我有故事,讓機器人來讀
最近作業較忙,回家閑下來只想閉目休息,一分鐘螢屏都不想再看,然而我又想追更之前看的小說,于是,需求來了——我需要一個給我講故事的機器人!
瀏覽器或者閱讀器App里其實也有朗讀功能,但是比較僵硬,總是將引人入勝的情節念成流水賬,分分鐘讓人棄坑,所以我考慮自己使用爬蟲定時下載更新的章節,而后將文字合成存盤到音頻檔案,這樣不僅可以選擇一個靠譜的語音合成工具來處理文字,而且保存下來的音頻還能反復收聽,一舉兩得,
文本整合容易,但是如何將其快速轉換成音頻呢?難道要自己訓練模型“煉丹”解決?no no ,費力不討好,畢竟自己手頭這點演算法知識非常淺顯,而且硬體條件也不允許,本著“能用就行”的原則,我決定先使用市面上開放平臺的產品來解決,經過對比,發現有道智云的語音合成還不錯(此處可體驗),決定使用有道智云的語音合成API進行開發,
效果先睹為快:
我拿來朱自清先生的《荷塘月色》的其中兩段作為實驗素材,開發了簡單的demo,走通了從加載文本到生成音頻檔案的邏輯,下面我來詳細介紹開發程序,
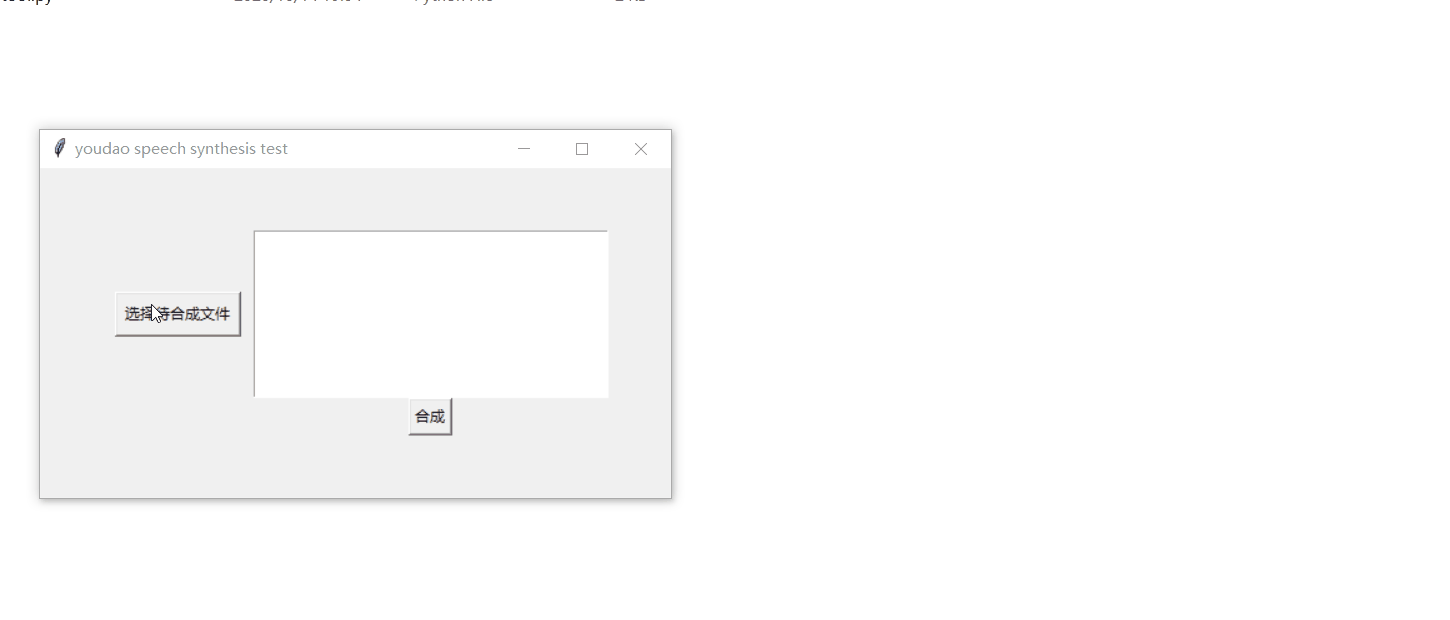
需要語音合成的文本:
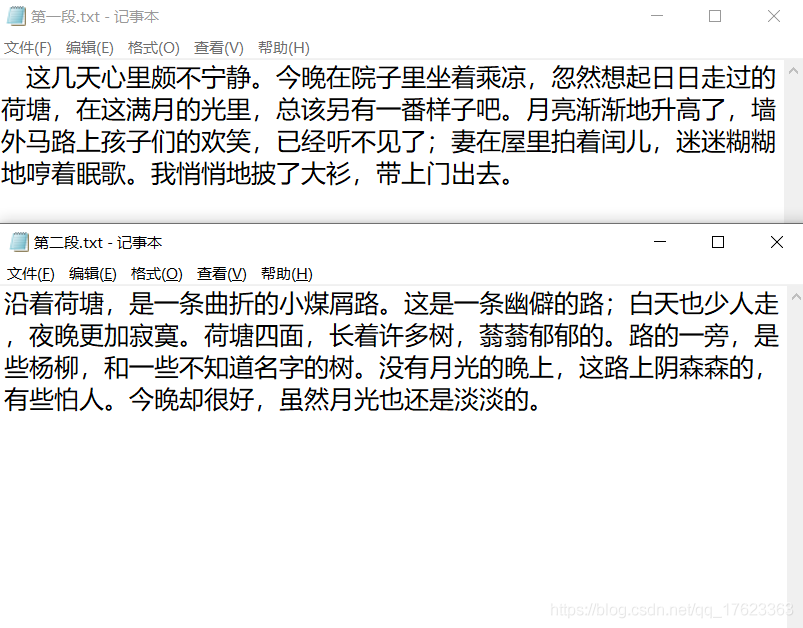
合成結果(第一段):
合成結果(第二段):
很可惜,這里不能上傳mp3格式的音樂檔案

呼叫API介面的準備作業
首先,是需要在有道智云的個人頁面上創建實體、創建應用、系結應用和實體,獲取到應用的id和密鑰,具體個人注冊的程序和應用創建程序詳見文章分享一次批量檔案翻譯的開發程序,
開發程序詳細介紹
下面介紹具體的代碼開發程序,
首先根據檔案分析有道智云的API輸入輸出規范,語音合成API呼叫十分簡單,該API采用https方式通信,所需引數如下表:
| 欄位名 | 型別 | 含義 | 必填 | 備注 |
|---|---|---|---|---|
| q | text | 待合成音頻檔案的文本字串 | True | 比如:您好 |
| langType | text | 合成文本的語言型別 | True | 支持語言 |
| appKey | text | 應用 ID | True | 可在 應用管理 查看 |
| salt | text | UUID | True | UUID |
| sign | text | 簽 | True | MD5(應用ID+q+salt+應用密鑰) |
| voice | text | 翻譯結果發音選擇,0為女聲,1為男聲,默認為女聲 | false | 0 |
| format | text | 目標音頻格式,支持mp3 | false | mp3 |
| speed | text | 合成音頻的語速 | false | 比如:"1"為正常速度 |
| volume | text | 合成音頻的音量 | false | 正常為"1.00",最大為"5.00",最小為"0.50" |
簡單概括,組織好自己的語言(utf-8編碼文本),輔以簽名等必要引數,并告訴API所需要的音頻特征,即可得到一份令人滿意的合成音頻,
介面輸出中,如果合成成功,正常回傳為二進制語音檔案,具體header資訊 Content-type: audio/mp3,如果合成出現錯誤,則會回傳json結果,具體header資訊為:Content-type: application/json,可據此判斷運行情況,
Demo開發:
這個demo使用python3開發,包括maindow.py,synthesis.py,synthesistool.py三個檔案,分別為demo的界面、界面邏輯處理和語音合成介面呼叫工具封裝,
-
界面部分:
界面部分代碼如下,比較簡單,
root=tk.Tk() root.title("youdao speech synthesis test") frm = tk.Frame(root) frm.grid(padx='50', pady='50') # 檔案選取按鈕 btn_get_file = tk.Button(frm, text='選擇待合成檔案', command=get_files) btn_get_file.grid(row=0, column=0, ipadx='3', ipady='3', padx='10', pady='20') # 所選檔案串列展示框 text1 = tk.Text(frm, width='40', height='10') text1.grid(row=0, column=1) # 啟動按鈕 btn_sure=tk.Button(frm,text="合成",command=synthesis_files) btn_sure.grid(row=1,column=1)其中啟動按鈕btn_sure的系結事件synthesis_files()來收集帶所有的文本檔案,啟動合成,并列印運行結果:
def synthesis_files(): if syn_m.file_paths: message=syn_m.get_synthesis_result() tk.messagebox.showinfo("提示", message) os.system('start' + '.\\result') else : tk.messagebox.showinfo("提示","無檔案") -
synthesis.py
這里主要是配合界面實作一些文本讀取和請求介面處理回傳值的邏輯,首先定義一個Synthesis_model
class Synthesis_model(): def __init__(self,file_paths,result_root_path,syn_type): self.file_paths=file_paths # 待合成檔案路徑 self.result_root_path=result_root_path # 結果路徑 self.syn_type=syn_type # 合成型別get_synthesis_result()方法實作了批量讀取檔案并呼叫合成方法、處理回傳資訊的邏輯:
def get_synthesis_result(self): syn_result="" for file_path in self.file_paths: # 讀取檔案 file_name=os.path.basename(file_path).split('.')[0] file_content=open(file_path,encoding='utf-8').read() # 呼叫合成方法 result=self.synthesis_use_netease(file_name,file_content) # 處理回傳訊息 if result=="1": syn_result=syn_result+file_path+" ok !\n" else: syn_result=syn_result+file_path+result return syn_result單獨定義了方法synthesis_use_netease()具體實作呼叫API的方法,這樣增加了demo的擴展性,實作了一種合成模塊可插拔的松耦合形式:
def synthesis_use_netease(self,file_name,text): result=connect(text,'zh-CHS') print(result) if result.headers['Content-Type']=="audio/mp3": millis = int(round(time.time() * 1000)) filePath = "./result/" + file_name+"-"+str(millis) + ".mp3" fo = open(filePath, 'wb') fo.write(result.content) fo.close() return "1" else: return "error:"+result.content -
synthesistool.py
-
synthesistool.py中是和請求有道智云API直接相關的一些方法,最核心的是connect()方法,整合了API所要求的各個引數,并呼叫執行請求的方法do_request(),并回傳API處理結果,
def connect(text,lang_type): q = text data = {} data['langType'] = lang_type salt = str(uuid.uuid1()) signStr = APP_KEY + q + salt + APP_SECRET sign = encrypt(signStr) data['appKey'] = APP_KEY data['q'] = q data['salt'] = salt data['sign'] = sign response = do_request(data) return response
需要體驗一下的小伙伴,請下載我的代碼自行嘗試或去官網體驗 : P,專案地址:https://github.com/LemonQH/SpeechSynthesis
特別提示:
1、運行demo時,需要替換synthesistool.py模塊中的 APP_KEY 、 APP_SECRET為你自己生成的 APP_KEY、APP_SECRET哦
2、該工程默認存放結果存在./result 檔案夾下,你需要手動在專案路徑下創建該目錄,或者修改為任意你想存放的位置 -
總結
以上就是我的開發程序,有道智云的語音合成API檔案清晰,呼叫程序全程無坑,開發體驗和合成效果都令人感到舒適,
我有故事,我把它交給機器人來講,閉目養神不枯燥,真是一件美事!
歡迎關注我,一塊來履行我之前的承諾,連更一個月之內,把幾篇寫完,
| 序號 | 預計完成時間 | 開發dome名字以及功能&發布文章內容 | 是否已寫完 | 文章鏈接 |
|---|---|---|---|---|
| 1 | 9月3 | 文本翻譯,單文本翻譯,批量翻譯demo, | 已完成 | CSDN:點我直達 微信公眾號:點我直達 |
| 2 | 9月11 | OCR-demo,完成批量上傳識別;在一個demo中可選擇不同型別的OCR識別《包含手寫體/印刷體/身份證/表格/整題/名片),然后呼叫平臺能力,具體實作步驟等, | 已完成 | CSDN:點我直達 微信公眾號: |
| 3 | 10月27 | 語音識別demo,demo中上傳—段視頻,并截取視頻中短語音識別-demo的一段音頻進行短語音識別 | CSDN:點我直達 微信公眾號: | |
| 4 | 9月17 | 智能語音評測-demo | CSDN: 微信公眾號: | |
| 5 | 9月24 | 作文批改-demo | CSDN: 微信公眾號: | |
| 6 | 9月30 | 語音合成-demo | CSDN: 微信公眾號: | |
| 7 | 10月15 | 單題拍搜-demo | CSDN: 微信公眾號: | |
| 8 | 10月20 | 圖片翻譯-demo | CSDN: 微信公眾號: | |
關注我微信公眾號第一時間推送給你哦:
回復選單,更有好禮,驚喜在等著你,

歡迎掃碼加入我創建的社區群哦,可以與我更進一步的交流,群里還有很多大佬等著你,一起玩耍,一起進步!!!


 CSDN認證博客專家
Linux
分布式
Java
CSDN認證博客專家
Linux
分布式
Java
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/190237.html
標籤:其他