Kafka 架構深入
公眾號 : 倔強小獅子(最新發布)

Kafka 作業流程(詳細)
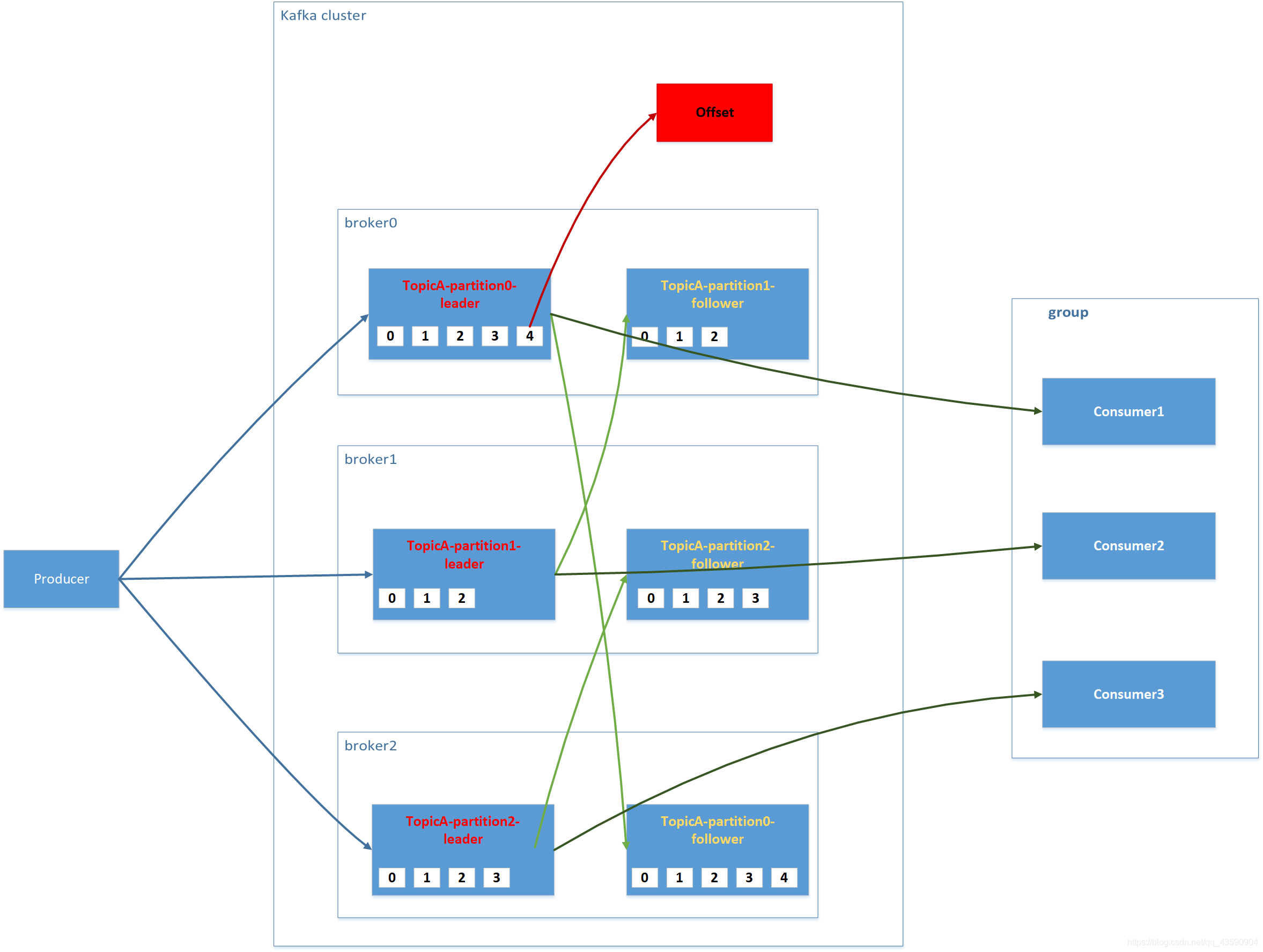
- Kafka 中訊息是以 topic 進行分類的,生產者生產訊息,消費者消費訊息,都是面向 topic的,
topic 是邏輯上的概念,而 partition 是物理上的概念,每個 partition 對應于一個 log 檔案,該 log 檔案中存盤的就是producer 生產的資料,Producer 生產的資料會被不斷追加到該log 檔案末端,且每條資料都有自己的 offset(偏移量),消費者組中的每個消費者,都會實時記錄自己消費到了哪個 offset,以便出錯恢復時,從上次的位置繼續消費
檔案存盤機制
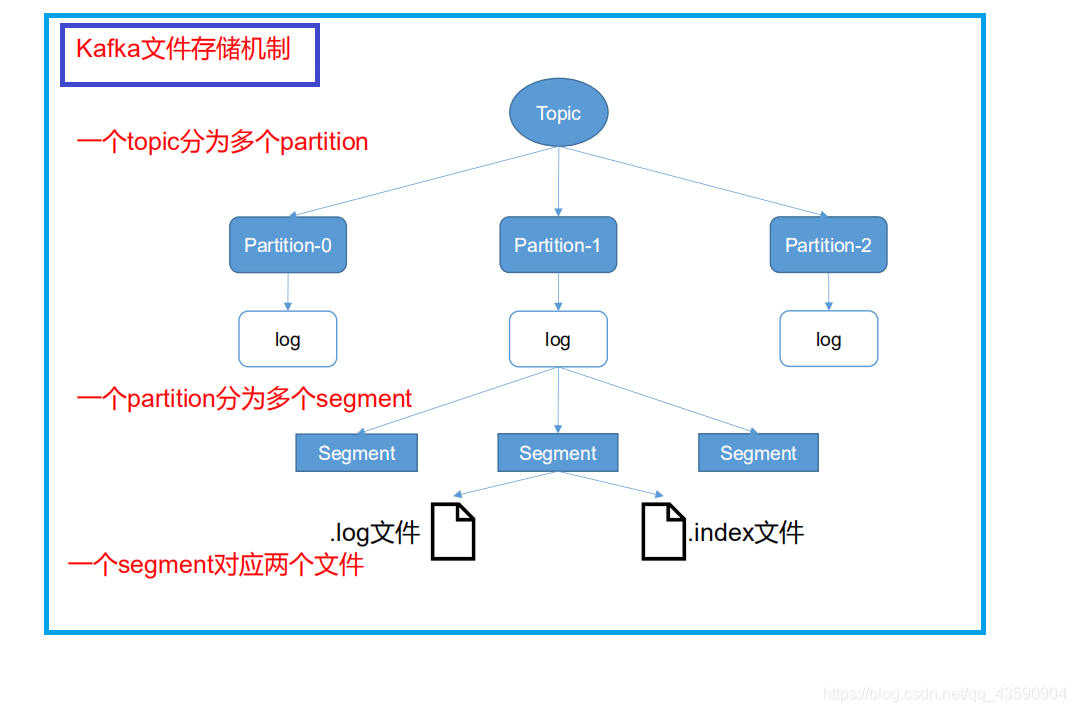
- 圖細化 Topic->partition->segment
- 生產者不斷追加到 .log檔案末端(注意: .log檔案不是日志檔案,是資料檔案),為了防止資料量過大, 定位資料效率低下,Kafka 采取了分片和索引機制,將每個 partition 分為多個 segment,每個 segment對應兩個檔案——“.index”檔案和“.log”檔案,這些檔案位于一個檔案夾下,檔案夾命名規則為:規則為:topic 名稱+磁區序號,
.index .log 檔案講解

注意 : index 和 log 檔案以當前 segment 的第一條訊息的 offset 命名
index 和 log 檔案講解(網上扒的圖,自己做的修改)
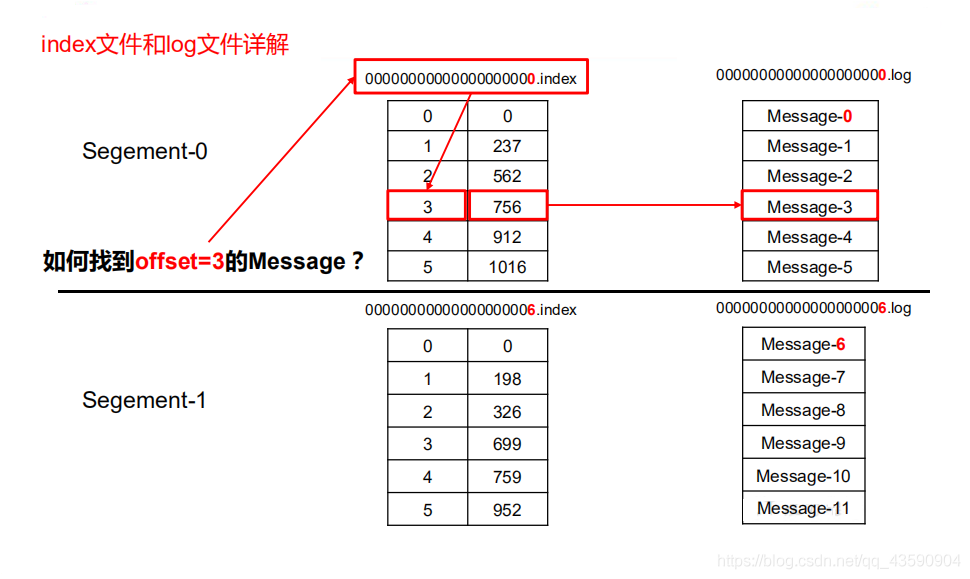
1.“.index”檔案存盤大量的索引資訊,“.log”檔案存盤大量的資料,索引檔案中的元資料(可以描述資料的資料)指向對應資料檔案中
message 的物理偏移地址(不要懵,偏移量是Kafka訊息的索引,而物理偏移量是Kafka偏移量的系統地址值),
2. 注意 : Kafka 按照 二分查找演算法進行檢索資料,二分查找演算法百度百科
Kafka 生產者
磁區策略
磁區的原因
- 方便在集群中擴展,一個 topic又可以有多個 Partition 組成
- 可以提高并發,因為可以以 Partition 為單位讀寫了,
磁區的原則
- 我們需要將 producer 發送的資料封裝成一個 ProducerRecord 物件

指明 partition 的情況下,直接將指明的值直接作為 partiton 值;
3. 沒有指明 partition 值但有 key 的情況下,將 key 的 hash 值與 topic 的 partition數進行取余得到 partition 值
4. 既沒有 partition 值又沒有 key 值的情況下,第一次呼叫時隨機生成一個整數(后面每次呼叫在這個整數上自增),將這個值與 topic 可用的 partition 總數取余得到 partition
值,也就是常說的 round-robin 演算法
資料可靠性保證
- 為保證 producer 發送的資料,能可靠的發送到指定的 topic,topic 的每個 partition 收到
producer 發送的資料后,都需要向 producer 發送 ack(acknowledgement 確認收到),如果producer 收到 ack,就會進行下一輪的發送,否則重新發送資料
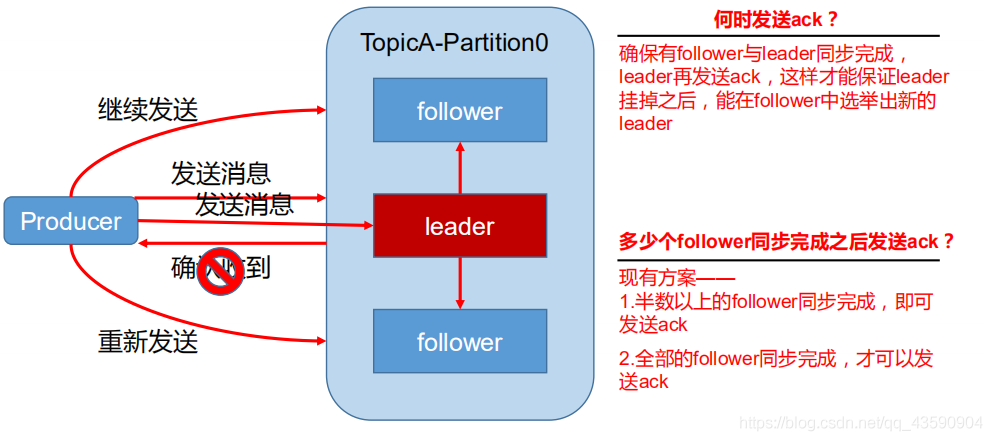
副本資料同步策略
| 方案 | 優點 | 缺點 |
|---|---|---|
| 半數以上完成同步,就發送 ack | 延遲低 | 選舉新的 leader 時,容忍 n 臺節點的故障,需要 2n+1個副本 |
| 全部完成同步,才發送ack | 選舉新的 leader 時,容忍 n 臺節點的故障,需要 n+1 個副本 | 延遲高 |
- Kafka 選擇第二種方案
- 采用第二種方案后,設想下一個場景:leader 收到資料,所有 follower 都開始同步資料,但有一個 follower,因為某種故障,遲遲不能與 leader 進行同步,那 leader 就要一直等下去,直到它完成同步,才能發送 ack,這個問題怎么解決呢?
- Leader 維護了一個動態的 in-sync replica set (ISR),意為和 leader 保持同步的 follower 集合,當 ISR 中的 follower 完成資料的同步之后,leader 就會給 follower 發送 ack,如果 follower長時間 未 向 leader 同 步 數 據 , 則 該 ollower 將 被 踢 出 ISR , 該 時 間 閾 值 由replica.lag.time.max.ms 引數設定,Leader 發生故障之后,就會從 ISR 中選舉新的 leader,
ack 應答機制
對于某些不重要的資料, 對資料的要求性不高的情況下,能夠容忍資料的丟失性,不需要等待 ISR 所有follower全部接收.所以Kafka提供了三種可靠性級別,可以根據專案業務的需求權衡
acks 引數配置 :
- 引數 0 : producer 不等待 broker 的 ack,這一操作提供了一個最低的延遲,broker 一接收到還沒有寫入磁盤就已經回傳 ack,當 broker 故障時有可能丟失資料;
- 引數 1 : producer 等待 broker 的 ack,partition 的 leader 寫盤成功后回傳 ack,如果在 follower同步成功之前 leader 故障,那么將會丟失資料;
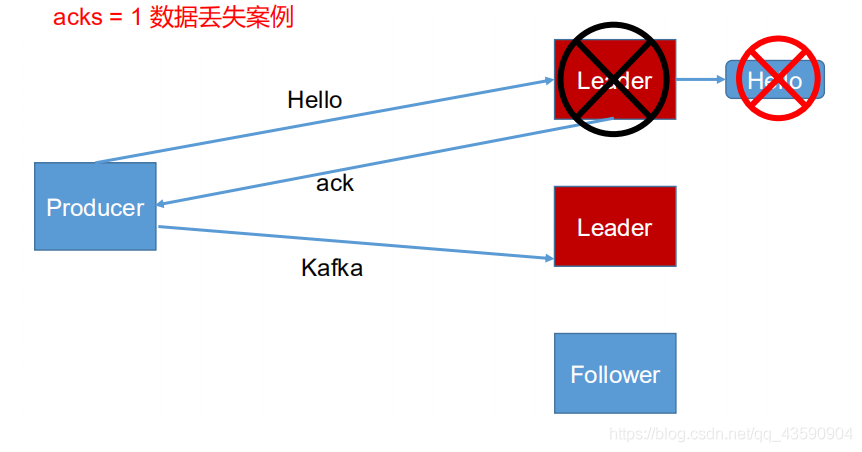
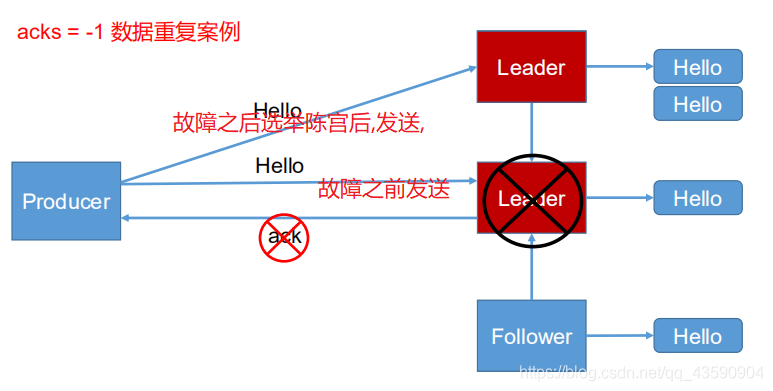
- 引數 -1 或者(all):producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落盤成功后才回傳 ack,但是如果在 follower 同步完成后,broker 發送 ack 之前,leader 發生故障,那么會造成資料重復,(這里所說的follower是ISR中的)
故障處理細節
Log檔案中的 HW 和 LEO
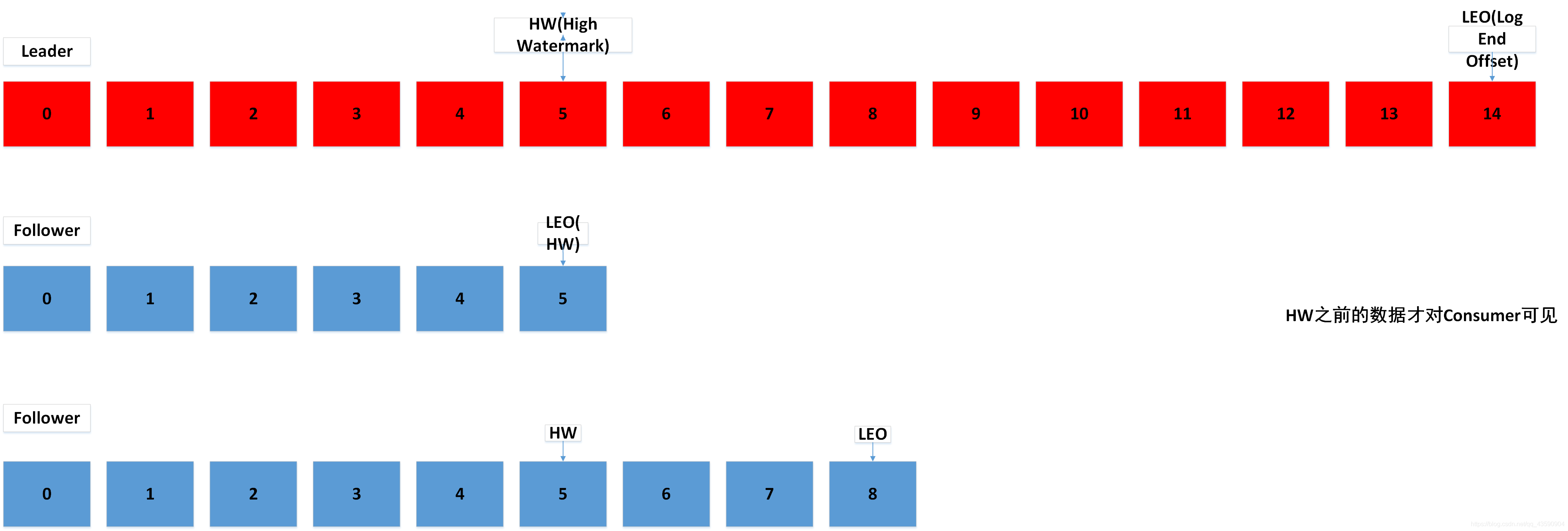
- LEO:每個副本的最后一個offset
- HW:指的是消費者能見到的最大的 offset,ISR 佇列中最小的 LEO,
- follower 發生故障后會被臨時踢出 ISR,待該 follower 恢復后,follower 會讀取本地磁盤記錄的上次的 HW,并將 log 檔案高于 HW 的部分截取掉,從 HW 開始向 leader 進行同步,等該 follower 的 LEO 大于等于該 Partition 的 HW,即 follower 追上 leader 之后,就可以重
新加入 ISR 了,- leader 發生故障之后,會從 ISR 中選出一個新的 leader,之后,為保證多個副本之間的資料一致性,其余的 follower 會先將各自的 log 檔案高于 HW 的部分截掉,然后從新的 leader
同步資料
注意:這只能保證副本之間的資料一致性,并不能保證資料不丟失或者不重復,
Exactly Once 語意(重點)
將服務器的 ACK 級別設定為-1,可以保證 Producer 到 Server 之間不會丟失資料,即 At Least Once 語意,相對的,將服務器 ACK 級別設定為 0,可以保證生產者每條訊息只會被發送一次,即 At Most Once 語意,
At Least Once 可以保證資料不丟失,但是不能保證資料不重復;相對的,At Least Once可以保證資料不重復,但是不能保證資料不丟失,但是,對于一些非常重要的資訊,比如說交易資料,下游資料消費者要求資料既不重復也不丟失,即 Exactly Once 語意,在 0.11 版本以前的 Kafka,對此是無能為力的,只能保證資料不丟失,再在下游消費者對資料做全域去重,對于多個下游應用的情況,每個都需要單獨做全域去重,這就對性能造成了很大影響,0.11 版本的 Kafka,引入了一項重大特性:冪等性,所謂的冪等性就是指 Producer 不論向 Server 發送多少次重復資料,Server 端都只會持久化一條,冪等性結合 At Least Once 語意,就構成了 Kafka 的 Exactly Once 語意,
即:
At Least Once + 冪等性 = Exactly Once
要啟用冪等性,只需要將 Producer 的引數中enable.idompotence 設定為 true 即可,
Kafka的冪等性實作其實就是將原來下游需要做的去重放在了資料上游,開啟冪等性的 Producer 在初始化的時候會被分配一個 PID,發往同一Partition 的訊息會附帶 Sequence Number,而Broker 端會對<PID, Partition, SeqNumber>做快取,當具有相同主鍵的訊息提交時,Broker 只會持久化一條,
但是 PID 重啟就會變化,同時不同的 Partition 也具有不同主鍵,所以冪等性無法保證跨
磁區跨會話的 Exactly Once,
作者:專業于寫這些入門到深層知識,提升我們的基本功,期待你的關注,和我一起學習
轉載說明:未獲得授權,禁止轉載
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/155719.html
標籤:其他