前言
一般我們都會將資料爬取下來保存在臨時檔案或者控制臺直接輸出,但對于超大規模資料的快速讀寫,高并發場景的訪問,用資料庫管理無疑是不二之選,首先簡單描述一下MySQL和MongoDB的區別:MySQL與MongoDB都是開源的常用資料庫,MySQL是傳統的關系型資料庫,MongoDB則是非關系型資料庫,也叫檔案型資料庫,是一種NoSQL的資料庫,它們各有各的優點,我們所熟知的那些SQL陳述句就不適用于MongoDB了,因為SQL陳述句是關系型資料庫的標準語言,
一、關系型資料庫
關系模型就是指二維表格模型,因而一個關系型資料庫就是由二維表及其之間的聯系組成的一個資料組織,常見的有:Oracle、DB2、PostgreSQL、Microsoft SQL Server、Microsoft Access、MySQL、浪潮K-DB 等
MySQL:
1、在不同的引擎上有不同的存盤方式,
2、查詢陳述句是使用傳統的sql陳述句,擁有較為成熟的體系,成熟度很高,
3、開源資料庫的份額在不斷增加,mysql的份額頁在持續增長,
4、缺點就是在海量資料處理的時候效率會顯著變慢,
二、非關系型資料庫
非關系型資料庫(nosql ),屬于檔案型資料庫,檔案的資料庫:即可以存放xml、json、bson型別的資料,這些資料具備自述性,呈現分層的樹狀資料結構,資料結構由鍵值(key=>value)對組成,常見的有:NoSql、Cloudant、MongoDB、redis、HBase,
NoSQL(Not only SQL),泛指非關系型的資料庫,隨著互聯網 web2.0 網站的興起,傳統的關系資料庫在應付 web2.0 網站,特別是超大規模和高并發的 SNS 型別的 web2.0 純動態網站已經顯得力不從心,暴露了很多難以克服的問題,而非關系型的資料庫則由于其本身的特點得到了非常迅速的發展,NoSQL 資料庫的產生就是為了解決大規模資料集合多重資料種類帶來的挑戰,尤其是大資料應用難題,非關系型資料庫可以為大資料建立快速、可擴展的存盤庫,
MongoDB
1、存盤方式:虛擬記憶體+持久化,
2、查詢陳述句:是獨特的MongoDB的查詢方式,
3、適合場景:事件的記錄,內容管理或者博客平臺等等,
4、架構特點:可以通過副本集,以及分片來實作高可用,
5、資料處理:資料是存盤在硬碟上的,只不過需要經常讀取的資料會被加載到記憶體中,將資料存盤在物理記憶體中,從而達到高速讀寫,
6、成熟度與廣泛度:新興資料庫,成熟度較低,Nosql資料庫中最為接近關系型資料庫,比較完善的DB之一,適用人群不斷在增長,
三、MongoDB優勢與劣勢
優勢:
1、快速, 在適量級的記憶體的MongoDB的性能是非常迅速的,它將熱資料存盤在物理記憶體中,使得熱資料的讀寫變得十分快,
2、高擴展性, MongoDB的高可用和集群架構擁有十分高的擴展性,
3、自身的FaiLover機制, 在副本集中,當主庫遇到問題,無法繼續提供服務的時候,副本集將選舉一個新的主庫繼續提供服務,
4、Json的存盤格式, MongoDB的Bson和JSon格式的資料十分適合檔案格式的存盤與查詢,
劣勢:
1、 不支持事務操作,MongoDB本身沒有自帶事務機制,若需要在MongoDB中實作事務機制,需通過一個額外的表,從邏輯上自行實作事務,
2、 應用經驗少,由于NoSQL興起時間短,應用經驗相比關系型資料庫較少,
3、MongoDB占用空間過大,
四、MySQL優勢與劣勢
優勢:
1、在不同的引擎上有不同 的存盤方式,
2‘、查詢陳述句是使用傳統的sql陳述句,擁有較為成熟的體系,成熟度很高,
3、開源資料庫的份額在不斷增加,mysql的份額頁在持續增長,
劣勢:
1、在海量資料處理的時候效率會顯著變慢,
五、Mysql和Mongodb主要應用場景
1.如果需要將mongodb作為后端db來代替mysql使用,即這里mysql與mongodb 屬于平行級別,那么,這樣的使用可能有以下幾種情況的考量:
(1) mongodb所負責部分以檔案形式存盤,能夠有較好的代碼親和性,json格式的直接寫入方便,(如日志之類)
(2) 從datamodels設計階段就將原子性考慮于其中,無需事務之類的輔助,開發用如nodejs之類的語言來進行開發,對開發比較方便,
(3) mongodb本身的failover機制,無需使用如MHA之類的方式實作,
2.將mongodb作為類似redis ,memcache來做快取db,為mysql提供服務,或是后端日志收集分析, 考慮到mongodb屬于nosql型資料庫,sql陳述句與資料結構不如mysql那么親和 ,也會有很多時候將mongodb做為輔助mysql而使用的類redis memcache 之類的快取db來使用, 亦或是僅作日志收集分析,
六、對比
| 資料庫名 | MongoDB | MySQL |
| 資料庫模型 | 非關系型 | 關系型 |
| 存盤方式 | 以類JSON的檔案的格式存盤(虛擬記憶體+持久化) | 不同引擎有不同的存盤方式 |
| 查詢陳述句 | MongoDB查詢方式(包含類似JavaScript的函式) | 傳統SQL陳述句 |
| 資料處理方式 | 基于記憶體,將熱資料存放在物理記憶體中,從而達到高速讀寫 | 不同引擎有自己的特點 |
| 架構特點 | 可以通過副本集,以及分片來實作高可用 | 常見有單點,M-S,MHA.MMMCluster等架構方式 |
| 成熟度 | 新興資料庫,成熟度較低 | 成熟度高 |
| 廣泛度 | NoSQL資料庫中,比較完善且開源,使用人數在不斷增長 | 開源資料庫,市場份額不斷增長 |
| 事務性 | 僅支持單檔案事務操作,弱一致性 | 支持事務操作 |
| 占用空間 | 占用空間大 | 占用空間小 |
| join操作 | MongoDB沒有join | MySQL支持join |
七、scrapy爬取貓眼電影排行榜海量資料,并法將其保存在本地Mysql和MongoDB中,
1. 創建虛擬環境,在適當的目錄創建專案 本案例專案名 mongodb 創建專案命令 :scrapy startproject myfrist(your_project_name)(scrapy startproject mongodb)用pycharm打開專案所在目錄,并在終端輸入 scrapy gendpider maoyan maoyan.com(以貓眼電影網頁為例) 創建爬蟲, 創建爬蟲命令 :scrapy genspider 爬蟲名 爬蟲的地址 ,完整專案結構如下: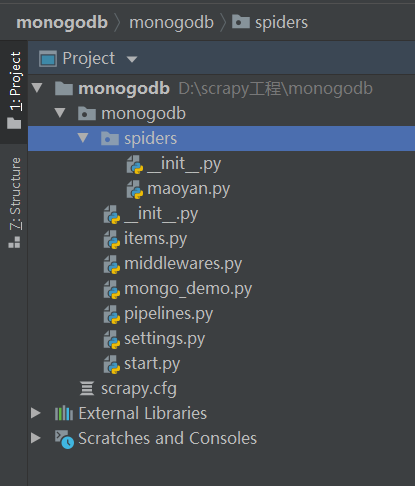
2.思路:先訪問首頁的排行榜,可以提取出首頁排行的電影名和得分(每頁三十個資料),在首頁中提取下一頁標簽的href,不斷推送,就可以回圈爬取啦,

maoyan.py代碼如下:
1 import scrapy 2 3 4 class MaoyanSpider(scrapy.Spider): 5 name = 'maoyan' 6 allowed_domains = ['maoyan.com'] 7 start_urls = ['https://maoyan.com/films?showType=3&offset=0'] 8 count = 0 9 NUM_PAGE = 3 # 默認爬前三頁 10 11 def parse(self, response): 12 if self.count == self.NUM_PAGE: # 控制抓取的頁數 例如只抓取前三頁就回圈三次 13 return 14 names = response.xpath('//dd/div[@]/@title').extract() 15 grades = [div.xpath('string(.)').extract_first() for div in response.xpath('//dd/div[@]')] 17 next_url = response.xpath('//ul[@]/li[last()]/a/@href').extract_first() # 匹配父標簽下相同子標簽的最后一個 18 for name, grade in zip(names, grades): 19 # 把資料推送給pipeline管道 20 yield { 21 'name': name, 22 'grade': grade 23 } 24 yield scrapy.Request(response.urljoin(next_url), callback=self.parse) 25 self.count += 1
3.資料的保存是在pipelines.py模塊中,代碼如下,
from pymongo import MongoClient from pymysql import connect class MonogodbPipeline: """ 資料庫名:maoyan 資料表名:t_maoyan_movie 可以事先不用創建,python會自動創建資料庫和資料表 """ def open_spider(self, spider): self.client = MongoClient('localhost', 27017) self.db = self.client.maoyan self.collection = self.db.t_maoyan_movie def process_item(self, item, spider): self.collection.insert(item) return item def close_spider(self, spider): self.client.close() class MySQLPipeline: """ 資料庫名:maoyan 資料表名:t_maoyan_movie mysql需要自己手動創建資料庫和相對應的資料表 """ def open_spider(self, spider): self.client = connect(host='localhost', port=3306, user='root', password='root', database='maoyan', charset='utf8') # 創建游標 self.cursor = self.client.cursor() def process_item(self, item, spider): sql = 'insert into t_maoyan_movie values(0,%s,%s) ' self.cursor.execute(sql, [item['name'], item['grade']]) self.client.commit() return item def close_spider(self, spider): self.cursor.close() self.client.close()
4. setting.py中設定配置,想保存哪個資料庫就引入并開啟哪個中間件,也可以兩個一起開啟,setting中如下設定:
from fake_useragent import UserAgent # 偷懶的寫法,一般自己定義USER-AGENT中間件 USER_AGENT = UserAgent().chrome ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3 # 隔三秒爬一次
ITEM_PIPELINES = { 'monogodb.pipelines.MonogodbPipeline': 300, 'monogodb.pipelines.MySQLPipeline': 301, }
5. 創建mysql資料庫和資料表 注意: python會自動創建mongodb資料庫和對應collection,但mysql需要先手動創建,如果嫌命令創建麻煩,完全可以使用Navicat連接資料庫界面操作,
1.連接mysql cmd中 命令: mysql -u root -p root
2. 創建資料庫: create database maoyan charser ''utf8 (庫名必須和代碼中庫名一致)
3.切換到已創建資料庫創建表:user maoyan
4. 創建表
create table t_maoyan_movie (id int primary key auto_increment,name varchar(20), grade varchar(20));
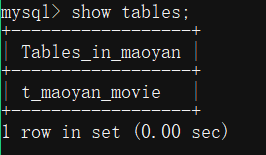
6. 執行程式插入資料
創建start.py檔案,并執行
from scrapy.cmdline import execute execute('scrapy crawl maoyan'.split())
也可以在終端中輸入: scrapy crawl maoyan
7.結果:
1.mysql中結果
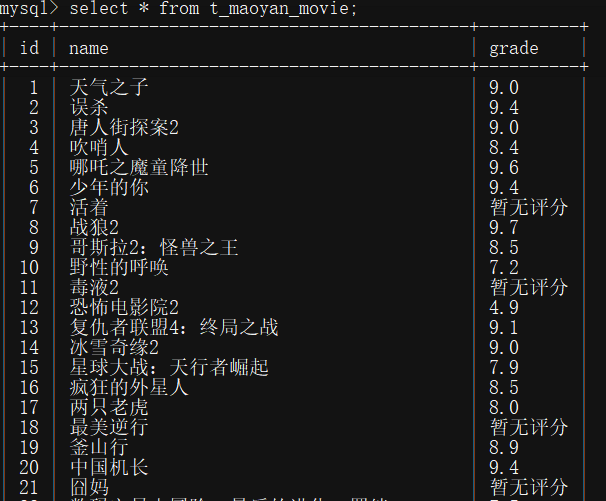
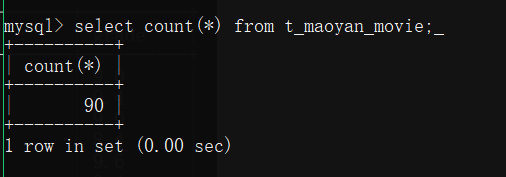
可以看到有90條資料,因為只爬了前三頁,一頁30條,可以在程式中選擇頁數,
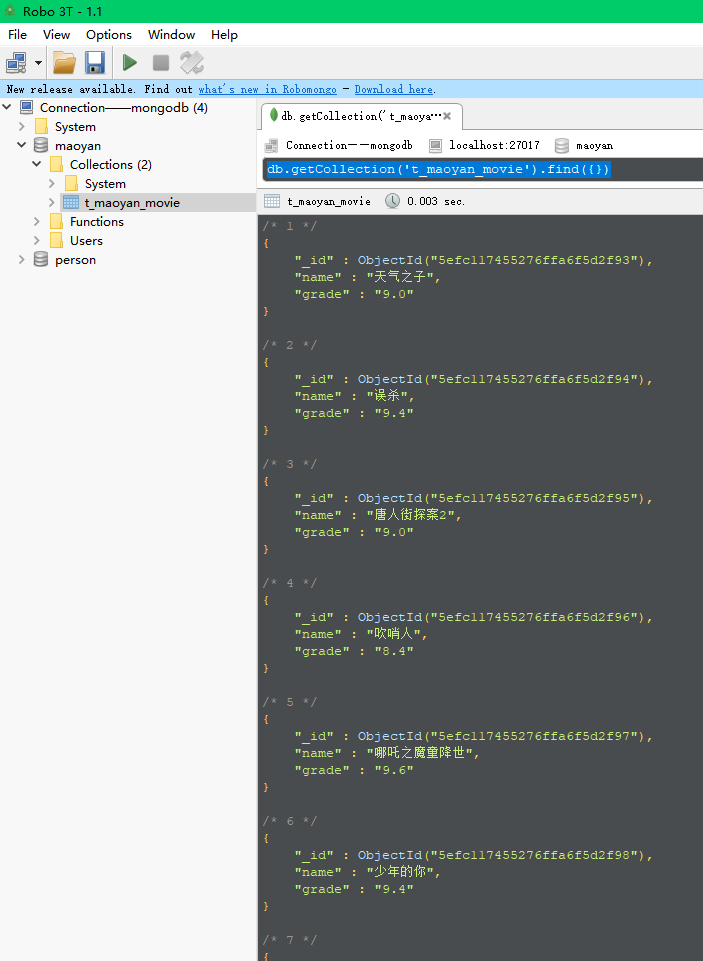
mongodb中結果:
打開Robo 3T, 執行 db.getCollection('t_maoyan_movie').find({})
可以看到電影資訊啦
執行 db.getCollection('t_maoyan_movie').find({}).count()

可以看到依然有90條資料,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/95148.html
標籤:Python