目錄
一、寫作背景
二、文章指引
三、必要概念字典介紹
四、認識二進制日記(Binlog)
4.1 Binlog概念
4.2 Binlog 作用
4.3 Binlog 記錄程序及刷盤時機
4.4 Binlog 記錄格式
五、認識事務日記(Undo log)
5.1 Undo log 概念
5.2 Undo log 作用
5.3 Undo log 記錄程序及刷盤時機
5.4 Undo log 總結
六、認識事務日記 (Redo log)
6.1 Redo log 概念
6.2 Redo log 作用
6.3 Redo log 的兩階段提交
6.4 Redo log 容災恢復程序
6.5 Redo log 刷盤時機
6.6 Redo log 存盤方式
6.7 Redo Log 檢查點
6.8 Redo Log LSN
6.9 Redo log 容災恢復程序與LSN
七、了解 ChangeBuffer
7.1 為啥提到ChangeBuffer
7.2 ChangeBuffer概念及作用
7.3 ChangeBuffer與Redo log區別
7.4 有沒有用到ChangeBuffer對于Redo log的區別
7.5 ChangeBuffer的merge程序
八、日記大連貫U-R-B,一舉攻破拿下
8.1 制造演示資料
8.2 假設沒有日記和ChangeBuffer 示范
8.3 考慮所有日記和ChangeBuffer 示范--現有Innodb流程
8.3.1 兩階段提交程序
8.3.2 merge 程序
8.3.3 資料刷盤程序
九、結尾
一、寫作背景
大家都清楚,日志是 MySQL資料庫的重要組成部分,記錄著資料庫運行期間各種狀態資訊,MySQL日志主要包括錯誤日志、查詢日志、慢查詢日志、二進制日志(binlog)和事務日志(redo log、undo log)幾大類,
其中,二進制日記和事務日記尤為重要,一直被人重視、深入研究;可是事實很殘忍,重視或者說大多數人一般都是了解個表面,真正懂得人并不多,真想攻破這兩塊日記必須下血本,而且還不一定能攻破,但是不要緊,為了讓你們省下血本還能順利攻破這兩塊日記,我連續研究幾周MySQL日記,最終肝出了這篇文章,
二、文章指引
文章指導:文章第三節內容切莫跳過,但如果覺得第四、第五、第六和第七節沒意思或者已經有了概念,直接進入文章第八節一舉攻破拿下,
文章方向:理論、原理篇,
三、必要概念字典介紹
基礎不牢地動山搖,還是常規套路,先把必要知識普及/溫習一遍,當后續文章出現疑慮反過來看下這些概念字典,說不定能 “柳暗花明又一村” 呢?
寫了又寫,想了又想,糾結了好久,這部分知識確實有點多,最后還是決定將這些必要概念字典單獨分出一個文章,后續打算用截圖方式引入各個章節中,建議遇到不懂名詞查閱一下字典,
點擊獲取通往字典的大門的鑰匙--想學習進階資料庫知識???這些概念必須攻破!

四、認識二進制日記(Binlog)
4.1 Binlog概念
Binlog 是邏輯日記,用于記錄資料庫執行的寫入操作(查詢不記錄)資訊,Server層記錄和引擎層無關,并且是以追加方式進行寫入,可以通過引數 max_binlog_size 設定每個Binlog檔案的大小,檔案大小達到設定值時會生成新的檔案來保存日記,
![]()

4.2 Binlog 作用
在實際應用中,主要用在兩個場景:主從復制和資料恢復
- 主從復制場景:在Master主端開啟Binlog,將Binlog發生到各個Slave從端,Slave從端重放Binlog從而達到主從資料一致
- 資料恢復場景:通過使用 mysqlbinlog 工具來恢復資料
4.3 Binlog 記錄程序及刷盤時機
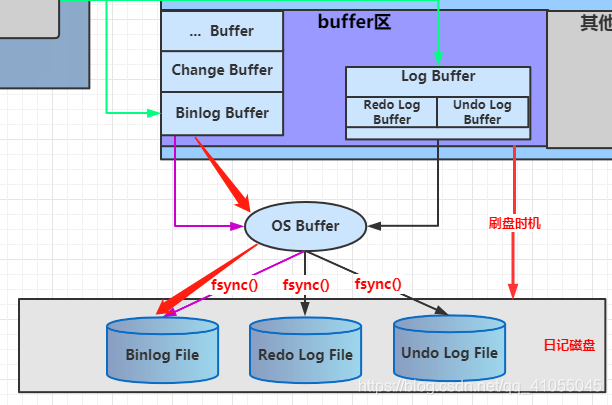
Binlog何時記錄將在第六點進行介紹,大致記錄程序是先寫Binlog Buffer,然后通過刷盤時機,控制刷入OS Buffer,控制fsync()進行寫入Binlog File日記磁盤的程序,

對于Binlog,MySQL是通過引數sync_binlog引數來控制刷盤時機,取值是0、1和N三種值,0表示由系統自行判斷何時呼叫sync()寫入磁盤;1表示每次事務commit都要呼叫fsync()寫入磁盤;N表示每N個事務,才會呼叫fsync()寫入磁盤,
4.4 Binlog 記錄格式
MySQL5.7.7版本之前默認格式是STATEMENT,版本之后默認是ROW,可以通過引數 binlog-format指定,
| STATMENT | 基于SQL陳述句復制,每一條修改資料的sql陳述句都會被記錄到Binlog中, 優點:不需要記錄每一行的變化,記錄Binlog日記量減少, 缺點:在某種情況下會導致主從資料不一致,比如執行sysdate()、slepp()等,具體可以自己去深入了解, |
| ROW | 推薦使用,MySQL高版本的默認值,基于行的復制,不記錄每條sql資訊,僅僅記錄哪行資料被修改了, 優點:沒有STATMENT模式中所說的主從資料不一致情況, 缺點:記錄行,需要更多的空間,會產生大量的日記, |
| MIXED | 上面兩種模式的混合,一般情況采用STATMENT模式保存Binlog,特殊情況采用ROW模式保存Binlog, |
五、認識事務日記(Undo log)
5.1 Undo log 概念
Undo log是邏輯日記、回滾日記,比如一條修改+3的邏輯陳述句,Undo log會記錄對應一條-3的邏輯日記,一條插入陳述句則會記錄一條洗掉陳述句,這樣發生錯誤時,根據執行Undo log就可以回滾到事務之前的資料狀態,
5.2 Undo log 作用
- 回滾資料:當程式發生例外錯誤時等,根據執行Undo log就可以回滾到事務之前的資料狀態,保證原子性,要么成功要么失敗,
- MVCC一致性視圖:通過Undo log找到對應的資料版本號,是保證MVCC視圖的一致性的必要條件,
5.3 Undo log 記錄程序及刷盤時機
刷盤程序及時機類似于Binlog和Redo,可以參考Redo log刷盤時機章節給出的圖片,已經體現出來了,
5.4 Undo log 總結
Undo log日記內容不是很多,重點是回滾和多版本控制MVCC那塊,此外,我記得印象筆記深刻的是長事務會導致日記過多,這個日記就是Undo log,因為長事務存在,導致需要保存很多視圖快照,其實這里就是設及到Undo log何時洗掉和生成的問題,當時糾結好久,其實很簡單,生成是事務開始后寫Redo log之前生成,當沒有事務需要用到Undo log時就會被洗掉,舉個例子,如果事務A一直存活,那么事務A之后產生的事務B、C...等等就算提交了,也不會被洗掉,因為事務A需要用到B、C...事務去找A的版本,所以避免長事務可以減少Undo log日記量,當然還可以提高性能,
六、認識事務日記 (Redo log)
6.1 Redo log 概念
Redo log 是重做日記,屬于InnoDB引擎的日記,是物理日記,日記記錄的內容的是資料頁的更改,這個頁 “做了什么改動”,如:add xx記錄 to Page1,向資料頁Page1增加一個記錄,

6.2 Redo log 作用
- 前滾操作:具備crash-safe能力,提供斷電重啟時解決事務丟失資料問題,
- 提高性能:先寫Redo log記錄更新,當等到有空閑執行緒、記憶體不足、Redo log滿了時 “刷臟”,寫Redo log是順序寫入,刷臟是隨機寫,節省的是隨機寫磁盤的 IO 消耗(轉成順序寫),所以性能得到提升,此技術稱為WAL技術:Write-Ahead Logging,它的關鍵點就是先寫日記磁盤,再寫資料磁盤,
6.3 Redo log 的兩階段提交
更新記憶體后引擎層寫Redo log將狀態改成prepare為預提交第一階段,Server層寫Binlog,將狀態改成commit為提交第二階段,兩階段提交可以確保Binlog和Redo log資料一致性,
6.4 Redo log 容災恢復程序
MySQL的處理程序如下
- 判斷redo log是否完整,如果判斷是完整(commit)的,直接用Redo log恢復
- 如果redo log只是預提交prepare但不是commit狀態,這個時候就會去判斷binlog是否完整,如果完整就提交Redo log,用Redo log恢復,不完整就回滾事務,丟棄資料,
只有在redo log狀態為prepare時,才會去檢查binlog是否存在,否則只校驗redo log是否是 commit就可以啦, 怎么檢查binlog:一個完整事物binlog結尾有固定的格式,
6.5 Redo log 刷盤時機
Undo log的刷盤時機和Redo log差不多,但是對于Undo log我沒找到對應的刷盤引數設計,所以不在提,Redo log每次先寫入Redo Log Buffer中,然后通過刷盤時機控制刷入OS Buffer時間和刷入日記磁盤的時間,

在Undo Log中,MySQL是通過引數innodb_flush_log_at_trx_commit來控制刷盤時機,取值是0、1和2三種值,0表示事務提交后,每秒寫入OS Buffer并呼叫fsync()寫入日記磁盤中;1表示每次事務提交會寫入OS Buffer并呼叫fsync()將日記寫入日記磁盤中,2表示事務每次提交寫入到OS Buffer,每秒呼叫fsync()寫入日記磁盤,可見引數為1是最安全的,同時也是默認值,

6.6 Redo log 存盤方式

上圖是日記磁盤的Redo log環形設計圖(從頭寫,寫到結束又從頭開始寫~回圈),write pos和check point是兩個指標,write pos指標指向當前日記檔案寫入的位置,check point指標指向當前要擦除的開始位置,圖中綠色部分是可以寫入Redo log地方,每次寫入,write pos指標會順時針推進,當然基本不會與check point指標重合,因為MySQL有這種機制去實作,每次觸發檢查點checkpoint,check point會指標向前推進,這個程序就是需要進行刷日記和資料磁盤,記錄相應的LSN,引出難點LSN,
6.7 Redo Log 檢查點
啥時候會觸發檢查點checkpoint,網上找了點資料:啥時候資料庫會觸發檢查點checkpoint

Checkpoint發生的時間、條件及臟頁的選擇等都非常復雜,而Checkpoint所做的事情無外乎是將緩沖池中的臟頁刷回到磁盤,不同之處在于每次重繪多少頁到磁盤,每次從哪里取臟頁,以及什么時間觸發Checkpoint,這些本文不會去研究,
6.8 Redo Log LSN
LSN這個概念,比較復雜,我介紹完你們不一定懂!LSN稱為日志的邏輯序列號(log sequence number),在innodb存盤引擎中,lsn占用8個位元組,LSN的值會隨著日志的寫入而逐漸增大,可以簡單理解SLN就是記錄從開始到現在已經產生了多少位元組的Redo log值,
存盤方式兩個指標又是通過LSN計算得到指向位置,因為LSN記錄的是檔案的大小位元組,當超過檔案大小時,需要用取模計算出這兩個指標位置,取模使得寫入就會從頭開始寫,這樣使得兩個指標在一個檔案中,一直落在回圈位置,你追我趕的程序,這就是Redo log 環形邏輯思想設計實作,
上面提到LSN比較復雜,是因為它有很多個值,輸入命令"show engine innodb status;",可以看到四個的lsn記錄

為了方便識別,我都為它們重新命名,如下,名詞記不住,后面無法繼續深入
1、記憶體日記:redo log buffer lsn;磁盤日記:redo log file lsn;
一般關系為:redo log buffer lsn >= redo log file lsn,如果刷盤時機為1,則redo log buffer lsn = redo log file lsn,
2、記憶體資料頁:data buffer lsn;資料磁盤資料頁:data disk lsn;
一般關系為data buffer lsn > data disk lsn,如果已經刷入資料磁盤,則data buffer lsn = data disk lsn,
3、檢查點:chckpoint lsn;
后面提到檢查點刷盤,資料刷盤和日記刷盤(如果有日記刷盤:則說明我假設的日記刷盤的時機設定值不為1,為1是同步的,即始終redo log buffer lsn = redo log file lsn,不會由檢查點觸發刷日記磁盤),
都說Redo log是環形記錄,那么怎么記錄的?下面結合LSN給出記錄程序虛構圖,可以對比6.6 Redo log 存盤方式圖
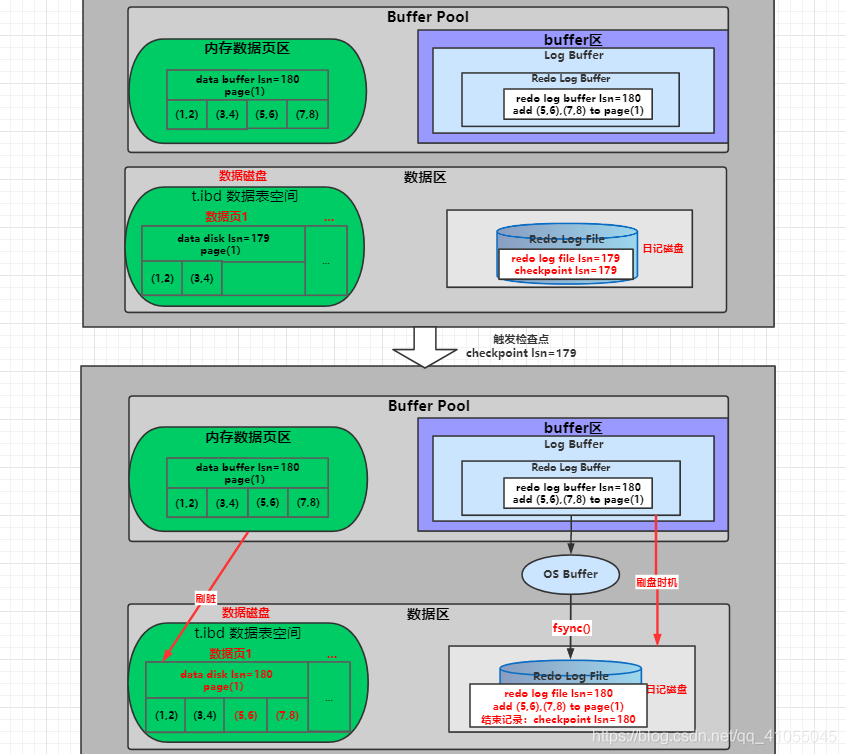
相關知識:日記磁盤 + redo log file lsn + checkpoint lsn + 雙指標(write pos、check point)
1-8按時間順序發生,1點是假設最初的狀態;2、3點寫日記磁盤;4點是觸發了檢查點checkpoint,進行刷盤,checkpoint lsn=1開始,刷盤結束并更新checkpoint lsn=512,在5點、6點已經刷過了一回圈記憶體、二回圈記憶體,從頭開始寫入log,兩個指標指向回到了頭部,第7點也是一個觸發checkpoint的程序,9點是假設沒有更新,最后達到平衡的結果,即記憶體中資料頁和日記都完成了刷盤,

整個流程:
在某些情況下,觸發checkpoint,觸發資料頁和日志頁刷盤,此時將記憶體中的臟資料---"資料臟頁"和"日志臟資料" 分別刷到資料磁盤和日記磁盤中,而且兩者刷盤速度不一樣,checkpoint會保護機制,當資料刷盤速度超過日志刷盤時,將會暫時停止資料刷盤,等待日志刷盤進度超過資料刷盤,
刷盤時,對于資料磁盤,全部都是在記憶體中,此時每次刷一個資料頁到記憶體更新資料頁也更新了data disk lsn為data buffer lsn(在更新記憶體資料頁時,會更新data buffer lsn),
對于日記磁盤,除了要記錄checkpoint lsn的值為檢查點 checkpoint的值(必須在結束時 直接記錄一個值,速度很快),這里是針對日記刷盤時機不是1(1是同步快取刷日記刷盤)時,并且日記還沒刷到日記磁盤需要觸發將快取中日記提前刷到日記磁盤中,此時會將redo buffer log刷到redo log file中也更新了redo log file lsn為redo log buffer lsn ,
模擬檢查點觸發前后,整個流程變化,一個資料頁和日記,資料變化及lsn從179-180的變化圖(刷盤時機不為1)
6.9 Redo log 容災恢復程序與LSN
結合6.4 Redo log 容災恢復程序和6.8的LSN知識,再次細化6.4的Redo log恢復程序
重啟innodb時,Redo log完不完整,采用6.4知識程序,用Redo log恢復,啟動資料庫時,InnoDB會掃描資料磁盤的資料頁data disk lsn和日志磁盤中的checkpoint lsn,兩者相等則從checkpoint lsn點開始恢復,恢復程序是利用 redo log到buffer pool,直到checkpoint lsn等于redo log file lsn,則恢復完成,
如果checkpoint lsn 小于 data disk lsn,說明在檢查點觸發后還沒結束刷盤時資料庫宕機了,因為checkpoint lsn最新值是在資料刷盤結束后才記錄的,檢查點之后有一部分資料已經刷入資料磁盤,這個時候資料磁盤已經寫入部分的部分恢復將不會重做,直接跳到沒有恢復的lsn值開始恢復,
七、了解 ChangeBuffer
7.1 為啥提到ChangeBuffer
為啥本文我會提到ChangeBuffer呢,其實很多時候會將ChangeBuffer和Redo log搞混,兩者都是巧用記憶體,減少磁盤IO,為了不弄混我覺得有必要專門對這個進行一個講解,
7.2 ChangeBuffer概念及作用
下面是我對ChangeBuffer的簡單介紹

也就是說對于更新的操作,如果用到了ChangeBuffer,更新的資料所在的資料頁如果不在記憶體中,將不用去資料磁盤將資料頁讀到記憶體,而是將這一次操作記錄在ChangeBuffer中,ChangeBuffer 主要節省的則是隨機讀磁盤的 IO 消耗,下次讀取查詢等讀取資料頁時用上ChangeBuffer中的記錄即可,其實也是一種巧用記憶體的思想,
7.3 ChangeBuffer與Redo log區別
Redo log 主要節省的是隨機寫磁盤的 IO 消耗(轉成順序寫),而 ChangeBuffer 主要節省的則是隨機讀磁盤的 IO 消耗,
這句話怎么理解,看下面:
Redo log 與 ChangeBuffer(含磁盤持久化) 這2個機制,不同之處在于優化了整個變更流程的不同階段,
先不考慮Redo log、ChangeBuffer機制,簡化抽象一個更新(insert、update、delete)流程:
- 從磁盤讀取待變更的行所在的資料頁,讀入記憶體頁中
- 對記憶體頁中的行,執行變更操作
- 將變更后的資料頁,寫入至資料磁盤中
其中,流程中的步驟1涉及隨機讀磁盤IO;步驟3涉及隨機寫磁盤IO;剛好對應ChangeBuffer和Redo log,
對那句話的理解答案:
- ChangeBuffer機制,優化了步驟1——避免了隨機讀磁盤IO ,將不在記憶體中的資料頁的操作寫入ChangeBuffer中,而不是將資料頁從磁盤讀入記憶體頁中
- Redo log機制, 優化了步驟3——避免了隨機寫磁盤IO,將隨機寫磁盤,優化為了順序寫磁盤(寫Redo log,確保crash-safe)
7.4 有沒有用到ChangeBuffer對于Redo log的區別
Redo log機制,為了保證crash-safe,一直都會用到, 有無用到ChangeBuffer機制,對于redo log這步的區別在于—— 用到了ChangeBuffer機制時,在Redo log中記錄的本次變更,是記錄new change buffer item相關的資訊,而不是直接的記錄物理頁的變更(文章中第八節都有體現這一程序), 在我們mysql innodb中, ChangeBuffer機制不是一直會被應用到,僅當待操作的資料頁當前不在記憶體中,需要先讀磁盤加載資料頁時,ChangeBuffer才有用武之地,
7.5 ChangeBuffer的merge程序

除了訪問這個資料頁會觸發 merge 外,系統有后臺執行緒會定期 merge,在資料庫正常關閉(shutdown)的程序中,也會執行 merge 操作,
merge程序做三步
- 從磁盤讀入資料頁到記憶體(老版本的資料頁);
- 從 change buffer 里找出這個資料頁的 change buffer 記錄 (可能有多個),依次應用,得到新版資料頁;
- 寫 redo log,這個 redo log 包含了資料的變更和 change buffer 的變更,
八、日記大連貫U-R-B,一舉攻破拿下
前面分別講的是Binlog、Undo log和Redo log,下面將他們都串聯起來,在一些流程體現全部日記,
同樣,以一些最經典的更新陳述句例子展開說明,
8.1 制造演示資料
測驗陳述句:插入陳述句+查詢陳述句,a欄位是普通索引
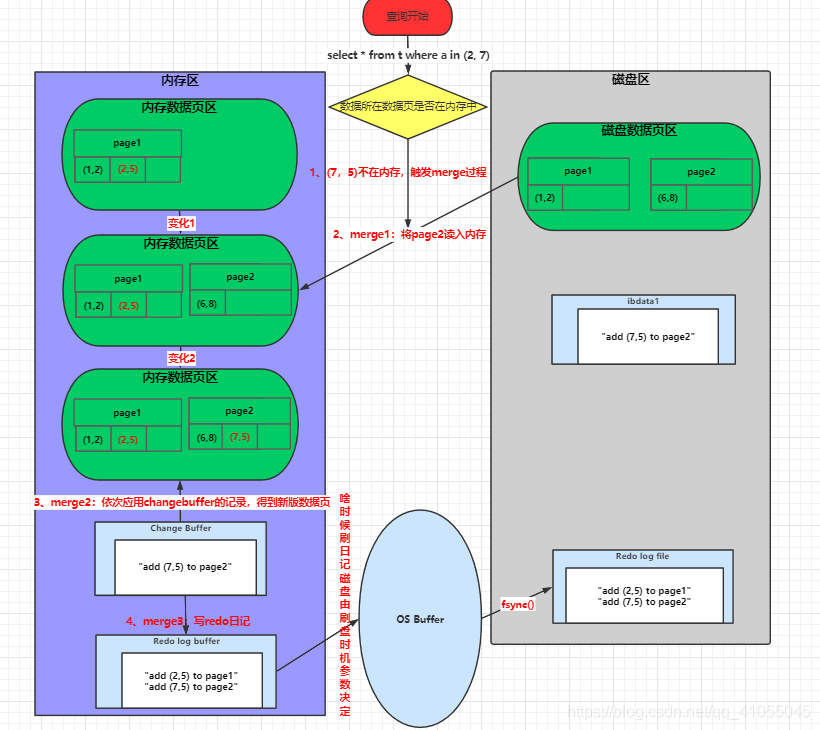
1、insert into ta(a,b) values(2,5),(7, 5)
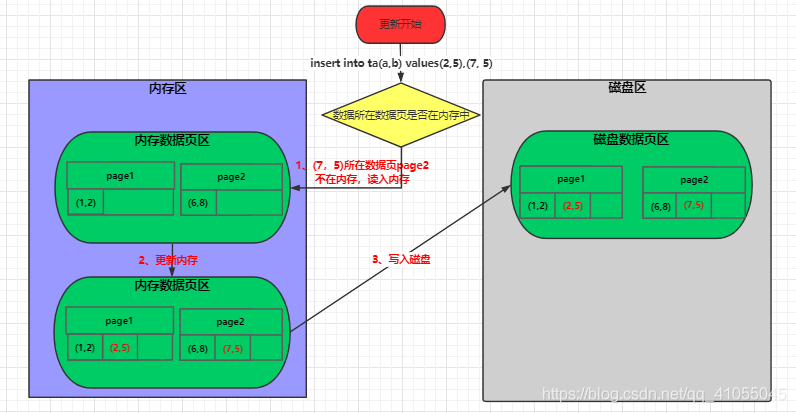
2、select * from t where a in (2, 7)假設原來的資料如下圖,資料頁page1在記憶體中,page2不在,插入的資料(2,5)落在page1,資料(7,5)落在page2中,

8.2 假設沒有日記和ChangeBuffer 示范
先不考慮所有日記及ChangeBuffer機制,簡化抽象一個更新insert流程
- 從磁盤讀取待變更的行所在的資料頁,讀入記憶體頁中
- 對記憶體頁中的行,執行變更操作
- 將變更后的資料頁,寫入至資料磁盤中
8.3 考慮所有日記和ChangeBuffer 示范--現有Innodb流程
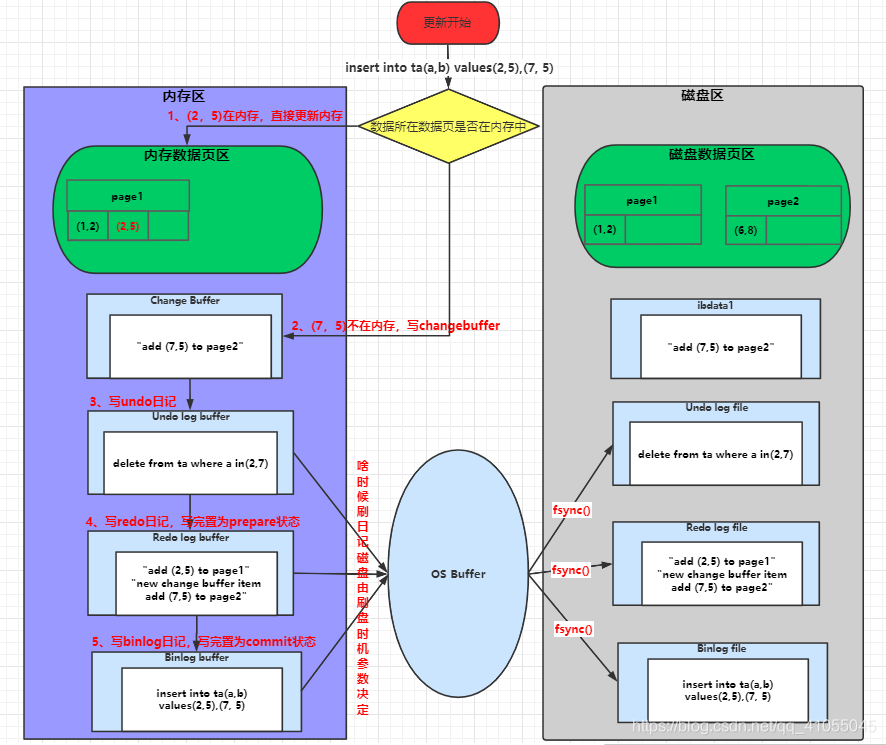
程序是 兩階段提交-----日記刷盤------資料刷盤(涉及Redo log lsn 和 ChangeBuffer的內容)
8.3.1 兩階段提交程序
- 資料(2,5)所在頁page1在記憶體中直接更新記憶體;資料(7,5)所在頁page2不在記憶體中,記錄change buffer(具有唯一性的索引或者沒有使用change buffer的操作是將磁盤中的資料頁讀入記憶體中并做更新),
- 寫undo日記,先寫快取,后面根據刷盤引數決定何時刷入磁盤,后面的redo/Binlog都一樣,日記刷盤 在每一個日記中基本已經提到,它和設定的引數有關,具體刷盤可以參考上文4.3和6.5章節,下文不會再展開介紹,
- 寫redo日記(先記在記憶體中的更新,然后記不在記憶體中的change buffer的改變)
- 日記狀態改成prepare階段,
- 寫Binlog日記,
- 提交事務,日記狀態改成commit階段,
8.3.2 merge 程序
緊接著上文,圖片可上下參考,假設現在執行查詢陳述句 “select * from t where a in (2, 7)” ,此次查詢索引a=7所在的資料頁不在記憶體中,并且上一步更新已經在change buffer中有記錄,將會觸發merge程序(參考第七章節7.5),
- 將page2讀入記憶體
- 依次應用change buffer中的記錄,得到最新版資料頁
- 寫入redo,之前記錄的changebuffer改動,現在改成資料頁的改動
至于changebuffer被應用后是洗掉還是標記,還有redo中原有的記錄changebuffer的改動怎么調整是洗掉還是修改成資料頁的改動這里下面的圖是按照自己的想法描述出來,如有誤望留言指正,
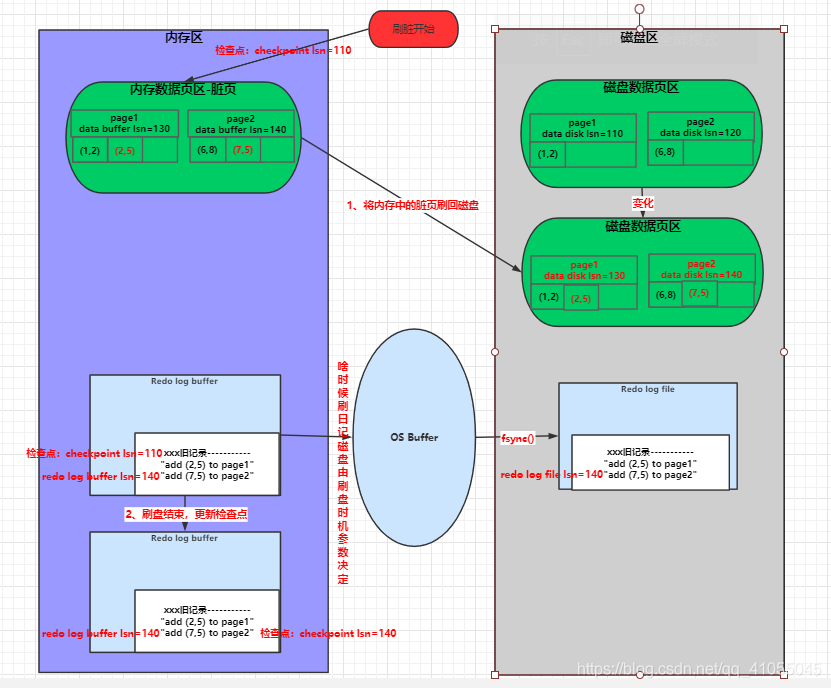
8.3.3 資料刷盤程序
資料刷盤flush的有四種情況
- InnoDB 的 redo log 寫滿了,這時候系統會停止所有更新操作,把 checkpoint 往前推進,redo log 留出空間可以繼續寫
- 系統記憶體不足,當需要新的記憶體頁,而記憶體不夠用的時候,就要淘汰一些資料頁,空出記憶體給別的資料頁使用,如果淘汰的是“臟頁”,就要先將臟頁寫到磁盤
- MySQL 認為系統“空閑”的時候
- MySQL 正常關閉的情況
資料刷盤也代表著Redo log檢查點checkpoint觸發,這一步將聯系到第六章6.7和6.8中的章節內容,較為復雜,
假設資料刷盤flush的四種情況發生了一種,那么聯系上文的程序將如下
- 將臟頁從記憶體中刷回到資料磁盤
- 刷完后更新檢查點checkpoint的值
流程中間某個環節資料庫宕機后,恢復具體程序,這些留在心里了,沒往上去寫,讀者可以自行思考,不難,
九、結尾
整個文章講了Binlog、Undo log和Redo log,隨帶一提ChangeBuffer,前面四五六七章是分講,最后第八章是對整個日記相關聯講解,對此,講到這里,基本上要把我要將的已經講完,內容挺多,有耐心可以慢慢啃,不懂歡迎留言!
思考環節,下面留下兩個問題,歡迎大家留言解答
1、為啥Binlog沒有crash-safe功能?
2、保證crash-safe為啥要用兩個日記,不能用一個日記嗎(Redo log或Binglog)?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/170137.html
標籤:其他