使用VMWare進行集群系統與Hadoop集群的搭建
- 集群系統的搭建
- 一、注意事項
- 二、復制虛擬機
- 三、給虛擬機設定靜態IP地址
- 四、給每臺虛擬機修改對應的主機名
- 五、為每臺虛擬機設定IP和域名映射
- 六、關閉防火墻與SELinux
- 七、設定虛擬機免密碼登錄
- 八、設定時鐘同步
- Hadoop集群搭建
- 1、下載并解壓Hadoop
- 2、下載并解壓JDK
- 3、配置系統環境變數
- 4、為相關的Hadoop檔案配置JAVA_HOME環境變數
- 5、配置HDFS
- 6、配置YARN
- 7、復制Hadoop安裝檔案到其他主機
- 8、格式化NameNode
- 9、啟動Hadoop
- 10、查看各個節點啟動的行程
集群系統的搭建
一、注意事項
1、確定Windows系統中所有關于VMWare的服務都已啟動
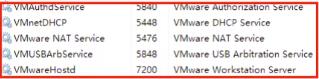
2、確認好VMWare生成的網關地址
查看步驟:
虛擬機中:編輯 --> 虛擬網路編輯器 --> VMnet8 --> NAT設定
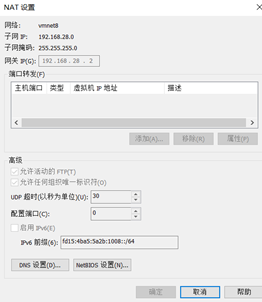
3、確認VMnet8網卡已經配置好了IP地址和DNS(域名服務器)
查看步驟:
電腦右下角的wifi圖示點擊右鍵 --> 打開網路和Internet 設定 --> 以太網 --> 更改配接器選項 --> 找到VMnet8后點擊右鍵,選擇屬性 --> 雙擊Internet協議版本4 --> 選擇“使用下面的IP地址”(本質上就算配置網卡的IP地址)

二、復制虛擬機
先安裝好一臺虛擬機,再將那臺虛擬機的檔案復制幾份后,將檔案名進行更改即可
進入檔案,點擊格式名為.vmx的檔案打開虛擬機
注意下記憶體的分配,以16G記憶體,創建3臺虛擬機為例,(16 -4) / 3 = 4
三、給虛擬機設定靜態IP地址
使用下方命令打開虛擬機的網卡檔案
vim /etc/sysconfig/network-scripts/ifcfg-ens33
配置后的檔案如下:
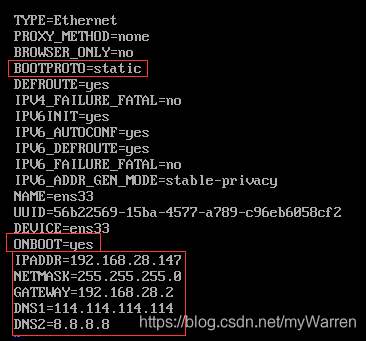
接下來對添加和修改的部分做下解釋:
BOOTPROTO屬性可以有兩種選項:dhcp和static
1、dhcp表示centos7獲取IP地址采用動態獲取的方式,使用dhcp的前提是保證路由器已經開啟了DHCP
2、static表示centos7獲取IP地址采用靜態獲取的方式
ONBOOT屬性,centos7默認是關閉的,需要手動改成yes才能進行網路連接
IPADDR屬性為靜態獲取IP地址時所使用的IP地址
NETMASK為子網掩碼
GATEWAY為網關IP,這個可以從上述的注意事項中的第二項中查看如何獲取
DNS1為第一個域名服務器,這個可以去網上百度
DNS2為第二個域名服務器
四、給每臺虛擬機修改對應的主機名
下面介紹幾條指令,可以用于操作主機名
hostname # 單獨使用可以查看當前主機名
hostname 主機名 # 可以臨時修改主機名
hostnamectl # 可以查看主機資訊
hostnamectl set-hostname 主機名 # 可以永久修改主機名
此處我為我的三臺虛擬機分別設定主機名為node01、node02、node03(下列指令分別在不同的三臺虛擬機里運行)
hostnamectl set-hostname node01
hostnamectl set-hostname node02
hostnamectl set-hostname node03
五、為每臺虛擬機設定IP和域名映射
使用如下命令打開 /etc/hosts檔案
vim /etc/hosts
在該檔案中添加如下陳述句:
192.168.28.147 node01 node01.hadoop.com
192.168.28.148 node02 node02.hadoop.com
192.168.28.149 node03 node03.hadoop.com
對上列陳述句解釋下:上列陳述句的列對應是 主機IP地址 主機名 域名
沒域名可以不用寫
六、關閉防火墻與SELinux
關閉防火墻指令如下:
systemctl stop firewalld # 關閉防火墻,但這只是暫時的,一當開機重啟后,防火墻會再次打開
systemctl disable firewalld # 永久關閉防火墻
關閉SELinux的方法如下:
vim /etc/selinux/config
SELINUX=disabled # 關閉SELinux
這里解釋下什么是SELinux,所謂的SELinux是一種Linux的安全子系統,Linux的權限管理是針對檔案而非行程的,因此,如果root用戶啟動了某項行程的話,該行程便可操作任何一個檔案,因為是root用戶創建了它,它就相當于有了root用戶的權限,這會存在著很高的安全風險,因此,我們使用SELinux增加對行程的限制,使得行程只能在允許的范圍內操作資源
接下來再解釋下SELinux的三大取值,也是它的三種作業模式:
1、enforcing強制模式(如果操作違反了SELinux的規則,會直接將操作禁止,并且把該行為記錄到日志中)
2、permissive寬容模式(如果操作違反了SELinux的規則,不會直接制止,但是會把此次行為記錄到日志中)
3、disabled關閉SELinux
七、設定虛擬機免密碼登錄
執行此操作,是為了避免從某個節點啟動另一個節點時需要輸入密碼帶來的煩惱
免密SSH登錄的原理:
1、首先需要在B節點配置A節點的公鑰
2、A節點請求B節點要求登錄
3、B節點使用A節點的公鑰,加密一段隨機文本
4、A節點使用私鑰解密,并發回給B節點
5、B節點驗證文本是否正確
接下來是如何實作虛擬機免密碼登錄的操作:
1、分別在三個節點中使用如下命令,以在三個節點下生成公鑰和私鑰:
ssh-keygen -t rsa # 使用rsa加密演算法生成公鑰和私鑰
2、使用以下命令將三臺主機的公鑰拷貝到一臺主機上去,這里使用node01主機:
ssh-copy-id node01
3、在獲得三臺主機的公鑰的主機上執行如下操作,以將第一臺主機的公鑰拷貝到另外幾臺主機上去:
scp /root/.ssh/authorized_keys node02:/root/.ssh
scp /root/.ssh/authorized_keys node03:/root/.ssh
注意,因為我是直接使用root用戶來構建集群系統的,生成密鑰也是用root用戶在root的根目錄下生成的,所有.ssh所在位置是 /root/.ssh,如果不是root用戶的話,.ssh所在的路徑應該是 /home/用戶名/.ssh
4、查看每個節點的 .ssh目錄下是否生成了 known_hosts檔案,這是用于保存可以識別的主機的檔案
5、使用 ssh 主機名便可以進行免密登錄了
八、設定時鐘同步
這是為了防止三個節點因為時間的不同步而出現應用程式運行的混亂,從而造成不可預知的問題,舉個簡單的例子,當我們使用HBase時,如果節點之間時間差別過大的話,就會導致HBase掛掉,下面介紹時鐘同步的方法:
1、安裝ntp
yum -y install ntp
2、通過定時任務啟動時鐘同步
執行下列命令:
crontab -e
彈出vim編輯框后輸入下列陳述句保存后即可實作時鐘同步:
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com
Hadoop集群搭建
1、下載并解壓Hadoop
如果沒有Hadoop檔案,可以使用如下命令下載Hadoop的壓縮包:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
如果Windows上有下載Hadoop的壓縮包,可以使用 rz命令將壓縮包上傳到centos7中,該命令的安裝如下:
yum -y install lrzsz # 安裝 rz 命令
rz # 打開上傳界面,進行檔案從Windows到Linux的上傳
解壓Hadoop的命令如下:
tar -zxf hadoop-2.9.2.tar.gz -C /usr/local # 將Hadoop解壓到 /usr/local 中
2、下載并解壓JDK
如果沒有JDK檔案,可以執行如下命令在線下載:
yum -y install java-1.8.0-openjdk*
檔案下載后一般存盤于 /usr/lib/jvm中,如果要想具體知道檔案下載后存盤在哪,可以使用如下命令:
ls -l /etc/alternatives
找到java的軟連接,該軟連接所指向的檔案位置就是檔案下載后存盤的位置
如果是通過 rz 命令上傳的,一般將檔案解壓到 /usr/lib 中,如下:
tar -zxf jdk-8u271-linux-x64.tar.gz -C /usr/lib
注意,我這里用于代碼演示的兩jdk包是不同的,以下均采用 java-1.8.0-openjdk*
3、配置系統環境變數
使用如下命令打開系統環境變數的組態檔:
vim /etc/profile
在檔案的末尾添加如下內容,可以直接在命令模式下鍵入 G 直接跳入最后一行(以下命令均為手打鍵入,可能會輸錯,但是大體就是這樣):
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
輸入完畢后保存退出,使用如下命令使檔案生效:
. /etc/profile # 或者使用 source /etc/profile也行, . 是 source的縮寫
檢查Hadoop環境變數是否配置成功(配置Hadoop環境變數的原因在于,配置完后可以方便地在任意目錄下執行hadoop命令,而不需要進入到hadoop的安裝目錄中使用 ./ 來運行),直接鍵入 hadoop 命令即可,出現如下情況即表明配置成功:
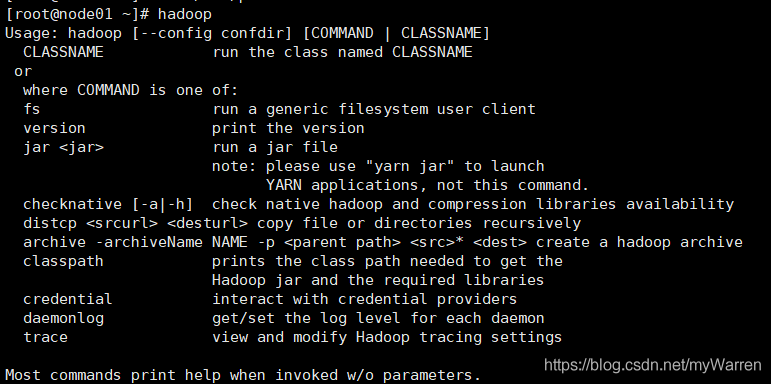
4、為相關的Hadoop檔案配置JAVA_HOME環境變數
使用如下命令,進入 hadoop 檔案
cd /usr/local/hadoop-2.9.2/etc/hadoop
對下方三個檔案分別使用 vim 在檔案末添加陳述句
vim hadoop-env.sh
vim mapred-env.sh
vim yarn-env.sh
每個檔案末添加的陳述句:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64
5、配置HDFS
使用 vim 打開 core-site.xml 檔案(該檔案仍在上方目錄中)
添加如下陳述句:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/server/hadoop-2.9.2/tmp</value>
</property>
</configuration>
對上方的陳述句進行下解釋:
1、fs.defaultFS:這是HDFS的默認訪問路徑,也是NameNode的訪問地址
2、hadoop.tmp.dir:這是Hadoop資料檔案的存放目錄,如果不配置該引數,則會默認指向 /tmp,而 /tmp目錄在重啟后會被自動清空
使用 vim修改 hdfs-site.xml檔案,加入如下內容:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property><!--不用檢查用戶權限-->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/server/hadoop-2.9.2/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/server/hadoop-2.9.2/tmp/dfs/data</value>
</property>
</configuration>
對上方陳述句進行下解釋:
1、dfs.replication:檔案在HDFS系統中的副本數
2、dfs.namenode.name.dir:NameNode節點資料在本地檔案系統中的存放位置
3、dfs.datanode.data.dir:DataNode節點資料在本地檔案系統中的存放位置
4、dfs.permissions.enabled:用來決定是否檢查用戶權限
用 vim 打開 slaves檔案,加入如下內容(主機名):
node01
node02
node03
注意,如果使用Hadoop3.x版本的,則修改workers檔案,增加內容一樣
6、配置YARN
所需修改的檔案仍在上方檔案所在目錄中
先將 mapred-site.xml.template 檔案重命名為 mapred-site.xml,重命名方法如下(Hadoop 3.x已經默認將名字改過,就不用改了):
mv mapred-site.xml.template mapred-site.xml
然后對該檔案進行修改,添加如下陳述句:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
解釋下該陳述句的意思,該陳述句指定了mapreduce任務的執行框架為yarn
接著再打開 yarn-site.xml 檔案,添加如下內容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node01:8032</value>
</property>
</configuration>
解釋下上方內容:
1、yarn.nodemanager.aux-services:這是NodeMananger上運行的附屬服務,我們需要將其配置為 mapreduce_shuffle,只有這樣,我們才能運行MapReduce程式,至于為什么需要它,之后關于mapreduce的博客中會介紹,YARN提供了該配置項用于在NodeManager上擴展自定義服務,MapReduce的Shuffle功能正是一種擴展服務
2、yarn.resourcemanager.address:指定ResourceManager所在的節點與訪問埠,默認為8032,此處指定ResourceManager運行在node01節點,若不添加上述內容,ResourceManager將默認在執行YARN啟動命令(start-yarn.sh)的節點上啟動
7、復制Hadoop安裝檔案到其他主機
scp -r /usr/local/hadoop-2.9.2 node02:/usr/local/
scp -r /usr/local/hadoop-2.9.2 node03:/usr/local/
直接復制就可以減少了再在另外兩個節點中配置的麻煩
8、格式化NameNode
在啟動Hadoop之前,需要先格式化NameNode,其目的是初始化HDFS檔案系統中的一些目錄和檔案,我們在node01節點上執行以下命令,進行格式化操作:
hadoop namenode -format
格式化成功后會生成 /usr/local/hadoop-2.9.2/tmp/dfs/name/current 目錄,該目錄中則會生成用于存盤HDFS檔案系統元資料資訊的檔案 fsimage
9、啟動Hadoop
在node01節點上執行以下命令,啟動Hadoop集群,命令在 /usr/local/hadoop-2.9.2/sbin中
./start-all.sh
以下闡述下一些配置不進行會產生的結果:
1、若不配置SecondaryNameNode所在的節點,將默認在執行HDFS啟動命令(start-dfs.sh)的節點上啟動
2、若不配置ResourceManager所在的節點,將默認在執行YARN啟動命令(start-yarn.sh)的節點上啟動;若配置了ResourceManager所在的節點,則必須在所配置的節點啟動YARN,否則在其他節點啟動時將拋出例外
3、NodeManager無需配置,會與DataNode在同一個節點上,以獲取任務執行時的資料本地優勢,即有DataNode的節點就會有NodeManager
我在啟動Hadoop 3.x時有遇到個問題,就是啟動Hadoop是出現如下報錯:
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
我暫時將解決方法寫在下方,由于具體源由我還沒弄清,就暫時不是很詳細,補充留在下篇博客
修改下面四個檔案
1、對于 start-dfs.sh和 stop-dfs.sh檔案,在第一行非注釋代碼的上一行添加如下代碼:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2、對于 start-yarn.sh 和 stop-yarn.sh檔案,在第一行非注釋代碼的上一行添加如下代碼:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
之后重新 ./start-all.sh即可
10、查看各個節點啟動的行程
[root@node01 sbin]# jps
15088 NodeManager
14786 SecondaryNameNode
1987 QuorumPeerMain
14617 DataNode
14941 ResourceManager
15374 Jps
14479 NameNode
[root@node02 ~]# jps
15697 QuorumPeerMain
20611 Jps
20360 DataNode
20475 NodeManager
[root@node03 ~]# jps
20548 DataNode
20663 NodeManager
20793 Jps
15789 QuorumPeerMain
注意,如果jps時沒有出現DataNode有可能是因為再次使用 hadoop namenode -format 后,我們沒有將 /usr/local/hadoop-2.9.2/tmp/dfs/data/current中的資料洗掉,并且每個節點中的都要洗掉
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/194030.html
標籤:其他