文章目錄
- 專案地址
- 實操
- 配置環境
- 資料
- 運行
- 原碼解讀
- 建立dataset
- init
- getitem
- len
- 建立dataloader
- collate_fn
- 模型的建立
- 模型的計算流程
- 明確輸入
- extend
- sentence padding
- sentence encoder
- document padding
- document encoder
- 輸出
- 總結
- 接下去的作業
專案地址
Text Segmentation as a Supervised Learning Task
實操
這里介紹如何跑它的原碼,
配置環境
- python2.7
conda create -n textseg python=2.7 numpy scipy gensim ipython
- 依賴庫
pip install http://download.pytorch.org/whl/cu80/torch-0.3.0-cp27-cp27mu-linux_x86_64.whl
pip install tqdm pathlib2 segeval tensorboard_logger flask flask_wtf nltk
pip install pandas xlrd xlsxwriter termcolor
其中torch-0.3.0 cu80 改成torch-1.2.0 cu10(我cuda是10.0的)
cp27m檔案會報錯:
pip install --user https://download.pytorch.org/whl/cu100/torch-1.2.0-cp27-cp27m-manylinux1_x86_64.whl
改成:cp27mu即可:
pip install --user https://download.pytorch.org/whl/cu100/torch-1.2.0-cp27-cp27mu-manylinux1_x86_64.whl
資料
資料地址(百度云盤):
wiki_727K
提取碼:1nrj
google word2vec
提取碼:pnkc
wiki_test_50(這個我還沒用過)
提取碼:s5ur
- 首先是下載:wiki727k, google word2vec,并解壓縮
wiki_727解壓縮:tar -xjf wiki_727K.tar.bz2
googleword2vec解壓縮:gzip -d GoogleNews-vectors-negative300.bin.gz
CHOI本來就有 - 然后要更改configgenerator.py里面的路徑,其中choi資料集git下來就有
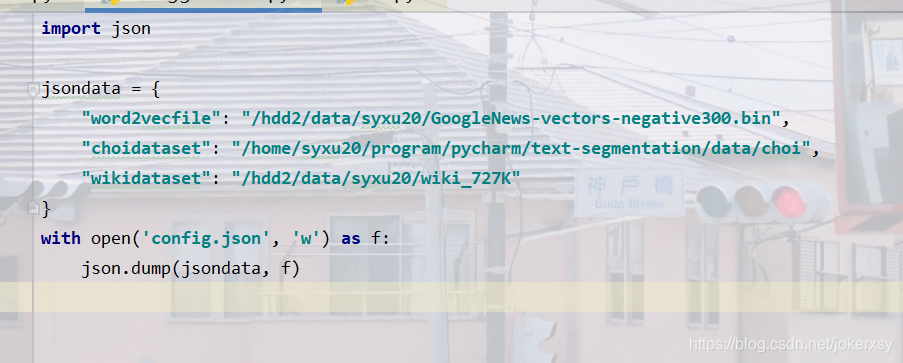
運行
然后應該就可以跑了吧,這里再記錄一點其它小錯誤,
- nltk版本錯誤
 解決:添加鏈接描述
解決:添加鏈接描述
pip install --user nltk==3.0
- 其它應該沒啥了
原碼解讀
原碼其實很簡單,大概做了三件事:建立dataset、建立dataloader(collate_fn)、建立模型
建立dataset
以下面建立train_dataset的代碼為例:

它是呼叫了wiki_loader.py中的WikipediaDataSet類,讓我們來看看這個類做了什么事情,首先要知道這個類是繼承了torch.utils.data中的Dataset的,當然會init, getitem,len這三個方法啦,
init

cache_path是是"..../wiki727K/train/paths_cache"路徑,它是用來存放train中所有文章的路徑名的,如果它存在那就不要再創建了,如果不存在,就要呼叫cache_wiki_filenames來創建:
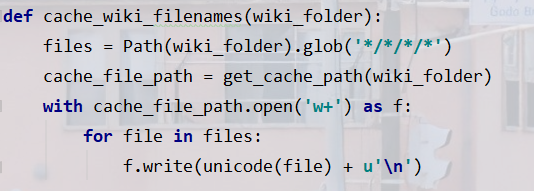
Path.glob("…")能夠遍歷路徑下三層(四層)中的所有檔案名,并依次寫入"…/wiki727K/train/paths_cache"`

然后就是其它的初始化,high_granularity表示是否是細粒度的,如果是那就去除所有"=========,(3-999)…"這樣的分割標記,如果不是,就不去除,
getitem
getitem是關鍵,它講述了如何把一個文章路徑變成data、targets、path的故事,
- 輸入:路徑的下標
- 輸出:data、target、path
- data:[句子1,句子2,句子3…]
- 句子1:[1x300,1x300,1x300]…(長度未padding)
- target:[分割點1,分割點2,分割點3…]

這個函式主要做了下面幾件事情
- 通過get_sections得到所有的分塊,怎么分?——就是根據"=========,(?)…“這種標題來分啊,回傳的是一個串列,里面的每一個分塊是"句子\n句子\n句子\n”…的形式,注意這個分塊會隨著是否細粒度而不同,
- 遍歷每一個分塊的每一個句子,通過extract_sentence_words來得到句子里面的單詞,這個函式在text_manipulation.py里,主要使用了nltk.tokenize中的RegexpTokenizer
- 使用word2vec把單詞轉換為向量,這個沒什么好說的
其它我注意到的細節依次如以下幾點:
-
根據粒度的不同,分割的標記符也有不同

-
把第一個分塊洗掉了

-
過濾掉"
***LIST***"
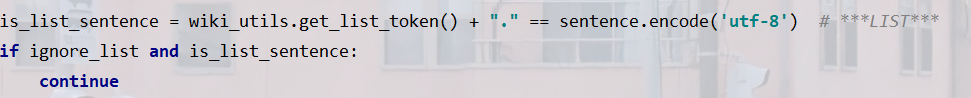
-
targets里面是類似于[3,10,20,47]這樣的分割點,

len
這沒啥好說的
建立dataloader
dl沒什么好說的,主要是它的collate_fn
collate_fn
這個函式定義在choiloader.py中
- 輸入:batch
- batch:[[data1,target1,path1],[data2,target2,path2]…(bs個)]
- data\target\path就是ds回傳的那些
- 輸出:batched_data, batched_targets, paths
- batched_data:[tensored_data1,tensored_data2,…]
- tensored_data1:[句子1,句子2…]
- 句子:一個tensor, 單詞數x300維
- batched_targets:[tensored_targets1,tensored_targets2,…]
- tensored_targets1:跟文章的句子數大小一致,如果是分割點,對應位置為1,否則為0
其它細節:
-
window_size:這個設定成了1也就是一個句子一個句子遍歷,影響不大

-
洗掉了最后一個target,在模型里面,也要記得洗掉最后一個句子的分類結果哦

模型的建立

模型有兩種建立方式
- import_model,它會匯入model/max_sentence_embedding.py,通過里面的create方法來建立模型,
- torch.load(),匯入訓練好的模型
其它細節:
- 這個model_name就是max_sentence_embedding,通過import這個python內置函式來匯入,

模型的計算流程
這部分是這篇博客的關鍵,因為之前我們也自己寫過,但并行化程度依舊不高,這份原始碼帶來的啟發很大,以后應該都會參照這個做法來做,

讓我們一起來看看這個model(data)做了什么吧
明確輸入
輸入是上面說的batched_data
batched_data:[tensored_data1,tensored_data2,…]
- tensored_data1:[句子1,句子2…]
- 句子:一個tensor, 單詞數x300維
注意:他既沒有對單詞數進行padding,也沒有對句子數進行padding,也就是說每一個tensored_data(每一篇文章)中的句子數都是真實的數量,每一個句子里面的單詞數也是真實的數量,而具體的padding是在模型里面做的,
extend

遍歷batch(batched_data),用extend來把所有的所有文章的所有句子拼到一起組成一個大的串列(all_batch_sentences),
- all_batch_sentences = [第一篇文章的句子1,第一篇文章的句子2,…,第二篇文章的…]
- 其中,第一篇文章的句子1 = 單詞數*300的一個tensor,注意每一個句子的單詞數都是真實單詞數,所以如果要把整個all_batch_sentences轉成tensor,需要padding,
- sentences_per_doc是字面意思,下面會用得到,用來把sentence encoder的輸出重新按照document來劃分,
sentence padding
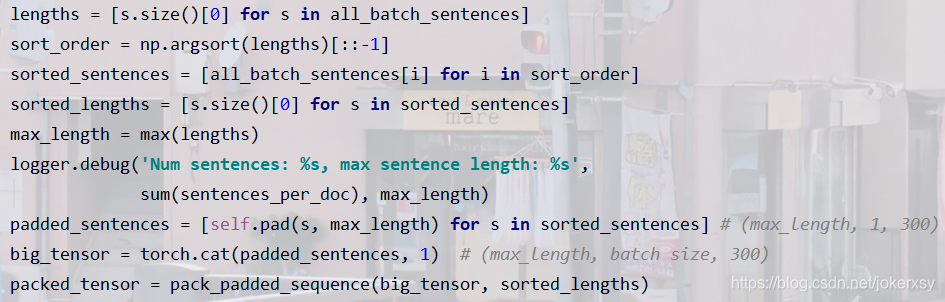
- lengths統計每個句子的單詞數
- sort_order根據lengths排序,得到下標,比如lengths=[5,10,6,8]表示三個句子各自的單詞數,sort_order就=[1,3,2,0],即長的句子的下標排在前面
- sorted_sentences是根據sort_order對all_batch_sentences進行抽取排序,其里面的句子是按照單詞數從多到少排好序了的
- sorted_lengths是排好序之后的每個句子的單詞數
- max_length字面意思(我認為取名為max_num_of_words_of_all_sens比較好)
- self.pad要具體說說:

對于一個句子s而言,它是一個單詞數*300的tensor,然后我們已知的是最大的單詞數,
首先把它unsqueeze成 (1,1,單詞數,300)維的矩陣,為什么?——好問題!因為F.pad的輸入要求是四維(及以上?)的,F.pad做的就是padding,第一個引數v就是上述四維矩陣,(0,0,0,max_length-s_length)就很有意思:它表示對于上述矩陣的最后兩維(把最后兩維單獨拎出來,想成是一個矩陣),分別對這個矩陣的左、右、上、下進行0,0,0,max_length-s_length的填充,(PyTorch碎片:F.pad的圖文透徹理解),于是乎,我們就得到了一個(1,1,max_length,300)的矩陣,然后通過view轉稱(max_length, 1, 300)的矩陣,為什么要轉稱(max_length, 1, 300)?——因為我們要在第二維進行拼接,最終得到(max_length,句子數(視作batch_size),300)的big_tensor,也就說,lstm的batch_first應該是False的, - padded_sentences = [(max_length,1,300),(max_length,1,300)…]
- big_tensor = (max_length, num_of_all_sens,300)
- packed_tensor:再對big_tensor進行pack_padded_sequence來去除padding的影響,
sentence encoder
我們已經得到了packed_tensor了,基本就大功告成了,只需要送入sentence encoder,

- 首先肯定是把它送入定義好的lstm,(max_length, batch_size, 300) -> (max_length, batch_size, hidden_size * 2)
- 然后用pad_packed_sequence把它pad回來(居然可以同時回傳lengths(ordered),太棒了)
- 接著就是很關鍵的一步: 取出句子向量表示,原碼里面是對于每一個句子(padded_output[:, i, :]),先取出它實際有多少個單詞(padded_output[:lengths[i], i, :]),在這些單詞里取出一個最大的向量,來表示這個句子(torch.max(padded_output[:lengths[i], i, :], 0)),那我們也可用: 最小、平均、 attention的方法來取出,所以在這一部分,我們對代碼進行了擴充:
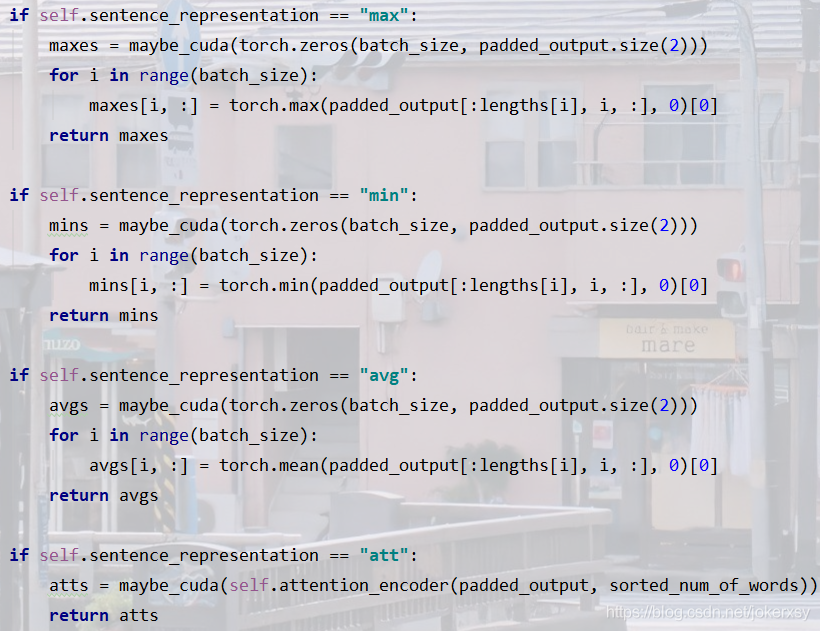
這一步對應的應該就是任務中的:
還有什么別的pooling?干脆一起比較了吧!
哦對了,我們甚至可以把lstm替換成gru、rnn、transformer來進行比較,這對應了任務中的:

只不過這個編碼器暫時只討論到句子編碼器,
話說回來,我們已經得到了 (所有句子數,hidden_size*2) 的句子向量表示矩陣了(encoded_sentences),
document padding
-
encoded_sentences進行重排序

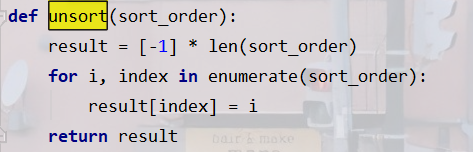 對于encoded_sentences我們先要把它按照原來的順序排回去,還是舉sentence padding中的例子,假如lengths = [5,10,6,8]表示三個句子各自的單詞數,sort_order就=[1,3,2,0],即長的句子的下標排在前面,我們要得到什么?——[3,0,2,1]哇,unsort做的就是這件事情,然后根據unsort_order對encoded_sentences進行重排序,得到unsorted_encodings,
對于encoded_sentences我們先要把它按照原來的順序排回去,還是舉sentence padding中的例子,假如lengths = [5,10,6,8]表示三個句子各自的單詞數,sort_order就=[1,3,2,0],即長的句子的下標排在前面,我們要得到什么?——[3,0,2,1]哇,unsort做的就是這件事情,然后根據unsort_order對encoded_sentences進行重排序,得到unsorted_encodings, -
重新取出每篇各自的句子
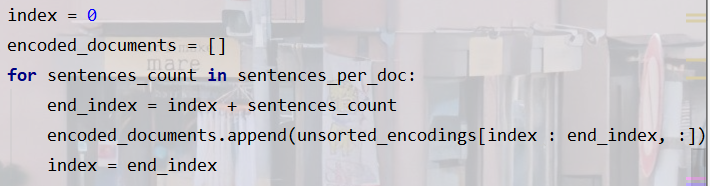 接著用extend環節就統計好的sentences_per_doc得到encoded_documents(=[(句子數1,hidden*2),(句子數2,hidden*2)…]),然后才是document padding,
接著用extend環節就統計好的sentences_per_doc得到encoded_documents(=[(句子數1,hidden*2),(句子數2,hidden*2)…]),然后才是document padding, -
document padding
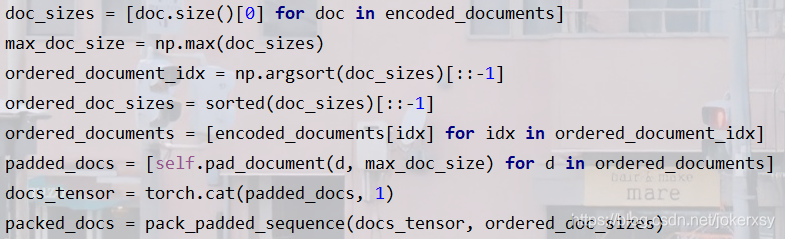
document_padding這部分就不解釋了,為什么?——去看上面sentence_padding的時候,all_batch_sentences = [第一篇文章的句子1,第一篇文章的句子2,…,第二篇文章的…] = [(單詞數1,hidden*2),(單詞數2,hidden*2)…],它跟encoded_documents(=[(句子數1,hidden*2),(句子數2,hidden*2)…])是基本一樣的,所以我覺得原碼中寫了兩個pad(self.pad, self.pad_document是完全沒必要的),所以我把sort、pad、pack寫在了一個函式里面,這樣可以簡化代碼(由于是我寫的,下面的變數名與原碼不同,注意區分):
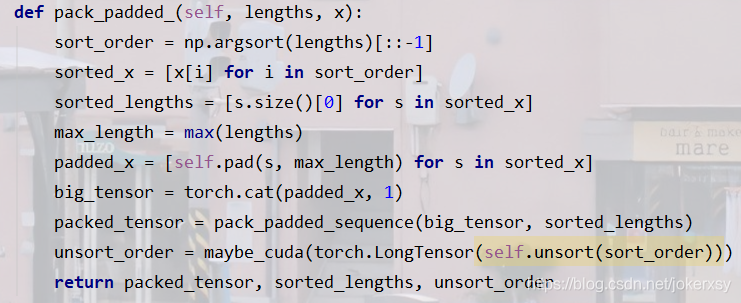

-
packed_docs: 最大句子數,batch_size(文章數), hidden_size*2
-
sorted_num_of_sens: 字面意思
-
unsort_order: 字面意思
哦對,在這之前別忘了統計原來每篇文章有多少個句子哦(num_of_sen_per_doc):

document encoder
這沒什么好說的,就是把上面的packed_docs傳入lstm,跟上面句子編碼器對應,我們也可以采用gru、rnn、transformer來做這件事情,

padded_output 為 (最大句子數,batch_size(文章數), hidden_size*2)
輸出

我們已經得到了padded_out(最大句子數,文章數, hidden_size*2)
- doc_outputs :根據document padding環節統計的sorted_num_of_sens對padded_out進行操作,取出每篇文章真正的句子數,doc_outputs = [(句子數1,hidden*2),(句子數2,hidden*2)…]
- unsorted_doc_outputs:然后用document padding環節統計的unsort_order對文章進行重排序得到unsorted_doc_outputs
- all_sentence_outputs:把unsorted_doc_outputs([(句子數1,hidden*2),(句子數2,hidden*2)…]) 在第0維進行拼接,得到all_sentence_outputs(所有句子數,hidden*2)
- final_outputs: 再傳給一個線性層,得到了所有句子的分類概率結果(所有句子數,2),
接下來就是計算loss等,
總結
哈哈, “Koshorek[18] (Two-level BiLSTM) (復現)”算是完成了一半了,
- 資料方面,他并沒有提取example、feature,而是在dataset里面通過路徑讀取data、target、path,在collate_fn里面再做成一個batch,
- 在模型傳入之前,他也沒有做任何的padding,對建立dataloader并不需要提前padding,這樣會有很多變數的(各種長度…),傳來傳去都覺得煩2333
- 模型大致分成四個部分: sentence_padding,sentence_encoder,document_padding,document_encoder,非常清晰
接下去的作業
- 把這個模型訓練起來,看看到底需要多久!來決定是否取少一點的wiki727K樣本
- 如果要:則把wiki727K的train、dev、test分別提取8000\1000\1000
- 只復現(抄)了 到train為止的代碼,還有validation,結果可視化(loss\acc\pk等)
- 除max、min、avg、att以外,有什么其它的pooling(?)操作?(句子編碼階段)
- 句子編碼階段和文章編碼階段,可以把lstm替換成rnn、gru和transformer啊!pytorch的transformer具體怎么用是我接下來要學習的東西,
- CRF在這種場景下該怎么寫(😔)?
- 其它
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/189063.html
標籤:其他
上一篇:web組態設計
下一篇:10.22 成長日記