前言
這是我聽老師講課做的筆記,考試要看的, 這是視頻地址
作者:陳運智
關注我的csdn博客,更多Linux筆記知識還在更新
本人只在csdn寫博客
配套這篇文章觀看效果更佳
MySQL索引的使用實體
- 一. 慢查詢日志
- 二. 查詢分析器——explain
- 三. 索引的基本使用
- 四. 復合索引
- 五. 覆寫索引
一. 慢查詢日志
//查看是否開啟慢查詢日志
mysql> show variables like '%slow%';
//臨時開啟慢查詢日志
mysql> set global slow_query_log=ON;
//查看是否開啟慢查詢日志
mysql> show variables like '%slow%';
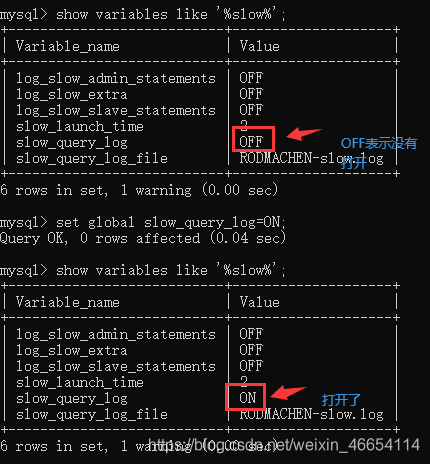
//查詢超過多少時間就可以記錄,上面是如果超過10秒就要記錄
mysql> show variables like '%long%';
//改成一秒,如果超過一秒就寫到慢日志里面去(一般一秒是最好的)
mysql> set long_query_time=1;
//查看日記存盤方式,默認FILE
mysql> show variables like '%log_output%';
// 慢查詢日志檔案所在位置
mysql> show variables like '%datadir%';
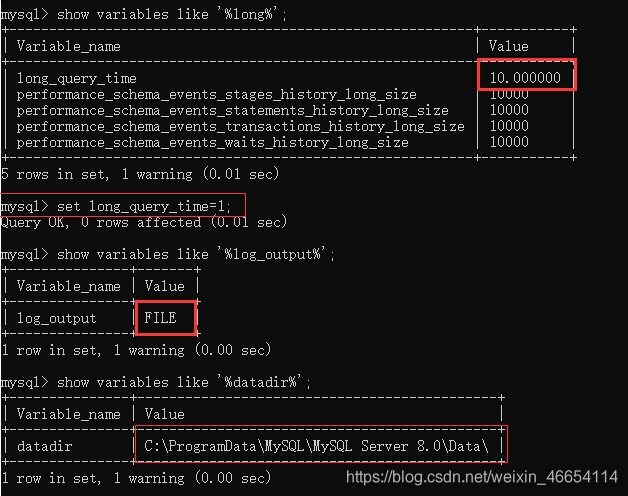
//回應時間是3秒,超過了原先設定的一秒
mysql> select sleep(3);
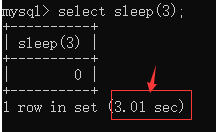
我們去檔案夾里面查看時發現它已經被存入慢查詢日記里面
這部分寫明了如何通過慢日志找出比較慢的SQL,后面部分要說為什么慢,如何能更快一點,
二. 查詢分析器——explain
作用:通過這個可以知道查看sql慢在哪里,需要朝那些方面優化
列:我們創建一個employee資料表
create table employee(
id int not null auto_increment primary key,
name varchar(30) comment '姓名',
sex varchar(1) comment '性別',
salary int comment '薪資(元)',
dept varchar(30) comment '部門'
);
insert into employee(name, sex, salary, dept) values('張三', '男', 5500, '部門A');
insert into employee(name, sex, salary, dept) values('李潔', '女', 4500, '部門C');
insert into employee(name, sex, salary, dept) values('李小梅', '女', 4200, '部門A');
insert into employee(name, sex, salary, dept) values('歐陽輝', '男', 7500, '部門C');
insert into employee(name, sex, salary, dept) values('李芳', '女', 8500, '部門A');
insert into employee(name, sex, salary, dept) values('張江', '男', 6800, '部門A');
insert into employee(name, sex, salary, dept) values('李四', '男', 12000, '部門B');
insert into employee(name, sex, salary, dept) values('王五', '男', 3500, '部門B');
insert into employee(name, sex, salary, dept) values('馬小龍', '男', 6000, '部門A');
insert into employee(name, sex, salary, dept) values('龍五', '男', 8000, '部門B');
insert into employee(name, sex, salary, dept) values('馮小芳', '女', 10000, '部門C');
insert into employee(name, sex, salary, dept) values('馬小花', '女', 4000, '部門B');
insert into employee(name, sex, salary, dept) values('柳峰', '男', 8800, '部門A');
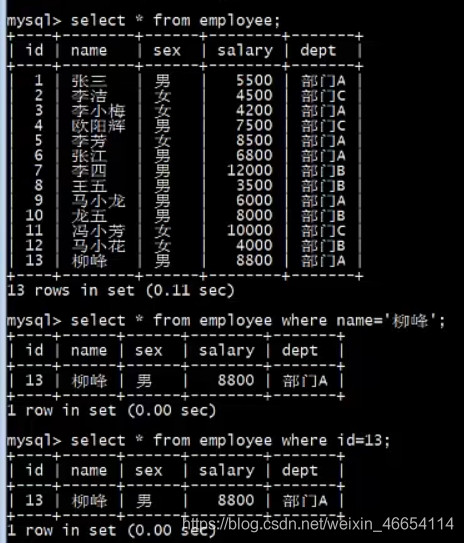
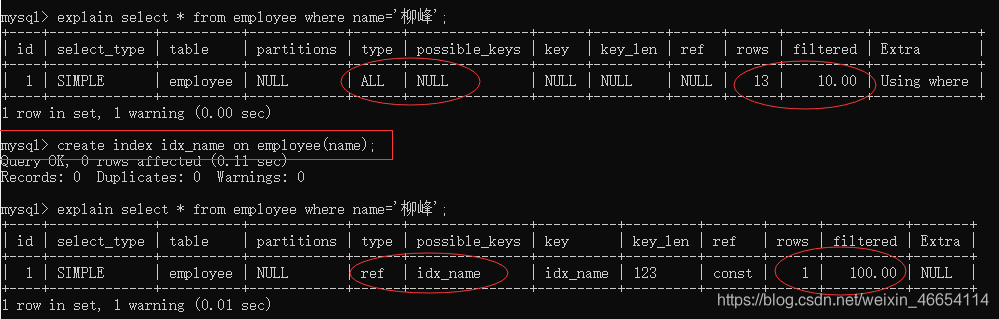
//通過explain解讀他,后面加一個\G便于閱讀
mysql> explain select * from employee where name='柳峰'\G;
//掃描快捷
mysql> explain select * from employee where id=13\G;
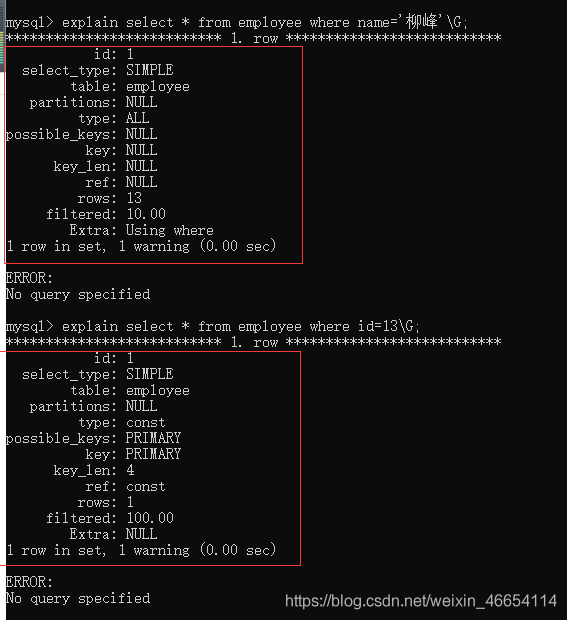
效果:如下圖,可以看之前為什么那么慢,需要四秒回應時間
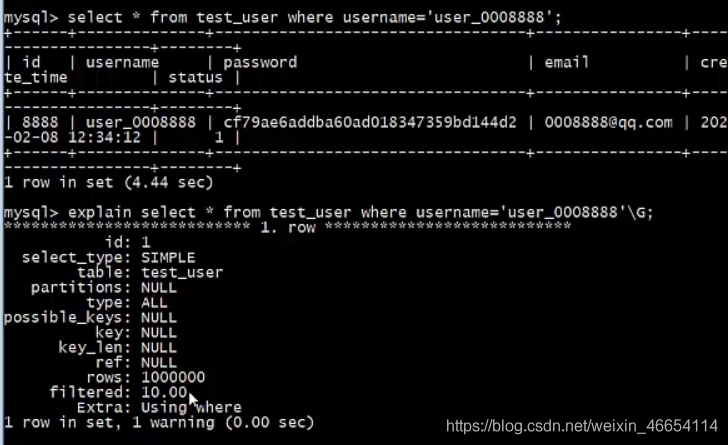
三. 索引的基本使用
mysql> show index from employee\G;
//主鍵會默認建一個id索引
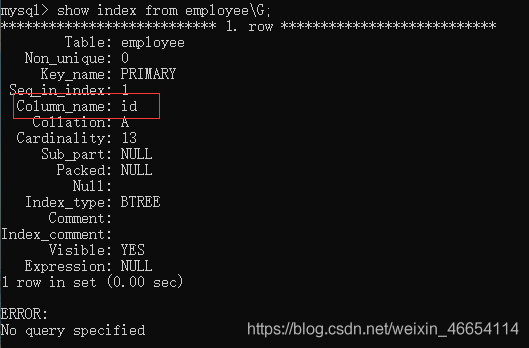
創建索引 效率提升
//查詢分析
mysql> explain select * from employee where name='柳峰';
//創建普通索引
mysql> create index idx_name on employee(name);
//洗掉
mysql> drop index idx_name on employee;
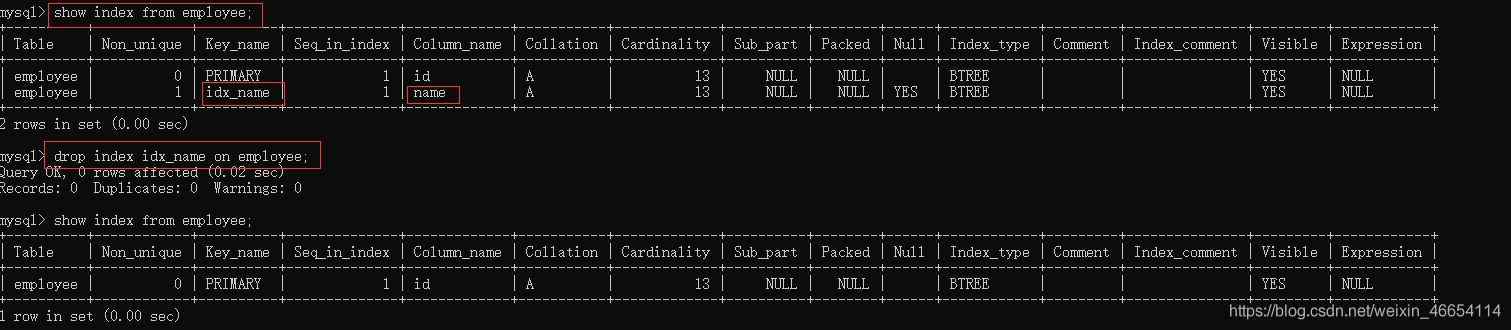
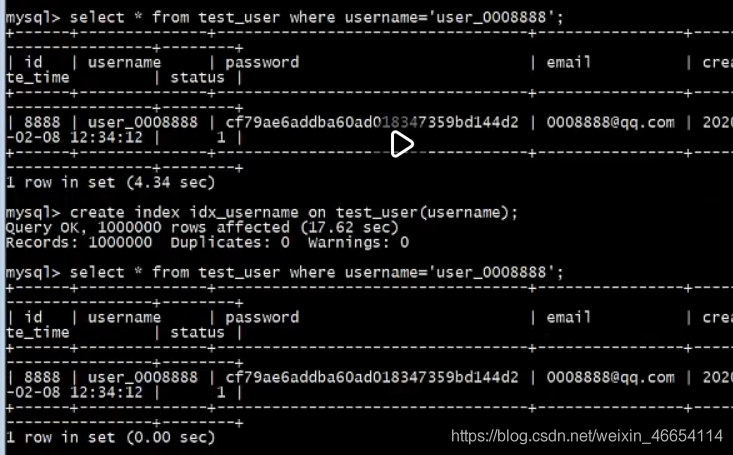
老師 事列:
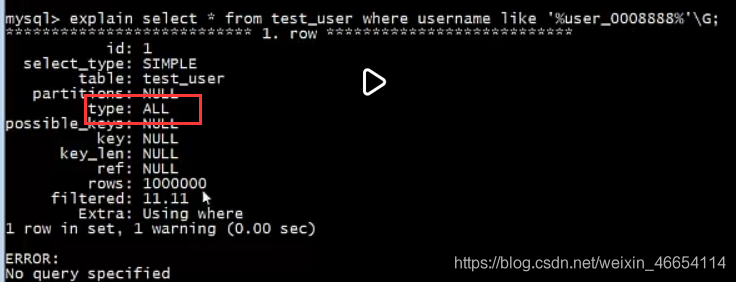
如過用like檢索,效率還是不變,所以要看你怎么用
四. 復合索引
//查的時候可以看到一個主鍵索引
mysql> show index from employee\G;
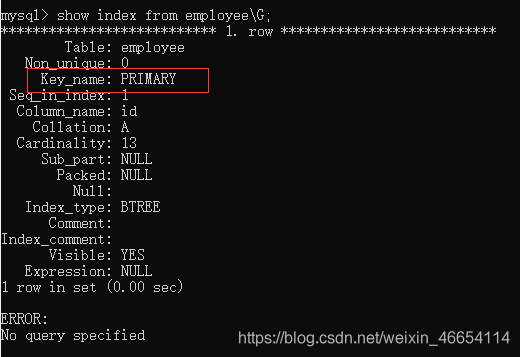
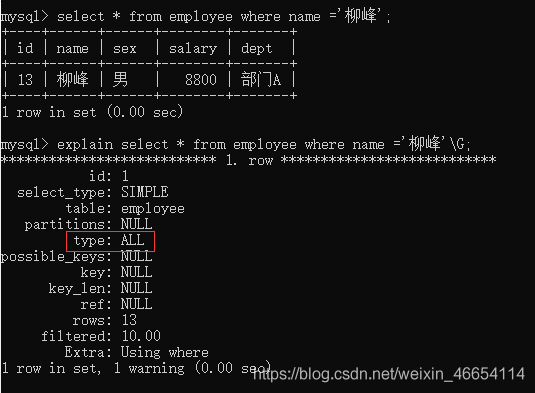
目前是all全域掃描
select * from employee where name ='柳峰';
//查詢分析
explain select * from employee where name ='柳峰'\G;
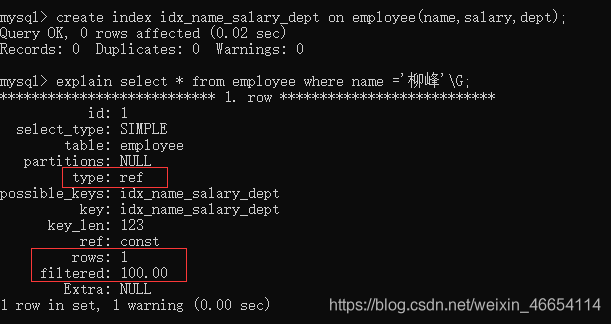
創建索引
//創建索引
create index idx_name_salary_dept on employee(name,salary,dept);
//查詢分析
explain select * from employee where name ='柳峰'\G;
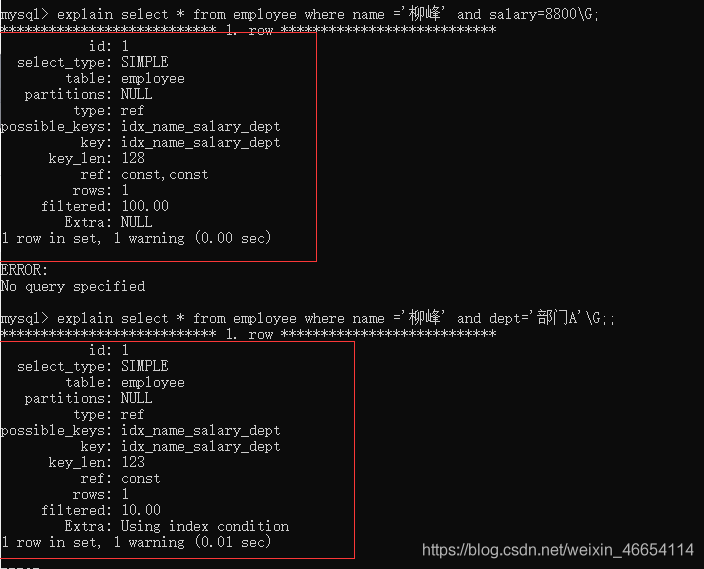
驗證有name就能索引
// name和salary
mysql> explain select * from employee where name ='柳峰' and salary=8800\G;
//name和dept
mysql> explain select * from employee where name ='柳峰' and dept='部門A'\G;
沒有name就不能使用索引
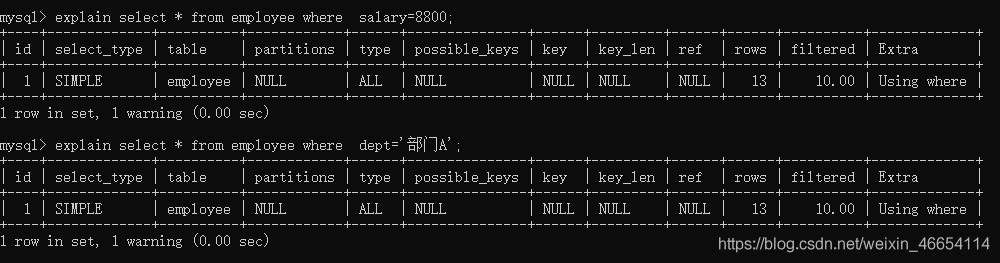
mysql> explain select * from employee where salary=8800;
mysql> explain select * from employee where dept='部門A';
五. 覆寫索引
按照上面步驟,我們可以看到四個索引,第一個是主鍵索引,后面是復合索引name_salary_dept
mysql> show index from employee;

如何觸發
我們用id作為查詢資料
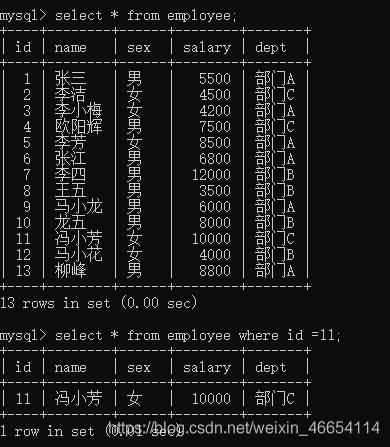
mysql> select * from employee;
mysql> select * from employee where id =11;
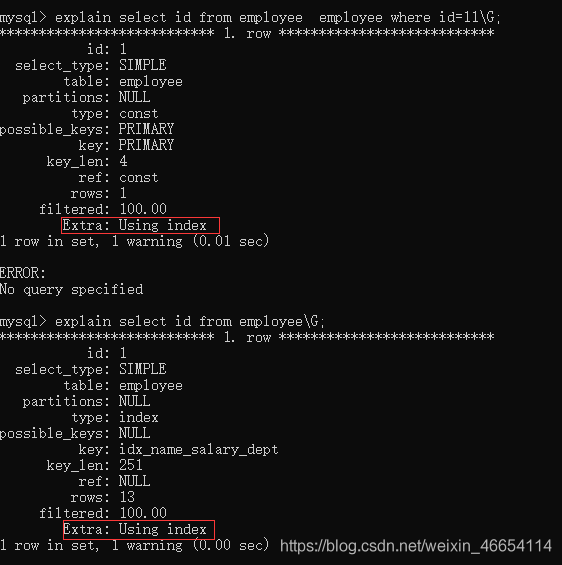
只查id
mysql> explain select id from employee employee where id=11\G;
mysql> explain select id from employee\G;
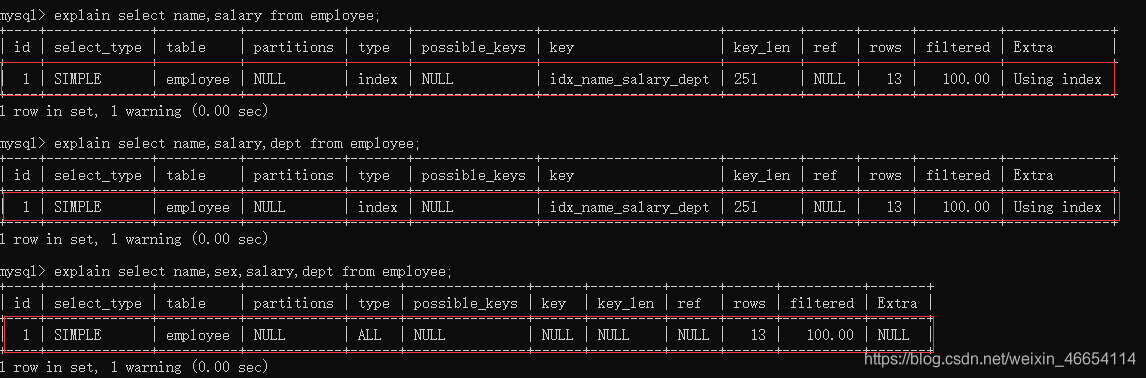
//查name,salary
mysql> explain select name,salary from employee;
//查name,salary,dept
mysql> explain select name,salary,dept from employee;
//因為沒有sxe條件,所以只能做全部掃描type為null
mysql> explain select name,sex,salary,dept from employee;
本人博客:https://blog.csdn.net/weixin_46654114
本人b站求關注:https://space.bilibili.com/391105864
轉載說明:跟我說明,務必注明來源,附帶本人博客連接,
請給我點個贊鼓勵我吧

轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/190233.html
標籤:其他