關注持續更新inging!!!
1.層次分析法與數學建模
在數學建模中,通常解決的問題是:“影響某一問題的幾個因素的權重大小”、“產生某一問題的主要的因素分析”、“權重的大小分析”,當然在現實生活中的應用也是十分廣泛而且一樣的不知不覺,最簡單的就是你想去幾個地方旅游,但是要綜合考慮時間、金錢、當地的風景、當地的旅游數是否較多等等因素,
2.層次分析法的基本原理與步驟
層次分析法( Analytic Hierarchy Process,簡稱 AHP)是對一些較為復雜、較為模糊的問題作出決策的簡易方法,它特別適用于那些難于完全定量分析的問題,直白的說就是那些沒有什么資料,基本就是憑空和個人的主觀意識讓你去選擇一個最佳的目標或者判斷出對于一個目標,各個因素所占的權重,這樣一說,它的優點和缺點也就很明顯了:優點就是簡單明了,不需要太多資料的處理;缺點就是主觀性太強,因此如何盡量客觀的兩兩比較因素之間的相對重要程度就比較重要了,基本上,大家的論文上寫的都是”在查閱相關資料后,得到如下判斷矩陣”,運用層次分析法建模,大體上可按下面四個步驟進行:
( i)建立遞階層次結構模型;
( ii)構造出各層次中的所有判斷矩陣;
( iii)層次單排序及一致性檢驗;
( iv)層次總排序及一致性檢驗,
具體來說就是:
( i)最高層:這一層次中只有一個元素,一般它是分析問題的預定目標或理想結果,因此也稱為目標層,
( ii)中間層:這一層次中包含了為實作目標所涉及的中間環節,它可以由若干
個層次組成,包括所需考慮的準則、子準則,因此也稱為準則層,
( iii)最底層:這一層次包括了為實作目標可供選擇的各種措施、決策方案等,因此也稱為措施層或方案層,
需要注意的是:
遞階層次結構中的層次數與問題的復雜程度及需要分析的詳盡程度有關,一般地
層次數不受限制,每一層次中各元素所支配的元素一般不要超過 9 個,這是因為支配的元素過多會給兩兩比較判斷帶來困難,把三個層次畫出來會比較容易理解:
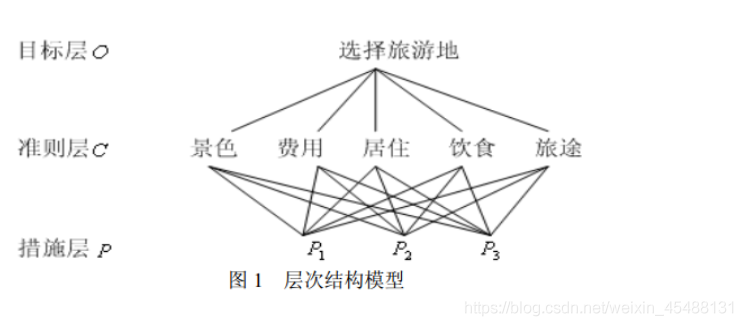
3.構造判斷矩陣
終于來到了正題,也是最基礎和重要的一個環節,層次結構反映了因素之間的關系,但準則層中的各準則在目標衡量中所占的比重并不一定相同,在決策者的心目中,它們各占有一定的比例,所以才會覺得如何判斷它們的相對大小很不容易,
設現在要比較 n 個因子 X = {x1,L, xn} 對某因素 Z 的影響大小, 怎樣比較才能提
供可信的資料呢? Saaty 等人建議可以采取對因子進行兩兩比較建立成對比較矩陣的辦法,即每次取兩個因子xi 和 x j ,以 aij 表示 xi 和 x j 對 Z 的影響大小之比,全部比較結果用矩陣A = (aij )n×n 表示,稱 A 為 Z ? X 之間的成對比較判斷矩陣(簡稱判斷矩陣),容易看出,若xi 與 x j 對 Z 的影響之比為 aij ,則 x j 與 xi 對 Z 的影響之比應為1/aij,
關于如何確定aij 的值, Saaty 等建議參考數字 1~9 及其倒數作為標度,

至于如何分為9個標度,據說是和心理學有關系的,
4.判斷矩陣的一致性檢驗
當寫出來判斷矩陣之后還會存在一個問題,那就是按理來說如果i對j的重要程度是a,j對k的重要程度是b,那么理所應當i對k的重要程度應該a*b,有點符合“傳遞性”的感覺,但事實上不是這樣的,所以需要進行一致性檢驗,如果在一定的合理范圍之內,矩陣不需要修改,如果不在,則需要修改矩陣,我們可以由λmax 是否等于 n 來檢驗判斷矩陣 A 是否為一致矩陣,由于特征根連續地依賴于aij ,故 λmax 比 n 大得越多, A 的非一致性程度也就越嚴重,λmax 對應的標準化特征向量也就越不能真實地反映出 因素在對目標的影響中所占的比重,因此,對決策者提供的判斷矩陣有必要作一次一致性檢驗,以決定是否能接受它,
(1)計算一致性指標
CI=(入-n)/(n-1)
(2)查找平均隨機一致性指標RI

(3)計算一致性比例
CR=CI/RI
當CR < 0.10 時,認為判斷矩陣的一致性是可以接受的,否則應對判斷矩陣作適當修正
矩陣符合一致性檢驗后,可以進行計算了:判斷矩陣 A 對應于最大特征值λmax 的特征向量W ,經歸一化后即為同一層次相應因素對于上一層次某因素相對重要性的排序權值,這一程序稱為層次單排序,
5、層次總排序及一致性檢驗
上面我們得到的是一組元素對其上一層中某元素的權重向量,我們最終要得到各元素,特別是最低層中各方案對于目標的排序權重,從而進行方案選擇,總排序權重要自上而下地將單準則下的權重進行合成,
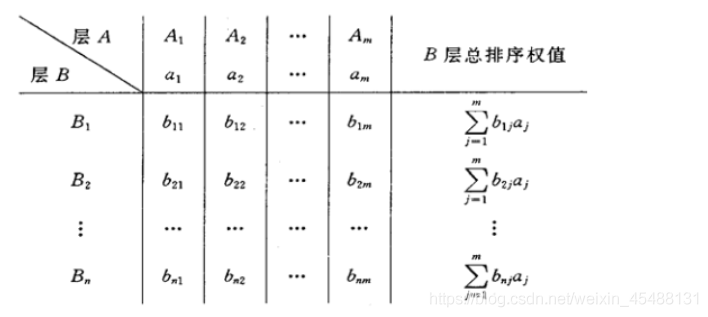
解釋一下,比如A1這一列的b11……bn1,分別表示對于A1這一個目標,b11……bn1的重要程度分布,
對層次總排序也需作一致性檢驗,檢驗仍象層次總排序那樣由高層到低層逐層進行,這是因為雖然各層次均已經過層次單排序的一致性檢驗,各成對比較判斷矩陣都已具有較為滿意的一致性,但當綜合考察時,各層次的非一致性仍有可能積累起來,引起最終分析結果較嚴重的非一致性,設 B 層中與Aj 相關的因素的成對比較判斷矩陣在單排序中經一致性檢驗,求得單排序一致性指標為CI( j) ,(j = 1,L,m ),相應的平均隨機一致性指標為 RI( j)( CI( j)、 RI( j) 已在層次單排序時求得),則 B 層總排序隨機一致性比例為
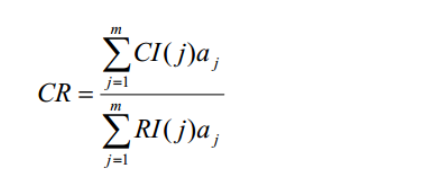
6、具體舉例及代碼
有一個畢業生為挑選合適的作業,經雙方懇談,已有三個單位表示愿意錄用某畢業生,該畢業生考慮的因素有6個,研究課題、發展前途、待遇、同事情況、地理位置和單位名氣,
那么這六個因素就是準則層,三個單位就是方案層,最后要求的就是應該去哪個單位,
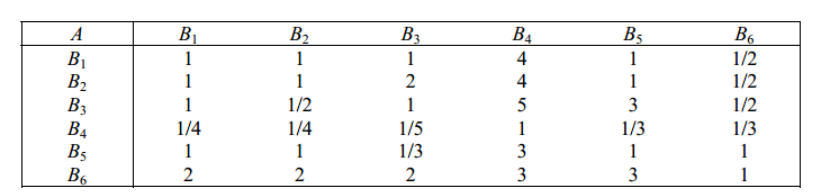
1)準則層判斷矩陣(主觀性)
2)方案層判斷矩陣(主觀性)
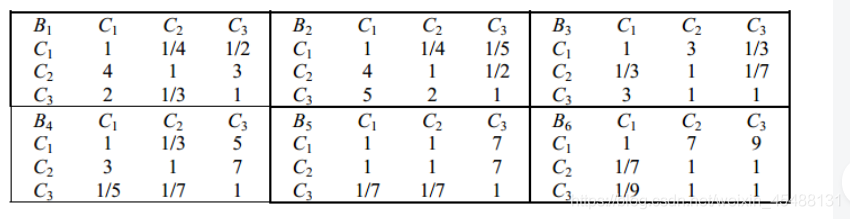
(分別針對每一個B,判斷C1、C2、C3之間的相對大小)
4)計算的 Matlab 程式如下:
clc,clear
fid=fopen(‘txt3.txt’,’r’);
n1=6;n2=3;
a=[];
for i=1:n1
tmp=str2num(fgetl(fid));
a=[a;tmp]; %讀準則層判斷矩陣
end
for i=1:n1
str1=char([‘b’,int2str(i),’=[];’]);
str2=char([‘b’,int2str(i),’=[b’,int2str(i),’;tmp];’]);
eval(str1);
for j=1:n2
tmp=str2num(fgetl(fid));
eval(str2); %讀方案層的判斷矩陣
end
-173-
end
ri=[0,0,0.58,0.90,1.12,1.24,1.32,1.41,1.45]; %一致性指標
[x,y]=eig(a);
lamda=max(diag(y));
num=find(diag(y)==lamda);
w0=x(:,num)/sum(x(:,num));
cr0=(lamda-n1)/(n1-1)/ri(n1)
for i=1:n1
[x,y]=eig(eval(char([‘b’,int2str(i)])));
lamda=max(diag(y));
num=find(diag(y)==lamda);
w1(:,i)=x(:,num)/sum(x(:,num));
cr1(i)=(lamda-n2)/(n2-1)/ri(n2);
end
cr1, ts=w1*w0, cr=cr1*w0
純文本檔案txt3.txt中的資料格式如下:
1 1 1 4 1 1/2
1 1 2 4 1 1/2
1 1/2 1 5 3 1/2
1/4 1/4 1/5 1 1/3 1/3
1 1 1/3 3 1 1
2 2 2 3 3 1
1 1/4 1/2
4 1 3
2 1/3 1
1 1/4 1/5
4 1 1/2
5 2 1
1 3 1/3
1/3 1 1/7
3 7 1
1 1/3 5
3 1 7
1/5 1/7 1
1 1 7
1 1 7
1/7 1/7 1
1 7 9
1/7 1 1
1/9 1 1

看上面 然后回復2020數學建模C題領取文獻,論文,還有層次分析法相關的,加油哦!!! 你懂的哦!!!
另外回復2020數學建模領取其他資料
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/16848.html
標籤:其他