文章目錄
- 一、堆資料結構簡介
- 1. 定義
- 2. 性質
- 二、堆資料結構應用
- 1. `add(k, v)`
- 完全二叉樹性質保證
- 堆序性質保證
- 2. `remove_min()`
- 完全二叉樹性質保證
- 堆序性質保證
- 三、堆資料結構實作
- 1. 實作方式選擇
- 2. 資料結構實作
- 2.1 堆的ADT
- 2.2 堆方法實作
- `_parent()`
- `_left()`
- `_right()`
- `_has_left()`
- `_has_right()`
- `_swap()`
- `_upheap()`
- `_downheap()`
- 2.3 優先級佇列方法實作
- `__init__()`
- `__len__()`
- `add()`
- `min()`
- `remove_min()`
- 2.4 基于堆的優先級佇列方法復雜度分析
- 四、完整測驗代碼
在【資料結構Python描述】優先級佇列簡介及Python手工實作中,我們使用位置串列作為鍵值對形式記錄的存盤容器,通過兩種策略分別給出了一個優先級佇列實作:
UnsortedPriorityQueue:佇列中的記錄不按照鍵的大小順序排列;SortedPriorityQueue:佇列中的記錄按照鍵的大小順序排列,
由此,在比較這兩種不同策略的實作后,可以發現一個有趣的現象:
UnsortedPriorityQueue中插入記錄方法add()的最壞時間復雜度雖然為 O ( 1 ) O(1) O(1),但是查找(或同時洗掉)鍵最小的記錄的方法min()(或remove_min())的最壞時間復雜度為 O ( n ) O(n) O(n);SortedPriorityQueue中雖然查找(或同時洗掉)鍵最小記錄的方法min()(或remove_min())的最壞時間復雜度為 O ( 1 ) O(1) O(1),但插入記錄方法add()的最壞時間復雜度雖然為 O ( n ) O(n) O(n),
實際上,由上述分析可知,如果實際要求add()、min()和remove_min()三個方法的最壞時間復雜度均低于
O
(
n
)
O(n)
O(n),則上述兩種實作方式均無法滿足要求,
為了實作上述需求,則需要使用本文介紹的一種新的資料結構——二叉堆,更具體地,可以使用本文將介紹的二叉堆來實作優先級佇列,以達到記錄插入和洗掉的最壞時間復雜度均為 l o g ( n ) log(n) log(n),
一、堆資料結構簡介
1. 定義
二叉堆:堆首先是一種特殊的二叉樹
T,該二叉樹T的每個結點處保存了一條鍵值對形式的記錄,除此之外該二叉樹T還具有以下兩條性質:
- 堆序性質:如果
p代表堆T任意一個除根結點的結點位置,則對于保存在位置p處的記錄,其鍵大于或等于p的父結點處記錄的鍵;- 完全二叉樹性質:堆
T是一個完全二叉樹,即如果二叉樹的高度為h,則樹的第 0 0 0, 1 1 1, 2 2 2, . . . ... ..., h ? 1 h-1 h?1層均有 2 i 2^i 2i(其中 0 ≤ i ≤ h ? 1 0\le{i}\le{h-1} 0≤i≤h?1)個結點,且第 h h h層的結點都保存在盡量靠左的位置,
下面給出一個滿足上述堆定義的例子:
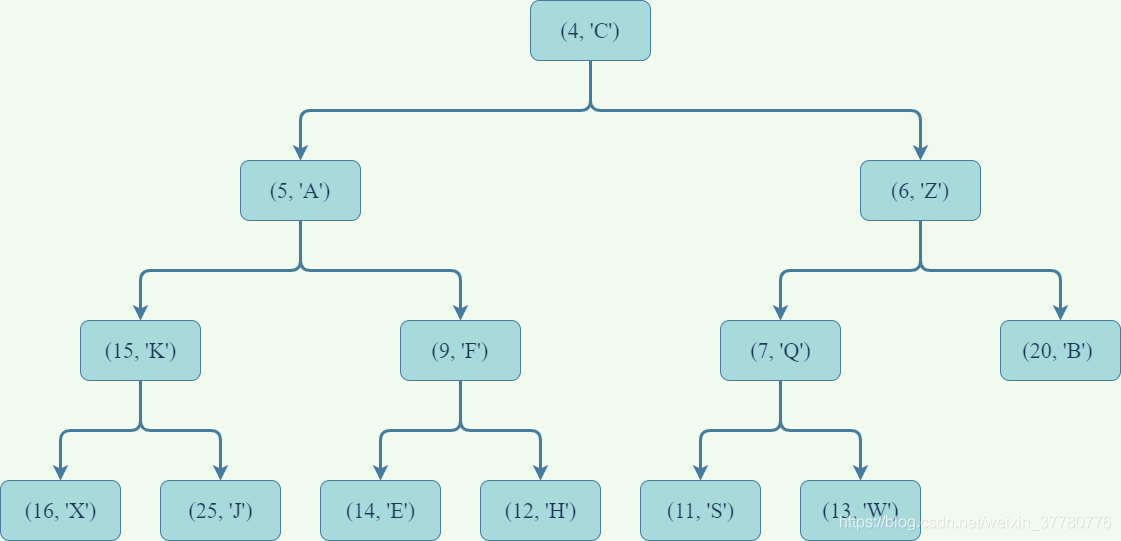
需要注意的是:
- 堆序性質保證了沿著從根結點開始到葉子結點結束的任意一條路徑,路徑上每一個位置處的鍵(非嚴格)單調遞增,且鍵最小的記錄在根結點處;
- 本文所描述的資料結構堆和計算機記憶體中的堆無任何關系,請讀者注意區分;
- 由于資料結構堆實際是一種特殊的完全二叉樹,因此本文后續將不區分堆和完全二叉樹的概念,
2. 性質
高度:對于保存 n n n條記錄的堆
T,其高度為 ? l o g ( n ) ? \lfloor log(n) \rfloor ?log(n)?,其中 ? x ? \lfloor x \rfloor ?x?表示對 x x x向下取整,
證明:由于堆T是一個完全二叉樹,則其從第 0 0 0層到第 h ? 1 h-1 h?1層的結點數目為 1 + 2 + 2 2 + ? ? ? + 2 h ? 1 = 2 h ? 1 1+2+2^2+\cdot\cdot\cdot+2^{h-1}=2^h-1 1+2+22+???+2h?1=2h?1,而第 h h h層的結點數目最少為 1 1 1個,最多為 2 h 2^h 2h個,因此:
( 2 h ? 1 ) + 1 ≤ n ≤ ( 2 h ? 1 ) + 2 h (2^h-1)+1\le{n}\le(2^h-1)+2^h (2h?1)+1≤n≤(2h?1)+2h
即:
2 h ≤ n ≤ 2 h + 1 ? 1 2^h\le{n}\le2^{h+1}-1 2h≤n≤2h+1?1
對上面運算式的左邊部分同時兩邊取對數得 h ≤ l o g ( n ) h\le{log(n)} h≤log(n),對上面運算式右邊部分移項后兩邊取對數再移項后得 h ≥ ( l o g ( n + 1 ) ? 1 ) h\ge({log(n+1)-1}) h≥(log(n+1)?1),
即:
( l o g ( n + 1 ) ? 1 ) ≤ h ≤ l o g ( n ) (log(n+1)-1)\le{h}\le{log(n)} (log(n+1)?1)≤h≤log(n)
又由于 h h h為正整數,則必有 h = ? l o g ( n ) ? h=\lfloor log(n) \rfloor h=?log(n)?,
二、堆資料結構應用
由上述關于堆T的高度性質可知,如果對T進行的修改類操作(如添加、洗掉類操作)可實作正比于其高度
h
h
h的時間復雜度,則對于有
n
n
n條記錄的T這寫修改類操作的時間復雜度為
l
o
g
(
n
)
log(n)
log(n),
自然地,如果可以使用堆T作為保存優先級佇列的所有鍵值對形式記錄,則基于此實作的優先級佇列,其add()、min()、remove_min()等操作有望實作
l
o
g
(
n
)
log(n)
log(n)的最壞時間復雜度,
實際上,如果使用堆實作的優先級佇列,對于其ADT中的所有方法:
__len__()和is_empty()方法的實作非常簡單,僅需回傳或判斷底層完全二叉樹的結點個數屬性即可;min()方法的實作也很直接,因為上述堆序性質保證了鍵最小的記錄保存在根結點處;add()和remove_min()兩個方法的實作較為復雜,因為要保證在記錄條目增刪前后仍然保持堆的堆序性質和完全二叉樹性質,
因此,下面著重從理論上分析如何基于堆來實作優先級佇列的add()和remove_min()兩個方法:
1. add(k, v)
首先考慮將鍵值對形式的記錄保存在堆的結點中,但需要注意的是該操作之后需要同時保證堆序性質和完全二叉樹性質,
完全二叉樹性質保證
為確保不違背完全二叉樹性質,add(k, v)方法需要將結點保存在二叉樹最底層最右側結點的右側緊鄰位置或者新一層結點的最左側位置,
下圖以滿足上述堆定義的圖為例,假設現在需要向其中增加一條鍵為2,值為'T'的記錄(2, 'T'),則圖(a)和(b)分別表示執行add(2, 'T')之前和之后(部分)堆的狀態:

堆序性質保證
上述步驟雖然確保了滿足堆的完全二叉樹性質,但是當呼叫add(k, v)方法之前堆不為空,則有可能僅完成上述步驟將違背堆的堆序性質,原因在于,如果假設插入完全二叉樹的結點的位置為p,且該結點的父結點位置為q,則有可能
k
p
<
k
q
k_p\lt{k_q}
kp?<kq?,
針對上述可能,我們需要交換位置p和q處結點的鍵值對形式記錄,此操作后原本位置p處的記錄將上移一層,如果此時完全二叉樹已滿足堆序性質,則插入操作才算完成,否則交換操作繼續,
針對上述分析,有如下圖的示例:
- 圖(c)和(d)表示繼圖(b)狀態后,完成記錄
(20, 'B')和(2, 'T')交換的程序和結果; - 圖(e)和(f)、圖(g)和(h)分別表示繼續進行結點間記錄交換的程序和結果,

實際上,上述一系列操作也稱為自堆底向上冒泡(up-heap bubbling)演算法,而且在最壞情況下(如上圖所示),此演算法將使得新結點處的記錄一直被交換至根結點處,此時交換操作的次數為堆的高度即 l o g ( n ) log(n) log(n)( n n n為堆的總結點數),
2. remove_min()
根據堆的定義,使用堆T實作的優先級佇列中鍵最小的記錄必然保存在根結點處,但實作remove_min()方法時不能直接將根結點洗掉,因為此時會形成兩個互不相連的子樹,即破壞了堆的完全二叉樹性質,
完全二叉樹性質保證
為解決上述問題,可以:
- 先洗掉堆最底層最右側結點并回傳保存的記錄;
- 然后使用上述回傳的記錄替換根結點處的記錄,
下圖為上述操作的示例:

堆序性質保證
完成上述操作后仍存在的問題是,此時樹雖然是完全二叉樹,但可能并不是堆,因為該二叉樹可能不滿足堆序性質,
實際上,如果洗掉堆的最底層最右側結點后,完全二叉樹中:
- 僅有一個結點,則該完全二叉樹同時也是堆;
- 不止一個結點,則令
p表示堆T的根結點位置,在以下兩種情況下:p只有左子結點,且其位置為c;p有左、右兩個子結點,令其鍵較小的子結點的位置為c,
如果
k
p
>
k
c
k_p\gt{k_c}
kp?>kc?,則類似上述實作add(k, v),此時完全二叉樹不是堆,需要交換位置p和c處的記錄直至整個完全二叉樹滿足堆序性質,下面系列圖例表達了這一具體程序:

實際上,與之前自堆底向上冒泡(up-heap bubbling)演算法相對,上述程序也稱為自堆頂向下冒泡(down-heap bubbling),且類似地該演算法的最壞時間復雜度為
l
o
g
(
n
)
log(n)
log(n)(其中
n
n
n為堆中元素個數),
三、堆資料結構實作
1. 實作方式選擇
由于堆實際上是一種特殊的二叉樹,則你可能第一反應是根據【資料結構Python描述】樹的簡介、基本概念和手動實作一個二叉樹中定義專門的結點類,并以結點的鏈式方式來實作堆,
實際上,通過上述方式實作堆本身并沒有問題,但問題在于本文在開頭引出的問題及其解決方案,即本文實作堆的目的是使用堆來進一步實作更加優化的優先級佇列(相比于之前使用位置串列實作優先級佇列),因此使用基于結點鏈式結構實作堆有以下主要缺陷:
- 實作起來較為復雜,
- 進一步實作的優先級佇列的部分操作時間復雜度高,對于優先級佇列的
add()和remove_min()方法,其實作依賴于先找到堆中的最后一個結點,而這對于基于結點鏈式結構實作的堆來說時間復雜度為 O ( n ) O(n) O(n),
實際上,除了使用基于結點鏈式結構來實作二叉樹,另一種方式是使用串列作為存盤每一個結點元素的容器來實作,
具體地,假設完全二叉樹T的所有結點均保存在串列A中,假設函式
f
(
p
)
f(p)
f(p)將結點位置p映射為串列A中的正整數索引,則T中所有結點在串列A中對應的索引為:
- 如果位置
p處為根結點,則 f ( p ) = 0 f(p)=0 f(p)=0; - 如果
p是位置q處結點的左子結點的位置,則 f ( p ) = 2 f ( q ) + 1 f(p)=2f(q)+1 f(p)=2f(q)+1; - 如果
p是位置q處結點的右子結點的位置,則 f ( p ) = 2 f ( q ) + 2 f(p)=2f(q)+2 f(p)=2f(q)+2,
基于上述定義,則將上述滿足堆定義的完全二叉樹轉換為串列存盤形式為:

由上述可知:
- 將保存業務元素的結點進行鏈式存盤,其優勢是可以較為直觀地體現完全二叉樹的結構,劣勢是訪問任意結點的遍歷較為耗時;
- 將完全二叉樹各個結點的業務元素保存在串列中,其優勢是根據串列索引訪問任意結點的業務元素,劣勢是完全二叉樹的結構是隱式的,
2. 資料結構實作
下面結合上述理論分析,繼承優先級佇列抽象基類PriorityQueueBase,通過使用普通串列作為堆中結點的存盤容器,進而使用堆保存鍵值對形式記錄,實作高效的優先級佇列HeapPriorityQueue,
2.1 堆的ADT
下面是堆的常用ADT方法,需要注意的是所有方法均為非公共方法,因為本文最終目的是實作一個面向用戶的高效優先級佇列,而用戶無需了解或使用底層的堆是如何實作的,
| 方法名稱 | 方法描述 |
|---|---|
_parent(j) | 對于堆T,如果其某結點處的業務元素保存在串列的索引j處,回傳其父結點處業務元素在串列中的索引, |
_left(j) | 對于堆T,如果其某結點處的業務元素保存在串列的索引j處,回傳其左子結點處業務元素在串列中的索引, |
_right(j) | 對于堆T,如果其某結點處的業務元素保存在串列的索引j處,回傳其右子結點處業務元素在串列中的索引, |
_has_left(j) | 對于堆T,如果其某結點處的業務元素保存在串列的索引j處,如果該結點有左子結點則回傳True,否則回傳False, |
_has_right(j) | 對于堆T,如果其某結點處的業務元素保存在串列的索引j處,如果該結點有右子結點則回傳True,否則回傳False, |
_swap(i, j) | 對于完全二叉樹T,假設其一對父子結點的業務元素分別保存在串列的索引i和j處,如果父子結點的業務元素違背了堆序性質則交換這對結點的業務元素, |
_upheap(j) | 自堆底向上冒泡(up-heap bubbling)演算法實作, |
_downheap(j) | 自堆頂向下冒泡(up-heap bubbling)演算法實作, |
2.2 堆方法實作
_parent()
根據堆中子結點和其父結點的業務元素在串列中的索引關系可得:
def _parent(self, j):
"""
回傳父結點處業務元素在串列中的索引
:param j: 任意結點處的業務元素在串列中的索引
:return: 父結點處業務元素在串列中的索引
"""
return (j - 1) // 2
_left()
該方法實作類似_parent()方法:
def _left(self, j):
"""
回傳左子結點處業務元素在串列中的索引
:param j: 任意結點處的業務元素在串列中的索引
:return: 左子結點處業務元素在串列中的索引
"""
return 2 * j + 1
_right()
該方法實作類似_parent()方法:
def _right(self, j):
"""
回傳右子結點處業務元素在串列中的索引
:param j: 任意結點處的業務元素在串列中的索引
:return: 右子結點處業務元素在串列中的索引
"""
return 2 * j + 1
_has_left()
該方法實作依賴于_left()方法:
def _has_left(self, j):
"""
如結點有左子結點則回傳True,否則回傳False
:param j: 任意結點處的業務元素在串列中的索引
:return: 判斷結點是否有左子結點的Boolean結果
"""
return self._left(j) < len(self._data) # 確保串列索引不越界
_has_right()
該方法實作依賴于_right()方法:
def _has_right(self, j):
"""
如結點有右子結點則回傳True,否則回傳False
:param j: 任意結點處的業務元素在串列中的索引
:return: 判斷結點是否有右子結點的Boolean結果
"""
return self._right(j) < len(self._data) # 確保串列索引不越界
_swap()
實作該方法僅需交換串列兩個索引處的業務元素即可:
def _swap(self, i, j):
"""
交換一對父子結點的業務元素
:param i: 業務元素在串列中的索引
:param j: 業務元素在串列中的索引
:return: None
"""
self._data[i], self._data[j] = self._data[j], self._data[i]
_upheap()
該方法實作遵照本文前述理論分析以確保向堆中插入新業務元素后不破壞其堆序性質:
def _upheap(self, j):
"""
自堆底向上冒泡演算法
:param j: 堆底結點處業務元素在串列中的索引
:return: None
"""
parent = self._parent(j)
if j > 0 and self._data[j] < self._data[parent]:
self._swap(j, parent)
self._upheap(parent) # 遞回呼叫
_downheap()
該方法實作遵照本文前述理論分析以確保洗掉堆中根結點業務元素后不破壞其堆序性質:
def _downheap(self, j):
"""
自堆頂向下冒泡演算法
:param j: 結點處業務元素在串列中的索引
:return: None
"""
if self._has_left(j):
left = self._left(j)
small_child = left
# 如果有左、右兩個子結點,令small_child參考鍵較小子結點的業務元素在串列中的索引
if self._has_right(j):
right = self._right(j)
if self._data[right] < self._data[left]:
small_child = right
# 至少根結點有左子結點時,才有可能self雖然是完全二叉樹但不是堆
if self._data[small_child] < self._data[j]:
self._swap(j, small_child)
self._downheap(small_child) # 遞回呼叫
2.3 優先級佇列方法實作
下面基于上述堆的各ADT方法實作優先級佇列:
__init__()
實作初始化方法僅需指定用于保存優先級佇列記錄的容器的空串列:
def __init__(self):
"""將創建的優先級佇列初始化為空"""
self._data = list()
__len__()
實作該方法僅需回傳串列長度即可:
def __len__(self):
"""回傳優先級佇列中的記錄條目數"""
return len(self._data)
add()
實作該方法需要:
- 先將新鍵值對封裝為記錄物件后追加至串列尾部;
- 然后呼叫自堆底向上冒泡演算法的實作
_upheap()確保完全二叉樹滿足堆序性質,
def add(self, key, value):
"""向優先級佇列中插入一條key-value記錄"""
self._data.append(self._Item(key, value)) # 新記錄條目插入并確保完全二叉樹性質
self._upheap(len(self._data) - 1) # 確保滿足堆序性質
min()
實作該方法僅需回傳根結點處的鍵值對即可:
def min(self):
"""回傳(但不洗掉)優先級佇列中鍵最小的記錄,如優先級佇列此時為空則拋出例外"""
if self.is_empty():
raise Empty('優先級佇列為空!')
item = self._data[0]
return item.key, item.value
remove_min()
實作該方法需要:
- 先判斷優先級佇列是否為空;
- 其次交換根結點和堆最底層最右側結點處記錄;
- 然后洗掉堆最底層最右側結點,并保存該結點處記錄(經上述交換操作后,此記錄的鍵為堆中最小的);
- 再呼叫自堆頂向下冒泡演算法的實作
_downheap()確保經過交換操作后完全二叉樹滿足堆序性質; - 最后回傳鍵最小記錄的鍵和值,
def remove_min(self):
"""回并洗掉優先級佇列中鍵最小的記錄,如優先級佇列此時為空則拋出例外"""
if self.is_empty():
raise Empty('優先級佇列為空!')
self._swap(0, len(self._data) - 1) # 將根結點處鍵最小記錄交換至完全二叉樹最底層最右側結點處
item = self._data.pop()
self._downheap(0) # 確保完全二叉樹滿足堆序性質,即確定需保存在根結點處的鍵最小記錄
return item.key, item.value
2.4 基于堆的優先級佇列方法復雜度分析
針對基于堆實作的優先級佇列,其ADT方法的時間復雜度如下表所示,其中 n n n表示方法執行時優先級佇列中記錄條目數:
| 方法名稱 | 時間復雜度 |
|---|---|
__len__() | O ( 1 ) O(1) O(1) |
is_empty() | O ( 1 ) O(1) O(1) |
min() | O ( 1 ) O(1) O(1) |
add() | O ( l o g ( n ) ) O(log(n)) O(log(n))1 |
remove_min() | O ( l o g ( n ) ) O(log(n)) O(log(n))1 |
實際上,上述表格的分析基于以下事實:
- 堆
T具有 n n n個結點,每個結點保存一個鍵值對的參考; - 堆
T的高度為 l o g ( n ) log(n) log(n),因為T為完全二叉樹; min()方法的最壞時間復雜度為 O ( 1 ) O(1) O(1),因為根結點保存了鍵最小的記錄;- 實作
add()和remove_min()方法需要找到鍵最小的記錄,對于基于串列實作的堆和結點鏈式存盤的堆,該操作的時間復雜度分別為 O ( 1 ) O(1) O(1)和 O ( l o g ( n ) ) O(log(n)) O(log(n)); - 在最壞情況下,自堆底向上冒泡和自堆頂向下冒泡的次數等于堆的高度,
至此,我們實作了本文開頭期望的均能高效執行增(add(k, v))、刪(remove_min())、查(min())操作的優先級佇列,
四、完整測驗代碼
完整測驗代碼如下,其中使用了【資料結構Python描述】優先級佇列簡介及Python手工實作中的優先級佇列抽象基類PriorityQueueBase:
from priority_queue import PriorityQueueBase
class Empty(Exception):
"""嘗試對空優先級佇列進行洗掉操作時拋出的例外"""
pass
class HeapPriorityQueue(PriorityQueueBase):
"""使用堆存盤鍵值對形式記錄的優先級佇列"""
def __init__(self):
"""將創建的優先級佇列初始化為空"""
self._data = list()
def _parent(self, j):
"""
回傳父結點處業務元素在串列中的索引
:param j: 任意結點處的業務元素在串列中的索引
:return: 父結點處業務元素在串列中的索引
"""
return (j - 1) // 2
def _left(self, j):
"""
回傳左子結點處業務元素在串列中的索引
:param j: 任意結點處的業務元素在串列中的索引
:return: 左子結點處業務元素在串列中的索引
"""
return 2 * j + 1
def _right(self, j):
"""
回傳右子結點處業務元素在串列中的索引
:param j: 任意結點處的業務元素在串列中的索引
:return: 右子結點處業務元素在串列中的索引
"""
return 2 * j + 2
def _has_left(self, j):
"""
如結點有左子結點則回傳True,否則回傳False
:param j: 任意結點處的業務元素在串列中的索引
:return: 判斷結點是否有左子結點的Boolean結果
"""
return self._left(j) < len(self._data) # 確保串列索引不越界
def _has_right(self, j):
"""
如結點有右子結點則回傳True,否則回傳False
:param j: 任意結點處的業務元素在串列中的索引
:return: 判斷結點是否有右子結點的Boolean結果
"""
return self._right(j) < len(self._data) # 確保串列索引不越界
def _swap(self, i, j):
"""
交換一對父子結點的業務元素
:param i: 業務元素在串列中的索引
:param j: 業務元素在串列中的索引
:return: None
"""
self._data[i], self._data[j] = self._data[j], self._data[i]
def _upheap(self, j):
"""
自堆底向上冒泡演算法
:param j: 結點處業務元素在串列中的索引
:return: None
"""
parent = self._parent(j)
if j > 0 and self._data[j] < self._data[parent]:
self._swap(j, parent)
self._upheap(parent) # 遞回呼叫
def _downheap(self, j):
"""
自堆頂向下冒泡演算法
:param j: 結點處業務元素在串列中的索引
:return: None
"""
if self._has_left(j):
left = self._left(j)
small_child = left
# 如果有左、右兩個子結點,令small_child參考鍵較小子結點的業務元素在串列中的索引
if self._has_right(j):
right = self._right(j)
if self._data[right] < self._data[left]:
small_child = right
# 至少根結點有左子結點時,才有可能self雖然是完全二叉樹但不是堆
if self._data[small_child] < self._data[j]:
self._swap(j, small_child)
self._downheap(small_child) # 遞回呼叫
def __len__(self):
"""回傳優先級佇列中的記錄條目數"""
return len(self._data)
def __iter__(self):
"""生成優先級佇列中所有記錄的一個迭代"""
for each in self._data:
yield each
def add(self, key, value):
"""向優先級佇列中插入一條key-value記錄"""
self._data.append(self._Item(key, value)) # 新記錄條目插入并確保完全二叉樹性質
self._upheap(len(self._data) - 1) # 確保滿足堆序性質
def min(self):
"""回傳(但不洗掉)優先級佇列中鍵最小的記錄,如優先級佇列此時為空則拋出例外"""
if self.is_empty():
raise Empty('優先級佇列為空!')
item = self._data[0]
return item.key, item.value
def remove_min(self):
"""回并洗掉優先級佇列中鍵最小的記錄,如優先級佇列此時為空則拋出例外"""
if self.is_empty():
raise Empty('優先級佇列為空!')
self._swap(0, len(self._data) - 1) # 將根結點處鍵最小記錄交換至完全二叉樹最底層最右側結點處
item = self._data.pop()
self._downheap(0) # 確保完全二叉樹滿足堆序性質,即確定需保存在根結點處的鍵最小記錄
return item.key, item.value
if __name__ == '__main__':
heap_queue = HeapPriorityQueue()
print(heap_queue.is_empty()) # True
heap_queue.add(4, 'C')
heap_queue.add(6, 'Z')
heap_queue.add(7, 'Q')
heap_queue.add(5, 'A')
print(heap_queue) # [(4, 'C'), (5, 'A'), (7, 'Q'), (6, 'Z')]
heap_queue.add(2, 'T')
print(heap_queue) # [(2, 'T'), (4, 'C'), (7, 'Q'), (6, 'Z'), (5, 'A')]
print(heap_queue.remove_min()) # (2, 'T')
print(heap_queue.remove_min()) # (4, 'C')
print(heap_queue) # [(5, 'A'), (6, 'Z'), (7, 'Q')]
print(heap_queue.min()) # (5, 'A')
print(heap_queue.is_empty()) # False
經攤銷后的時間復雜度, ?? ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/154080.html
標籤:其他