標題無意冒犯,就是覺得這個廣告挺好玩的
上面這張思維導圖喜歡就拿走,反正我也學不了這么多
文章目錄
- 前言
- 歡迎來到我們的圈子
- 初見爬蟲
- 為什么是爬蟲
- 通用爬蟲架構
- 爬蟲的作業步驟
- 優秀爬蟲的特性
- 1.高性能
- 2.可擴展性
- 3.健壯性
- 4.友好性
- 爬蟲初體驗
- requests.get()
- Response物件常用的四個屬性
- 我國有一部完整的法律
前言
前期回顧:我要偷偷的學Python,然后驚呆所有人(第六天)
前一天說了,我們今天要進入到爬蟲的學習,對,今天我們開始爬

本系列文默認各位有一定的C或C++基礎,因為我是學了點C++的皮毛之后入手的Python,這里也要感謝齊鋒學長送來的支持,
本系列文默認各位會百度,學習‘模塊’這個模塊的話,還是建議大家有自己的編輯器和編譯器的,上一篇已經給大家做了推薦啦?
我要的不多,點個關注就好啦
然后呢,本系列的目錄嘛,說實話我個人比較傾向于那兩本 Primer Plus,所以就跟著它們的目錄結構吧,
本系列也會著重培養各位的自主動手能力,畢竟我不可能把所有知識點都給你講到,所以自己解決需求的能力就尤為重要,所以我在文中埋得坑請不要把它們看成坑,那是我留給你們的鍛煉機會,請各顯神通,自行解決,
如果是小白的話,可以看一下下面這一段:
歡迎來到我們的圈子
我建了一個Python學習答疑群,有興趣的朋友可以了解一下:這是個什么群
直通群的傳送門:傳送門
初見爬蟲
我和你們大部分人都一樣,首次自己玩爬蟲,以前都是被人爬的那種,
不過呢,我也不是啥大佬,所以也不會一上來就一大堆特別高大上的爬蟲技巧呈現出來,我們一步一步來吧,
網路爬蟲,也叫網路蜘蛛(Web Spider),它根據網頁地址(URL)爬取網頁內容,而網頁地址(URL)就是我們在瀏覽器中輸入的網站鏈接,比如:https://www.baidu.com/,它就是一個URL,
為什么是爬蟲
通用搜索引擎的處理物件是互聯網網頁,目前互聯網網頁的數量已達百億,所以搜索引擎首先面臨的問題是:如何能夠設計出高效的下載系統,以將如此海量的網頁資料傳送到本地,在本地形成互聯網網頁的鏡像備份,
網路爬蟲能夠起到這樣的作用,完成此項艱巨的任務,它是搜索引擎系統中很關鍵也很基礎的構件,
舉個很常見的栗子吧:百度,
百度這家公司會源源不斷地把千千萬萬個網站爬取下來,存盤在自己的服務器上,你在百度搜索的本質就是在它的服務器上搜索資訊,你搜索到的結果是一些超鏈接,在超鏈接跳轉之后你就可以訪問其它網站了,
通用爬蟲架構
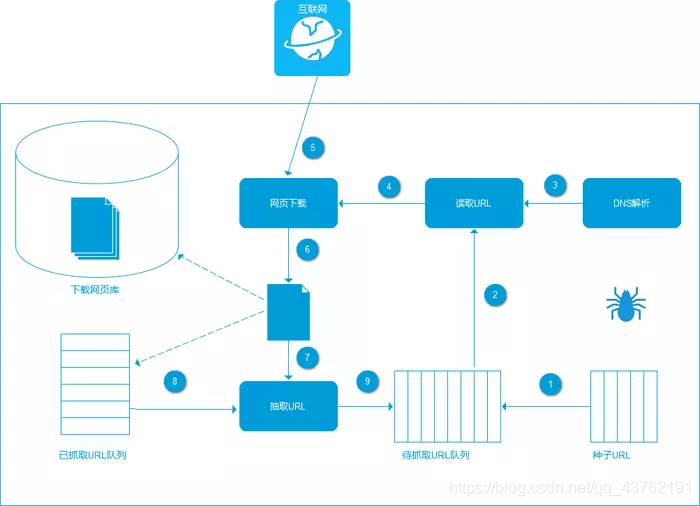
好,上面這張圖能看明白嗎?如果不能的話,我們來再看些用戶訪問網站的流程圖:
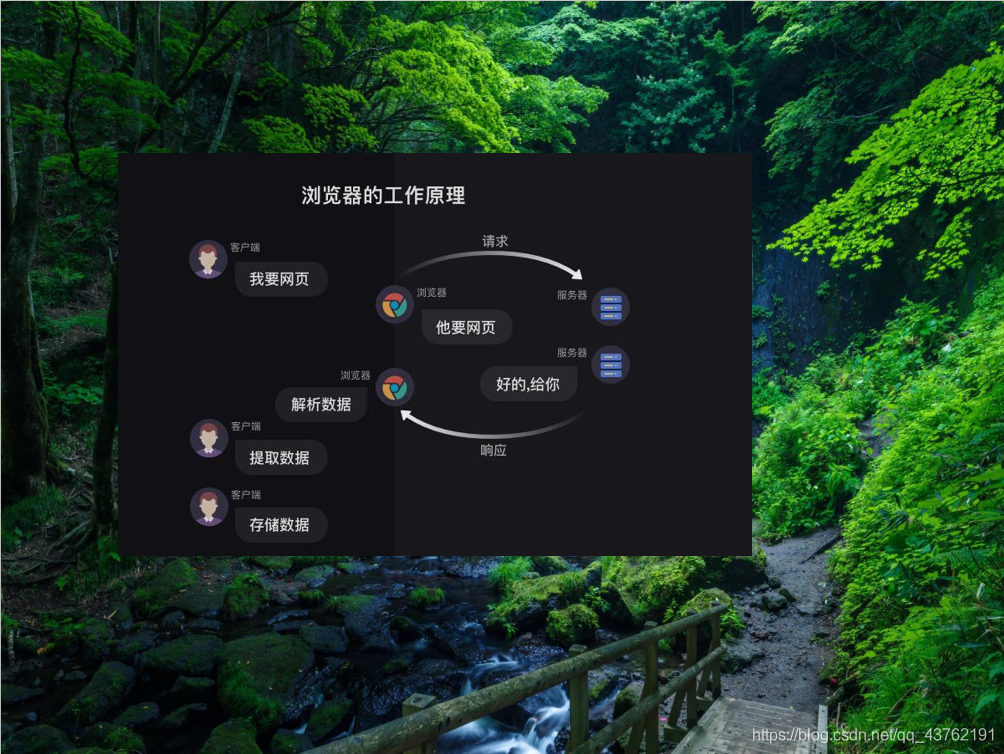
這是一個人機互動的流程,那么我們再來看看爬蟲在這個倍訓里面能夠取代掉哪些作業:

是吧,非常符合我們的“人工智能”的特性,解放我們的雙手,
爬蟲的作業步驟
第1步:獲取資料,爬蟲程式會根據我們提供的網址,向服務器發起請求,然后回傳資料,
第2步:決議資料,爬蟲程式會把服務器回傳的資料決議成我們能讀懂的格式,
第3步:提取資料,爬蟲程式再從中提取出我們需要的資料,
第4步:儲存資料,爬蟲程式把這些有用的資料保存起來,便于你日后的使用和分析,
這就是爬蟲的作業原理啦,無論之后的學習內容怎樣變化,其核心都是爬蟲原理,
本章旨在直截了當的認識爬蟲,所以過多的不必要的概念就不引伸了,
優秀爬蟲的特性
話說優秀的代碼好像都是這些特性,
不過有人能說出優秀架構的特性嗎?讓我眼前一亮,驚呼一聲:“大佬,帶我”
1.高性能
這里的性能主要是指爬蟲下載網頁的抓取速度,常見的評價方式是以爬蟲每秒能夠下載的網頁數量作為性能指標,單位時間能夠下載的網頁數量越多,爬蟲的性能越高,
要提高爬蟲的性能,在設計時程式訪問磁盤的操作方法(磁盤IO)及具體實作時資料結構的選擇很關鍵,比如對于待抓取URL佇列和已抓取URL佇列,因為URL數量非常大,不同實作方式性能表現迥異,所以高效的資料結構對于爬蟲性能影響很大,
2.可擴展性
即使單個爬蟲的性能很高,要將所有網頁都下載到本地,仍然需要相當長的時間周期,為了能夠盡可能縮短抓取周期,爬蟲系統應該有很好地可擴展性,即很容易通過增加抓取服務器和爬蟲數量來達到此目的,
目前實用的大型網路爬蟲一定是分布式運行的,即多臺服務器專做抓取,每臺服務器部署多個爬蟲,每個爬蟲多執行緒運行,通過多種方式增加并發性,
對于巨型的搜索引擎服務商來說,可能還要在全球范圍、不同地域分別部署資料中心,爬蟲也被分配到不同的資料中心,這樣對于提高爬蟲系統的整體性能是很有幫助的,
3.健壯性
爬蟲要訪問各種型別的網站服務器,可能會遇到很多種非正常情況:比如網頁HTML編碼不規范、 被抓取服務器突然死機,甚至爬到陷阱里邊去了等,爬蟲對各種例外情況能否正確處理非常重要,否則可能會不定期停止作業,這是無法忍受的,
從另外一個角度來講,假設爬蟲程式在抓取程序中死掉,或者爬蟲所在的服務器宕機,健壯的爬蟲應能做到:再次啟動爬蟲時,能夠恢復之前抓取的內容和資料結構,而不是每次都需要把所有作業完全從頭做起,這也是爬蟲健壯性的一種體現,
4.友好性
爬蟲的友好性包含兩方面的含義:一是保護網站的部分私密性;另一是減少被抓取網站的網路負載,爬蟲抓取的物件是各型別的網站,對于網站所有者來說,有些內容并不希望被所有人搜到,所以需要設定協議,來告知爬蟲哪些內容是不允許抓取的,目前有兩種主流的方法可達到此目的:爬蟲禁抓協議和網頁禁抓標記,
這一點后面會再詳細說明,
爬蟲初體驗
網路爬蟲的第一步就是根據URL,獲取網頁的HTML資訊,在Python3中,可以使用urllib.request和requests進行網頁爬取,
urllib庫是python內置的,無需我們額外安裝,只要安裝了Python就可以使用這個庫,
requests庫是第三方庫,需要我們自己安裝,
requests庫的基礎方法如下:
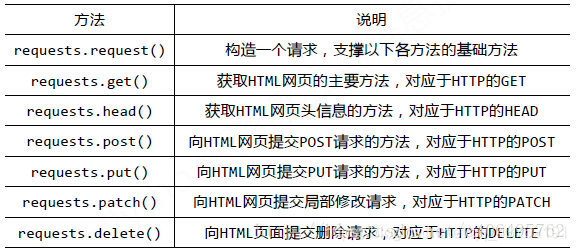
requests.get()
看一段偽代碼:
import requests
#引入requests庫
res = requests.get('URL')
#requests.get是在呼叫requests庫中的get()方法,
#它向服務器發送了一個請求,括號里的引數是你需要的資料所在的網址,然后服務器對請求作出了回應,
#我們把這個回應回傳的結果賦值在變數res上,
剛剛我還在群里跟他們說,學習Python最重要的是打基礎,從資料型別,資料結構開始,
那我們就來看看這爬蟲獲取資料的回傳值是個什么資料型別,
先隨便找個網址吧,要不就開頭那個小烏龜的網址吧:
http://photogz.photo.store.qq.com/psc?/V12wi4eb4HvNdv/ruAMsa53pVQWN7FLK88i5qLH0twfxCgrwzDJPH6IRZadTdk*QTPnqFYrVt5PNiU7vBOh1cvefk4UXqNZcMdzLWowRX1pF4GqWoBZ7YPq5AQ!/b&bo=eAFyAXgBcgERECc!
網址是長了點哈,不過可以實驗的,
import requests
res = requests.get('URL')
print(type(res))
#列印變數res的資料型別
結果:<class ‘requests.models.Response’>
Response物件常用的四個屬性
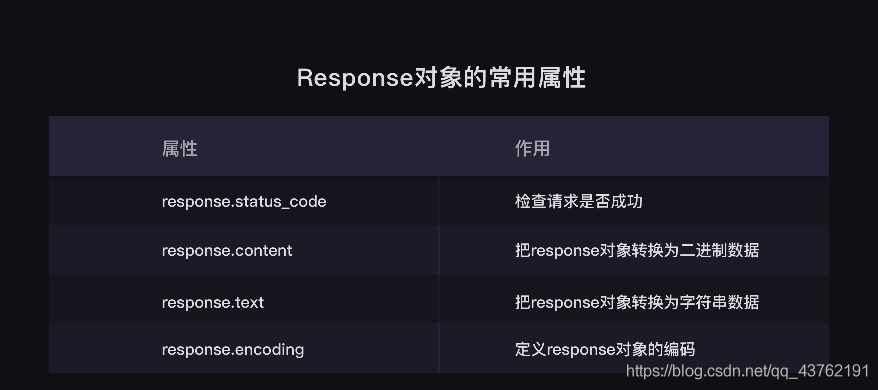
首先是我們的status_code,它是一個很常用的屬性,用于檢查請求出否成功,可以把它的回傳值列印出來看,
接著的屬性是response.content,它能把Response物件的內容以二進制資料的形式回傳,適用于圖片、音頻、視頻的下載,看個例子你就懂了,
來我們把那個小烏龜爬下來,我放在我的QQ空間里面的:
import requests
res = requests.get('http://photogz.photo.store.qq.com/psc?/V12wi4eb4HvNdv/ruAMsa53pVQWN7FLK88i5qLH0twfxCgrwzDJPH6IRZadTdk*QTPnqFYrVt5PNiU7vBOh1cvefk4UXqNZcMdzLWowRX1pF4GqWoBZ7YPq5AQ!/b&bo=eAFyAXgBcgERECc!')
#發出請求,并把回傳的結果放在變數res中
pic=res.content
#把Reponse物件的內容以二進制資料的形式回傳
photo = open('烏龜.jpg','wb')
#新建了一個檔案ppt.jpg,這里的檔案沒加路徑,它會被保存在程式運行的當前目錄下,
#圖片內容需要以二進制wb讀寫,你在學習open()函式時接觸過它,
photo.write(pic)
#獲取pic的二進制內容
photo.close()
#關閉檔案
大家也可以去爬一爬自己空間里面的小照片,
有的朋友會問:那我要怎么知道我的小照片網址呢?
其實也好辦:右擊小照片,新建標簽頁打開,網址不就有了嗎,
再不行,你直接把這篇博客上的小照片拖一下嘛,拖到新視窗去,網址就有了,
好,今天的實操大概就在這里了,
講完了response.content,繼續看response.text,這個屬性可以把Response物件的內容以字串的形式回傳,適用于文字、網頁源代碼的下載,
看清楚啊,是源代碼,
來,隨便找個網址,比方說我這篇博客的網址,咱來體驗一下:
import requests
#參考requests庫
res = requests.get('https://editor.csdn.net/md?articleId=109320746')
novel=res.text
#把Response物件的內容以字串的形式回傳
k = open('《第七天》.txt','a+')
#創建一個名為《第七天》的txt檔案,指標放在檔案末尾,追加內容
k.write(novel)
#寫進檔案中
k.close()
#關閉檔案
接下來,我們看最后一個屬性:response.encoding,它能幫我們定義Response物件的編碼,
首先,目標資料本身是什么編碼是未知的,用requests.get()發送請求后,我們會取得一個Response物件,其中,requests庫會對資料的編碼型別做出自己的判斷,但是!這個判斷有可能準確,也可能不準確,
如果它判斷準確的話,我們列印出來的response.text的內容就是正常的、沒有亂碼的,那就用不到res.encoding;如果判斷不準確,就會出現一堆亂碼,那我們就可以去查看目標資料的編碼,然后再用res.encoding把編碼定義成和目標資料一致的型別即可,
講的有點累了啊,咱再提一點,
我國有一部完整的法律
其實我國關于爬蟲的法律還在完善當中啦,所以嘛,要爬趁早,
通常情況下,服務器不太會在意小爬蟲,但是,服務器會拒絕頻率很高的大型爬蟲和惡意爬蟲,因為這會給服務器帶來極大的壓力或傷害,
不過,服務器在通常情況下,對搜索引擎是歡迎的態度(剛剛講過,谷歌和百度的核心技術之一就是爬蟲),當然,這是有條件的,而這些條件會寫在Robots協議,
Robots協議是互聯網爬蟲的一項公認的道德規范,它的全稱是“網路爬蟲排除標準”(Robots exclusion protocol),這個協議用來告訴爬蟲,哪些頁面是可以抓取的,哪些不可以,
如何查看網站的robots協議呢,很簡單,在網站的域名后加上/robots.txt就可以了,
協議里最常出現的英文是Allow和Disallow,Allow代表可以被訪問,Disallow代表禁止被訪問,
工具在你手中,如何利用它是你的選擇,當你在爬取網站資料的時候,別忘了先看看網站的Robots協議是否允許你去爬取,
同時,限制好爬蟲的速度,對提供資料的服務器心存感謝,避免給它造成太大壓力,維持良好的互聯網秩序,也是我們該做的事,
以上,就是我們今天要講的內容啦,下一次我們就來對那些網頁進行分析,獲取網頁中我們要的東西,


轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/197087.html
標籤:其他