學會這招,小姐姐看你的眼神將不一樣
- 前言
- 一、爬蟲分析
- 二、爬取專案ID
- 1.抓取帖子的URL
- 2.提取帖子中的UUID
- 3.完整代碼
- 三、爬取專案的資料
- 寫在最后
前言
今天某小麗同學來找我,有個實驗需要用到輕松籌的資料進行一個分析,可是沒有足夠的資料,如何辦是好?
樂于助人的我,當然不會置之不理~
(ps.畢竟是小姐姐嘛,拒絕了不好,對叭)
于是乎,我抄起家伙,說干就干,
一、爬蟲分析
通過簡單的分析,可以發現輕松籌提供了一個介面,可以回傳某個專案的相關資料,具體如下:
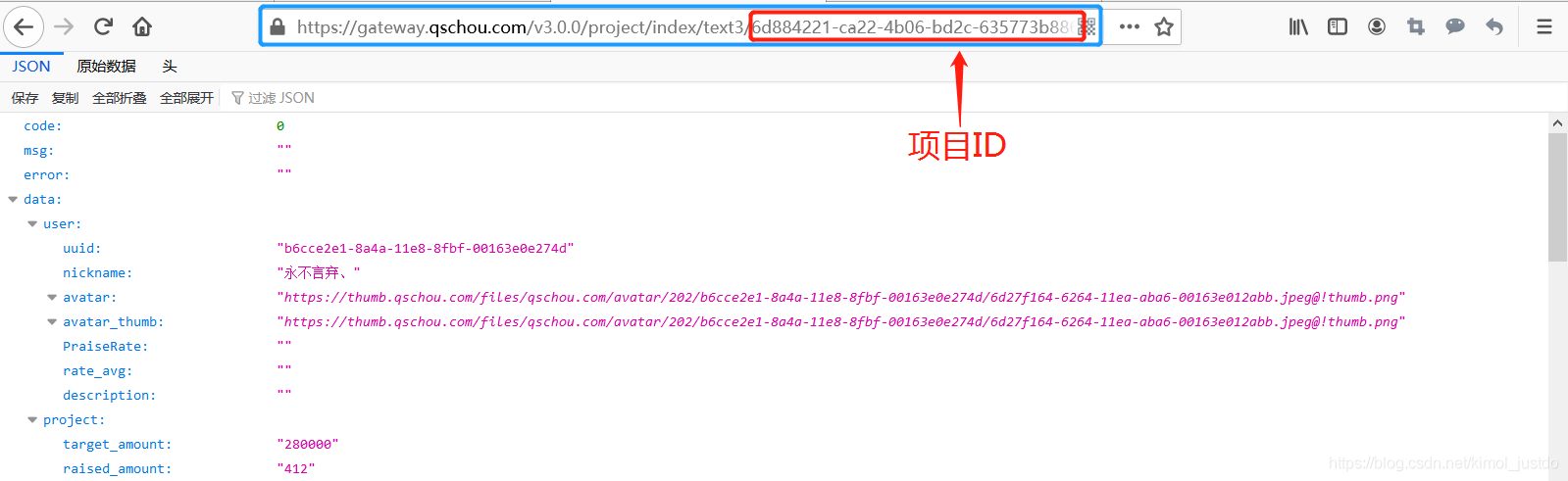
地址如下,xxxxxx表示專案的UUID:
https://gateway.qschou.com/v3.0.0/project/index/text3/xxxxxx
也就是說,我們只要有UUID,那么就可以通過requests發送請求很容易就能得到資料,這還不簡單,我們對UUID進行遍歷不就行了嘛?
然而,UUID的長度為32位,要是想遍歷的話,等明年去叭…
解決問題(小聲說:“獲得小姐姐的青睞”)的關鍵就是想辦法找到專案的UUID,
二、爬取專案ID
在官網搜尋了一番,并沒有發現哪里有UUID,于是,我們只能另辟蹊徑,最后,我決定從百度貼吧入手,搜索相關的帖子,并把帖子中的專案鏈接中的UUID提取出來,
1.抓取帖子的URL
遍歷整個“輕松籌吧”,抓取每個帖子的URL:
url_tieba = 'https://tieba.baidu.com/f?kw=輕松籌&ie=utf-8&pn=%d' # 貼吧頁面,pn=0,50,100...
p_href = 'href="/p/(.*?)"'
hrefs = []
for i in range(1): # 爬取的頁數
try:
pn = i*50
res = requests.get(url_tieba%pn)
html = res.text
list_herf = re.findall(p_href,html)
for h in list_herf:
hrefs.append('https://tieba.baidu.com/p/'+h)
print('第%d頁獲取成功'%(i+1))
except:
pass
with open('tiezi_url.txt','w') as f:
for h in hrefs:
f.write(h+'\n')
2.提取帖子中的UUID
要獲取每個帖子里面的專案UUID,主要有兩種方式:
(1)從帖子中的鏈接中提取
首先定義匹配鏈接的正則運算式:
p_projuuid = 'https://m2.qschou.com.*?projuuid=(.*?)&'
對帖子進行匹配:
for h in hrefs:
try:
res = requests.get(h)
html = res.text
list_projuuid = re.findall(p_projuuid,html) # 判斷帖子里是否有直接的鏈接
if len(list_projuuid) != 0:
for p in list_projuuid:
if p not in projuuids and len(p) == 36:
projuuids.append(p)
print('%s 提取到projuuid:%s'%(h,p))
else: # 提取帖子中的圖片獲取二維碼
list_img = re.findall(p_img,html)
if len(list_img) == 0:
print('%s 無法提取到projuuid'%h)
else:
for i in list_img:
txt_list = get_ewm(i)
if len(txt_list) != 0:
barcodeData = txt_list[0].data.decode("utf-8")
for p in re.findall('projuuid=(.*)',barcodeData):
if p not in projuuids and len(p) == 36:
projuuids.append(p)
print('%s 提取到projuuid:%s'%(h,p))
except:
pass
(2)從帖子中的二維碼中提取
首先,我們得匹配帖子中的所有圖片,正則如下:
p_img = 'class="BDE_Image" src="(.*?)"'
然后對其中的每張圖片,進行二維碼讀取,如果包含專案連接則將其中的UUID提取出來:
for h in hrefs:
try:
res = requests.get(h)
html = res.text
list_projuuid = re.findall(p_projuuid,html) # 判斷帖子里是否有直接的鏈接
if len(list_projuuid) != 0:
for p in list_projuuid:
if p not in projuuids and len(p) == 36:
projuuids.append(p)
print('%s 提取到projuuid:%s'%(h,p))
else: # 提取帖子中的圖片獲取二維碼
list_img = re.findall(p_img,html)
if len(list_img) == 0:
print('%s 無法提取到projuuid'%h)
else:
for i in list_img:
txt_list = get_ewm(i)
if len(txt_list) != 0:
barcodeData = txt_list[0].data.decode("utf-8")
for p in re.findall('projuuid=(.*)',barcodeData):
if p not in projuuids and len(p) == 36:
projuuids.append(p)
print('%s 提取到projuuid:%s'%(h,p))
except:
pass
其中,讀取二維碼的函式如下:
def get_ewm(img_adds):
# 讀取二維碼的內容: img_adds:二維碼地址(可以是網址也可是本地地址)
if os.path.isfile(img_adds):
# 從本地加載二維碼圖片
img = Image.open(img_adds)
else:
# 從網路下載并加載二維碼圖片
rq_img = requests.get(img_adds).content
img = Image.open(BytesIO(rq_img))
txt_list = pyzbar.decode(img)
#barcodeData = txt_list[0].data.decode("utf-8")
return txt_list
注意:這里需要用到pyzbar庫,通過pip安裝即可:
pip install pyzbar
3.完整代碼
import re
import os
import requests
from PIL import Image
from io import BytesIO
from pyzbar import pyzbar
def get_ewm(img_adds):
# 讀取二維碼的內容: img_adds:二維碼地址(可以是網址也可是本地地址)
if os.path.isfile(img_adds):
# 從本地加載二維碼圖片
img = Image.open(img_adds)
else:
# 從網路下載并加載二維碼圖片
rq_img = requests.get(img_adds).content
img = Image.open(BytesIO(rq_img))
txt_list = pyzbar.decode(img)
#barcodeData = txt_list[0].data.decode("utf-8")
return txt_list
if __name__ == '__main__':
# 獲取每個帖子的編號
url_tieba = 'https://tieba.baidu.com/f?kw=輕松籌&ie=utf-8&pn=%d' # 貼吧頁面,pn=0,50,100...
p_href = 'href="/p/(.*?)"'
hrefs = []
for i in range(1): # 爬取的頁數
try:
pn = i*50
res = requests.get(url_tieba%pn)
html = res.text
list_herf = re.findall(p_href,html)
for h in list_herf:
hrefs.append('https://tieba.baidu.com/p/'+h)
print('第%d頁獲取成功'%(i+1))
except:
pass
with open('tiezi_url.txt','w') as f:
for h in hrefs:
f.write(h+'\n')
# 爬取每個帖子中的輕松籌鏈接
projuuids = []
p_projuuid = 'https://m2.qschou.com.*?projuuid=(.*?)&'
p_img = 'class="BDE_Image" src="(.*?)"'
for h in hrefs:
try:
res = requests.get(h)
html = res.text
list_projuuid = re.findall(p_projuuid,html) # 判斷帖子里是否有直接的鏈接
if len(list_projuuid) != 0:
for p in list_projuuid:
if p not in projuuids and len(p) == 36:
projuuids.append(p)
print('%s 提取到projuuid:%s'%(h,p))
else: # 提取帖子中的圖片獲取二維碼
list_img = re.findall(p_img,html)
if len(list_img) == 0:
print('%s 無法提取到projuuid'%h)
else:
for i in list_img:
txt_list = get_ewm(i)
if len(txt_list) != 0:
barcodeData = txt_list[0].data.decode("utf-8")
for p in re.findall('projuuid=(.*)',barcodeData):
if p not in projuuids and len(p) == 36:
projuuids.append(p)
print('%s 提取到projuuid:%s'%(h,p))
except:
pass
with open('projuuids.txt','w') as f:
for p in projuuids:
f.write(p+'\n')
三、爬取專案的資料
這里通過遍歷之前獲得的UUID,即可獲得相應的資料:
import requests
import pandas as pd
# 讀取projuuid
with open('projuuids.txt','r') as f:
projuuids = f.readlines()
for i in range(len(projuuids)): # 去除尾部換行符
projuuids[i] = projuuids[i][:-1]
# 獲取資料
url_api = 'https://gateway.qschou.com/v3.0.0/project/index/text3/%s'
datas = []
for projuuid in projuuids:
res = requests.get(url_api%projuuid)
data_json = res.json()
data = data_json['data']['project']
data['certification'] = data_json['data']['subsidy'][1]['subhead'].split()[-2]
datas.append(data)
print('%s 獲取完畢'%projuuid)
datas = pd.DataFrame(datas)
datas.to_csv('data.csv',encoding='utf-8',index=False)
寫在最后
至此,大功告成,我也獲得了小姐姐的贊美,嘻嘻~
最后,感謝各位大大的耐心閱讀~
慢著,大俠請留步… 動起可愛的雙手,來個贊再走唄 (???←?)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/157806.html
標籤:其他