1 AOP實作Redis快取服務
1.1 現有代碼的分析
說明:
1.雖然在業務層service中完成了代碼的實作.但是該代碼不具有復用性.如果換了其他的業務則需要重新編輯.
2.由于快取的代碼寫在業務層service中,所以代碼的耦合性高,不方便以后的擴展.
需求:
1.能否實作代碼的復用.
2.能否降低代碼的耦合性.
1.2 AOP
1.2.1 AOP作用
名稱:面向切面編程.
一句話總結: 在不改變原有代碼的條件下,對功能進行擴展.
公式: AOP = 切入點運算式 + 通知方法.
專業術語:
1.連接點: 在執行正常的業務程序中滿足了切入點運算式時進入切面的點.(織入) 多個
2.通知: 在切面中執行的具體的業務(擴展) 方法
3.切入點: 能夠進入切面的一個判斷 if判斷 一個
4.目標方法: 將要執行的真實的業務邏輯.
1.2.2 關于通知說明
1.前置通知: 目標方法執行之前執行
2.后置通知: 目標方法執行之后執行
3.例外通知: 目標方法執行之后拋出例外時執行
4.最終通知: 不管什么時候都要執行的方法.
說明:上述的四大通知型別不能控制目標方法是否執行.一般使用上述的四大通知型別,都是用來記錄程式的執行狀態.
5.環繞通知: 在目標方法執行前后都要執行的通知方法. 控制目標方法是否執行.并且環繞通知的功能最為強大.
1.2.3 切入點運算式說明
1). bean(bean的id) 類名首字母小寫 匹配1個類
2). within(包名.類名) 按包路徑匹配類 匹配多個類
上述運算式是粗粒度的控制,按類匹配.
3).execution(回傳值型別 包名.類名.方法名(引數串列))
4).@annotation(包名.注解名) 按注解進行攔截.
1.2.4 AOPDemo復習
package com.jt.aop;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
@Component //將物件交給spring容器管理
@Aspect //標識我是一個切面
public class CacheAOP {
/**
* AOP = 切入點運算式 + 通知方法.
*
* 攔截需求:
* 1.要求攔截itemCatServiceImpl的bean
* 2.攔截com.jt.service下的所有的類
* 3.攔截com.jt.service下的所有類及方法
* 3.1攔截com.jt.service的所有的類.回傳值為int型別的.并且add開頭
* 的方法.并且引數一個 為String型別
*/
//@Pointcut(value = "bean(itemCatServiceImpl)")
//@Pointcut("within(com.jt.service..*)")
//攔截com.jt.service下的所有類的所有方法的任意引數型別
//@Pointcut("execution(int com.jt.service..*.add*(String))")
@Pointcut("execution(* com.jt.service..*.*(..))")
public void pointcut(){
}
//定義前置通知
@Before("pointcut()")
public void before(){
System.out.println("我是前置通知");
}
}
1.3 實作Redis快取
1.3.1 需求分析
1.自定義注解CacheFind 主要被注解標識的方法,則開啟快取的實作.
2.為了將來區分業務,需要在注解中標識key屬性,由使用者自行填寫.
3.為了用戶提供資料超時功能.
1.3.2 自定義注解
@Retention(RetentionPolicy.RUNTIME) //該注解什么時候有效
@Target({ElementType.METHOD}) //對方法有效
public @interface CacheFind {
String key(); //該屬性為必須添加
int seconds() default 0; //設定超時時間 默認不超時
}
1.3.3 編輯CacheAOP
package com.jt.aop;
import com.jt.anno.CacheFind;
import com.jt.pojo.ItemDesc;
import com.jt.util.ObjectMapperUtil;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import redis.clients.jedis.Jedis;
import java.lang.reflect.Method;
import java.util.Arrays;
@Component //將物件交給spring容器管理
@Aspect //標識我是一個切面
public class CacheAOP {
//1.注入快取redis物件
@Autowired
private Jedis jedis;
/**
* 攔截@CacheFind注解標識的方法.
* 通知選擇: 快取的實作應該選用環繞通知
* 步驟:
* 1.動態生成key 用戶填寫的key+用戶提交的引數
*/
@Around("@annotation(cacheFind)")
public Object around(ProceedingJoinPoint joinPoint, CacheFind cacheFind){
//1.如何獲取用戶在注解中填寫的內容呢??? 如何獲取注解物件....
String key = cacheFind.key(); //前綴 ITEM_CAT_PARENTID
//2.如何獲取目標物件的引數呢???
Object[] array = joinPoint.getArgs();
key += "::"+Arrays.toString(array); // "ITEM_CAT_PARENTID::[0]"
//3.從redis中獲取資料
Object result = null;
if(jedis.exists(key)){
//需要獲取json資料之后,直接轉化為物件回傳!!
String json = jedis.get(key);
//如何獲取回傳值型別
MethodSignature methodSignature =
(MethodSignature) joinPoint.getSignature();
Class targetClass = methodSignature.getReturnType();
result = ObjectMapperUtil.toObject(json,targetClass);
System.out.println("AOP實作快取的查詢!!!");
}else{
//key不存在,應該查詢資料庫
try {
result = joinPoint.proceed(); //執行目標方法,獲取回傳值結果
String json = ObjectMapperUtil.toJSON(result);
if(cacheFind.seconds()>0){ //判斷是否需要超時時間
jedis.setex(key, cacheFind.seconds(), json);
}else{
jedis.set(key,json);
}
System.out.println("AOP執行資料庫操作!!!");
} catch (Throwable throwable) {
throwable.printStackTrace();
throw new RuntimeException(throwable);
}
}
return result;
}
/**
* AOP = 切入點運算式 + 通知方法.
*
* 攔截需求:
* 1.要求攔截itemCatServiceImpl的bean
* 2.攔截com.jt.service下的所有的類
* 3.攔截com.jt.service下的所有類及方法
* 3.1攔截com.jt.service的所有的類.回傳值為int型別的.并且add開頭
* 的方法.并且引數一個 為String型別
*/
//@Pointcut(value = "bean(itemCatServiceImpl)")
//@Pointcut("within(com.jt.service..*)")
//攔截com.jt.service下的所有類的所有方法的任意引數型別
//@Pointcut("execution(int com.jt.service..*.add*(String))")
/* @Pointcut("execution(int com.jt.service..*.add*(String))")
public void pointcut(){
}
//定義前置通知
@Before("pointcut()")
public void before(){
System.out.println("我是前置通知");
}*/
}
1.3.4 關于環繞通知引數的說明
問題一:連接點必須位于通知的引數的第一位.

否則報錯資訊如下:

問題二: 其他四大通知了型別是否可以添加ProceedingJoinPoint物件
答案: ProceedingJoinPoint 只能添加到環繞通知中.
報錯如下:

1.3.5 關于JoinPoint方法說明
/**
* 要求: 攔截注解方法
* 列印:
* 1.列印目標物件的型別
* 2.列印方法的引數
* 3.獲取目標物件的名稱及方法的名稱
* @param joinPoint
*/
@Before("@annotation(com.jt.anno.CacheFind)")
public void before(JoinPoint joinPoint){
Object target = joinPoint.getTarget(); //獲取目標物件
Object[] args = joinPoint.getArgs(); //獲取方法引數的
String targetName =
joinPoint.getSignature().getDeclaringTypeName(); //獲取目標物件的名稱
//獲取目標物件的型別
Class targetClass = joinPoint.getSignature().getDeclaringType();
//獲取目標方法的名稱
String methodName = joinPoint.getSignature().getName();
System.out.println(target);
System.out.println(args);
System.out.println(targetName);
System.out.println(targetClass);
System.out.println(methodName);
}
1.4 商品串列分類實作快取處理
說明:在業務方法中添加快取的注解.
/**
* 分析業務: 通過itemCatId獲取商品分類的名稱
* 1.url地址: url:"/item/cat/queryItemName",
* 2.引數: {itemCatId:val},
* 3.回傳值: 商品分類名稱 String
*/
@RequestMapping("/queryItemName")
@CacheFind(key="ITEM_CAT_NAME")
public String findItemCatName(Long itemCatId){
return itemCatService.findItemCatNameById(itemCatId);
}
2.Redis分片機制
2.1 需求資料
如果需要在redis中進行海量的資料存盤,如果只有一臺redis顯然不能實作該功能.如果通過擴大記憶體的方式也不能達到要求.因為時間都浪費在尋址中. 如何有效的存盤海量的資料呢???
2.2 Redis分片說明
說明:一般采用多臺redis,分別保存用戶的資料,從而實作記憶體資料的擴容.
對于用戶而言:將redis分片當做一個整體,用戶不在乎資料到底存盤到哪里,只在乎能不能存.
分片主要的作用: 實作記憶體擴容.
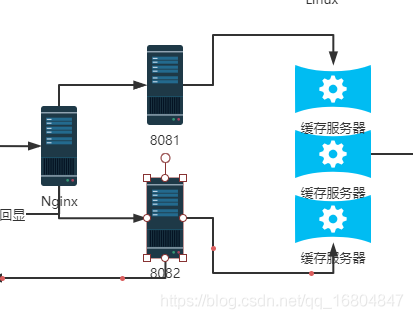
2.3 Redis分片準備
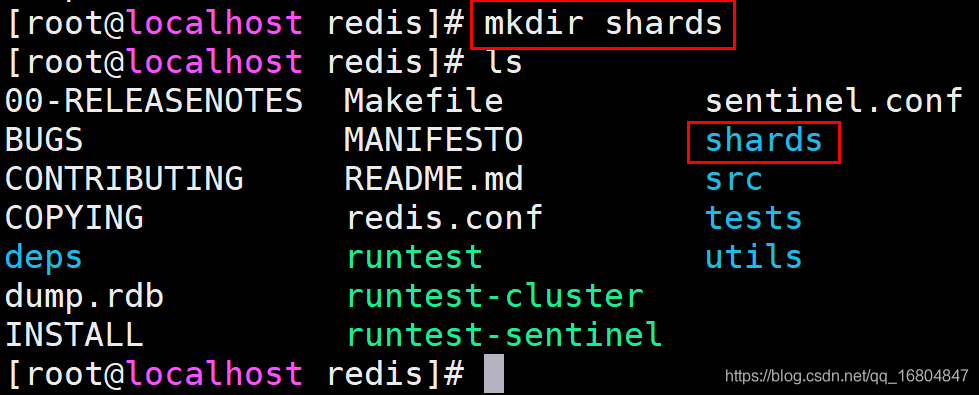
2.3.1 創建目錄
說明:在redis根目錄中創建一個shards目錄
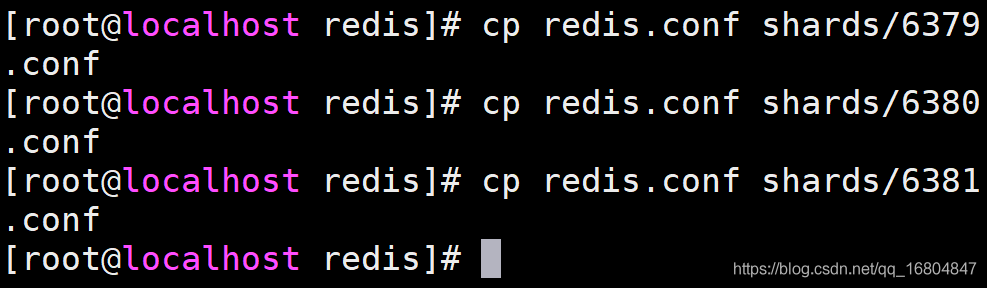
2.3.2 分片搭建策略
說明:由于Redis啟動是根據組態檔運行的,所以如果需要準備3臺redis,則需要復制3份組態檔redis.conf. 埠號依次為6379/6380/6381
復制組態檔:
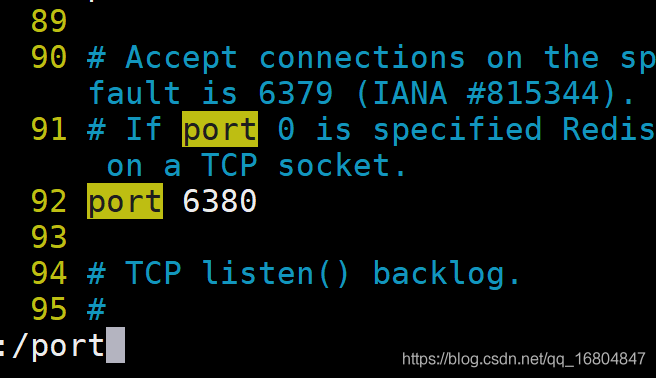
修改埠號:
根據組態檔名稱,動態修改對應的埠即可.

啟動redis:
redis-server 6379.conf
redis-server 6380.conf
redis-server 6381.conf

2.3.3 Redis分片入門案例
/**
* 測驗Redis分片機制
* 業務思路:
* 用戶需要通過API來操作3臺redis.用戶無需關心資料如何存盤,
* 只需要了解資料能否存盤即可.
* 思考: 2005的資料存盤到哪臺redis中
* redis分片是如何實作資料存盤的!
*/
@Test
public void testShards(){
List<JedisShardInfo> list = new ArrayList<>();
list.add(new JedisShardInfo("192.168.126.129", 6379));
list.add(new JedisShardInfo("192.168.126.129", 6380));
list.add(new JedisShardInfo("192.168.126.129", 6381));
ShardedJedis shardedJedis = new ShardedJedis(list);
shardedJedis.set("2005", "redis分片學習");
System.out.println(shardedJedis.get("2005"));
}
2.4 一致性hash演算法
2.4.1 演算法介紹
一致性哈希演算法在1997年由麻省理工學院提出,是一種特殊的哈希演算法,目的是解決分布式快取的問題, [1] 在移除或者添加一個服務器時,能夠盡可能小地改變已存在的服務請求與處理請求服務器之間的映射關系,一致性哈希解決了簡單哈希演算法在分布式哈希表( Distributed Hash Table,DHT) 中存在的動態伸縮等問題 [2] ,
2.4.2 常識介紹
1.常見hash多少位16進制數? 8位16進制數
2.16進制數取值有哪些 0-9 A-F 共16個數
3. hash的取值范圍從 00000000 ~ FFFFFFFF (24)8
4. 上述取值的個數共有多少個??? 要求以2為底 2^32 冪
5. 對相同的資料進行hash值一致
2.4.3 一致性hash說明
步驟:
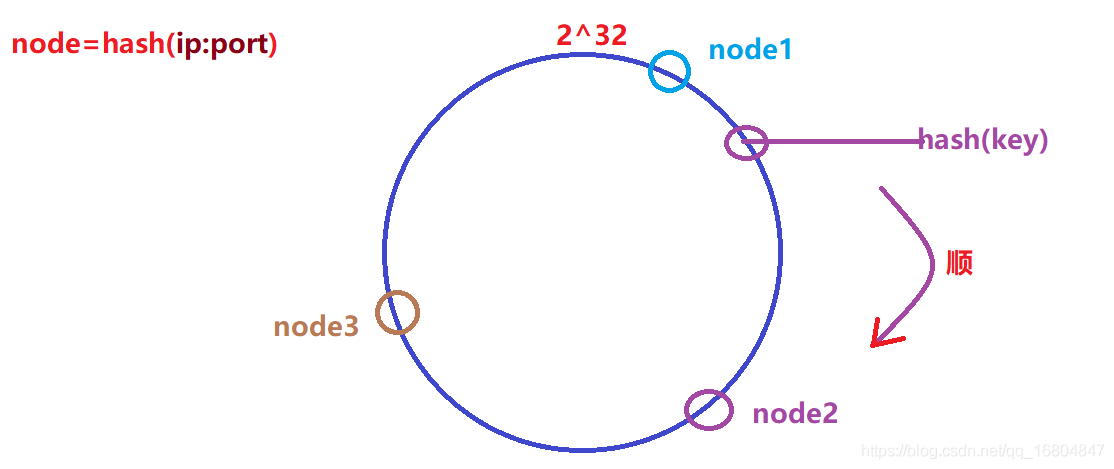
1.首先計算node節點
2.將用戶的key進行hash計算,之后按照順時針的方向找到最近的node節點之后鏈接,執行set操作.
2.4.3 特性一 平衡性
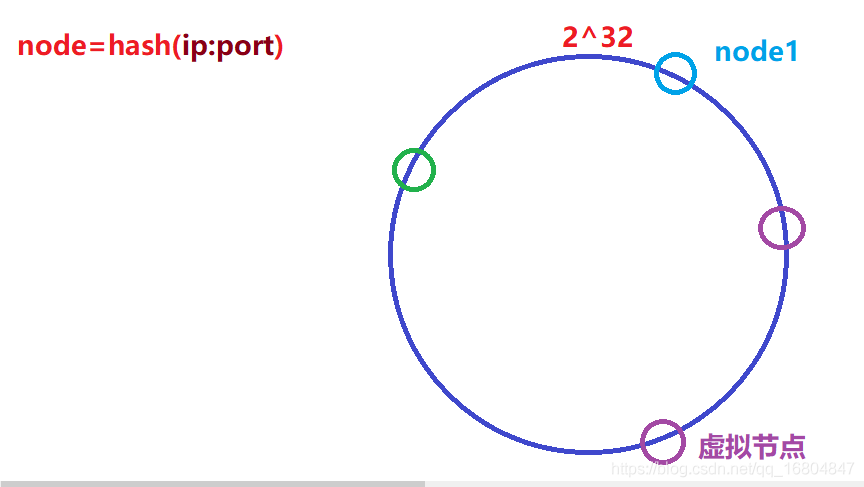
①平衡性是指hash的結果應該平均分配到各個節點,這樣從演算法上解決了負載均衡問題 [4] ,
說明: 如果發現節點中存盤的資料負載不均,則采用虛擬節點的方式實作資料的平衡(相對平衡)
2.4.3 特性一 單調性
②單調性是指在新增或者刪減節點時,不影響系統正常運行 [4] 因為可以實作自動的資料遷移.,
原則: 在進行資料遷移時 應該盡可能少的改變原有的資料.
2.4.4 特性一 分散性
③分散性是指資料應該分散地存放在分布式集群中的各個節點(節點自己可以有備份),不必每個節點都存盤所有的資料 [4] ,
雞蛋不要放在一個籃子里
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/16840.html
標籤:其他