由于畢業設計的需要,本人最近在學習爬取一些簡單的試題庫,寫篇Blog記錄一下,就以問答庫(https://www.asklib.com/)為例,
可以看到,問答庫中查看答案是需要付費VIP的,這個沒辦法,我開通了一個5元7天的會員,用來測驗,(此處不提供賬號密碼)
先附上完整代碼


1 import json 2 from bs4 import BeautifulSoup 3 from time import sleep 4 from selenium import webdriver 5 from selenium.webdriver.common.by import By # 參考網頁選擇器 6 from selenium.webdriver.support.ui import WebDriverWait # 參考設定顯示等待時間 7 from selenium.webdriver.support import expected_conditions as EC # 參考等待條件 8 import time 9 10 11 def init(): 12 # 定義為全域變數,方便其他模塊使用 13 global url, browser, username, password, wait 14 # 登錄界面的url 15 url = 'https://www.asklib.com/?from=logout' 16 # 實體化一個chrome瀏覽器 17 browser = webdriver.Chrome("C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe") 18 # 用戶名 19 username = "" 20 # 密碼 21 password = "" 22 # 設定等待超時 23 wait = WebDriverWait(browser, 20) 24 25 26 def login(): 27 # 打開登錄頁面 28 browser.get("https://www.asklib.com/?from=logout") 29 button = wait.until( 30 EC.element_to_be_clickable((By.XPATH, '/html/body/div[2]/div/ul[1]/li[1]/a'))) # 等待目標可以點擊 31 button.click() 32 time.sleep(1) 33 browser.switch_to.frame(browser.find_element_by_xpath("//iframe[contains(@id,'layui-layer-iframe1')]")) 34 input_psw = browser.find_element_by_xpath('//div[@]/input')#獲得密碼輸入 35 input_user = browser.find_element_by_xpath('//div[@]/input')#獲得賬號輸入 36 input_user.send_keys("xxxxxxxxx") # 發送登錄賬號 37 time.sleep(1) 38 input_psw.send_keys("xxxxxxxxx")#發送登錄密碼 39 time.sleep(1) # 等待 一秒 防止被識別為機器人 40 login1 = wait.until(EC.element_to_be_clickable((By.XPATH, '/html/body/section/div[1]/input'))) 41 login1.click() 42 browser.switch_to.default_content() 43 44 45 def get_item_info(url): 46 browser.get(url) 47 soup = BeautifulSoup(browser.page_source.encode('utf-8'), 'lxml') 48 question_list = soup.select( 49 'body > div.content.clear > div:nth-child(2) > div.listleft > div:nth-child(1) > div.essaytitle.txt_l ') 50 question = question_list[0].text 51 answer_list = soup.select('body > div.content.clear > div:nth-child(2) > div.listleft > div.listbg > div') 52 answer = answer_list[0].text 53 jiexi_list = soup.select('#commentDiv > div ') 54 jiexi = jiexi_list[0].text 55 56 data =https://www.cnblogs.com/lychan/p/ { 57 'question': question, 58 'answer': answer, 59 'jiexi': jiexi 60 } 61 62 with open('data.json', 'a', encoding='utf-8') as f: 63 json.dump(data, f, ensure_ascii=False, indent=2) 64 65 66 def get_all_link(): 67 for page in range(1,100): 68 if page == 100: 69 break 70 if page == 1: 71 browser.get('https://www.asklib.com/s/%E6%96%87%E5%AD%A6/p1') 72 sleep(5) 73 else: 74 browser.get('https://www.asklib.com/s/%E6%96%87%E5%AD%A6/p'+str(page)) 75 soup = BeautifulSoup(browser.page_source.encode('utf-8'), 'lxml') 76 hrefs_list = soup.select( 77 'body > div.content.clear > div:nth-child(2) > div.listleft > div > div.b-tQ.clear > div > a') 78 for href in hrefs_list: 79 link = href.get('href') 80 url1 = 'https://www.asklib.com/'+link 81 get_item_info(url1) 82 83 84 def main(): 85 # 初始化 86 init() 87 # 登錄 88 login() 89 sleep(6) 90 get_all_link() 91 92 93 if __name__ == '__main__': 94 main()問答庫爬蟲
前期準備:你需要一些網頁基礎(簡單的HTML,CSS,JS可以到W3C學習 https://www.w3school.com.cn/html/index.asp)
掌握一定的python基礎(這里推薦一下廖老師的教程 https://www.liaoxuefeng.com/wiki/1016959663602400)
然后我們就可以開始快樂地編程了,
1. 爬取一個網頁,你需要先到頁面上看看自己需要爬取哪些資訊,對于我的需求的話,我只需要題目,答案以及決議即可,打開開發人員工具,我是用的是微軟的edge,快捷鍵F12,常見的瀏覽器都差不多,右擊檢查,或者在右側區域選中你需要爬取的資訊,復制選擇器(selector)
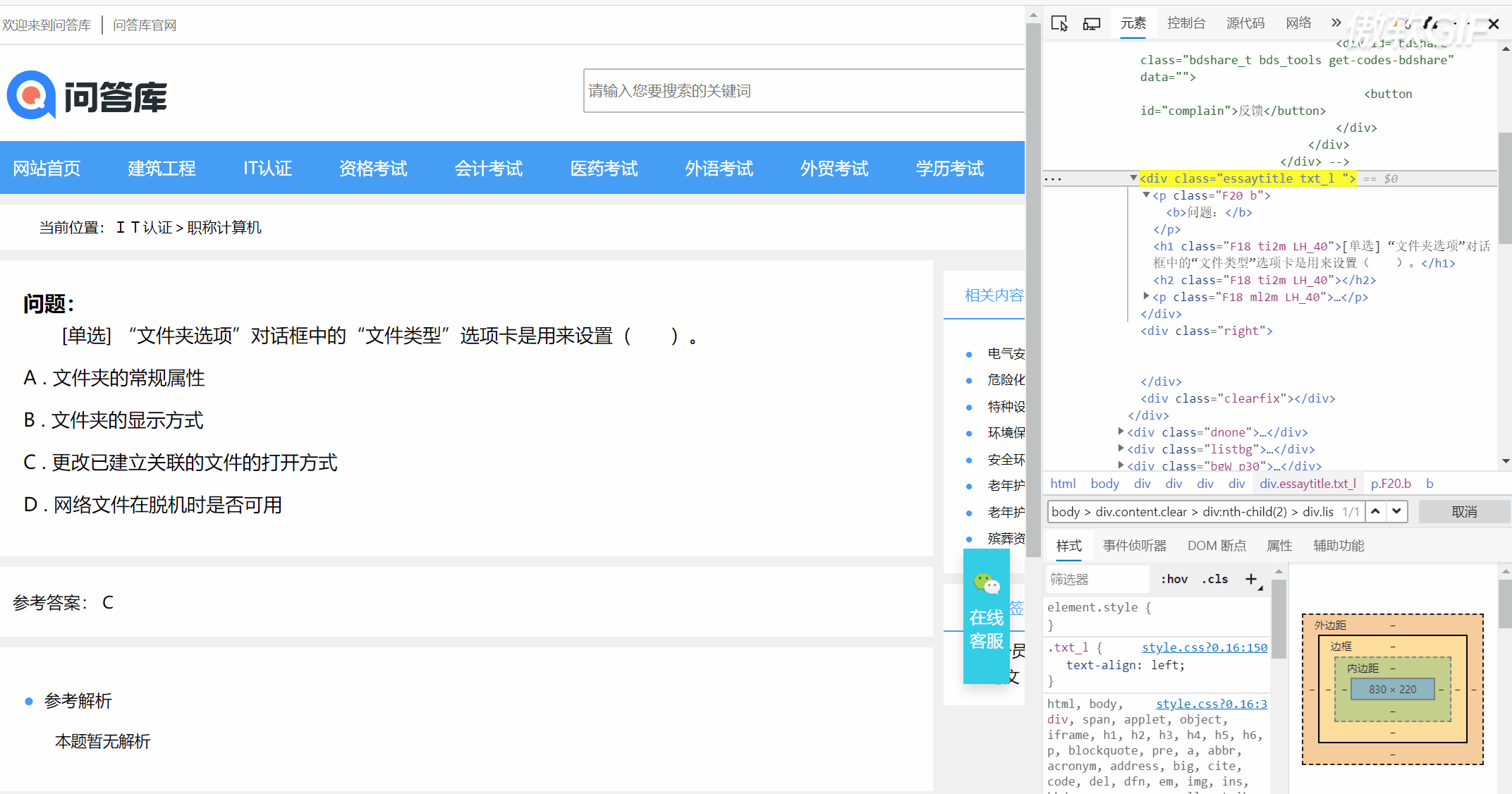
2. 在pycharm中新建python檔案,匯入第三方庫
1 import json 2 import requests 3 from bs4 import BeautifulSoup 4 from time import sleep 5 from selenium import webdriver 6 from selenium.webdriver.common.by import By # 參考網頁選擇器 7 from selenium.webdriver.support.ui import WebDriverWait # 參考設定顯示等待時間 8 from selenium.webdriver.support import expected_conditions as EC # 參考等待條件 9 import time
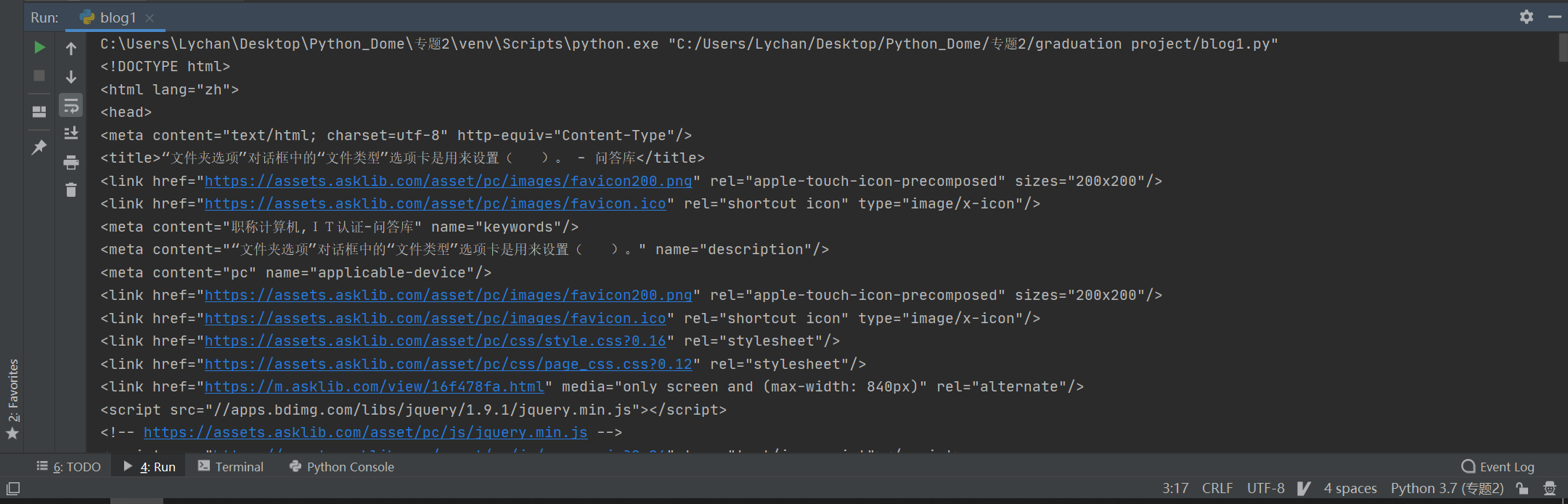
3. 嘗試用BeautifulSoup爬取頁面源代碼,爬取成功,
1 def get_item_info(): 2 url = 'https://www.asklib.com/view/16f478fa.html' 3 wb_data =https://www.cnblogs.com/lychan/p/ requests.get(url) 4 soup = BeautifulSoup(wb_data.text, 'lxml') 5 print(soup)
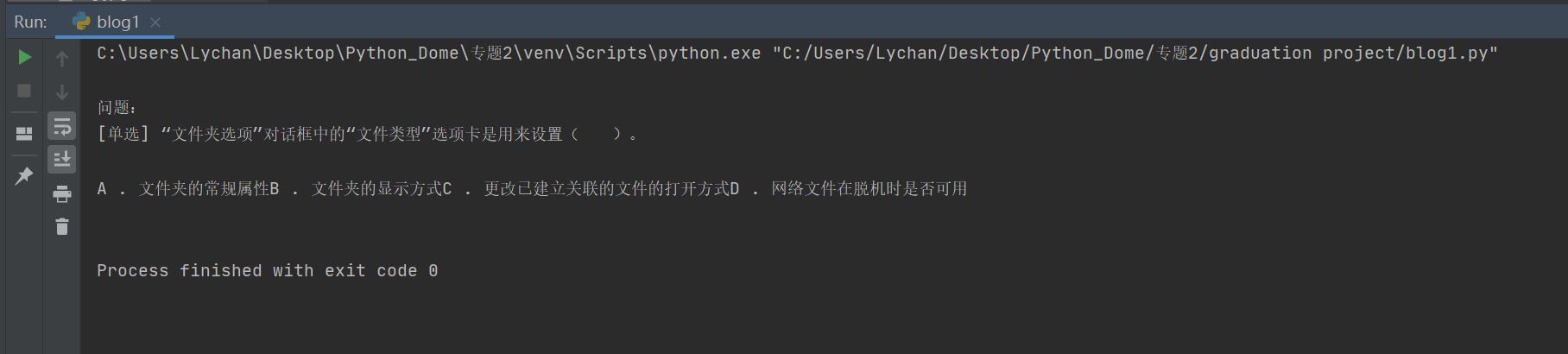
4. 利用選擇器(selector)爬取我們想要的資訊,稍微修改上面的代碼即可,這里以題目為例其他的資訊爬取也一樣,
1 def get_item_info(): 2 url = 'https://www.asklib.com/view/16f478fa.html' 3 wb_data =https://www.cnblogs.com/lychan/p/ requests.get(url) 4 soup = BeautifulSoup(wb_data.text, 'lxml') 5 question_list = soup.select('body > div.content.clear > div:nth-child(2) > div.listleft > div:nth-child(1) > div.essaytitle.txt_l') 6 question = question_list[0].text 7 print(question)
5. 將資訊結構化成字典
1 def get_item_info(): 2 url = 'https://www.asklib.com/view/16f478fa.html' 3 wb_data =https://www.cnblogs.com/lychan/p/ requests.get(url) 4 soup = BeautifulSoup(wb_data.text, 'lxml') 5 question_list = soup.select('body > div.content.clear > div:nth-child(2) > div.listleft > div:nth-child(1) > div.essaytitle.txt_l') 6 question = question_list[0].text 7 question_list = soup.select( 8 'body > div.content.clear > div:nth-child(2) > div.listleft > div:nth-child(1) > div.essaytitle.txt_l ') 9 question = question_list[0].text 10 answer_list = soup.select('body > div.content.clear > div:nth-child(2) > div.listleft > div.listbg > div') 11 answer = answer_list[0].text 12 jiexi_list = soup.select('#commentDiv > div ') 13 jiexi = jiexi_list[0].text 14 data =https://www.cnblogs.com/lychan/p/ { 15 'question': question, 16 'answer': answer, 17 'jiexi': jiexi 18 } 19 print(data)
6. 模擬瀏覽器登錄,此處需要ChromeDriver,安裝請自行百度,
1 def init(): 2 # 定義為全域變數,方便其他模塊使用 3 global url, browser, username, password, wait 4 # 登錄界面的url 5 url = 'https://www.asklib.com/?from=logout' 6 # 實體化一個chrome瀏覽器 7 browser = webdriver.Chrome("C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe") 8 # 用戶名 9 username = "" 10 # 密碼 11 password = "" 12 # 設定等待超時 13 wait = WebDriverWait(browser, 20)
此處不提供賬號密碼,如有需要,自行購買,
1 def login(): 2 # 打開登錄頁面 3 browser.get("https://www.asklib.com/?from=logout") 4 button = wait.until( 5 EC.element_to_be_clickable((By.XPATH, '/html/body/div[2]/div/ul[1]/li[1]/a'))) # 等待目標可以點擊 6 button.click() 7 time.sleep(1) 8 browser.switch_to.frame(browser.find_element_by_xpath("//iframe[contains(@id,'layui-layer-iframe1')]")) 9 input_psw = browser.find_element_by_xpath('//div[@]/input') 10 input_user = browser.find_element_by_xpath('//div[@]/input') 11 input_user.send_keys("XXXXXXXXXXXX") # 發送登錄賬號 12 time.sleep(1) 13 input_psw.send_keys("XXXXXXXXXXX")#發送登錄密碼 14 time.sleep(1) # 等待 一秒 防止被識別為機器人 15 login1 = wait.until(EC.element_to_be_clickable((By.XPATH, '/html/body/section/div[1]/input'))) 16 login1.click() 17 browser.switch_to.default_content()
7. 實作了登錄功能后,我們發現,所以的問題鏈接都是在<a href>標簽中,每頁有10個問題,通過網頁鏈接可以查看到規律,
1 def get_all_link(): 2 for page in range(1,100): 3 if page == 100: 4 break 5 if page == 1: 6 browser.get('https://www.asklib.com/s/%E6%96%87%E5%AD%A6/p1') 7 sleep(5) 8 else: 9 browser.get('https://www.asklib.com/s/%E6%96%87%E5%AD%A6/p'+str(page)) 10 soup = BeautifulSoup(browser.page_source.encode('utf-8'), 'lxml') 11 hrefs_list = soup.select( 12 'body > div.content.clear > div:nth-child(2) > div.listleft > div > div.b-tQ.clear > div > a') 13 for href in hrefs_list: 14 link = href.get('href') 15 url1 = 'https://www.asklib.com/'+link 16 get_item_info(url1)
8. 將以上代碼整合,具體代碼開頭已經給出,在此宣告,此方法不是最好的方法,但是selenium是真的nb,歡迎交流學習,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/88116.html
標籤:Python
上一篇:設定頁邊距