Python3正則運算式
- 前言
- 簡介
- 1.引入
- 2.正則運算式是什么
- 正則運算式語法
- 1.基礎知識-元字符
- 2.常用元字符
- 2.1匹配不定長的字符集
- 2.2指定重復次數的字符
- re模塊中常量
- re模塊中常用函式
- 1.字串匹配
- 1.1match( )
- 1.2search( )
- 1.3 findall( )
- 1.4 finditer( )
- 1.5小結
- 1.6目標串回傳
- 2.字串替換——re.sub
- 3.字串拆分——re.split()
- 正則運算式物件
- 1.compile()函式
- 2.字串匹配
- 2.字串替換
- 3.字串分割
- 4.小結
- 總結
前言
hello!這是我的第一篇博客,當然是是因為作業啊!在通過查閱檔案,閱讀別人所寫的博客,和最重要的當然是自己上手操作的程序中,我已經初步知道正則運算式的基本語法以及如何使用了,就來寫一篇學習筆記總結一下哦,作為初學者,錯誤難免有哦,歡迎指出來鴨,
簡介
1.引入
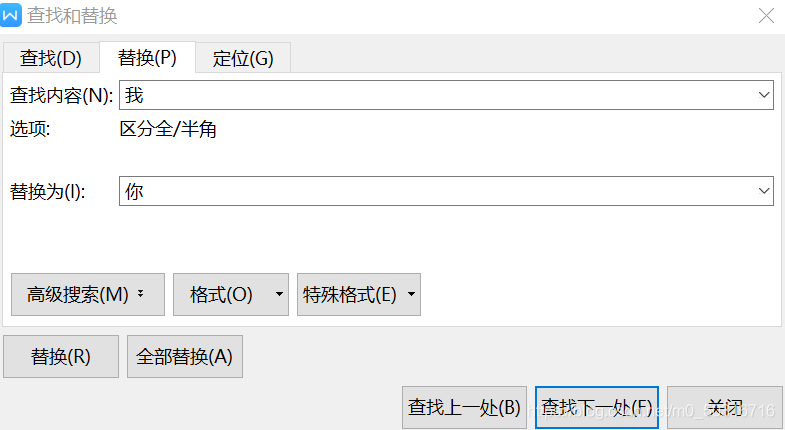
老師在引入正則運算式的時候,舉出了這樣一個例子:我們用world中寫好了一篇論文,可是發現某個字全篇都是錯誤的,這時候是要找到一個改一個嗎?肯定不是!查找替換功能輕松解決,
2.正則運算式是什么
這種查找替換的功能就類似于正則運算式,
正則運算式,實際上是一個字串,通過給定一個正則運算式和另一個字串,我們可以達到如下的目的:①. 給定的字串是否可以和正則運算式符合,②. 可以通過正則運算式,從字串中獲取我們想要的特定部分,
正則運算式是字串處理的有力工具,但是并不是Python獨有的,其他語言也有,
下面我們就開始從基本語法開始學習正則運算式
正則運算式語法
1.基礎知識-元字符
- 元字符
有一些字符比較特殊,它們和自身并不匹配,而是表明應和一些特殊的東西匹配,或者會影響重復次數,這些特殊的字符我們稱之為元字符, - 原始字串
在字串前面加上字母r或R表示原始字串,所有的字符都是原始的本義而不會進行任何轉義,這個功能的實作就很像正則運算式了
2.常用元字符
2.1匹配不定長的字符集
① “.”:
表示除換行符以外的任意字符,
與“.”類似(但不相同)的一個符號是“\S”,表示不是空白符的任意字符,
代碼如下(示例):
import re
s='hi,i am a student.my name is Tom'
print(re.findall(r'.',s))運行結果
['h', 'i', ',', 'i', ' ', 'a', 'm', ' ', 'a', ' ', 's', 't', 'u', 'd', 'e', 'n', 't', '.', 'm', 'y', ' ', 'n', 'a', 'm', 'e', ' ', 'i', 's', ' ', 'T', 'o', 'm']② " / "
反斜杠后面可以加不同的字符表示不同的特殊意義
“^”表示補集,匹配不在區間范圍內的字符,
例如:[^3]表示除3以外的字符,
| 字符 | 意義 |
|---|---|
| \b | 匹配單詞頭或單詞尾 |
| \B | 與\b相反,匹配非單詞頭或單詞尾 |
| \d | 匹配任何十進制數;相當于[0-9] |
| \D | \d相反,匹配任何非數字字符,相當于[^0-9] |
| \s | 匹配任何空白字符,相當于[\t\n\r\f\v] |
| \S | 與\s相反,匹配任何非空白字符,相當于[^\t\n\r\f\v] |
| \w | 匹配任何字母、數字或下畫線字符,相當于[a-zA-Z0-9_] |
| \W | 匹配任何非字母、數字和下畫線字符,相當于[^a-zA-Z0-9_] |
也可以用于取消所有的元字符:
這些特殊字符都可以包含在[]中.
③ “^”:
匹配行首,匹配以^后面的字符開頭的字串
代碼如下(示例):
import re
s='helloTom BabyhelloMary helo'
print(re.findall(r'hello',s))
運行結果
['hello', 'hello']④ “$”:
匹配行尾,匹配以它之前的字符結束的字串
代碼如下(示例):
s='helloTom BabyhelloMary helo'
print(re.findall(r'lo',s))運行結果
['lo', 'lo', 'lo']⑤ “[ ]”:
常用來指定一個字符集,例如:[abc]、[a-z]、[0-9];
元字符在方括號中不起作用,例如:[akm$]和[m.]中元字符都不起作用.
代碼如下(示例):
s='abc acd abc'
print(re.findall(r'a[bc]\D*',s))
print(re.findall(r'a[^b]',s))運行結果
['abc acd abc']
['ac']2.2指定重復次數的字符
① “*”:
匹配位于*之前的字符或子模式的0次或多次出現
代碼如下(示例):
s='aab abb abbbb b a'
print(re.findall(r'ab*',s))運行結果
['a', 'ab', 'abb', 'abbbb', 'a']② “+”:
匹配位于+之前的字符或子模式的1次或多次出現
代碼如下(示例):
s='aab abb abbbb b a'
print(re.findall(r'ab+',s))
運行結果
['ab', 'abb', 'abbbb']③ “?”:
匹配位于?之前的0個或1個字符
當“?”緊隨其他限定符(*、+、{n}、{n,}、{n,m})之后時,匹配模式是“非貪心的”,
“非貪心的”模式匹配搜索到盡可能短的字串,而默認的“貪心的”模式匹配搜索到的、盡可能長的字串,
代碼如下(示例):
s='a ab abbbbb abbbbbxa'
print(re.findall(r'ab+',s))
print(re.findall(r'ab+?',s))運行結果
['ab', 'abbbbb', 'abbbbb']
['ab', 'ab', 'ab']④ “{m,n}”
表示至少有m個重復,至多有n個重復,
m,n均為十進制數,
忽略m表示0個重復,忽略n表示無窮多個重復,
代碼如下(示例):
s1='12345 123567'
s2='a b baaa baaaa'
print(re.findall(r'123\d{2}',s1))
print(re.findall(r'a{1,3}',s2))
運行結果
['12345', '12356']
['a', 'aaa', 'aaa', 'a']re模塊中常量
- re.IGNORECASE 簡寫re.l
作用:大小寫忽略匹配 - re.ASCII 簡寫 re.A
作用:讓\w,\b,\d…只匹配ASCII,而不是Unicode - re.DOTALL 簡寫 re.S
作用:匹配所有,包括\n - re.MULTILINE 簡寫 re.M
作用:多行模式,當某字串中有換行符\n,默認模式下是不 支持換行符特性的,比如:行開頭 和 行結尾,而多行模式下是支持匹配行開頭的 - re.VERBOSE 簡寫 re.X
作用:在正則運算式中加注解
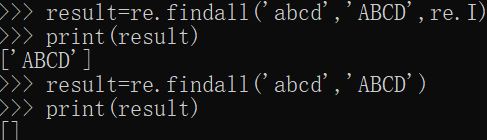
簡單給出一個例子
更多詳細可以參考python正則運算式中re模塊常量用法簡介
re模塊中常用函式
1.字串匹配
re模塊提供了正則運算式操作所需要的功能
1.1match( )
re.match(pattern,string[,flags])
從首字母開始開始匹配,string如果包含pattern子串,則匹配成功,回傳Match物件;失敗則回傳None
代碼如下(示例):
import re
print(re.match(r'How','How are you'))運行結果
<re.Match object; span=(0, 3), match='How'>1.2search( )
re.search(pattern,string[,flags])
將字串的所有子串嘗試與正則運算式匹配,
如果所有的字串都沒有匹配成功,回傳none,否則回傳Match物件,
注意:多個子串,只回傳第一個
代碼如下(示例):
s1='ahello'
s2='bahello world hello'
print(re.match(s1,s2))
print(re.search(s1,s2))運行結果
None
<re.Match object; span=(1, 7), match='ahello'>1.3 findall( )
re.findall(pattern,string[,flags])
串列的形式回傳所有能匹配的子串,如果沒有找到匹配的,則回傳空串列,
代碼如下(示例):
s3=r'abc'
print(re.findall(s3,'aabaab'))
print(re.findall(s3,'aabcaabc'))運行結果
[]
['abc', 'abc']1.4 finditer( )
re.finditer(pattern, string[, flags])
回傳string中所有與pattern相匹配的全部字串,回傳形式為Match物件的迭代器,
1.5小結
1.我們會發現對于findall()函式回傳的是一個串列,
而match()和search()函式,直接列印輸出的結果很多,因此匹配物件的方法只適用于match,search,findier,而不適合findall,
2.例如<re.Match object; span=(0, 5), match=‘abcde’>它就是函式回傳的match物件,但是我們想要得到的只是最后一個結果match=‘abcde’,接下來我們會學習匹配物件的方法來解決這個問題
1.6目標串回傳
在正則運算式中使用()用來分組,group()用來提出分組截獲的字串,
group() 同group(0)就是匹配正則運算式整體結果;
group(1) 回傳第1個括號匹配部分;
group(2) 列出第2個括號匹配部分;
group(3) 列出第3個括號匹配部分;
…
代碼如下(示例):
a="123abc456"
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group())
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0))
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1))
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2))
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3))運行結果
123abc456
123abc456
123
abc
4562.字串替換——re.sub
re.sub(pattern, repl, string[, count])
使用repl替換string中每一個匹配的子串后回傳替換后的字串,
當repl是一個字串時,可以使用\id或\g、\g參考分組,但不能使用編號0;當repl是一個方法時,這個方法應當只接受一個引數(Match物件),并回傳一個字串用于替換(回傳的字串中不能再參考分組),
count用于指定最多替換次數,默認全部替換,
代碼如下(示例):
s1="she is a girl. she likes apples"
result = re.sub('she','he',s1,1)
print(result)運行結果
he is a girl. she likes apples3.字串拆分——re.split()
re.split(pattern,string,maxsplit)
maxsplit指定最大分割次數,不指定將全部分割,回傳根據匹配到的子串將字串分割成串列
代碼如下(示例):
result = re.split('\d+','a111b222c33')
print (result)db = '2020-10-121 23:23:23'
result = re.split("\W+",db)
print (result)運行結果
['a', 'b', 'c', '']['2020', '10', '121', '23', '23', '23']正則運算式物件
1.compile()函式
compile(pattern,[,flags]
compile()函式 編譯正則運算式(以字串書寫的)pattern,轉換為模式物件然后回傳一個正則運算式物件,不同于re.method()這種模式,使用預編譯的代碼物件比直接使用字串要快,因為解釋器在執行字串形式的代碼前都必須把字串編譯成代碼物件,
用正則運算式物件獲取匹配子串
2.字串匹配
Pattern.match(string[, pos[, endpos]])
Pattern.search(string[, pos[, endpos]])
Pattern.findall(string[, pos[, endpos]])
可選引數 endpos 限定了字串搜索的結束;它假定字串長度到 endpos , 所以只有從 pos 到
endpos - 1 的字符會被匹配,如果 endpos 小于 pos,就不會有匹配產生;
如果 string 的 開始位置 能夠找到這個正則樣式的匹配,就回傳一個相應的 匹配物件,如果不匹配,就回傳 None ;
代碼如下(示例):
s1='abcde abcdef bcde'
pattern = re.compile(r'\w*bcd\w*')
result = pattern.match(s1)
print(result.group())運行結果
abcde2.字串替換
Pattern.sub(repl, string, count=0)
等價于 sub() 函式,使用了編譯后的樣式
代碼如下(示例):
s1='abcde abcdef bcde'
pattern = re.compile(r'\s+')
result = pattern.sub('-',s1,3)
print(result)運行結果
abcde-abcdef-bcde3.字串分割
Pattern.split(string, maxsplit=0)
代碼如下(示例):
s1='a1b2c3d4ee5'
pattern = re.compile(r'\d+')
result1 = pattern.split(s1)
result2 = pattern.split(s1,3)
#只分割三次,后面不分割
print(result1)
print(result2)運行結果
['a', 'b', 'c', 'd', 'ee', '']
['a', 'b', 'c', 'd4ee5']4.小結
在re模塊的函式中的函式 compile函式 ,這個函式可以預編譯回傳一個正則物件,此正則物件擁有與re模塊相同的函式,
那到底該用re模塊 還是 正則物件Pattern ?
官方檔案推薦:在多次使用某個正則運算式時推薦使用正則物件Pattern 以增加復用性,因為通過 re.compile(pattern) 編譯后的模塊級函式會被快取,
總結
路漫漫其修遠兮,老師也說python正則運算式文化博大精深,我們也是需要掌握好常見的用法的,
以上即為我對python正則運算式的簡要了解,
我在學習以及練習的程序中,真的意識到實踐才能出真知!!!有疑惑就去實操!!!識訓一定會有的!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/188760.html
標籤:其他
上一篇:Python 技術篇-操作word檔案插入圖片和表格實體演示
下一篇:發送帶附件的郵件