移動互聯網打破了傳統門戶網站的交流屏障,社交軟體則架起了資訊之間無障礙溝通的橋梁,
根據《2019年社交行業研究報告》顯示,目前市面上的社交軟體一共有6000多個,包括內容社交、工具社交、場景社交三個方面,
現今,社交軟體不僅僅是普通的交友軟體,它本質上是一種傳遞資訊的媒介,并具有極大的包容性、復雜性、廣泛性,成千上萬個社交軟體散布在網路世界的各個角落,它所帶來的改變足以帶動整個互聯網時代資訊交流的變遷,
它容許并鼓勵全球不同地域的用戶注冊登錄,每一位用戶都可以自由發言盡情創作,以資訊分享為核心,進行個性交流、評論轉發、在線直播、擴列交友、知識創作等操作,所以它是數字化資訊傳播的重要落地典范,但是這把雙刃劍,同時也存在著很多令人頭疼的安全風控隱患,
社交行業挑戰升級
伴隨著產業互聯網數字化的不斷推進,社交軟體的容錯性也越來越低,
以資訊傳播為載體的6000+社交軟體在分類上成樹狀圖分布,主要以知識性內容社交分享(知乎、CSDN、微博、抖音、快手等)、即時通訊社交聊天(微信、探探、陌陌等)、各行業垂直場景社交交流(脈脈、馬蜂窩等)三類為主,

面對這些多場景多渠道社交形式,顯而易見,有交流的地方一定會有文本內容,并且在某些社交平臺上,卻存在一些共性風控問題,如頻繁出現暴恐、涉政、低俗、辱罵等違法違規內容,以及發布黑產廣告導流等違規資訊,這不僅違反了網路安全的和諧秩序,也對用戶造成了惡劣的觀感體驗,造成正常用戶流失,
從根本原因上去剖析,除了小部分原因是用戶自身的行為違規,大部分原因是由于一些黑產分子將社交軟體看成了自己的“吸金池”,且作案手法層出不窮:游戲點金、殺豬盤、惡意營銷薅羊毛、黃牛倒賣機票火車票演唱會門票…
在國家監管部門的指導下,社交平臺也采取了一系列處罰措施,
2020年8月,微博管理方關閉了109個黑產導流賬號;斗魚關停違規直播間525個、封禁賬號571個;武漢市指導某直播平臺依法依規關閉違規直播間525個,封禁違規用戶賬號571個,清理標題黨136個,
截止2020年9月,全國網信系統同電信部門處罰違法網站6907家,有關網站平臺依法關閉各類違法違規群組86萬余個…因此,國家對社交軟體的內容監管要求也越來越嚴,
各類社交平臺違規內容的不斷頻發,黑產團伙花樣百出的作案手法,使得內容審核挑戰的不斷升級,給社交軟體帶來很大的生存壓力,
黑產攻防之戰愈演愈烈,針對如何解決此類問題,數美人工智能研究院結合行業背景,對智能文本識別技術進行了深入研究和開發,通過自研天凈智能內容過濾引擎來應對挑戰,
社交軟體內容精準過濾器:數美智能文本審核
數美人工智能研究院發現,社交軟體的文本審核主要聚焦在直播視頻彈幕、論壇灌水發帖、產品評論留言、頭像昵稱簽名、垃圾廣告群發、游戲頻道聊天六大方面,
對于不同的應用場景,就對智能文本的語意識別精準度、識別范圍廣泛性、多語種識別等方面要求極高,對此,數美科技智能文本過濾通過建立完善用戶畫像系統和特色智能語意分析功能,結合多場景、多維度判定,支持涉政違禁、低俗污穢、廣告導流風險識別,
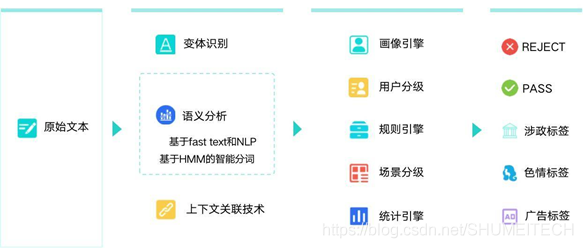
針對不同的社交場景,數美智能文本過濾采用語意分析技術和多種文本識別模型和策略、以及文本處理技術,包括采用基于敏感詞庫的名單服務,基于深度學習的NLP模型,用戶畫像的行為分析,實時分布式規則引擎、統計引擎等,對海量文本資料進行學習和訓練,能夠精準識別語意并進行風險判斷,
涉政違規識別
實時同步網安、網信辦等有關部門監管要求,持續更新數十萬量級的敏感詞庫,通過靈活的名單匹配
(白名單、黑名單、忽略名單、變體名單等)和智能NLP模型,精準有效識別文本中的涉政違規風險,
包括領匯入名、敏感事件、禁書禁片、邪教迷信、政府機構、反動分裂、違禁品、暴力恐怖、英雄烈士、熱點事件等,并支持業務場景的敏感詞個性化設定、變體識別(同音字、形近字、拼音、插入混淆、影射等)及多種靈活匹配方式,
低俗違規識別
通過積累大量行業語料,基于NLP技術訓練低俗和辱罵等模型,結合低俗敏感詞庫,精準識別文本中不合規的低俗污穢等內容,并將該內容分為多個等級,靈活適應不同應用、場景、角色的個性化審核標準,
智能NLP模型和色情敏感詞相結合,多角度全方位進行攔截,且支持自定義敏感詞名單,并利用智能語意識別技術,對同一個詞在不同語境中產生對應的判別結果,
廣告導流識別
主要針對廣告導流黑產團伙在社交軟體中發布的大量垃圾廣告、詐騙廣告,利用智能文字變體識別能力,可以精準識別欺詐廣告、導流廣告,支持廣告法合規性檢查,減少違規風險,上萬種主流聯系方式(微信、QQ、手機號、網址、公眾號、百度搜索、微博、廣告法合規等)變體特征庫,
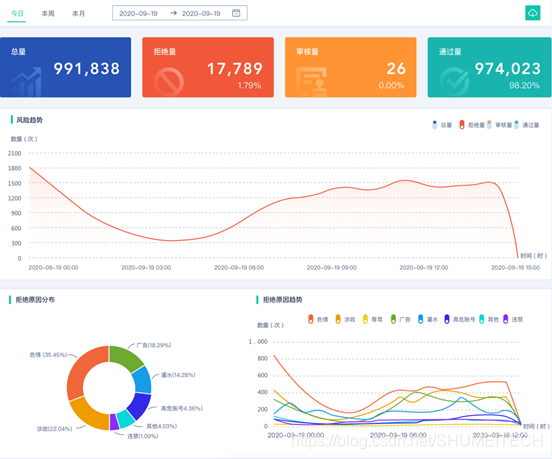
漢語文化博大精深,同一個詞在不同語境中意義差別極大,傳統敏感詞匹配技術的準確率很難達到精準高效審核的要求,數美智能文本過濾識別準確率高達99%以上,可對文本進行快速處理,極大降低誤殺率,并減少人工審核成本,有效杜絕線上風險,
在技術指標上,數美智能文本過濾API平均回應時間低于50ms,最大回應時間500ms,超時率低于0.1%,吞吐大于100QPS,還可根據需求水平擴展,并可支持UTF8多語言文本字符編碼,文本內容限制為不超過1MB、2萬字,
數美核心技術優勢:文本分類NLP模型
數美智能文本過濾采用了word2vec詞向量、fasttext文本分類等技術,基于海量文本語料訓練NLP模型,
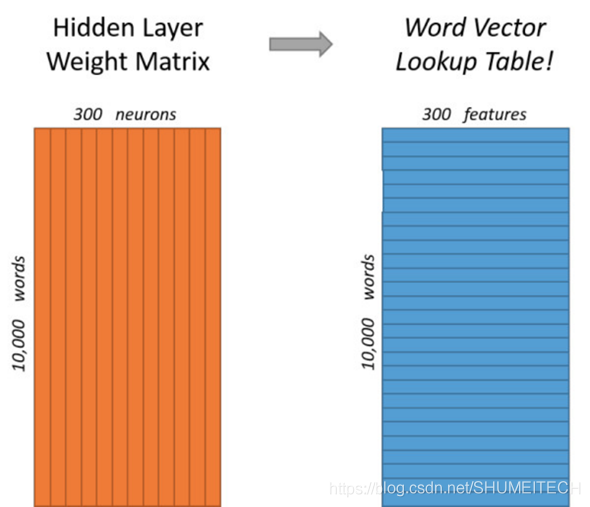
Word2Vec是從大量文本語料中以無監督的方式學習語意知識的一種模型,它被大量地用在自然語言處理(NLP)中,它通過學習文本來用詞向量的方式表征詞的語意資訊,即通過一個嵌入空間使得語意上相似的單詞在該空間內距離很近,
Embedding其實就是一個映射,將單詞從原先所屬的空間映射到新的多維空間中,也就是把原先詞所在空間嵌入到一個新的空間中去,
其中,在Word2Vec模型中,主要有Skip-Gram和CBOW兩種模型,從直觀上理解,Skip-Gram是給定input word來預測背景關系,而CBOW是給定背景關系,來預測input word,

fastText資料庫,能針對文本表達和分類幫助建立量化的解決方案,fastText結合了自然語言處理和機器學習中最成功的理念,這些包括了使用詞袋以及n-gram 袋表征陳述句,還有使用子字(subword)資訊,并通過隱藏表征在類別間共享資訊,
另外,數美人工智能研究院采用了一個softmax層級(利用了類別不均衡分布的優勢)來加速運算程序,這些不同概念被用于兩個不同任務:有效文本分類和學習詞向量表征,在文本處理領域中深度神經網路近來大受歡迎,但是它們訓練以及測驗程序十分緩慢,這也限制了它們在大資料集上的應用,fastText卻能夠直接解決這個問題,
fastText 專注于文本分類,這使得在特別大型的資料集上,它能夠被快速訓練,使用一個標準多核 CPU,就得到了在10分鐘內訓練完超過10億詞匯量模型的結果,此外,fastText還能在五分鐘內將50萬個句子分成超過30萬個類別,
數美人工智能研究院長期深耕在智能文本識別NLP模型訓練和開發中,不斷和黑產欺詐團伙抗爭,并從內容、行為、畫像多維度協同AI,精準有效識別違規內容,形成了一站式智能風控引擎,數美科技作為一家專業從事AI風控解決方案提供商,也會持續為全球千家社交行業客戶在線業務保駕護航,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/111310.html
標籤:其他
上一篇:c++ IO操作