一、SQLAlchemy介紹
QLAlchemy是一個基于Python的ORM框架,該框架是建立在DB-API之上,使用關系物件映射進行資料庫操作,
簡而言之就是,將類和物件轉換成SQL,然后使用資料API執行SQL并獲取執行結果,
什么是DB-API?
DB-API是Python的資料庫介面規范,
在沒有DB-API之前,各資料庫之間的應用介面非常混亂,實作各不相同,
專案需要更換資料庫的時候,需要做大量的修改,非常不方便,DB-API就是為了解決這樣的問題,

pip install sqlalchemy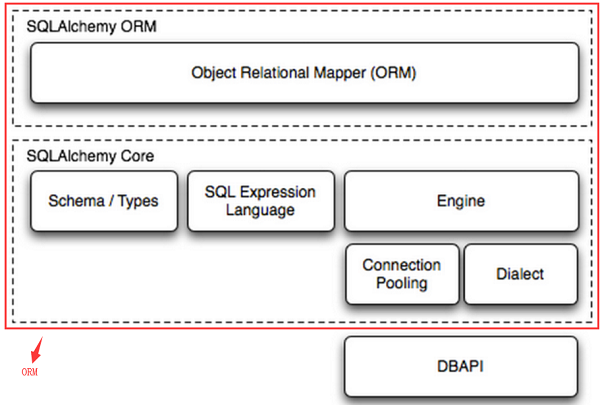
組成部分:
-- engine,框架的引擎
-- connection pooling 資料庫連接池
-- Dialect 選擇鏈接資料庫的DB-API種類(實際選擇哪個模塊鏈接資料庫)
-- Schema/Types 架構和型別
-- SQL Expression Language SQL運算式語言
二、連接資料庫
SQLAlchemy 本身無法操作資料庫,其必須依賴遵循DB-API規范的三方模塊,
Dialect 用于和資料API進行互動,根據配置的不同呼叫不同資料庫API,從而實作資料庫的操作,
下面是不同資料庫的API:
# MySQL-PYthon mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> # Pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] # MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> # Cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
連接資料庫
from sqlalchemy import create_engine# create_engine就是去建立連接,相當于我們pymsql建立連接的時候 conn= pymysql.connect(...) conn = create_engine( "mysql+pymysql://root:[email protected]:3306/資料庫名?charset=utf8mb4", max_overflow=0, # 超過連接池大小外最多創建的連接數 pool_size=5, # 連接池大小 pool_timeout=30, # 連接池中沒有執行緒最多等待時間,否則報錯 pool_recycle=-1, # 多久之后對連接池中的連接進行回收(重置)-1不回收 )
三、執行原生SQL
from sqlalchemy import create_engineconn = create_engine( "mysql+pymysql://root:[email protected]:3306/test?charset=utf8mb4", max_overflow=0, pool_size=5, )
def test(): ret = conn.execute("select * from MyTest") result = ret.fetchall() print(result) ret.close()
if __name__ == '__main__': test()
四、ORM
1、創建表



# 1. 創建單表
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
from sqlalchemy import Index, UniqueConstraint
import datetime
ENGINE = create_engine("mysql+pymysql://root:[email protected]:3306/test?charset=utf8mb4",)
# Base是declarative_base的實體化物件
Base = declarative_base()
# 每個類都要繼承Base
class UserInfo(Base):
# __tablename__是必須要的,它是設定實際存在資料庫中的表名
__tablename__ = "user_info"
# Column是列的意思,固定寫法 Column(欄位型別, 引數)
# primary_key主鍵、index索引、nullable是否可以為空
id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=False)
email = Column(String(32), unique=True)
create_time = Column(DateTime, default=datetime.datetime.now)
# 相當于Django的ORM的class Meta,是一些元資訊
__table_args__ = (
UniqueConstraint("id", "name", name="uni_id_name"),
Index("name", "email")
)
def create_db():
# metadata.create_all創建所有表
Base.metadata.create_all(ENGINE)
def drop_db():
# metadata.drop_all洗掉所有表
Base.metadata.drop_all(ENGINE)
if __name__ == '__main__':
create_db()
1. 創建單表
# 2. 創建一對多的表
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
from sqlalchemy import Index, UniqueConstraint, ForeignKey
from sqlalchemy.orm import relationship
import datetime
ENGINE = create_engine("mysql+pymysql://root:[email protected]:3306/test?charset=utf8mb4",)
Base = declarative_base()
# ======一對多示例=======
class UserInfo(Base):
__tablename__ = "user_info"
id = Column(Integer, primary_key=True)
# index=True,設定索引
name = Column(String(32), index=True, nullable=False)
email = Column(String(32), unique=True)
create_time = Column(DateTime, default=datetime.datetime.now)
# ForeignKey欄位的建立,需要指定外鍵系結哪個表的哪個欄位
hobby_id = Column(Integer, ForeignKey("hobby.id"))
# 不生成表結構 方便查詢和增加的操作
# 第一個引數是關聯到哪個類(表), backref是給關聯的那個類反向查詢用的
hobby = relationship("Hobby", backref="user")
__table_args__ = (
# UniqueConstraint聯合唯一,這個聯合唯一的欄位名為:uni_id_name
UniqueConstraint("id", "name", name="uni_id_name"),
# 聯合索引
Index("name", "email")
)
class Hobby(Base):
__tablename__ = "hobby"
id = Column(Integer, primary_key=True)
title = Column(String(32), default="碼代碼")
def create_db():
Base.metadata.create_all(ENGINE)
def drop_db():
Base.metadata.drop_all(ENGINE)
if __name__ == '__main__':
create_db()
# drop_db()
2. 創建一對多的表
# 3. 創建多對多的表
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
from sqlalchemy import Index, UniqueConstraint, ForeignKey
from sqlalchemy.orm import relationship
import datetime
ENGINE = create_engine("mysql+pymysql://root:[email protected]:3306/test?charset=utf8mb4",)
Base = declarative_base()
# ======多對多示例=======
class Book(Base):
__tablename__ = "book"
id = Column(Integer, primary_key=True)
title = Column(String(32))
# 不生成表欄位 僅用于查詢和增加方便
# 多對多的relationship還需要設定額外的引數secondary:系結多對多的中間表
tags = relationship("Tag", secondary="book2tag", backref="books")
class Tag(Base):
__tablename__ = "tag"
id = Column(Integer, primary_key=True)
title = Column(String(32))
class Book2Tag(Base):
__tablename__ = "book2tag"
id = Column(Integer, primary_key=True)
book_id = Column(Integer, ForeignKey("book.id"))
tag_id = Column(Integer, ForeignKey("tag.id"))
def create_db():
Base.metadata.create_all(ENGINE)
def drop_db():
Base.metadata.drop_all(ENGINE)
if __name__ == '__main__':
create_db()
# drop_db()
3. 創建多對多的表
from sqlalchemy import create_engine, ForeignKey, UniqueConstraint, Index
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, scoped_session
from sqlalchemy.orm import relationship
from sqlalchemy import Index, UniqueConstraint
conn = create_engine(
"mysql+pymysql://root:[email protected]:3306/mytest?charset=utf8mb4",
max_overflow=0, # 超過連接池大小外最多創建的連接數
pool_size=5, # 連接池大小
pool_timeout=30, # 連接池中沒有執行緒最多等待時間,否則報錯
pool_recycle=-1, # 多久之后對連接池中的連接進行回收(重置)-1不回收
)
Base = declarative_base()
class Book(Base):
__tablename__ = 'book'
id = Column(Integer, primary_key=True)
title = Column(String(64), nullable=False)
publisher_id = Column(Integer, ForeignKey('publisher.id'))
publisher = relationship('Publisher', backref='books')
tags = relationship('Tag', backref='books', secondary='book2tag')
__table_args__ = (
# UniqueConstraint聯合唯一,這個聯合唯一的欄位名為:uni_id_name
UniqueConstraint("id", "title", name="uni_id_title"),
# 聯合索引
Index("id", "title")
)
def __repr__(self):
return self.title
class Publisher(Base):
__tablename__ = 'publisher'
id = Column(Integer, primary_key=True)
title = Column(String(64), nullable=False)
def __repr__(self):
return self.title
class Tag(Base):
__tablename__ = 'tag'
id = Column(Integer, primary_key=True)
title = Column(String(64), nullable=False)
def __repr__(self):
return self.title
class Book2Tag(Base):
__tablename__ = 'book2tag'
id = Column(Integer, primary_key=True)
book_id = Column(Integer, ForeignKey('book.id'))
tag_id = Column(Integer, ForeignKey('tag.id'))
def create_db():
# metadata.create_all創建所有表
Base.metadata.create_all(conn)
def drop_db():
# metadata.drop_all洗掉所有表
Base.metadata.drop_all(conn)
# 每次執行資料庫操作的時候,都需要創建一個session,相當于管理器(相當于Django的ORM的objects)
session_factory = sessionmaker(bind=conn)
# 執行緒安全,基于本地執行緒實作每個執行緒用同一個session
Session = scoped_session(session_factory)
# 實體化(相當于實作了一個單例模式)
session = Session()
# session2 = Session() --> session is session2
# 下面這種情況
# session_factory = sessionmaker(bind=conn)
# session3 = session_factory()
# session4 = session_factory()
# session3 is not session4
if __name__ == '__main__':
# create_db()
# drop_db()
# publisher_obj = Publisher(title='xxx出版社')
# book_obj = Book(title='時間簡史', publisher=publisher_obj)
# tag_obj1 = Tag(title='python')
# tag_obj2 = Tag(title='go')
# tag_obj3 = Tag(title='linux')
# session.add(publisher_obj)
# session.add(book_obj)
# session.add_all([tag_obj1, tag_obj2, tag_obj3])
# session.commit()
# session.close()
# ret1 = session.query(Tag).filter(Tag.id==1).first()
# ret2 = session.query(Tag).filter_by(id=2).first()
# print(ret1)
# print(ret2)
# session.query(Tag).filter_by(id=2).update({"title": 'golang'})
# tag_obj = Tag(title='heihei2')
# tag_obj.books = [session.query(Book).filter_by(id=1).first()]
# session.add(tag_obj)
# session.commit()
# book_obj = Book(title='狗屎仔',
# publisher_id=1,
# tags=[session.query(Tag).filter_by(id=1).first(), session.query(Tag).filter_by(id=2).first()])
# session.add(book_obj)
# session.commit()
# ret = session.query(Book, Publisher).filter(Book.publisher_id==Publisher.id).all()
# ret = session.query(Book).join(Publisher).all()
# ret = session.query(Book).join(Publisher, isouter=True).all()
ret = session.query(Book).outerjoin(Publisher).all()
print(ret)
4. 完整的Demo
2、對資料庫表的操作(增刪改查)
# 1. scoped_session
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, scoped_session
from models_demo import Tag
ENGINE = create_engine("mysql+pymysql://root:[email protected]:3306/test?charset=utf8mb4",)
# 每次執行資料庫操作的時候,都需要創建一個session,相當于管理器(相當于Django的ORM的objects)
Session = sessionmaker(bind=ENGINE)
# 執行緒安全,基于本地執行緒實作每個執行緒用同一個session
session = scoped_session(Session)
# =======執行ORM操作==========
tag_obj = Tag(title="SQLAlchemy")
# 添加
session.add(tag_obj)
# 提交
session.commit()
# 關閉session
session.close()
1. scoped_session
# 2. 基本增刪改查
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker, scoped_session
from models_demo import Tag, UserInfo
import threading
ENGINE = create_engine("mysql+pymysql://root:[email protected]:3306/test?charset=utf8mb4",)
Session = sessionmaker(bind=ENGINE)
# 每次執行資料庫操作的時候,都需要創建一個session
session = Session()
session = scoped_session(Session)
# ============添加================
tag_obj = Tag(title="SQLAlchemy")
session.add(tag_obj)
# 批量添加
session.add_all([
Tag(title="Python"),
Tag(title="Django"),
])
# 提交
session.commit()
# 關閉session
session.close()
# ============基礎查詢============
ret = session.query(Tag).all()
# get(id)
ret1 = session.query(Tag).get(1) # 查詢Tag表 id=1的記錄
# filter(運算式)
ret2 = session.query(Tag).filter(Tag.title == "Python").all()
# filter_by(欄位=xx)
ret3 = session.query(Tag).filter_by(title="Python").all()
ret4 = session.query(Tag).filter_by(title="Python").first()
print(ret1, ret2, ret3, ret4)
# ============洗掉===========
session.query(Tag).filter_by(id=1).delete()
session.commit()
# ===========修改===========
session.query(Tag).filter_by(id=22).update({Tag.title: "LOL"})
session.query(Tag).filter_by(id=23).update({"title": "吃雞"})
session.query(Tag).filter_by(id=24).update({"title": Tag.title + "~"}, synchronize_session=False)
# synchronize_session="evaluate" 默認值進行數字加減
session.commit()
2. 基本增刪改查
# 3. 常用操作
# 條件查詢
ret1 = session.query(Tag).filter_by(id=22).first()
ret2 = session.query(Tag).filter(Tag.id > 1, Tag.title == "LOL").all()
ret3 = session.query(Tag).filter(Tag.id.between(22, 24)).all()
ret4 = session.query(Tag).filter(~Tag.id.in_([22, 24])).first()
from sqlalchemy import and_, or_
ret5 = session.query(Tag).filter(and_(Tag.id > 1, Tag.title == "LOL")).first()
ret6 = session.query(Tag).filter(or_(Tag.id > 1, Tag.title == "LOL")).first()
ret7 = session.query(Tag).filter(or_(
Tag.id>1,
and_(Tag.id>3, Tag.title=="LOL")
)).all()
# 通配符
ret8 = session.query(Tag).filter(Tag.title.like("L%")).all()
ret9 = session.query(Tag).filter(~Tag.title.like("L%")).all()
# 限制
ret10 = session.query(Tag).filter(~Tag.title.like("L%")).all()[1:2]
# 排序
ret11 = session.query(Tag).order_by(Tag.id.desc()).all() # 倒序
ret12 = session.query(Tag).order_by(Tag.id.asc()).all() # 正序
# 分組
ret13 = session.query(Tag.test).group_by(Tag.test).all()
# 聚合函式
from sqlalchemy.sql import func
ret14 = session.query(
func.max(Tag.id),
func.sum(Tag.test),
func.min(Tag.id)
).group_by(Tag.title).having(func.max(Tag.id > 22)).all()
# 連表
# print(ret15) 得到一個串列套元組 元組里是兩個物件
# [(user_obj1, hobby_obj1), (user_obj2, hobby_obj2), ]
ret15 = session.query(UserInfo, Hobby).filter(UserInfo.hobby_id == Hobby.id).all()
# print(ret16) 得到串列里面是前一個物件,join相當于inner join
# [user_obj1, user_obj2, ]
ret16 = session.query(UserInfo).join(Hobby).all()
# 相當于inner join
# for i in ret16:
# # print(i[0].name, i[1].title)
# print(i.hobby.title)
# 指定isouter=True相當于left join
ret17 = session.query(Hobby).join(UserInfo, isouter=True).all()
ret17_1 = session.query(UserInfo).join(Hobby, isouter=True).all()
# 或者直接用outerjoin也是相當于left join
ret18 = session.query(Hobby).outerjoin(UserInfo).all()
ret18_1 = session.query(UserInfo).outerjoin(Hobby).all()
print(ret17)
print(ret17_1)
print(ret18)
print(ret18_1)
3. 常用操作
# 4. 基于relationship的ForeignKey
# 添加
user_obj = UserInfo(name="提莫", hobby=Hobby(title="種蘑菇"))
session.add(user_obj)
hobby = Hobby(title="彈奏一曲")
hobby.user = [UserInfo(name="琴女"), UserInfo(name="妹紙")]
# hobby.user = [session.query(UserInfo).filter_by(id=1).first(), ]
session.add(hobby)
session.commit()
# 基于relationship的正向查詢
user_obj_1 = session.query(UserInfo).first()
print(user_obj_1.name)
print(user_obj_1.hobby.title)
# 基于relationship的反向查詢
hb = session.query(Hobby).first()
print(hb.title)
for i in hb.user:
print(i.name)
session.close()
4. 基于relationship的ForeignKey
基于relationship的M2M
# 5. 基于relationship的M2M
# 添加
# 直接給中間表添加
book_obj = Book(title="Python原始碼剖析")
tag_obj = Tag(title="Python")
b2t = Book2Tag(book_id=book_obj.id, tag_id=tag_obj.id)
session.add_all([
book_obj,
tag_obj,
b2t,
])
session.commit()
# 通過反向欄位添加
book = Book(title="測驗")
book.tags = [Tag(title="測驗標簽1"), Tag(title="測驗標簽2")]
# book.tags = [session.query(Tag).filter_by(id=1).first(), ]
session.add(book)
session.commit()
tag = Tag(title="LOL")
tag.books = [Book(title="大龍重繪時間"), Book(title="小龍重繪時間")]
session.add(tag)
session.commit()
# 基于relationship的正向查詢
book_obj = session.query(Book).filter_by(id=4).first()
print(book_obj.title)
print(book_obj.tags)
# 基于relationship的反向查詢
tag_obj = session.query(Tag).first()
print(tag_obj.title)
print(tag_obj.books)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/88141.html
標籤:Python
上一篇:python爬蟲 response.text 和 response.content的區別
下一篇:cv2處理圖片的模板