這篇文章不是面面俱到的基礎知識集合,只是我個人的學習筆記,說人話就是:這篇文章是JavaSE基礎知識全解的真子集,并不適合完全初學的小伙伴,且以下所有內容僅代表個人觀點,不一定正確,歡迎辯證~
| 版本 | 說明 | 發布日期 |
|---|---|---|
| 1.0 | 發布文章第一版 | 2020-10-24 |
文章目錄
- 概述
- 在編程之前
- 為什么需要配置環境變數?
- exe和路徑的愛恨情仇
- 環境變數path的作用
- 自己定義環境變數并參考
- 基礎語法
- 基本資料型別中的冷知識(基于64位系統)
- 基本資料型別與記憶體的糾纏
- 整數變數的賦值
- 強轉,不強轉?
- 1.0和1.1的愛恨情仇
- ==?
- boolean型別有多大?
- 自動型別轉換的一個小知識
- 強制型別轉換如何取舍地?
- 變數初始值
- 運算子中的冷知識
- 除以一個0.0試試
- 賦值運算本身也會回傳一個值
- 運算結果的型別
- 如何高效(裝逼)地運算i*4?
- 流程控制中的冷知識
- for( ; ; ){}
- switch的default的穿透與短途效應(自己取的名字哈哈)
概述
- 本篇文章只羅列了我所知道的,基本不涉及類知識的一些不太容易被人知曉的冷知識,不過其實這些知識大多對生產沒有太大用處,但是說不定哪天這些東西會幫助自己避坑呢?
在編程之前
為什么需要配置環境變數?
exe和路徑的愛恨情仇
- Windows執行可執行檔案時,只能識別當前目錄下的exe檔案,而javac和java這兩個可執行檔案,都在jdk\bin中,我們當然不能把所有.java檔案都扔到這個目錄里面去執行,這時候就需要用到path環境變數,
環境變數path的作用
- path環境變數讓Windows執行exe之前,先去path變數中從上到下(win7是從前到后)遍歷,如果其中存在對應的exe,則可以直接執行,
- 正因為如此,我們才需要把jdk\bin目錄加入到path環境變數中
自己定義環境變數并參考
- 而為了方便今后jdk路徑變更以及Java EE的使用,我們又將jdk的路徑單獨設定一個環境變數JAVA_HOME,然后path中填寫 J A V A H O M E JAVA_HOME JAVAH?OME\bin就完事兒了,以后如果要變更路徑,去改JAVA_HOME就行啦,
- PS:java11之后不需要配置classpath了,
基礎語法
基本資料型別中的冷知識(基于64位系統)
基本資料型別與記憶體的糾纏
- 或許大家知道基本資料型別存盤在堆疊區中,陣列和參考資料型別存盤在堆區中,但是大家可能容易忽略一個小細節,
int a = 1;
int b = 1;
- 上面這行代碼,a和b使用的是同一塊記憶體空間,什么意思呢?看下圖:
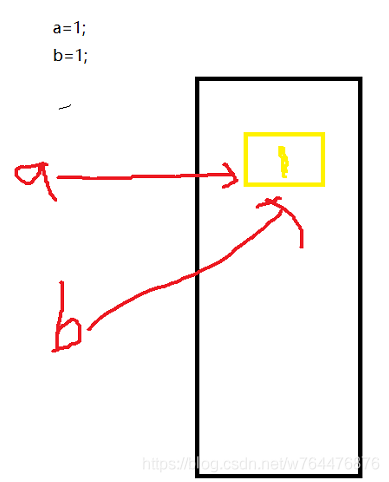
- 像"1"這樣的基本資料型別的值,我們稱為直接量,int b = 1;時,會先查找堆疊中是否存在直接量"1",如果找到了,那么直接使用這個直接量,
- 所以真正存盤在堆疊區中的其實是直接量,相同的直接量,不會重復占用多個記憶體空間,這就是上面代碼a和b使用同一地址的原因,而不同的值會被分配到不同的地址去,所以如果a=1、b=2,那么他們的地址又是不同的,
- 不同型別的相同值,也是會被分配到不同地址,很好理解嘛,因為他們需要的記憶體大小都不一樣嘛,比如1.0和1.0F,他們的在堆疊中的地址是不一樣的,
- 盡管這個特性看起來很像是“參考”,但是我們需要避免這樣去稱呼他們,因為“參考”指的是利用堆疊區中的記憶體地址,指向堆區中的資料,
整數變數的賦值
- 我們都知道
byte a = 1000; short b = 1000000之類的賦值會報錯:不兼容的資料型別,從int到byte(short),因為byte和short太小了, - 但你們知道
int a = 9999999998會報什么錯么?不兼容的資料型別?并不是,報錯的內容是:整數太大, - 這是為什么呢?因為在不加任何符號的情況下,1000、1000000、9999999998這些數字都是分配了4個位元組的記憶體進行存盤,并且型別為int,而某清華學子說過,我們小學二年級就學過int最大的表示范圍大概是25億,顯然9999999998大于了這個數字,
- 所以我們才需要使用int a = 9999999998L來解決這個問題,
- 說到這兒,就像順道說一下,浮點數(例如1.0)的默認型別是double,不是float喲~所以
float b = 1.0F才能正確給float賦值喲~~~~
強轉,不強轉?
- 看了上面兩小節之后,細的朋,哦不,細心的朋友們就要問了:
byte a = 1;為什么不報錯?float b = 1.0;為什么報錯? - 這個問題我也只知道一個很淺顯的答案:對于byte范圍內的值,JVM會自動將int(例如1)處理為byte,所以前者不報錯,而JVM表示并不想把doule處理成float,即使這個值在float的表示范圍內,
- 底層原因的話,猜測一下?可能是因為float和double是科學技術法表示的,轉起會惡心到JVM?望有大佬能夠明確一下答案,
1.0和1.1的愛恨情仇
- 我畫你猜,a和b那個是true?那個是false?:
boolean a = 1.0F == 1.0;
boolean b = 1.1F == 1.1;
- 答案是,a真b假,
- 哦喲,搞啥子哦?為啥子喃?簡單說一說:因為float和double都是近似值,并且精度不同,所以同樣是1.1,他們真實的值都有誤差,并且誤差程度不同,自然值就不同啦~而1.0之所以相同,純粹是巧合,因為剛好float和double都能精確表示1.0,
- 也就是說,99.9%的情況,float和double都是沒法相等的,不信的話,給你們個網址,自己試一試浮點數的誤差會有多大:https://www.h-schmidt.net/FloatConverter/IEEE754.html
==?
- 某清華學子說,我們小學2年級都學過:==比較的是地址,equals通常比較的是具體的內容(具體得看重寫的方法是怎么寫的),
- 這句話莫得毛病,但是點小有問題:基本資料型別的==比較,比的是數值;而參考型別比的是地址,不然為什么1.0 == 1.0F是true呢?是吧,哈哈哈,
boolean型別有多大?
- 這個問題標準答案是:沒有答案,對,就是這樣,因為JAVA官方沒有指明一個boolean占多大記憶體,但是大眾普遍認為大小是1個位元組,也不能算錯吧,但更合理的猜測,不應該是一個bit么?哈哈,
自動型別轉換的一個小知識
- 我們都知道,自動型別轉換遵從小轉大的原則,但是你知道么,這個小轉大,并不是完全指記憶體的大小,比如最特殊的一個:long型別可以自動轉換為float型別,
- 又有小老弟懵逼了,其實原因很簡單,long型別表示的范圍是
$-2^{63}$至$2^{63}-1$,而float的表示范圍大概是$\pm10^{38} \approx \pm2^{114}$,明顯float能表示的數字更大,所以能夠自動轉換,當然,自動轉換之后,也不可避免地會產生嚴重的誤差,
強制型別轉換如何取舍地?
byte a = 128;的結果是多少呢?這就要涉及到強轉的數值取舍了,小學二年級的時候都學過,128轉換為二進制為:0000 0000 1000 0000,- 因為byte型別就1個位元組,所以強轉之后,肯定需要舍棄一半,java在進行強制轉換時,舍棄的是高位部分,所以a的值最終為:1000 0000,也就是-128,
變數初始值
- 以前一直以為基本資料型別始侄訓有一個初始值,后來試了試,結果試試就逝世,
- 直接上結論吧
- 類成員變數(包括靜態的),無論是基礎資料型別還是參考資料型別,在不初始化的情況下都有初始值,基本資料型別除了char,其他的初始值都是0(或者0.0),char型別初始值是’’,而參考資料型別初始值統一為null,
- 而方法中的區域變數,不論是基本資料型別,還是參考型別,只要不初始化,直接編譯就報錯,
- 也就是說,下面這段代碼,列印結果是0,如果把te.wa換成age,則直接編譯報錯,
public class VarTest {
int wa;
public static void main(String[] args) {
int age;
VarTest te = new VarTest();
System.out.println(te.wa);
}
}
運算子中的冷知識
除以一個0.0試試
- 小學二年級就學過,java中除以0會報arithmeticExcetption,
- 那大家知不知道java能否除以0.0呢?答案是可以說可以,也可以說不可以~
- 例如:
5 / 0.0的結果是infinity;0 / 0.0的結果是NaN,顯然都不是一個正常的數字,所以我們肯定也不應該去除以0.0的哈,
賦值運算本身也會回傳一個值
- 什么意思呢?其實很(沒)簡(有)單(用),舉個栗子:
int a, b;
a = b = 3;
- 這段代碼執行完之后,a和b都被賦值為了3,因為
b = 3這個運算式的結果是3,
運算結果的型別
- 小伙伴們覺得下面這段代碼執行完后,a等于多少?
byte a = 10;
a = a + 2;
- 結果等于:報錯~哈哈哈,想不到吧,其實這是JAVA編譯器自動進行了優化處理,因為byte的運算(算術運算、移位運算等)的計算結果被編譯器自動轉換為了int,而int賦值給byte很顯然是會報錯的,
- 所以當我們真的想寫這樣一段邏輯的話,需要使用如下寫法:
byte a = 10;
a = (byte)(a + 2);
- 或者!還可以如下:
byte a = 10;
a += 2;
- 這就很騷了,原來
a += 2;等價的不是a = a + 2;,而是a = (byte)(a + 2);, - 同理,不光是+、也不光是short會有這種優化,可以自行嘗試一下其他地方是否也有如此特性,
如何高效(裝逼)地運算i*4?
- 大家都知道java中的位運算效率是最高的,因為計算機底層就是二進制,如果直接對二進制進行操作,java不需要再費精力去將變數與二進制進行轉換,
- 所以要高效地運算,最好的方法就是采用位運算,而移位運算子剛好就具備倍乘、倍除的特性,
- byte型別的9,二進制為0000 1001,左移一位,變為0001 0010,值為18,不用懷疑,就是二倍,同理,右移一位0000 0100,值為4,也不用懷疑,就是整數/2的結果,
- 所以的所以,如何高效運算i*4?答案是
i = i << 2;, - 當然,我勸大家可別在實際開發中這樣寫,壞處很明顯:容易被打…好吧,其實是可讀性太低,并且如果除符號位的最高位是1,左移之后的結果就很迷了,綜上,無用知識+1~
流程控制中的冷知識
for( ; ; ){}
- for( ; ; ){}陳述句可以正常運行,結果是無限回圈,
switch的default的穿透與短途效應(自己取的名字哈哈)
- 這個不算冷門吧,但switch確實用得太少了,導致這個問題之前并不知道,
- 眾所周知,switch售價2000元…說岔了,眾所周知,switch有一個default,用于匹配默認情況,但其實這句描述稍微有點問題,因為default匹配的其實不是默認情況,而是所有情況,什么意思呢?拿下面的例子說明:
int a = 1;
switch(a){
default:
System.out.print("default");
case 1:
System.out.print("1");
}
- 上面這行代碼執行結果是列印"default1",也就是說如果default在前面,后面就算有真正匹配的case,也會匹配進入default,這一點我就姑且稱之為短途效應吧~(名字取得好,逼格少不了)
- 至于穿透效應,其實就是帶不帶break;的問題,這里我就只是想說明一下,default陳述句塊如果放到前面,也是需要考慮帶不帶break的,
- 不過,說了這么多,有誰會在default后面寫case呢?(無用知識+1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/193497.html
標籤:其他