SQL相關指令整理
- 1 表
- 1.1 資料型別
- 數值型
- 字串型
- 日期時間型別
- 1.2表的創建
- 1.3 表的洗掉
- 1.4 表的修改
- 2 資料的處理
- 2.1 插入資料
- 2.2 更新記錄
- 2.3 洗掉記錄
- 3 其他指令語言
- 3.1 SELECT
- 3.2 WHERE
- 3.3 AS
- 3.4 ORDER BY
- 3.5 GROUP BY
- 3.6 HAVING
- 4 多表操作
- 4.1 多表的JOIN連接
- 4.2 自連接
- 4.3 UNION
SQL是用于資料庫查詢,刪改等的一種語言,方便對資料庫進行操作,本文主要講述MySQL下的SQL相關指令, 每一行指令結束記得寫分號;
DDL—資料定義語言(CREATE,ALTER,DROP,DECLARE)
DML—資料操縱語言(SELECT,DELETE,UPDATE,INSERT)
DCL—資料控制語言(GRANT,REVOKE,COMMIT,ROLLBACK)
1 表
資料庫管理著表以及表和表之間的關系,表中存盤著資料,我們絕大多數的操作也都是針對于表,
資料表由行(row)和列(column)組成,是一個二維的網格結構,每個列都是一個欄位,每一行是一個記錄,欄位由欄位名稱和欄位的資料型別以及一些約束條件組成,
常見的約束條件:
NOT NULL:該欄位的值不能為空
PRIMARY KEY: 主鍵,有唯一約束,不能為空,
FOREIGN KEY:外鍵,資料表2中索引資料表1中主鍵的鍵
NOT NULL: 非空約束
UNIQUE : 唯一約束
DEFAULT :如果插入資料時沒有給該欄位賦值,則使用默認值
1.1 資料型別
常見的資料型別有數值型,字串型別和日期時間型別:
數值型
- 整數型
- TINYINT 非常小的整數
- SMALLINT 小整數
- MEDIUMINT 中等大小的整數
- INT 正常大小的整數
- BIGINT 大整數 - 浮點型(近似值)
- FLOAT 一個小的(單精度)浮點數
- DOUBLE 正常大小(雙精度)浮點數 - 定點型(精確值)
- DECIMAL 定點數
字串型
- CHAR
- VARCHAR
CHAR(X)的長度確定,VARCHAR(X)的長度可變,當X=5時,對于CHAR若輸入一個字符,會用空格補齊 - BINARY
- VARBINARY
- BLOB
- TEXT
- ENUM
- SET
日期時間型別
- TIME
- DATE
- DATETIME
- TIMESTAMP
- YEAR
1.2表的創建
對于postgresSQL,創表的時候必須顯示定義主鍵,對于MySQL,當創建表時沒有顯示定義主鍵時,首先判斷表中是否有非空的整形唯一索引,如果有,則該列為主鍵(這時候可以使用 select _rowid from table 查詢到主鍵列);如果沒有符合條件的則會自動創建一個6位元組的主鍵(該主鍵是查不到的).
所以創表的時候還是應該顯示定義主鍵,
CREATE TABLE <table_name> (
column_name1 type1,
column_name2 type2,
...
column_nameN typeN
);
#例:
CREATE TABLE IF NOT EXISTS user(
id INT,
account VARCHAR(50) NOT NULL,
name VARCHAR(20) NOT NULL,
age INT,
gender ENUM('male','female','unknown') DEFAULT 'unknown',
PRIMARY KEY(id)#如果多個欄位組合成一個主鍵,用逗號隔開,
#也可以在定義id時直接寫成 id INT PRIMARY KEY
);
1.3 表的洗掉
DROP TABLE <table_name>;
);
#例
DROP TABLE user;
1.4 表的修改
使用ALTER TABLE,
1)加入column
ALTER TABLE <table_name>
ADD <definition_of_column>;
#例:
ALTER TABLE user
ADD married BINARY;
2)洗掉column
ALTER TABLE <table_name>
DROP COLUMN <column_name>;
#例:
ALTER TABLE user
DROP COLUMN married;
3)修改欄位型別
ALTER TABLE <table_name>
MODIFY COLUMN <definition_of_column>;
#例:
ALTER TABLE user
MODIFY COLUMN married VARCHAR(5);
2 資料的處理
2.1 插入資料
直接插入
未經賦值的欄位為NULL,當不指明要賦值的欄位串列時,自動依次對應錄入
INSERT INTO <table_name> (<要賦值的欄位的有序串列>) VALUES (
<要賦值的串列,逗號隔開>
);
#例:
INSERT INTO user (id,account,name,age,gender) VALUES (
1,"橘子鴨血粉絲湯","clemence",18,"male"
);
向表2中根據表1選出的內容進行插入
INSERT INTO <table_name> (<要賦值的欄位的有序串列>)
SELECT column1,..column2
FROM <table_name2>
(WHERE <限制條件>);
#例:
INSERT INTO user (id,account,name)
SELECT id,account
FROM user2
WHERE id=1;
2.2 更新記錄
UPDATE <table_name>
SET <column1=value1,..,columnN=valueN>
(WHERE <限制條件>);
#例:
UPDATE user
SET name='clementine'
WHERE id=1;
2.3 洗掉記錄
當僅有DELETE FROM時,洗掉所有column里的值,
DELETE FROM <table_name>
(WHERE <限制條件>);
#例:
DELETE FROM user
WHERE id=1;
3 其他指令語言
3.1 SELECT
想要洗掉重復項時,使用SELECT DISTINCT,
SELECT <name_of_columns>
FROM <table_name>
(WHERE <restriction>)
#---選擇所有欄位內資料---
SELECT *
FROM <table_name>
(WHERE <restriction>)
#例
SELECT id,name
FROM user
WHERE id=1
3.2 WHERE
以下的運算子可以在WHERE中使用:
| 運算子 | 描述 | 舉例 |
|---|---|---|
| = | 等于 | WHERE id=1 |
| <> | 不等于,注釋:在 SQL 的一些版本中,該運算子可被寫成 != | WHERE id<>1 |
| > | 大于 | WHERE id>1 |
| < | 小于 | WHERE id<1 |
| >= | 大于等于 | WHERE id>=1 |
| <= | 小于等于 | WHERE id<=1 |
| BETWEEN | 在某個范圍內 | WHERE id BETWEEN 1 AND 5 |
| IN | 某個列的多個可能值 | WHERE id IN (1,3,4) |
| LIKE | 模糊查詢搜索某種模式 | WHERE id LIKE ‘M%’ |
M 為要查詢內容中的模糊資訊:
- % 表示多個字值,_ 下劃線表示一個字符;
- M% : 正則運算式,查詢以 M 開頭的所有內容,
- %M% : 查詢只包含M的所有內容,
- %M_ : 查詢以M在倒數第二位的所有內容
多個查詢條件可以使用AND,OR來連接,
3.3 AS
重命名column,
SELECT <column1> AS <a1>, <column2> AS <a2>
FROM <table_name>
(WHERE <restriction>);
#例
SELECT id AS identifiant, account AS account_name
FROM user;
3.4 ORDER BY
對選擇出的記錄進行排序,DESC為從大到小排序,ASC為從小到大排序,默認為ASC,DESC 或者 ASC 只對它緊跟著的第一個列名有效,其他不受影響,仍然是默認的從小到達排序,
ORDER BY 多列的時候,先按照第一個column name排序,再對第一次排序好的各同屬部分分別按照第二個column name排序
SELECT <column1>, <column2>
FROM <table_name>
(WHERE <restriction>)
ORDER BY <column_names>;
#例
SELECT id, account, name
FROM user
ORDER BY id,name DESC #先按id從小到大排序,再按照name從大到小排序
#或
ORDER BY id DESC,name #先按id從大到小排序,再按照name從小到大排序
ORDER BY id DESC, name DESC 等價于 ORDER BY CONCAT(code,name) DESC #先按id從大到小排序,再按照name從大到小排序
3.5 GROUP BY
使用GROUP BY一定要遵循single value rule:
- 跟在SELECT后的column,要么出現在了GROUP BY后面, 要么在聚合函式里
- 如果GROUP BY的column是鍵,則SELECT后別的column可以不遵循上述原則(但最好不要這樣)
SELECT <column1,...,聚合函式(columnN)>
FROM <table_name>
(WHERE <restriction>)
GROUP BY <column1>
可以使用的聚合函式有:
- COUNT()
- AVG()
- SUM()
- MIN()
- MAX()
3.6 HAVING
用于篩選成組后的各種資料,可以在HAVING中使用聚合函式,但不能在WHERE中使用聚合函式,
SELECT <column1,...,聚合函式(columnN)>
FROM <table_name>
(WHERE <restriction>)
GROUP BY <column1>
HAVING <condition>
#例
SELECT Company.name,AVG(Person.age)
FROM Company, Person
WHERE Company.name=Person.ComName
GROUP BY Company.name
HAVING Company.type IN ('technologie','environment')
SQL中指令呼叫的順序為:
FROM->WHERE->GROUP BY->HAVING->SELECT->ORDER BY
4 多表操作
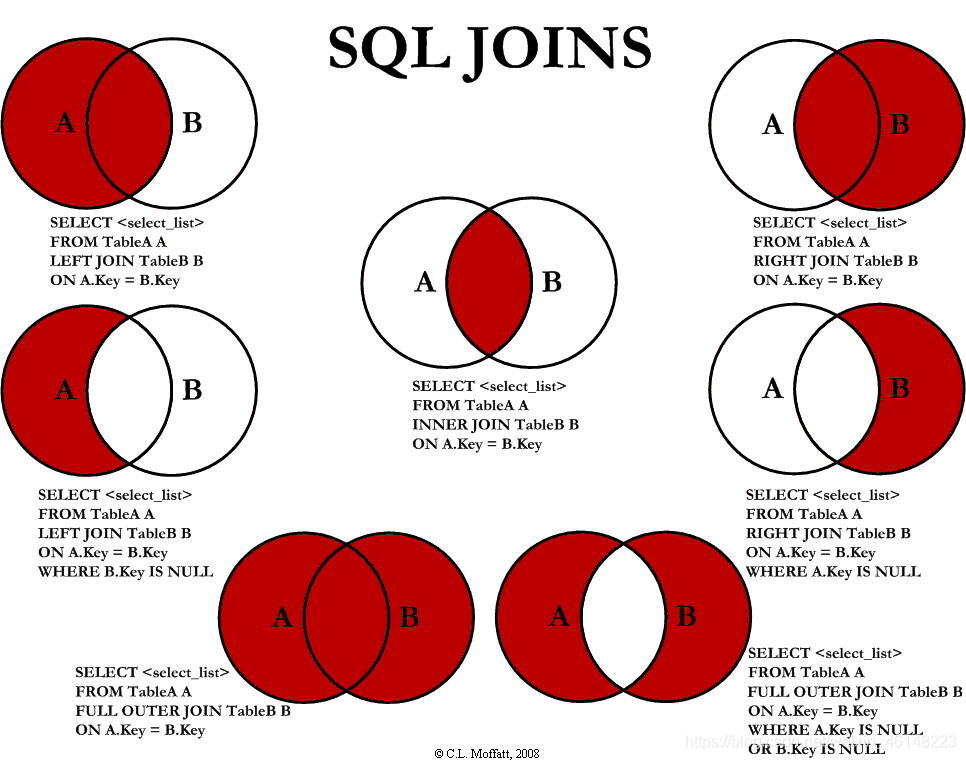
4.1 多表的JOIN連接
INNER JOIN 可以簡寫為JOIN,LEFT OUTR JOIN 可以簡寫為LEFT JOIN,RIGHT OUTER JOIN 可以簡寫為RIGHT JOIN,
SELECT *
FROM T1,T2
WHERE T1.C=T2.X;
#等價于
SELECT *
FROM T1 INNER JOIN T2
ON T1.C=T2.X;
4.2 自連接
SELECT *
FROM T T1, T T2
WHERE T1.X=T2.X;
4.3 UNION
UNION:R1和R2的被選出的columns的數量要一致,最后的結果會洗掉重復值,如果不想洗掉重復值可以使用UNION ALL
SELECT * FROM T1
UNION
SELECT * FROM T2
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/175882.html
標籤:其他