目錄
- 一.混淆矩陣
- 二.精準率和召回率
- 三.Precision-Recall的平衡
- 四.ROC曲線
- 五.多分類問題中的混淆矩陣
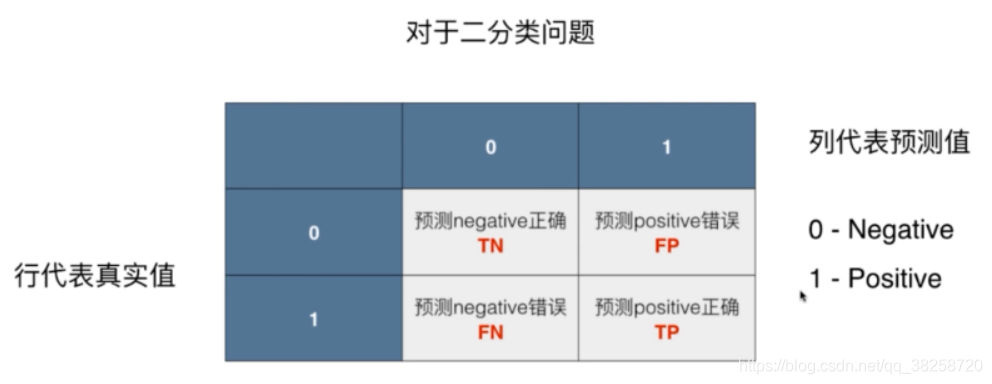
一.混淆矩陣

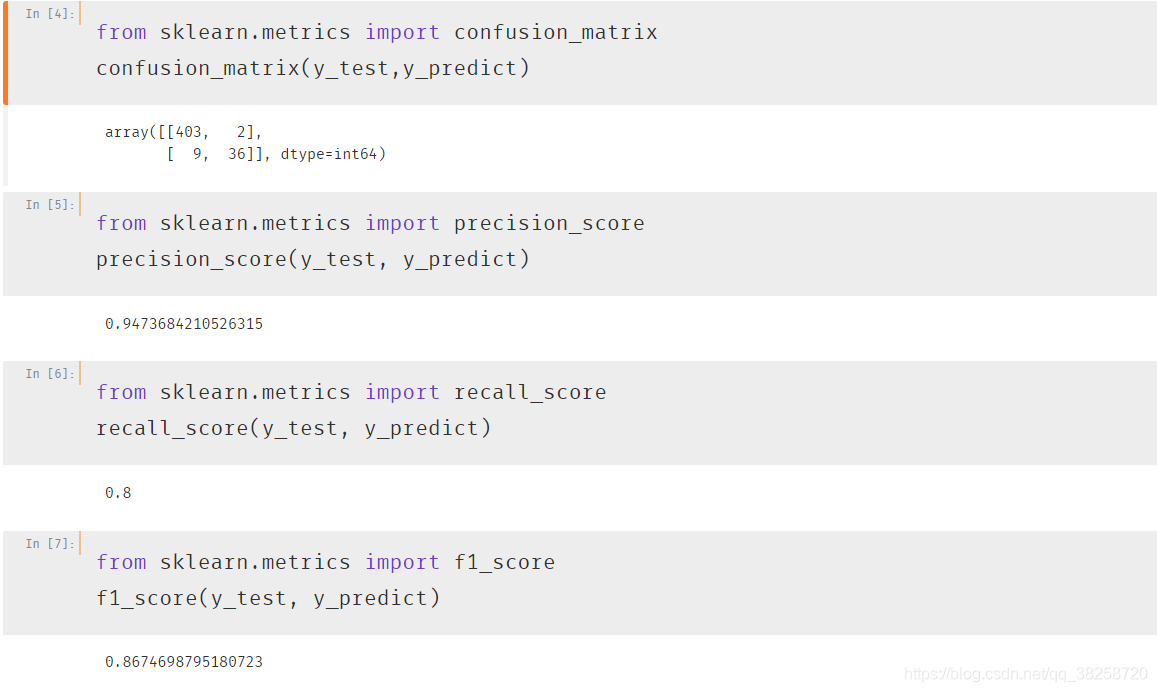
二.精準率和召回率
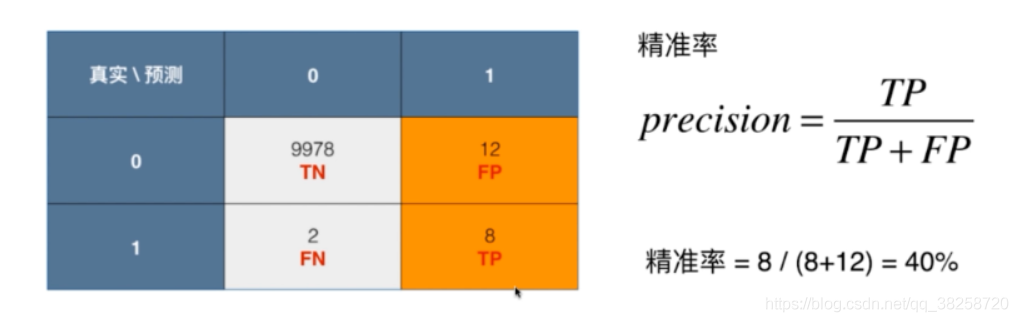
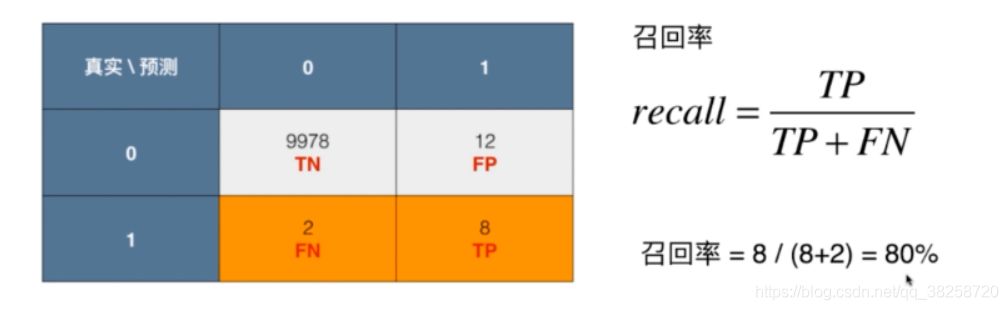
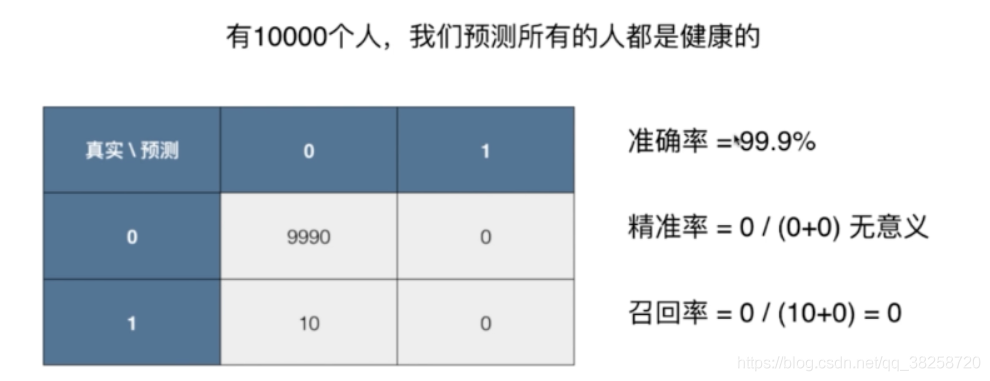 上圖說明只看準確率是遠遠不夠的,
上圖說明只看準確率是遠遠不夠的,

測驗資料:
from sklearn import datasets
from sklearn.model_selection import train_test_split
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
y[digits.target==9] = 1
y[digits.target!=9] = 0
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
邏輯回歸預測:
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
log_reg.score(X_test, y_test) #0.9755555555555555
y_predict = log_reg.predict(X_test)
三.Precision-Recall的平衡
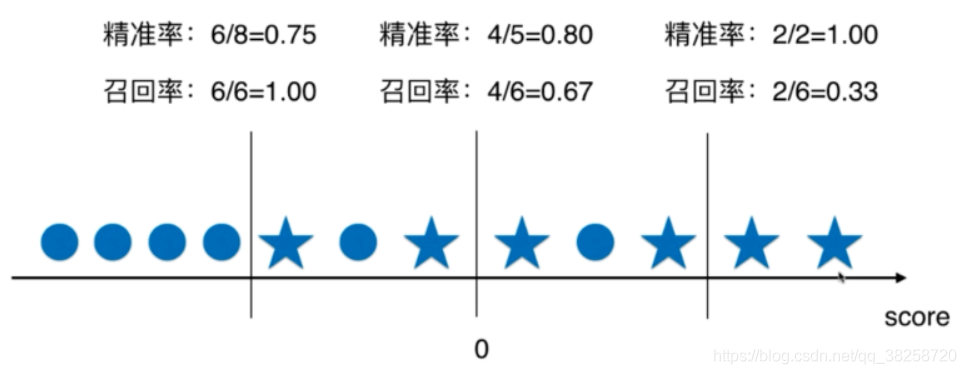 左邊為0,右邊為1,五角星為1,圓圈為0
左邊為0,右邊為1,五角星為1,圓圈為0
精準率增大時召回率降低
精準率高,則對特別有把握時才預測對,則以前本該算預測對的,變成不對,召回率就越低
召回率高,降低判斷, 10%的概率也說有病
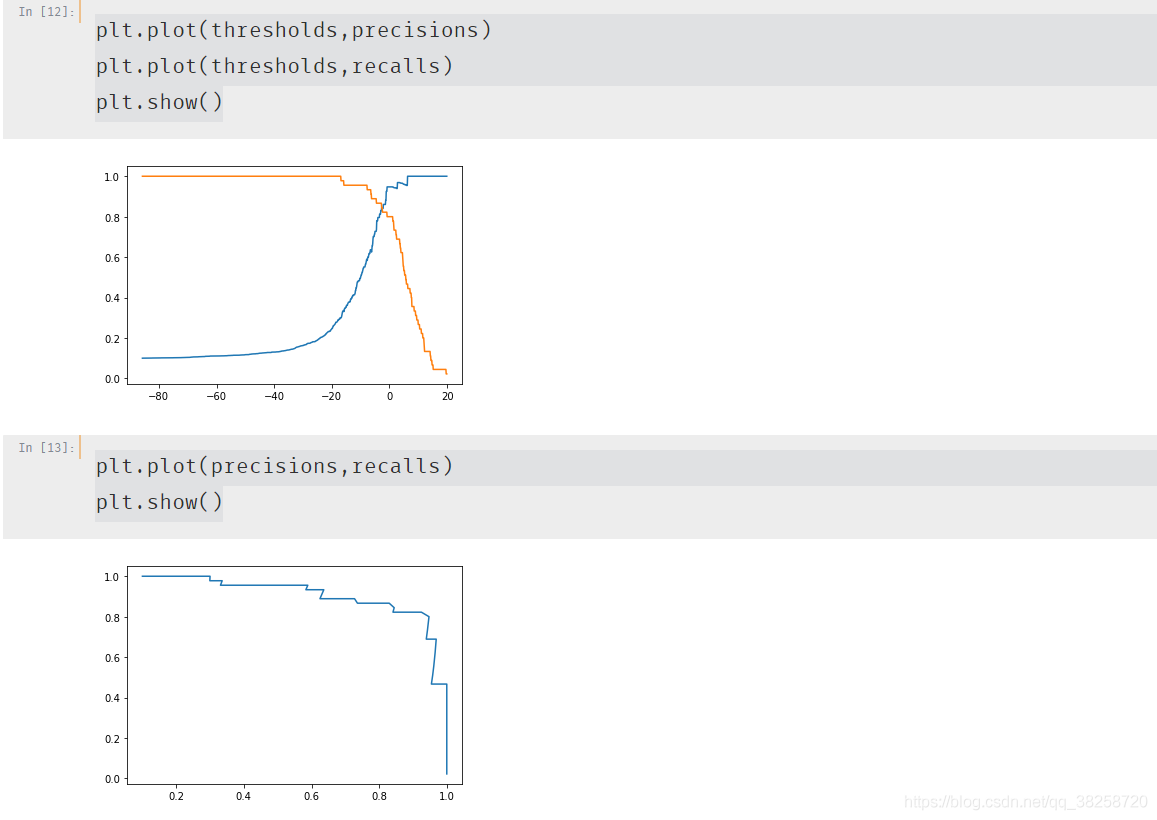
自定義曲線:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target.copy()
y[digits.target==9] = 1
y[digits.target!=9] = 0
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
decision_scores = log_reg.decision_function(X_test)
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
precisions = []
recalls = []
thresholds = np.arange(np.min(decision_scores), np.max(decision_scores), 0.1)
for threshold in thresholds:
y_predict = np.array(decision_scores >= threshold, dtype='int')
precisions.append(precision_score(y_test, y_predict))
recalls.append(recall_score(y_test, y_predict))
使用sklearn中的包:
from sklearn.metrics import precision_recall_curve
precisions,recalls,thresholds = precision_recall_curve(y_test,decision_scores)
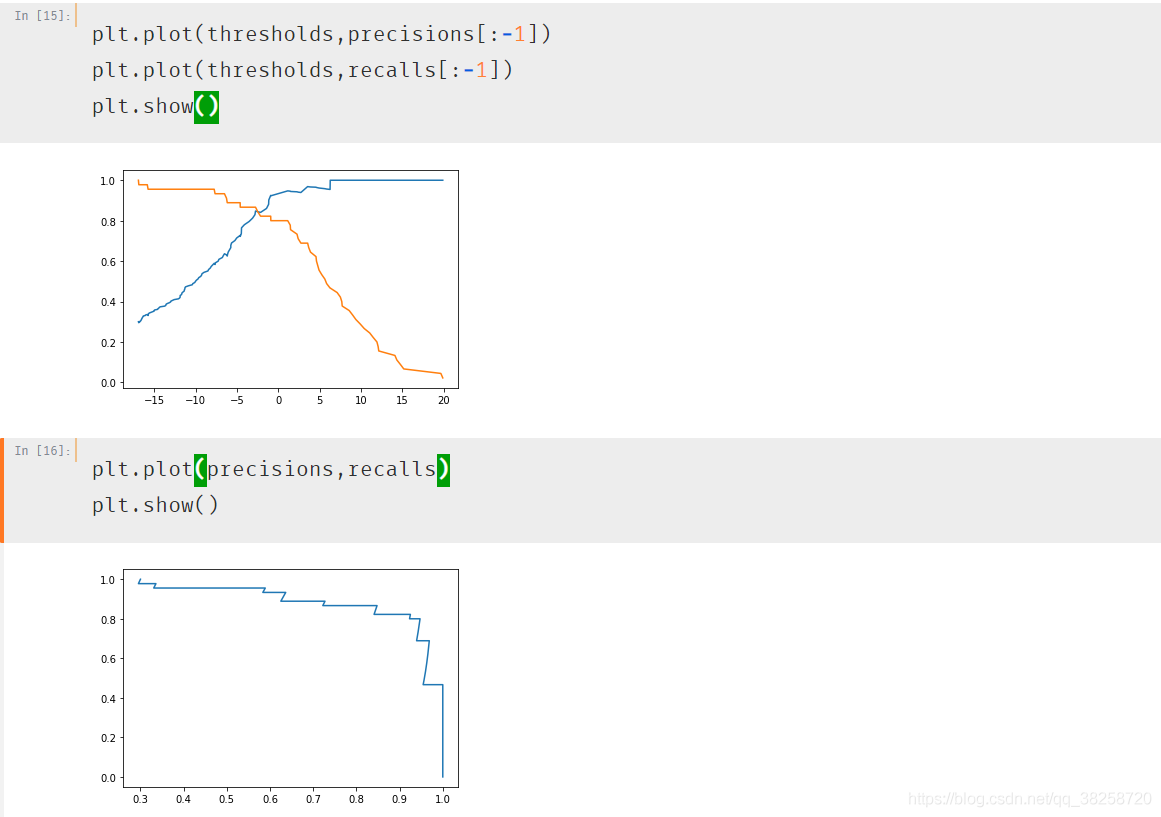
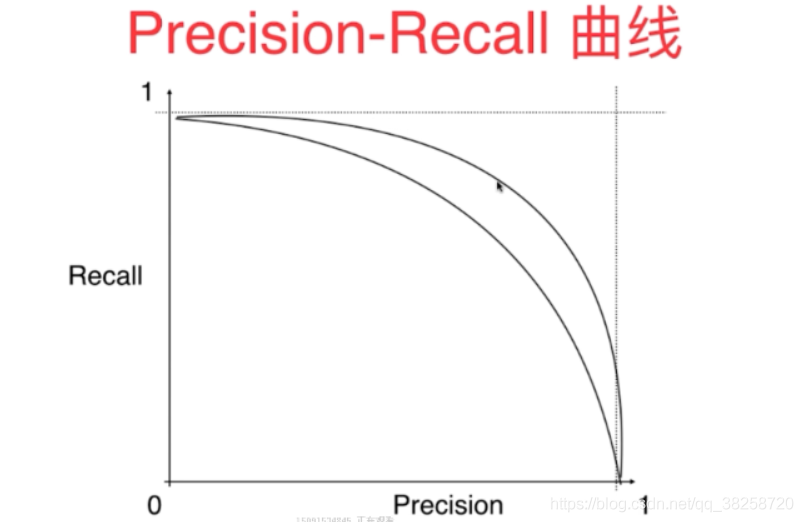
橫軸是P,縱軸是R
PR曲線靠外或xy軸的面積大則對應的模型好
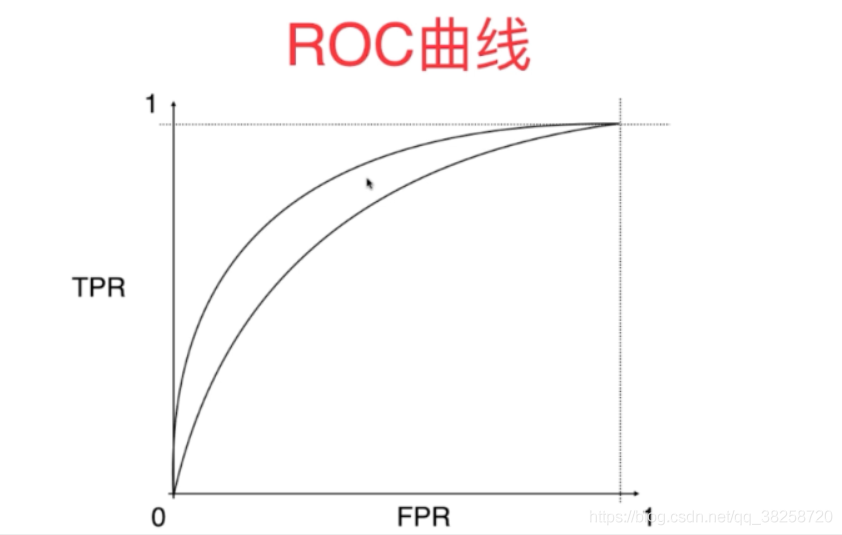
四.ROC曲線
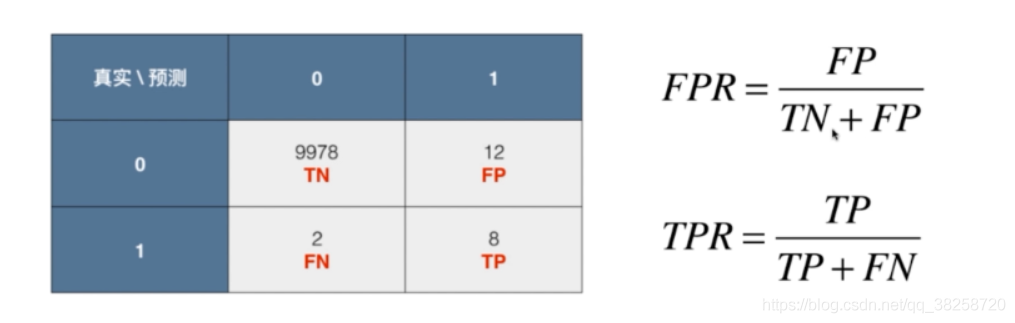
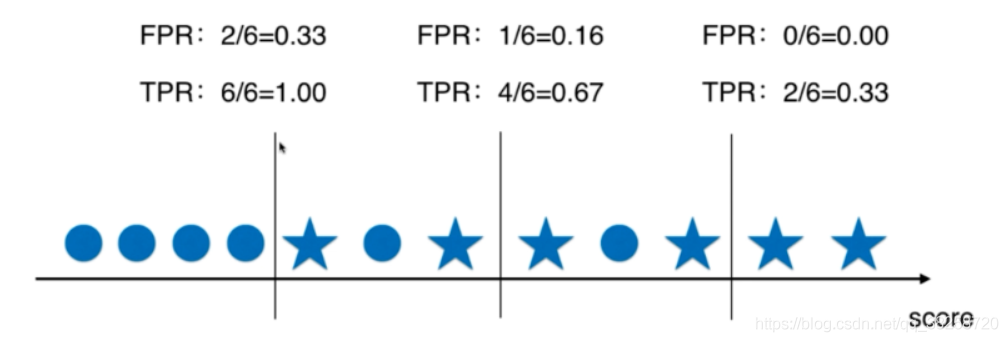
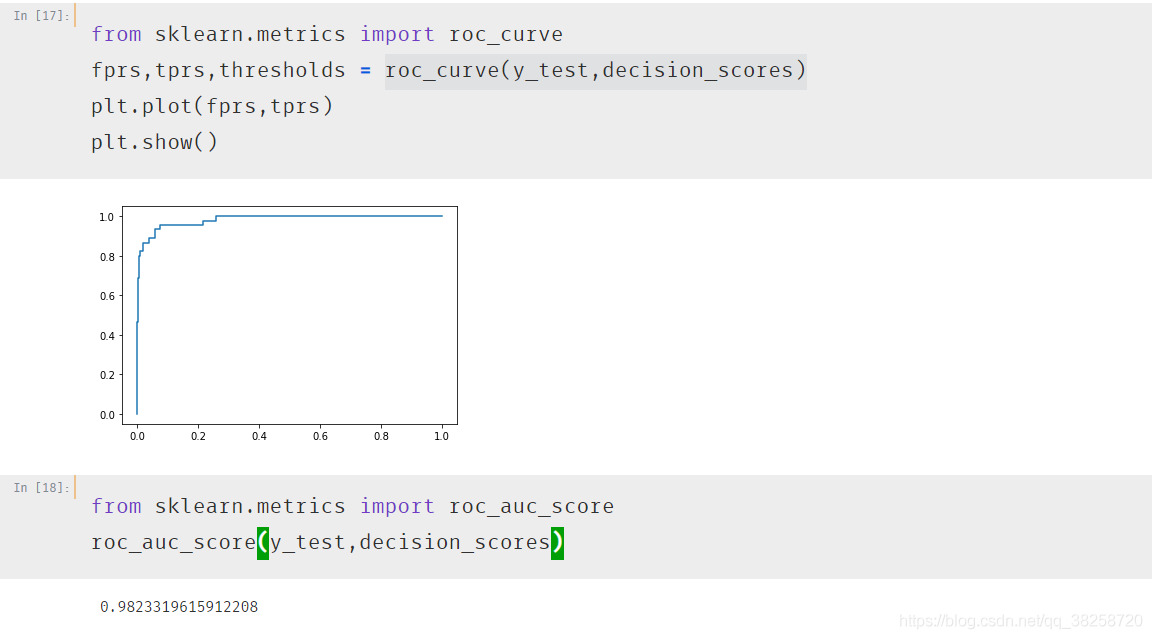
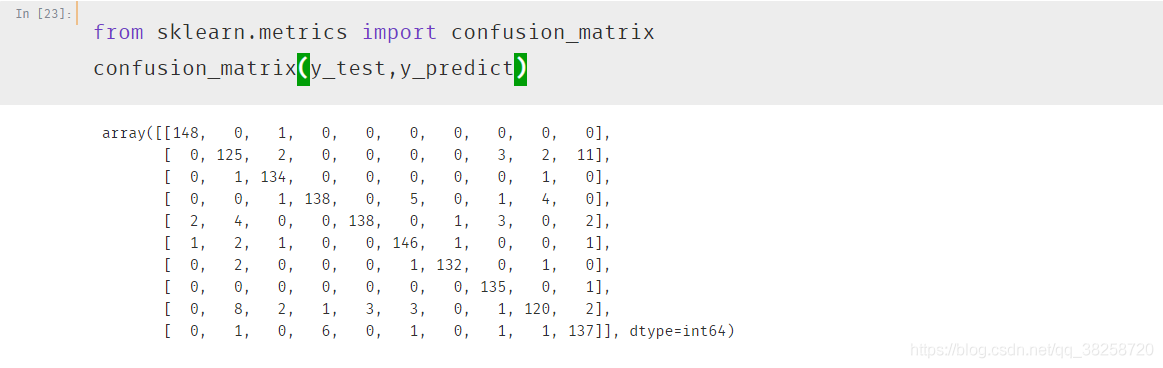
五.多分類問題中的混淆矩陣
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.8, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
log_reg.score(X_test, y_test)
y_predict = log_reg.predict(X_test)
from sklearn.metrics import precision_score
precision_score(y_test, y_predict,average='micro')
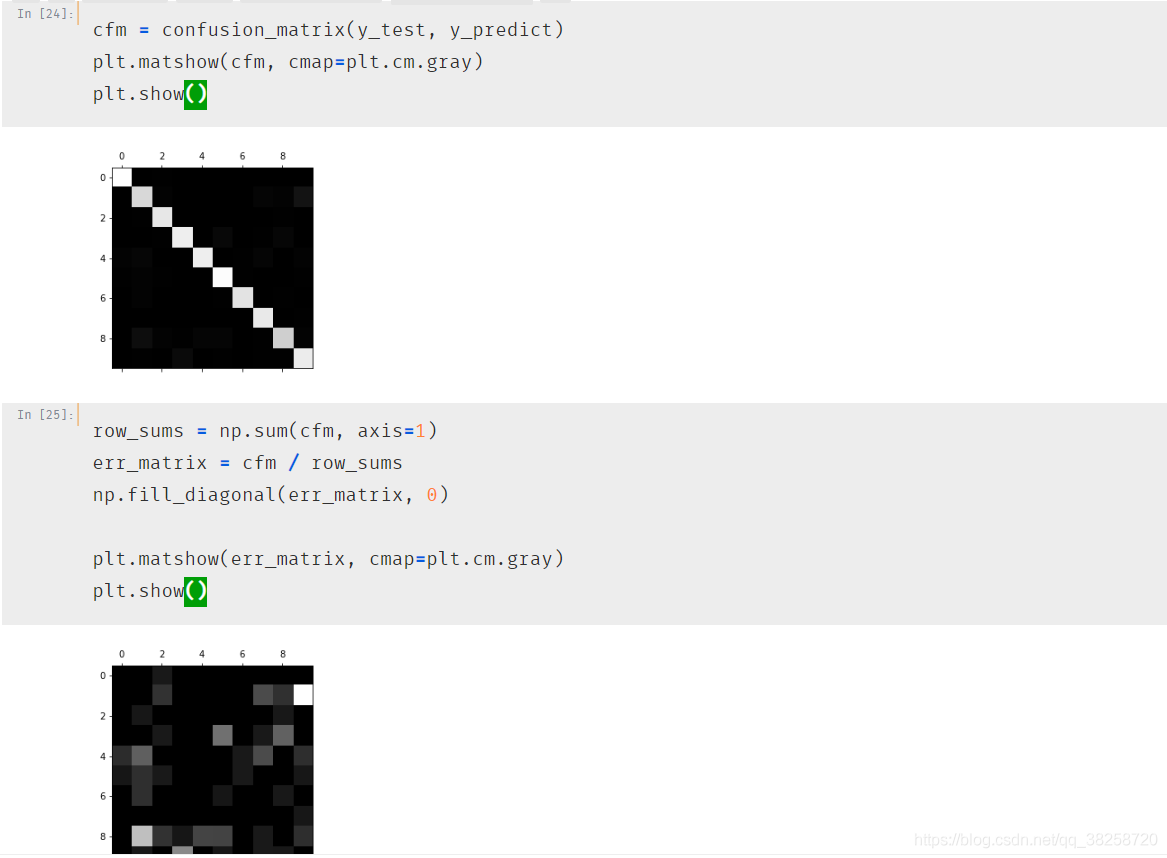
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/157800.html
標籤:其他