在前面我們學習了 Selenium 的基本用法,它功能的確非常強大,但很多時候我們會發現 Selenium 有一些不太方便的地方,比如環境的配置,得安裝好相關瀏覽器,比如 Chrome、Firefox 等等,然后還要到官方網站去下載對應的驅動,最重要的還需要安裝對應的 Python Selenium 庫,而且版本也得好好看看是否對應,確實不是很方便,另外如果要做大規模部署的話,環境配置的一些問題也是個頭疼的事情,
那么本課時我們就介紹另一個類似的替代品,叫作 Pyppeteer,注意,是叫作 Pyppeteer,而不是 Puppeteer,
1.Pyppeteer 介紹
Puppeteer 是 Google 基于 Node.js 開發的一個工具,有了它我們可以通過 JavaScript 來控制 Chrome 瀏覽器的一些操作,當然也可以用作網路爬蟲上,其 API 極其完善,功能非常強大,Selenium 當然同樣可以做到,
而 Pyppeteer 又是什么呢?它實際上是 Puppeteer 的 Python 版本的實作,但它不是 Google 開發的,是一位來自于日本的工程師依據 Puppeteer 的一些功能開發出來的非官方版本,
在 Pyppetter 中,實際上它背后也是有一個類似 Chrome 瀏覽器的 Chromium 瀏覽器在執行一些動作進行網頁渲染,首先說下 Chrome 瀏覽器和 Chromium 瀏覽器的淵源,
Chromium 是谷歌為了研發 Chrome 而啟動的專案,是完全開源的,二者基于相同的源代碼構建,Chrome 所有的新功能都會先在
Chromium 上實作,待驗證穩定后才會移植,因此 Chromium
的版本更新頻率更高,也會包含很多新的功能,但作為一款獨立的瀏覽器,Chromium
的用戶群體要小眾得多,兩款瀏覽器“同根同源”,它們有著同樣的 Logo,但配色不同,Chrome 由藍紅綠黃四種顏色組成,而
Chromium 由不同深度的藍色構成,

Pyppeteer 就是依賴于 Chromium 這個瀏覽器來運行的,那么有了 Pyppeteer 之后,我們就可以免去那些煩瑣的環境配置等問題,如果第一次運行的時候,Chromium 瀏覽器沒有安裝,那么程式會幫我們自動安裝和配置,就免去了煩瑣的環境配置等作業,另外 Pyppeteer 是基于 Python 的新特性 async 實作的,所以它的一些執行也支持異步操作,效率相對于 Selenium 來說也提高了,
那么下面就讓我們來一起了解下 Pyppeteer 的相關用法吧,
2.安裝
首先就是安裝問題了,由于 Pyppeteer 采用了 Python 的 async 機制,所以其運行要求的 Python 版本為 3.5 及以上,
安裝方式非常簡單:
pip3 install pyppeteer
好了,安裝完成之后我們在命令列下測驗:
import pyppeteer
如果沒有報錯,那么就證明安裝成功了,
快速上手
接下來我們測驗基本的頁面渲染操作,這里我們選用的網址為:https://dynamic2.scrape.cuiqingcai.com/,如圖所示,
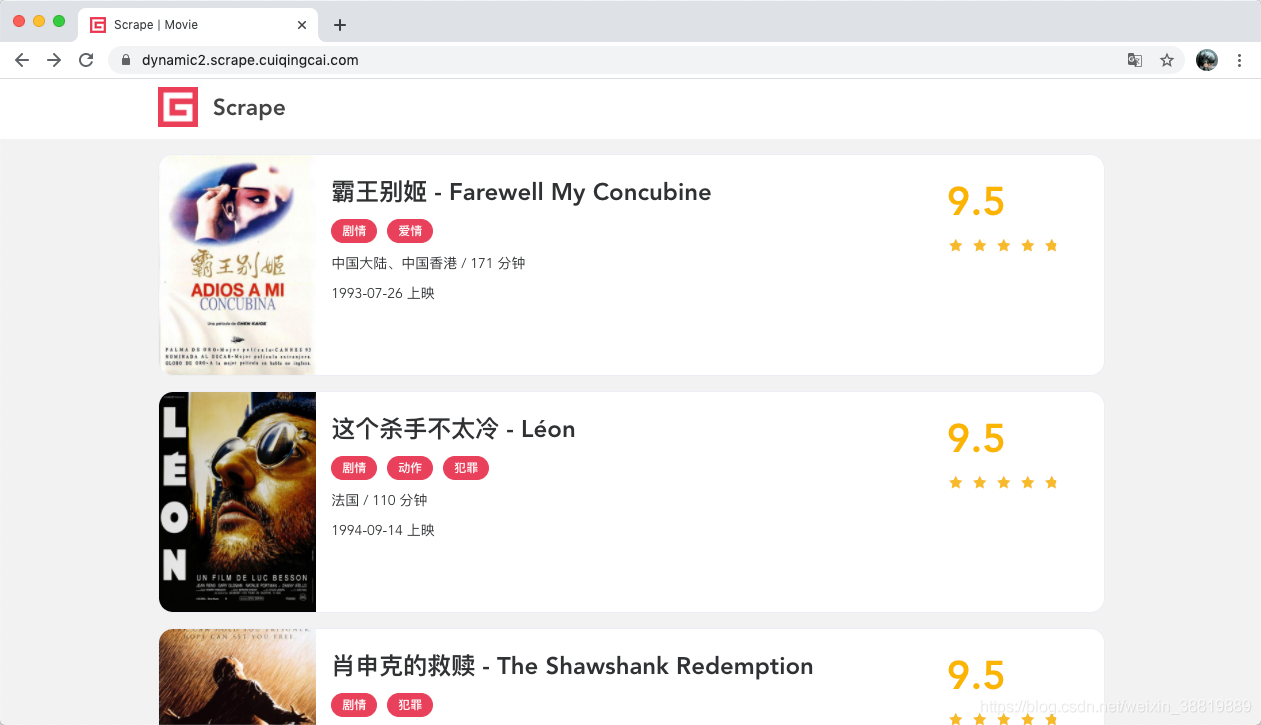
這個網站我們在之前的 Selenium 爬取實戰課時中已經分析過了,整個頁面是用 JavaScript 渲染出來的,同時一些 Ajax 介面還帶有加密引數,所以這個網站的頁面我們無法直接使用 requests 來抓取看到的資料,同時我們也不太好直接模擬 Ajax 來獲取資料,
所以前面一課時我們介紹了使用 Selenium 爬取的方式,其原理就是模擬瀏覽器的操作,直接用瀏覽器把頁面渲染出來,然后再直接獲取渲染后的結果,同樣的原理,用 Pyppeteer 也可以做到,
下面我們用 Pyppeteer 來試試,代碼就可以寫為如下形式:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
doc = pq(await page.content())
names = [item.text() for item in doc('.item .name').items()]
print('Names:', names)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
運行結果:
Names: ['霸王別姬 - Farewell My Concubine', '這個殺手不太冷 - Léon', '肖申克的救贖 - The Shawshank Redemption', '泰坦尼克號 - Titanic', '羅馬假日 - Roman Holiday', '唐伯虎點秋香 - Flirting Scholar', '亂世佳人 - Gone with the Wind', '喜劇之王 - The King of Comedy', '楚門的世界 - The Truman Show', '獅子王 - The Lion King']
先初步看下代碼,大體意思是訪問了這個網站,然后等待 .item .name 的節點加載出來,隨后通過 pyquery 從網頁原始碼中提取了電影的名稱并輸出,最后關閉 Pyppeteer,
看運行結果,和之前的 Selenium 一樣,我們成功模擬加載出來了頁面,然后提取到了首頁所有電影的名稱,
那么這里面的具體程序發生了什么?我們來逐行看下,
- launch 方法會新建一個 Browser 物件,其執行后最侄訓得到一個 Browser 物件,然后賦值給 browser,這一步就相當于啟動了瀏覽器,
- 然后 browser 呼叫 newPage 方法相當于瀏覽器中新建了一個選項卡,同時新建了一個 Page 物件,這時候新啟動了一個選項卡,但是還未訪問任何頁面,瀏覽器依然是空白,
- 隨后 Page 物件呼叫了 goto 方法就相當于在瀏覽器中輸入了這個 URL,瀏覽器跳轉到了對應的頁面進行加載,
- Page 物件呼叫 waitForSelector 方法,傳入選擇器,那么頁面就會等待選擇器所-對應的節點資訊加載出來,如果加載出來了,立即回傳,否則會持續等待直到超時,此時如果順利的話,頁面會成功加載出來,
- 頁面加載完成之后再呼叫 content 方法,可以獲得當前瀏覽器頁面的源代碼,這就是 JavaScript 渲染后的結果,
- 然后進一步的,我們用 pyquery 進行決議并提取頁面的電影名稱,就得到最終結果了,
另外其他的一些方法如呼叫 asyncio 的 get_event_loop 等方法的相關操作則屬于 Python 異步 async 相關的內容了,你如果不熟悉可以了解下前面所講的異步相關知識,
好,通過上面的代碼,我們同樣也可以完成 JavaScript 渲染頁面的爬取了,怎么樣?代碼相比 Selenium 是不是更簡潔易讀,而且環境配置更加方便,在這個程序中,我們沒有配置 Chrome 瀏覽器,也沒有配置瀏覽器驅動,免去了一些煩瑣的步驟,同樣達到了 Selenium 的效果,還實作了異步抓取,
接下來我們再看看另外一個例子,這個例子設定了瀏覽器視窗大小,然后模擬了網頁截圖,另外還可以執行自定義的 JavaScript 獲得特定的內容,代碼如下:
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch()
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
await asyncio.sleep(2)
await page.screenshot(path='example.png')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
這里我們又用到了幾個新的 API,完成了頁面視窗大小設定、網頁截圖保存、執行 JavaScript 并回傳對應資料,
首先 screenshot 方法可以傳入保存的圖片路徑,另外還可以指定保存格式 type、清晰度 quality、是否全屏 fullPage、裁切 clip 等各個引數實作截圖,
截圖的樣例如下:
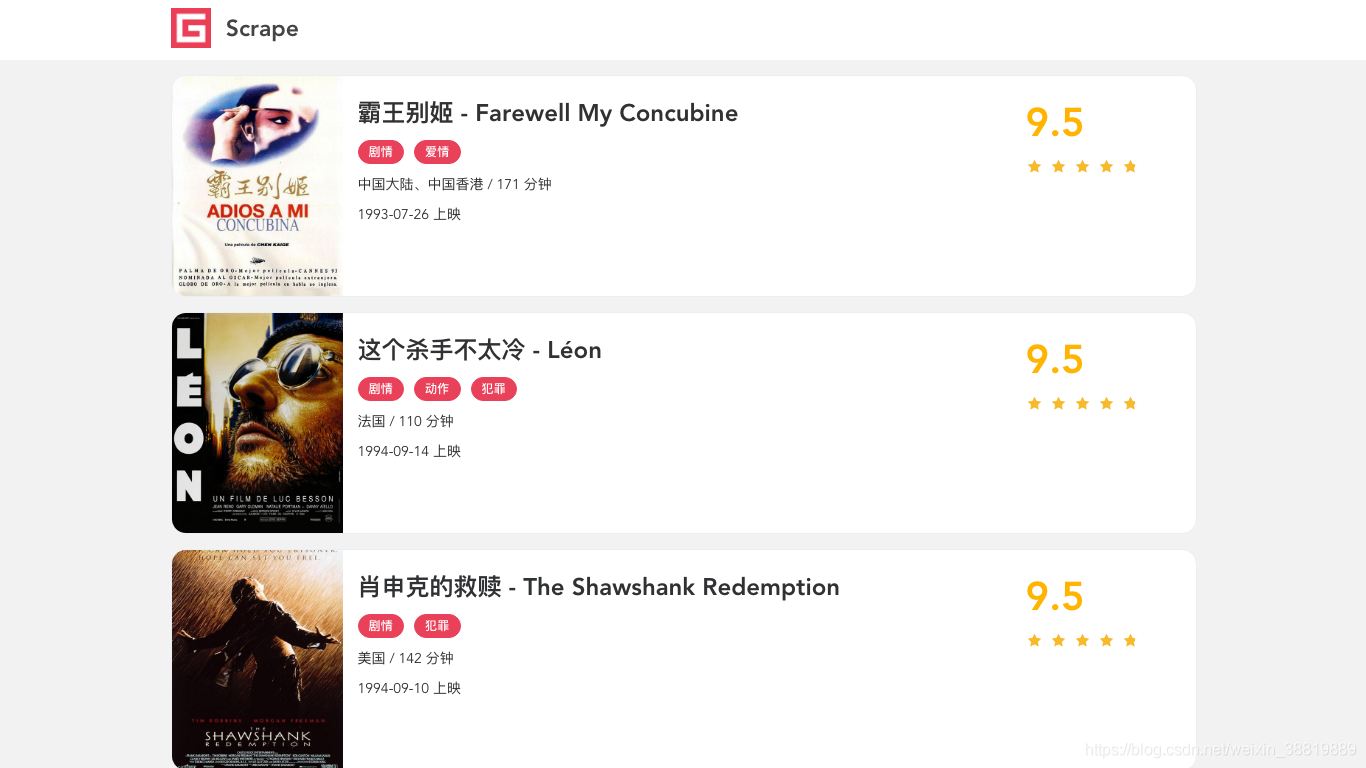
可以看到它回傳的就是 JavaScript 渲染后的頁面,和我們在瀏覽器中看到的結果是一模一樣的,
最后我們又呼叫了 evaluate 方法執行了一些 JavaScript,JavaScript 傳入的是一個函式,使用 return 方法回傳了網頁的寬高、像素大小比率三個值,最后得到的是一個 JSON 格式的物件,內容如下:
{'width': 1366, 'height': 768, 'deviceScaleFactor': 1}
OK,實體就先感受到這里,還有太多太多的功能還沒提及,
總之利用 Pyppeteer 我們可以控制瀏覽器執行幾乎所有動作,想要的操作和功能基本都可以實作,用它來自由地控制爬蟲當然就不在話下了,
3.詳細用法
了解了基本的實體之后,我們再來梳理一下 Pyppeteer 的一些基本和常用操作,Pyppeteer 的幾乎所有功能都能在其官方檔案的 API Reference 里面找到,鏈接為:https://miyakogi.github.io/pyppeteer/reference.html,用到哪個方法就來這里查詢就好了,引數不必死記硬背,即用即查就好,
3.1 launch
使用 Pyppeteer 的第一步便是啟動瀏覽器,首先我們看下怎樣啟動一個瀏覽器,其實就相當于我們點擊桌面上的瀏覽器圖示一樣,把它運行起來,用 Pyppeteer 完成同樣的操作,只需要呼叫 launch 方法即可,
我們先看下 launch 方法的 API,鏈接為:https://miyakogi.github.io/pyppeteer/reference.html#pyppeteer.launcher.launch,其方法定義如下:
pyppeteer.launcher.launch(options: dict = None, **kwargs) → pyppeteer.browser.Browser
可以看到它處于 launcher 模塊中,引數沒有在宣告中特別指定,回傳型別是 browser 模塊中的 Browser 物件,另外觀察原始碼發現這是一個 async 修飾的方法,所以呼叫它的時候需要使用 await,
接下來看看它的引數:
- ignoreHTTPSErrors (bool):是否要忽略 HTTPS 的錯誤,默認是 False,
- headless (bool):是否啟用 Headless 模式,即無界面模式,如果 devtools 這個引數是 True 的話,那么該引數就會被設定為 False,否則為 True,即默認是開啟無界面模式的,
- executablePath (str):可執行檔案的路徑,如果指定之后就不需要使用默認的 Chromium 了,可以指定為已有的 Chrome 或 Chromium,
- slowMo (int|float):通過傳入指定的時間,可以級訓 Pyppeteer 的一些模擬操作,
args (List[str]):在執行程序中可以傳入的額外引數, - ignoreDefaultArgs (bool):不使用 Pyppeteer 的默認引數,如果使用了這個引數,那么最好通過 args 引數來設定一些引數,否則可能會出現一些意想不到的問題,這個引數相對比較危險,慎用,
- handleSIGINT (bool):是否回應 SIGINT 信號,也就是可以使用 Ctrl + C 來終止瀏覽器程式,默認是 True,
- handleSIGTERM (bool):是否回應 SIGTERM 信號,一般是 kill 命令,默認是 True,
- handleSIGHUP (bool):是否回應 SIGHUP 信號,即掛起信號,比如終端退出操作,默認是 True,
- dumpio (bool):是否將 Pyppeteer 的輸出內容傳給 process.stdout 和 process.stderr 物件,默認是 False,
- userDataDir (str):即用戶資料檔案夾,即可以保留一些個性化配置和操作記錄,
env (dict):環境變數,可以通過字典形式傳入, - devtools (bool):是否為每一個頁面自動開啟除錯工具,默認是 False,如果這個引數設定為 True,那么 headless 引數就會無效,會被強制設定為 False,
- logLevel (int|str):日志級別,默認和 root logger 物件的級別相同,
- autoClose (bool):當一些命令執行完之后,是否自動關閉瀏覽器,默認是 True,
- loop (asyncio.AbstractEventLoop):事件回圈物件,
好了,知道這些引數之后,我們可以先試試看,
3.2 無頭模式
首先可以試用下最常用的引數 headless,如果我們將它設定為 True 或者默認不設定它,在啟動的時候我們是看不到任何界面的,如果把它設定為 False,那么在啟動的時候就可以看到界面了,一般我們在除錯的時候會把它設定為 False,在生產環境上就可以設定為 True,我們先嘗試一下關閉 headless 模式:
import asyncio
from pyppeteer import launch
async def main():
await launch(headless=False)
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
運行之后看不到任何控制臺輸出,但是這時候就會出現一個空白的 Chromium 界面了:
但是可以看到這就是一個光禿禿的瀏覽器而已,看一下相關資訊:
看到了,這就是 Chromium,上面還寫了開發者內部版本,你可以認為是開發版的 Chrome 瀏覽器就好,
3.3 除錯模式
另外我們還可以開啟除錯模式,比如在寫爬蟲的時候會經常需要分析網頁結構還有網路請求,所以開啟除錯工具還是很有必要的,我們可以將 devtools 引數設定為 True,這樣每開啟一個界面就會彈出一個除錯視窗,非常方便,示例如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(devtools=True)
page = await browser.newPage()
await page.goto('https://www.baidu.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
剛才說過 devtools 這個引數如果設定為了 True,那么 headless 就會被關閉了,界面始侄訓顯現出來,在這里我們新建了一個頁面,打開了百度,界面運行效果如下:

3.4 禁用提示條
這時候我們可以看到上面的一條提示:“Chrome 正受到自動測驗軟體的控制”,這個提示條有點煩,那該怎樣關閉呢?這時候就需要用到 args 引數了,禁用操作如下:
browser = await launch(headless=False, args=['--disable-infobars'])
這里就不再寫完整代碼了,就是在 launch 方法中,args 引數通過 list 形式傳入即可,這里使用的是 --disable-infobars 的引數,
3.5 防止檢測
你可能會說,如果你只是把提示關閉了,有些網站還是會檢測到是 WebDriver 吧,比如拿之前的檢測 WebDriver 的案例 https://antispider1.scrape.cuiqingcai.com/ 來驗證下,我們可以試試:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.goto('https://antispider1.scrape.cuiqingcai.com/')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
果然還是被檢測到了,頁面如下:
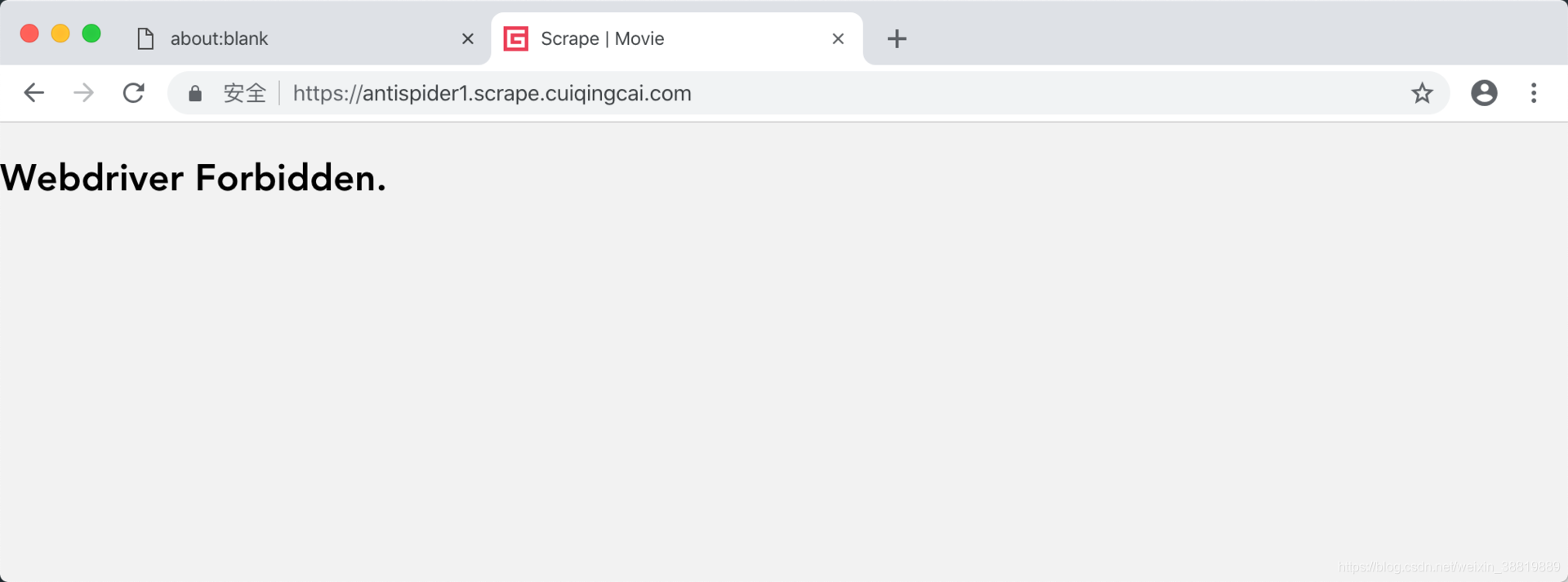
這說明 Pyppeteer 開啟 Chromium 照樣還是能被檢測到 WebDriver 的存在,
那么此時如何規避呢?Pyppeteer 的 Page 物件有一個方法叫作 evaluateOnNewDocument,意思就是在每次加載網頁的時候執行某個陳述句,所以這里我們可以執行一下將 WebDriver 隱藏的命令,改寫如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.evaluateOnNewDocument('Object.defineProperty(navigator, "webdriver", {get: () => undefined})')
await page.goto('https://antispider1.scrape.cuiqingcai.com/')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
這里我們可以看到整個頁面就可以成功加載出來了,如圖所示,
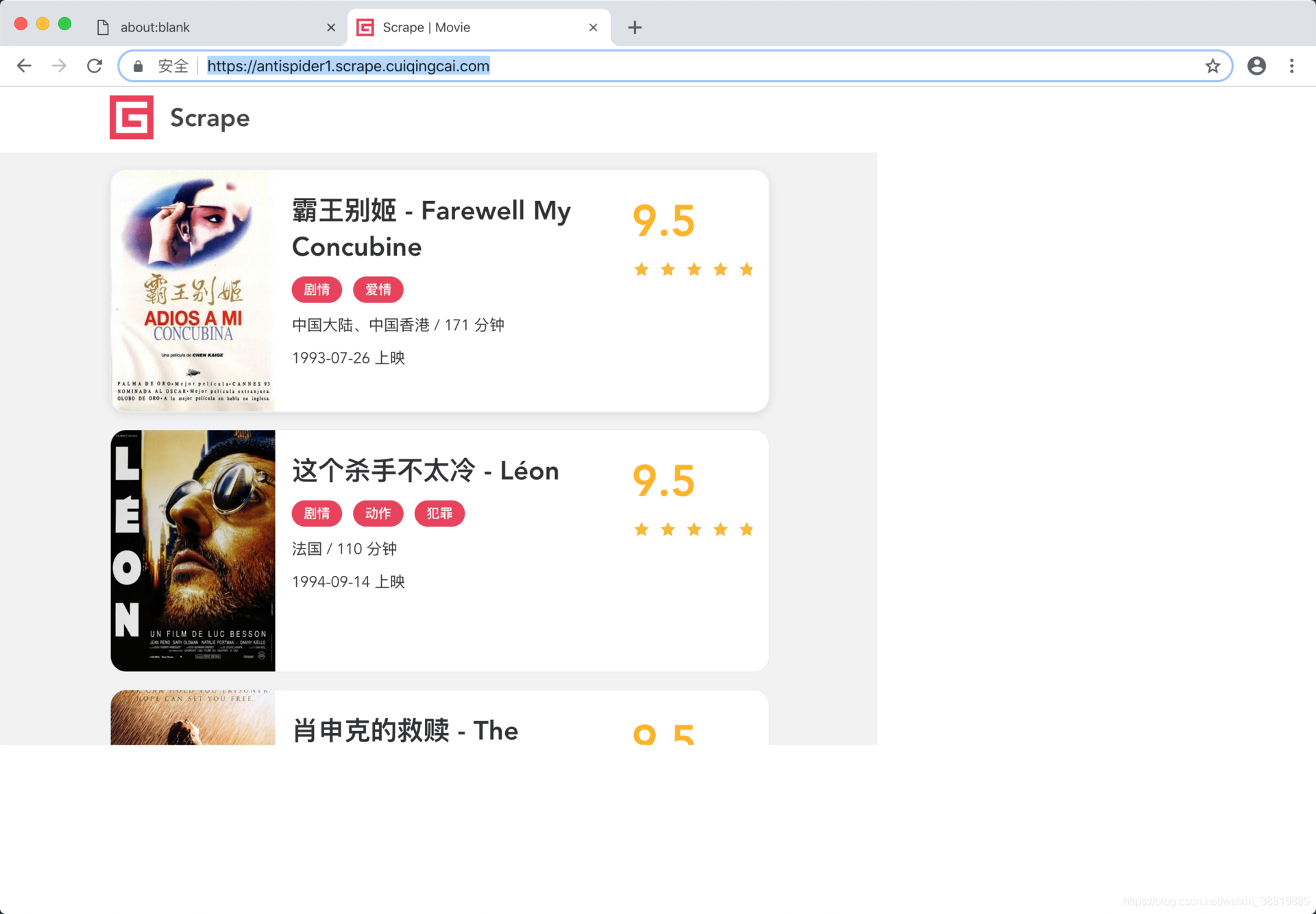
我們發現頁面就成功加載出來了,繞過了 WebDriver 的檢測,
3.6 頁面大小設定
在上面的例子中,我們還發現了頁面的顯示 bug,整個瀏覽器視窗比顯示的內容視窗要大,這個是某些頁面會出現的情況,
對于這種情況,我們通過設定視窗大小就可以解決,可以通過 Page 的 setViewport 方法設定,代碼如下:
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch(headless=False, args=['--disable-infobars', f'--window-size={width},{height}'])
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.evaluateOnNewDocument('Object.defineProperty(navigator, "webdriver", {get: () => undefined})')
await page.goto('https://antispider1.scrape.cuiqingcai.com/')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
這里我們同時設定了瀏覽器視窗的寬高以及顯示區域的寬高,使得二者一致,最后發現顯示就正常了,如圖所示,
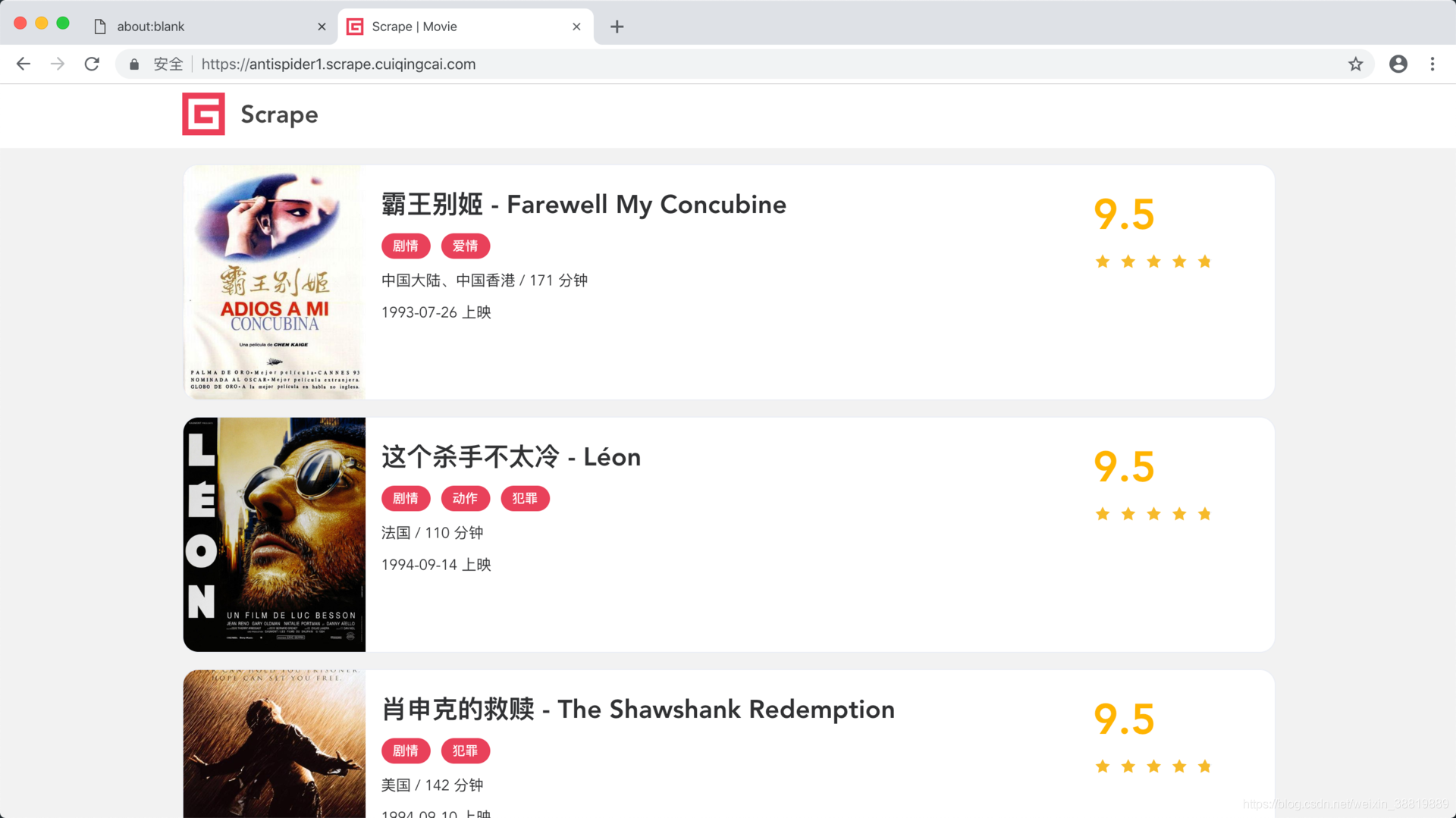
3.7 用戶資料持久化
剛才我們可以看到,每次我們打開 Pyppeteer 的時候都是一個新的空白的瀏覽器,而且如果遇到了需要登錄的網頁之后,如果我們這次登錄上了,下一次再啟動又是空白了,又得登錄一次,這的確是一個問題,
比如以淘寶舉例,平時我們逛淘寶的時候,在很多情況下關閉了瀏覽器再打開,淘寶依然還是登錄狀態,這是因為淘寶的一些關鍵 Cookies 已經保存到本地了,下次登錄的時候可以直接讀取并保持登錄狀態,
那么這些資訊保存在哪里了呢?其實就是保存在用戶目錄下了,里面不僅包含了瀏覽器的基本配置資訊,還有一些 Cache、Cookies 等各種資訊都在里面,如果我們能在瀏覽器啟動的時候讀取這些資訊,那么啟動的時候就可以恢復一些歷史記錄甚至一些登錄狀態資訊了,
這也就解決了一個問題:很多時候你在每次啟動 Selenium 或 Pyppeteer 的時候總是一個全新的瀏覽器,那這究其原因就是沒有設定用戶目錄,如果設定了它,每次打開就不再是一個全新的瀏覽器了,它可以恢復之前的歷史記錄,也可以恢復很多網站的登錄資訊,
那么這個怎么來做呢?很簡單,在啟動的時候設定 userDataDir 就好了,示例如下:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, userDataDir='./userdata', args=['--disable-infobars'])
page = await browser.newPage()
await page.goto('https://www.taobao.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
好,這里就是加了一個 userDataDir 的屬性,值為 userdata,即當前目錄的 userdata 檔案夾,我們可以首先運行一下,然后登錄一次淘寶,這時候我們同時可以觀察到在當前運行目錄下又多了一個 userdata 的檔案夾,里面的結構是這樣子的:
具體的介紹可以看官方的一些說明,如: https://chromium.googlesource.com/chromium/src/+/master/docs/user_data_dir.md,這里面介紹了 userdatadir 的相關內容,
再次運行上面的代碼,這時候可以發現現在就已經是登錄狀態了,不需要再次登錄了,這樣就成功跳過了登錄的流程,當然可能時間太久了,Cookies 都過期了,那還是需要登錄的,
以上便是 launch 方法及其對應的引數的配置,
3.8 Browser
上面我們了解了 launch 方法,其回傳的就是一個 Browser 物件,即瀏覽器物件,我們會通常將其賦值給 browser 變數,其實它就是 Browser 類的一個實體,
下面我們來看看 Browser 類的定義:
class pyppeteer.browser.Browser(connection: pyppeteer.connection.Connection, contextIds: List[str], ignoreHTTPSErrors: bool, setDefaultViewport: bool, process: Optional[subprocess.Popen] = None, closeCallback: Callable[[], Awaitable[None]] = None, **kwargs)
這里我們可以看到其構造方法有很多引數,但其實多數情況下我們直接使用 launch 方法或 connect 方法創建即可,
browser 作為一個物件,其自然有很多用于操作瀏覽器本身的方法,下面我們來選取一些比較有用的介紹下,
3.8.1 開啟無痕模式
我們知道 Chrome 瀏覽器是有一個無痕模式的,它的好處就是環境比較干凈,不與其他的瀏覽器示例共享 Cache、Cookies 等內容,其開啟方式可以通過 createIncognitoBrowserContext 方法,示例如下:
import asyncio
from pyppeteer import launch
width, height = 1200, 768
async def main():
browser = await launch(headless=False,
args=['--disable-infobars', f'--window-size={width},{height}'])
context = await browser.createIncognitoBrowserContext()
page = await context.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://www.baidu.com')
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
這里關鍵的呼叫就是 createIncognitoBrowserContext 方法,其回傳一個 context 物件,然后利用 context 物件我們可以新建選項卡,
運行之后,我們發現瀏覽器就進入了無痕模式,界面如下:
3.8.2 關閉
怎樣關閉自不用多說了,就是 close 方法,但很多時候我們可能忘記了關閉而造成額外開銷,所以要記得在使用完畢之后呼叫一下 close 方法,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
3.9 Page
Page 即頁面,就對應一個網頁,一個選項卡,在前面我們已經演示了幾個 Page 方法的操作了,這里我們再詳細看下它的一些常用用法,
3.9.1 選擇器
Page 物件內置了一些用于選取節點的選擇器方法,如 J 方法傳入一個選擇器 Selector,則能回傳對應匹配的第一個節點,等價于 querySelector,如 JJ 方法則是回傳符合 Selector 的串列,類似于 querySelectorAll,
下面我們來看下其用法和運行結果,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
j_result1 = await page.J('.item .name')
j_result2 = await page.querySelector('.item .name')
jj_result1 = await page.JJ('.item .name')
jj_result2 = await page.querySelectorAll('.item .name')
print('J Result1:', j_result1)
print('J Result2:', j_result2)
print('JJ Result1:', jj_result1)
print('JJ Result2:', jj_result2)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
在這里我們分別呼叫了 J、querySelector、JJ、querySelectorAll 四個方法,觀察下其運行效果和回傳結果的型別,運行結果:
J Result1: <pyppeteer.element_handle.ElementHandle object at 0x1166f7dd0>
J Result2: <pyppeteer.element_handle.ElementHandle object at 0x1166f07d0>
JJ Result1: [<pyppeteer.element_handle.ElementHandle object at 0x11677df50>, <pyppeteer.element_handle.ElementHandle object at 0x1167857d0>, <pyppeteer.element_handle.ElementHandle object at 0x116785110>,
...
<pyppeteer.element_handle.ElementHandle object at 0x11679db10>, <pyppeteer.element_handle.ElementHandle object at 0x11679dbd0>]
JJ Result2: [<pyppeteer.element_handle.ElementHandle object at 0x116794f10>, <pyppeteer.element_handle.ElementHandle object at 0x116794d10>, <pyppeteer.element_handle.ElementHandle object at 0x116794f50>,
...
<pyppeteer.element_handle.ElementHandle object at 0x11679f690>, <pyppeteer.element_handle.ElementHandle object at 0x11679f750>]
在這里我們可以看到,J、querySelector 一樣,回傳了單個匹配到的節點,回傳型別為 ElementHandle 物件,JJ、querySelectorAll 則回傳了節點串列,是 ElementHandle 的串列,
3.9.2 選項卡操作
前面我們已經演示了多次新建選項卡的操作了,也就是 newPage 方法,那新建了之后怎樣獲取和切換呢,下面我們來看一個例子:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.baidu.com')
page = await browser.newPage()
await page.goto('https://www.bing.com')
pages = await browser.pages()
print('Pages:', pages)
page1 = pages[1]
await page1.bringToFront()
await asyncio.sleep(100)
asyncio.get_event_loop().run_until_complete(main())
在這里我們啟動了 Pyppeteer,然后呼叫了 newPage 方法新建了兩個選項卡并訪問了兩個網站,那么如果我們要切換選項卡的話,只需要呼叫 pages 方法即可獲取所有的頁面,然后選一個頁面呼叫其 bringToFront 方法即可切換到該頁面對應的選項卡,
3.9.3 常見操作
作為一個頁面,我們一定要有對應的方法來控制,如加載、前進、后退、關閉、保存等,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic1.scrape.cuiqingcai.com/')
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
# 后退
await page.goBack()
# 前進
await page.goForward()
# 重繪
await page.reload()
# 保存 PDF
await page.pdf()
# 截圖
await page.screenshot()
# 設定頁面 HTML
await page.setContent('<h2>Hello World</h2>')
# 設定 User-Agent
await page.setUserAgent('Python')
# 設定 Headers
await page.setExtraHTTPHeaders(headers={})
# 關閉
await page.close()
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
這里我們介紹了一些常用方法,除了一些常用的操作,這里還介紹了設定 User-Agent、Headers 等功能,
3.9.4 點擊
Pyppeteer 同樣可以模擬點擊,呼叫其 click 方法即可,比如我們這里以 https://dynamic2.scrape.cuiqingcai.com/ 為例,等待節點加載出來之后,模擬右鍵點擊一下,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
await page.click('.item .name', options={
'button': 'right',
'clickCount': 1, # 1 or 2
'delay': 3000, # 毫秒
})
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
這里 click 方法第一個引數就是選擇器,即在哪里操作,第二個引數是幾項配置:
-
button:滑鼠按鈕,分為 left、middle、right,
-
clickCount:點擊次數,如雙擊、單擊等,
-
delay:延遲點擊,
-
輸入文本,
對于文本的輸入,Pyppeteer 也不在話下,使用 type 方法即可,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.taobao.com')
# 后退
await page.type('#q', 'iPad')
# 關閉
await asyncio.sleep(10)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
這里我們打開淘寶網,使用 type 方法第一個引數傳入選擇器,第二個引數傳入輸入的內容,Pyppeteer 便可以幫我們完成輸入了,
- 獲取資訊
Page 獲取源代碼用 content 方法即可,Cookies 則可以用 cookies 方法獲取,示例如下:
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
print('HTML:', await page.content())
print('Cookies:', await page.cookies())
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
- 執行
Pyppeteer 可以支持 JavaScript 執行,使用 evaluate 方法即可,看之前的例子:
import asyncio
from pyppeteer import launch
width, height = 1366, 768
async def main():
browser = await launch()
page = await browser.newPage()
await page.setViewport({'width': width, 'height': height})
await page.goto('https://dynamic2.scrape.cuiqingcai.com/')
await page.waitForSelector('.item .name')
await asyncio.sleep(2)
await page.screenshot(path='example.png')
dimensions = await page.evaluate('''() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}''')
print(dimensions)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
這里我們通過 evaluate 方法執行了 JavaScript,并獲取到了對應的結果,另外其還有 exposeFunction、evaluateOnNewDocument、evaluateHandle 方法可以做了解,
- 延時等待
在本課時最開頭的地方我們演示了 waitForSelector 的用法,它可以讓頁面等待某些符合條件的節點加載出來再回傳,
在這里 waitForSelector 就是傳入一個 CSS 選擇器,如果找到了,立馬回傳結果,否則等待直到超時,
除了 waitForSelector 方法,還有很多其他的等待方法,介紹如下,
- waitForFunction:等待某個 JavaScript 方法執行完畢或回傳結果,
- waitForNavigation:等待頁面跳轉,如果沒加載出來就會報錯,
- waitForRequest:等待某個特定的請求被發出,
- waitForResponse:等待某個特定的請求收到了回應,
- waitFor:通用的等待方法,
- waitForSelector:等待符合選擇器的節點加載出來,
- waitForXPath:等待符合 XPath 的節點加載出來,
通過等待條件,我們就可以控制頁面加載的情況了,
4. 更多
另外 Pyppeteer 還有很多功能,如鍵盤事件、滑鼠事件、對話框事件等等,在這里就不再一一贅述了,更多的內容可以參考官方檔案的案例說明:https://miyakogi.github.io/pyppeteer/reference.html,
以上,我們就通過一些小的案例介紹了 Pyppeteer 的基本用法,下一課時,我們來使用 Pyppeteer 完成一個實戰案例爬取,
本節代碼:https://github.com/Python3WebSpider/PyppeteerTest,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/100829.html
標籤:其他
下一篇:python assert