏感
- 無法處理浮動垃圾,可能出現Concurrent Model Failure失敗而導致另一次Full GC的產生
- 因為采用標記-清除演算法所以會存在空間碎片的問題,導致大物件無法分配空間,不得不提前觸發一次Full GC
CMS收集器的作業程序圖:
新生代垃圾回收器和老生代垃圾回收器有哪些?有什么區別
- 新生代收集器:Serial、ParNew、Parallel Scavenge
- 老年代收集器:CMS、Serial Old、Parallel Old
- 區別:
新生代垃圾回收器一般采用的是復制演算法,復制演算法的優點是效率高,缺點是記憶體利用率低;老年代回收器一般采用的是標記-整理的演算法進行垃圾回收
簡述分代垃圾回收器是怎么作業的
- 分代回收器有兩個磁區:老生代和新生代,新生代默認的空間占比總空間的 1/3,老生代的默認占比是 2/3, 新生代使用的是復制演算法,新生代里有 3 個磁區:Eden、To Survivor、From Survivor,它們的默認占比是 8:1:1
- 執行流程
- 把 Eden + From Survivor 存活的物件放入 To Survivor 區
- 清空 Eden 和 From Survivor 磁區; From Survivor 和 To Survivor 磁區交換,From Survivor 變 To Survivor,To Survivor 變 From Survivor
- 每次在 From Survivor 到 To Survivor 移動時都存活的物件,年齡就 +1,當年齡到達 15(默認配置是 15)時,升級為老生代,大物件也會直接進入老生代
- 老生代當空間占用到達某個值之后就會觸發全域垃圾識訓,一般使用標記整理的執行演算法
- 以上這些回圈往復就構成了整個分代垃圾回收的整體執行流程
JVM 調優的工具有哪些
- jconsole
jdk自帶的工具:是一個基于JMX(java management extensions)的GUI性能監測工具(jdk/bin目錄下點擊jconsole.exe即可啟動)- VisualVM:它提供了一個可視界面,用于查看 Java 虛擬機 (Java Virtual Machine, JVM) 上運行的基于 Java 技術的應用程式(Java 應用程式)的詳細資訊(jdk/bin目錄下面雙擊jvisualvm.exe既可使用)
- MAT
第三方調優工具:一個基于Eclipse的記憶體分析工具,是一個快速、功能豐富的Java heap分析工具,它可以幫助我們查找記憶體泄漏和減少記憶體消耗(MAT以eclipse 插件的形式來安裝)- GChisto:專業分析gc日志的工具,可以通過gc日志來分析:Minor GC、full gc的時間、頻率等等,通過串列、報表、圖表等不同的形式來反應gc的情況(配置好本地的jdk環境之后,雙擊GChisto.jar,在彈出的輸入框中點擊 add 選擇gc.log日志)
- gcviewer:分析小工具,用于可視化查看由Sun / Oracle, IBM, HP 和 BEA Java 虛擬機產生的垃圾收集器的日志
JVM 調優的引數有哪些
演算法題
其他部分面試題
Api 介面如何實作 ?
在類里使用 implements 關鍵字實作 Api 介面
MySQL 鏈接資料庫常用的幾種方式 ?
- Mybatis 框架
- Hibernate 框架
- JDBC 技術
- c3p0 連接池
- dbcp 連接池
SpringBoot 如何集成 Redis ?
在 pom.xml 檔案引入 redis 依賴
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
在 application 組態檔中 書寫 redis 配置
spring.redis.host=127.0.0.1
#Redis服務器連接埠
spring.redis.port=6379
#Redis服務器連接密碼(默認為空)
#spring.redis.password=
SpringCloud 的優點 ?
- 服務之間采用Restful等輕量級通訊
- 精準的制定優化服務方案,提高系統的可維護性
- 服務之間拆分細致,資源可重復利用,提高開發效率
SpringCloud 用了哪些組件 ?
- netflix Eureka 注冊中心
- netflix Ribbon 負載均衡
- netflix Zuul 網關
- netflix Hystrix 熔斷器
- feign 服務呼叫
List 和 Set 的區別
- List 允許有多個重復物件,而 Set 不允許有重復物件
- List 允許有多個NULL值,而 Set 只允許有一個NULL值
- List 是一個有序的容器,輸出順序即是輸入順序
- Set 是一個無序的容器無法保證每個元素的順序,但是可以用 TreeSet 通過 Comparator 或者 Comparable 維護排序順序
- List的實作類有 ArrayList、LinkList、Vector 其中 ArrayList 最常用于查詢較多,隨意訪問.LinkList 同于新增和洗掉較多的情況,Vector 表示底層陣列,執行緒安全象
- Set的實作類有 HashSet、TreeSet、LinkedHashSet 其中基于 HashMap 實作的 HashSet 最為流行,TreeSet 是一個有序的Set容器象
擴展
Map的實作類有HashMap、HashTable、TreeMap
Java 中 static 的作用
- 表示全域或靜態的意思、用來修飾成員變數和成員方法,也可以形成靜態代碼塊
- 達到了不用實體化就可以使用被 public static 修飾的變數或方法
什么單例模式 ?
保證整個專案中一個類只有一個物件的實體,實作這種功能就叫做單例模式
- 單例模式的好處:
- 單例模式節省公共資源
- 單例模式方便控制
- 如何保證是單利模式 ?
- 構造私有化
- 以靜態方法回傳實體
- 確保物件實體只有一個
- 單例模式有哪幾個 ?
- 餓漢模式
把物件創建好,需要使用的時候直接拿到就行
- 懶漢模式
等你需要的時候在創建物件,后邊就不會再次創建
SpringBoot 常用的幾個注解 ?
- @SpringBootApplication SpringBoot的核心注解 啟動類
- @EnableAutoConfiguration 開啟SpringBoot自動配置
- @RestController 在控制層 是@ResponseBody注解與@Controller注解的合集
- @RequestMapper 處理請求地址映射的注解
- @RequestParam 獲取url上傳過來的引數
- @Configuration 宣告配置類
- @Component 通用注解
- @Service 業務邏輯層
Java 八大資料型別
char 字符型 byte 位元組型 boolean 布爾型
float 單浮點型 double 雙浮點型
int 整數型 short 短整數型 long 長整數型
MySQL分頁和升序降序如何實作 ?
- 可以用 limit
select
name,age,sexfrom t_student limit(0,5);
- 升序 order by xx asc
select
name,age,sexfrom t_student order byageasc;
- 降序 order by xx desc
select
name,age,sexfrom t_student order byagedesc;
maven 是干什么的,它有什么好處 ?
- maven 專門構建和管理Java專案的工具
- maven的好處在于可以將專案程序規范化、自動化、高效化以及強大的可擴展性
MySQL 如何添加索引 ?
- PRIMARY KEY (主鍵索引)
- 添加INDEX(普通索引) ALTER TABLE
table_nameADD INDEX index_name (column)- 添加UNIQUE(唯一索引) ALTER TABLE
table_nameADD UNIQUE index_name (column)- 添加FULLTEXT(全文索引) ALTER TABLE
table_nameADD FULLTEXT (column)- 添加多列索引 ALTER TABLE
table_nameADD INDEX index_name (column1,column2,column3)
MySQL 索引的實作方式?
MySQL 索引底層的實作方式是 B+Tree也就是B+樹 具體查看 B+Tree實作方式
Vue的資料雙向系結原理
使用v-mode屬性, 它的原理是利用了Object.defineProperty()方法重新定義了物件獲取屬性值(get)和設定屬性值(set)的操作來實作的
ActiveMQ的訊息存盤方式
- 采取先進先出模式,同一時間,訊息只會發送給某一個消費者,只有當該訊息被消費并告知已收到時,它才能在代理的存盤中被洗掉.
- 對于持久性訂閱來說,每一個消費者都會獲取訊息的拷貝.為了節約空間,代理的存盤介質中只存盤了一份訊息,存盤介質的持久訂閱物件為其以后的被存盤的訊息維護了一個指標,消費者消費時,從存盤介質中復制一個訊息.訊息被所有訂閱者獲取后才能洗掉.
KahaDB訊息存盤
基于檔案的訊息存盤機制,為了提高訊息存盤的可靠性和可恢復性,它整合了一個事務日志.KahaDB擁有高性能和可擴展性等特點.由于KahaDB使用的是基于檔案的存盤,所以不需要使用第三方資料庫
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/88058.html
標籤:Java