SQL優化之多表聯合查詢干掉“distinct”去重關鍵字
- 一、優化目的
- 二、優化之前的sql長這樣
- 三、DISTINCT關鍵字的用法
- 四、談:如何優化distinct的sql
- 五、distinct真的和group by等價嗎?
- 六、優化后的sql長啥樣?
- 七、總結
一、優化目的
在我提交了代碼的時候,架構師給我指出我這個sql這樣寫會有問題,因為在分庫分表的時候,是不支持子查詢的,所以需要把多表的子查詢的sql結構進行優化,
二、優化之前的sql長這樣
是不是挺恐怖的;(此處為了脫敏,我把相關的sql關鍵詞都給打碼掉了)
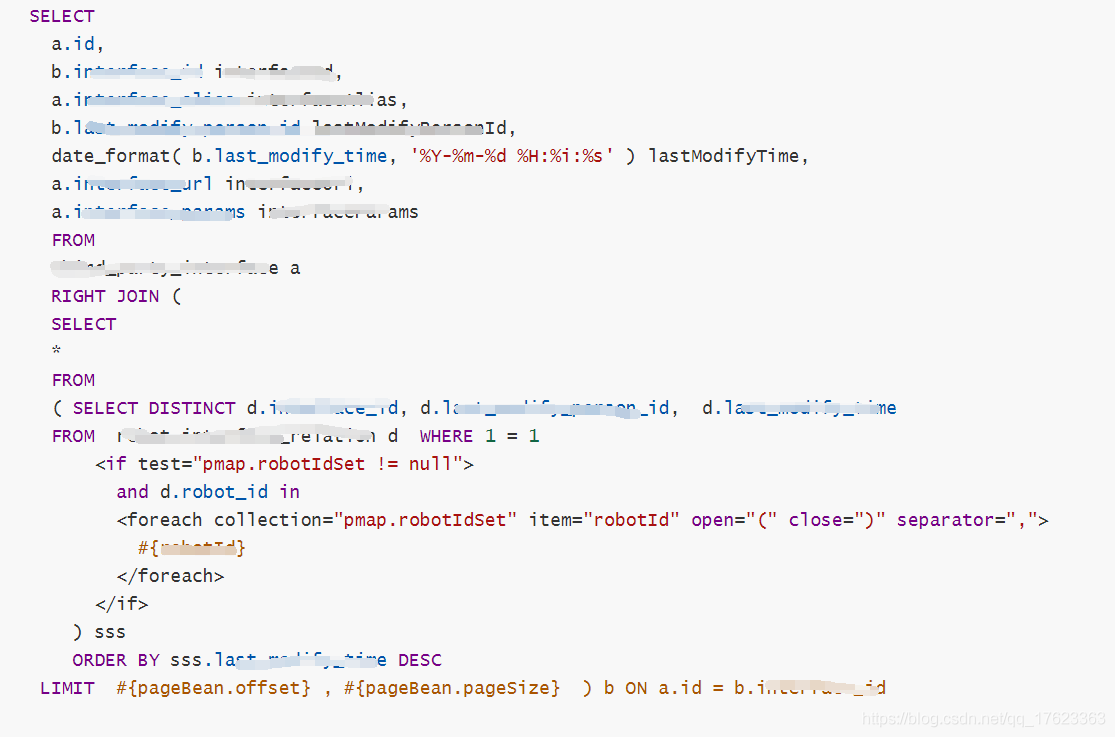
這個sql的執行步驟如下:
1、查詢出來d表中的某個id欄位包含多個id值的所有的資料(因為此表是1-n的關系,所以需要去重,僅需要拿到不重復的id才可以繼續下一個步驟);可以看到此步驟我把查詢出來的多個值的結果給生成的了一個子表名為sss;
2、下一個步驟就是需要進行排序(以時間進行倒序排序,因為要在前臺進行按時間進行展示);
3、第3步就是把這些結果與a表進行合并,查詢出來排序后的每個id的資訊;然后進行分頁處理;
其他的可以不必關心,最終要的是去重關鍵字(DISTINCT),拿小本本記號,一會要考哦,
三、DISTINCT關鍵字的用法
實踐是驗證真理的唯一標準
例如有下表:
可以看到
name和product_unit列的值都有可能是重復的,
mysql> SELECT t1.id,t1.name,t1.product_unit FROM dd_product_category t1;
+----+----------+--------------+
| id | name | product_unit |
+----+----------+--------------+
| 55 | 飲料 | 瓶 |
| 56 | 飲料 | 箱 |
| 57 | 零食 | 包 |
| 59 | 膨化食品 | 袋 |
| 60 | 方便食品 | 箱 |
| 61 | 自熱火鍋 | 碗 |
| 62 | 方便面 | 箱 |
| 63 | 礦泉水 | 箱 |
| 64 | 糖果 | |
| 65 | 酒類 | 箱 |
| 66 | 烈酒 | 箱 |
| 67 | 啤酒 | 箱 |
| 68 | 預調酒 | 箱 |
+----+----------+--------------+
13 rows in set (0.13 sec)
mysql>
mysql>
如何我們想只拿到name或者product_unit列的值并且不想要重復的值該怎么辦?
1、拿到單個值是好拿的,但是是存在重復的資料的,這些重復的資料我們只保留一個就可以了,那么該怎么做呢?
mysql> SELECT t1.product_unit FROM dd_product_category t1;
+--------------+
| product_unit |
+--------------+
| 瓶 |
| 箱 |
| 包 |
| 袋 |
| 箱 |
| 碗 |
| 箱 |
| 箱 |
| |
| 箱 |
| 箱 |
| 箱 |
| 箱 |
+--------------+
13 rows in set (19.31 sec)
mysql>
2、去除重復列
mysql>
mysql> SELECT DISTINCT t1.product_unit FROM dd_product_category t1;
+--------------+
| product_unit |
+--------------+
| 瓶 |
| 箱 |
| 包 |
| 袋 |
| 碗 |
| |
+--------------+
6 rows in set (0.11 sec)
mysql>
是不是很簡單,雖然看著簡單,但是如果多表子查詢的時候,就會出現問題,例如你想要查詢表a,b,c三個表的資料,這三個表必然都是有關系的,
a和b是1-n的關系,但是你只有b表中id,你需要先查詢出來b表的資料,然后利用b表的資料去查詢a表的資料,然后再去查詢c表的資料,
想必肯定是很繞的,
整個程序中你肯定是需要去重的
當整個sql寫完,基本上跟我寫的優化前的sql也就差不多了,(多表嵌套,多sql嵌套sql,啦啦啦一大堆),
優化思路還是有很多的,當時能想到的就是把這個復雜的sql拆分成多個簡單的sql執行,然后使用Java后臺代碼進行處理,(對于不甘于現狀的我,想找到一個比這個更友好的解決方案的我,我是不會屈服這個問題的,)
四、談:如何優化distinct的sql
說到這里,先給大家放上一個鏈接:
-
1、(Mysql5.7官方手冊中提及到的關于優化distinct的方法)
https://dev.mysql.com/doc/refman/5.7/en/distinct-optimization.html -
2、還有一個優化group by的:
https://dev.mysql.com/doc/refman/5.7/en/group-by-optimization.html
推薦大家閱讀,
Mysql5.7官方手冊中提及到的關于優化distinct的方法,原文如下:
MySQL 5.7 Reference Manual / … / DISTINCT Optimization
8.2.1.16 DISTINCT Optimization
DISTINCT combined with ORDER BY needs a temporary table in many cases.
distinct 與order by 結合的許多情況下需要建一個臨時表;
Because DISTINCT may use GROUP BY, learn how MySQL works with columns in ORDER BY or HAVING clauses that are not part of the selected columns. See Section 12.20.3, “MySQL Handling of GROUP BY”.
因為distinct可能使用group by,了解MySQL如何處理按order by 列或者具有不屬于所選列的子句,見12.20.3節, “MySQL Handling of GROUP BY”.
In most cases, a DISTINCT clause can be considered as a special case of GROUP BY. For example, the following two queries are equivalent:
在大多數情況下,一個不同的子句可以被認為是group by 的特殊情況,例如下面這兩個查詢是等價的:
SELECT DISTINCT c1, c2, c3 FROM t1
WHERE c1 > const;
SELECT c1, c2, c3 FROM t1
WHERE c1 > const GROUP BY c1, c2, c3;
Due to this equivalence, the optimizations applicable to GROUP BY queries can be also applied to queries with a DISTINCT clause. Thus, for more details on the optimization possibilities for DISTINCT queries, see Section 8.2.1.15, “GROUP BY Optimization”.
由于這種等價性,適用于group by查詢的優化,也可以應用于具有不同子句的查詢,因此,關于distinct的查詢優化的更多細節可以參考Section 8.2.1.15, “GROUP BY Optimization”.
When combining LIMIT row_count with DISTINCT, MySQL stops as soon as it finds row_count unique rows.
當row_count與distinct一起使用時,MySQL一旦發現row_count是唯一的行,就會停止,
If you do not use columns from all tables named in a query, MySQL stops scanning any unused tables as soon as it finds the first match. In the following case, assuming that t1 is used before t2 (which you can check with EXPLAIN), MySQL stops reading from t2 (for any particular row in t1) when it finds the first row in t2:
如果在查詢中不適用來自所有表的列,MySQL一旦找到第一個匹配項就會停止掃描任何未使用的表,
在下面的例子中,假設t1在t2之前使用(你可以使用explanin來檢查),MySQL在找到t2的第一行時停止從t2讀取(對于t1中的任何特定行),
SELECT DISTINCT t1.a FROM t1, t2 where t1.a=t2.a;
官方的手冊中寫到的,真是句句扣心呀!!!
總結有以下比較重要的幾點:
- 1、distinct與group by幾乎等價;
- 2、distinct的相關優化與group by的查詢優化方法是等價的;
五、distinct真的和group by等價嗎?
我們抱著試試看的態度,去做個試驗,
就以下列這個效果為最終目的好了:
mysql>
mysql> SELECT DISTINCT t1.product_unit FROM dd_product_category t1;
+--------------+
| product_unit |
+--------------+
| 瓶 |
| 箱 |
| 包 |
| 袋 |
| 碗 |
| |
+--------------+
6 rows in set (0.11 sec)
mysql>
使用group by去重:
mysql> select t1.product_unit from dd_product_category t1 group by t1.product_unit;
+--------------+
| product_unit |
+--------------+
| |
| 包 |
| 瓶 |
| 碗 |
| 箱 |
| 袋 |
+--------------+
6 rows in set (19.46 sec)
mysql>
可以看到,最終拿到的資料是一模一樣的,
那么我們試驗是成功的,distinct的效果和group by的效果是一樣的,
那么我們優化distinct就變向的去優化group by了(我優化前的sql并未使用group by所以談不上優化group by,只能說是把distinct的復雜sql改造成group by 的sql),
打開我前面提到的這個優化group by的官方手冊:
https://dev.mysql.com/doc/refman/5.7/en/group-by-optimization.html
由于原文比較長,這里就不在過多贅述,
現在需要做的就是把distinct改造成group by的sql語法的寫法,
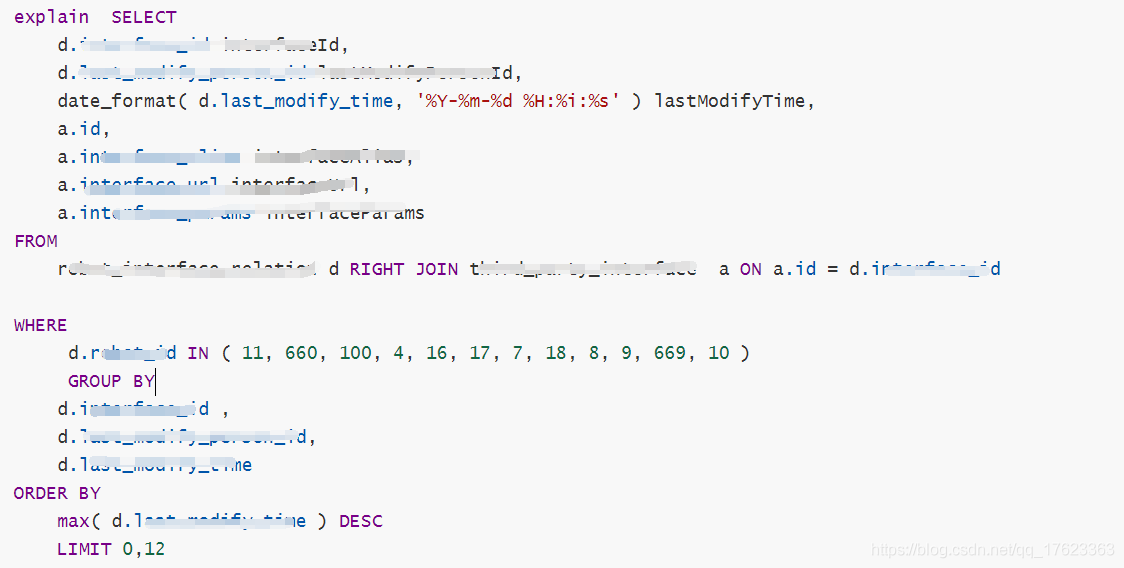
六、優化后的sql長啥樣?
怎么樣,改造后的sql,是不是還挺清爽的,
1、我們扔掉了多個嵌套sql;
2、也不用去生成一個sss的臨時表了
七、總結
對于本人而言學到了:
- 1、distinct與group by幾乎等價;
- 2、distinct的相關優化與group by的查詢優化方法是等價的;
- 3、如果distinct的不能讓sql最優化,那么可以嘗試著使用group by的方式去改造一下,
這些我都上傳到了百度云,
為了防止鏈接丟失可以關注公眾號,回復:"mysql",即可拿到MySQL相關的全部精彩內容,
歡迎一起學習,一起交流,一起進步,
關注我微信公眾號第一時間推送給你精彩內容哦:
回復選單,更有好禮,驚喜在等著你,

快來我粉絲群:每天歡快的玩耍(微信掃描二維碼即可加入,群馬上滿,抓緊啦!!!)


 CSDN認證博客專家
Linux
分布式
Java
CSDN認證博客專家
Linux
分布式
Java
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/170143.html
標籤:其他