系列文章
- 實時存盤引擎和實時計算引擎
- 美團點評 Hadoop/Spark 系統實踐
- 美團大資料查詢技術
文章目錄
- 系列文章
- 一、應用場景
- 二、系統架構
- 2.1.系統架構 Review - Presto
- 2.2.分布式 OLAP 系統擴展技術
- 2.2.1 Kylin 與 Cube 預聚合
- 2.2.2 Druid 與 流式寫入隔離,維度列倒排
- 2.2.3 Clickhouse 與 SIMD
- 2.2.4 Doris 與 我們的融合計劃
- 三、改造案例
- 3.1 Presto on Yarn
- 3.2 統一ADhoc查詢One SQL
- 3.3 統一OLAP建設
- 3.4 資料庫對比方法
本文主要涉及資料資源與服務中的資料產品和資料服務部分,
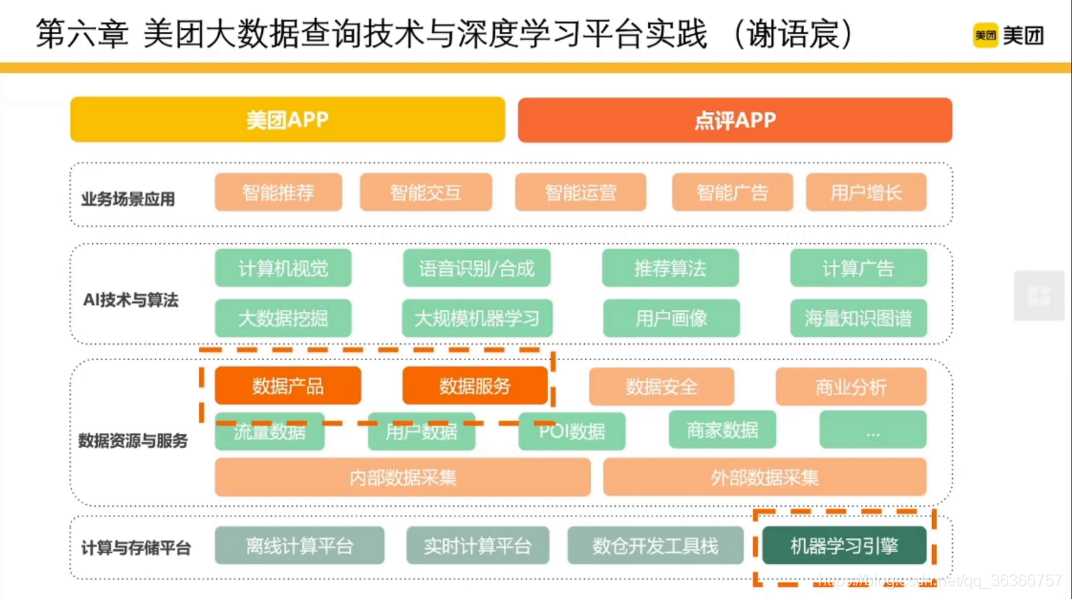
本文目錄如下:

一、應用場景
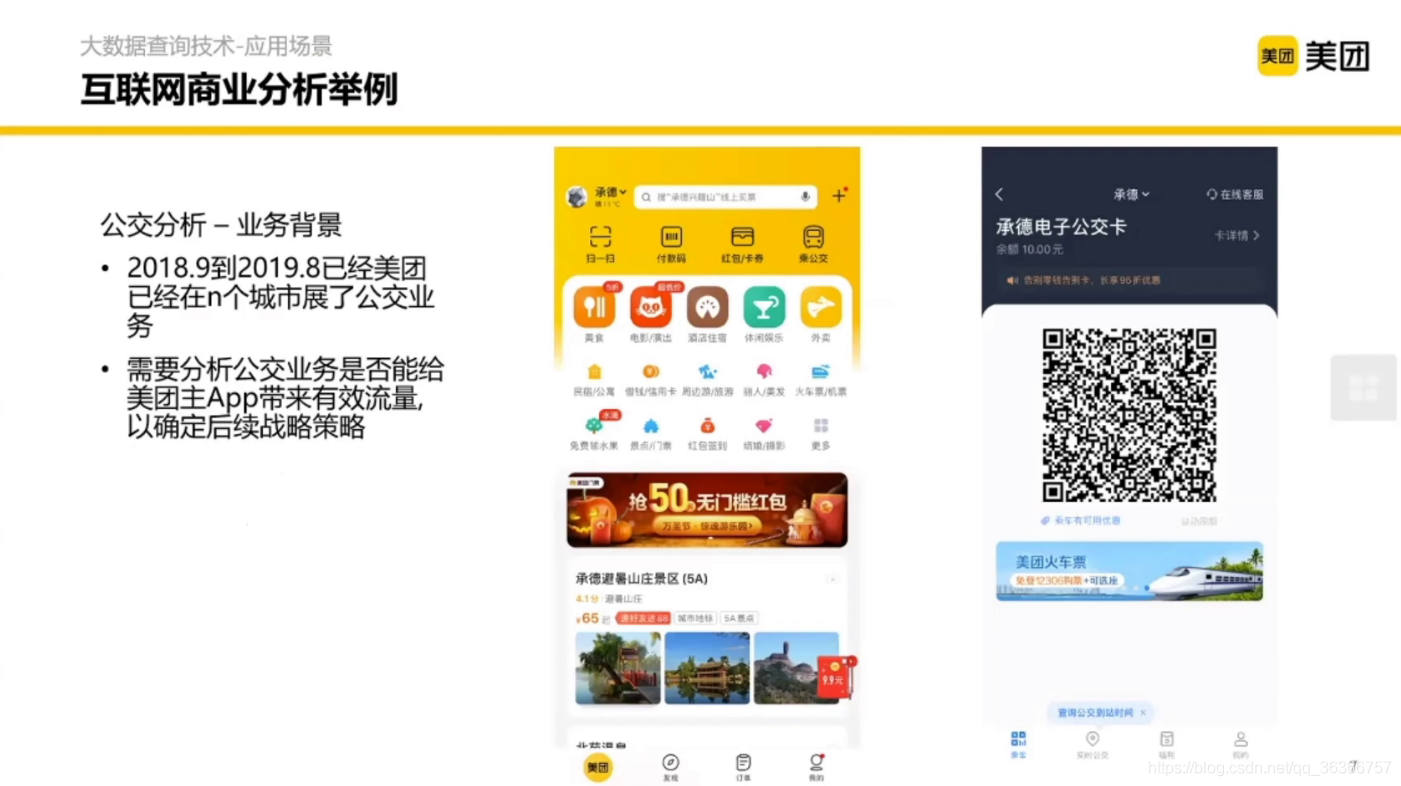
背景:電子公交卡的業務試點,想要了解這個業務對整個美團 App 有什么樣的影響,
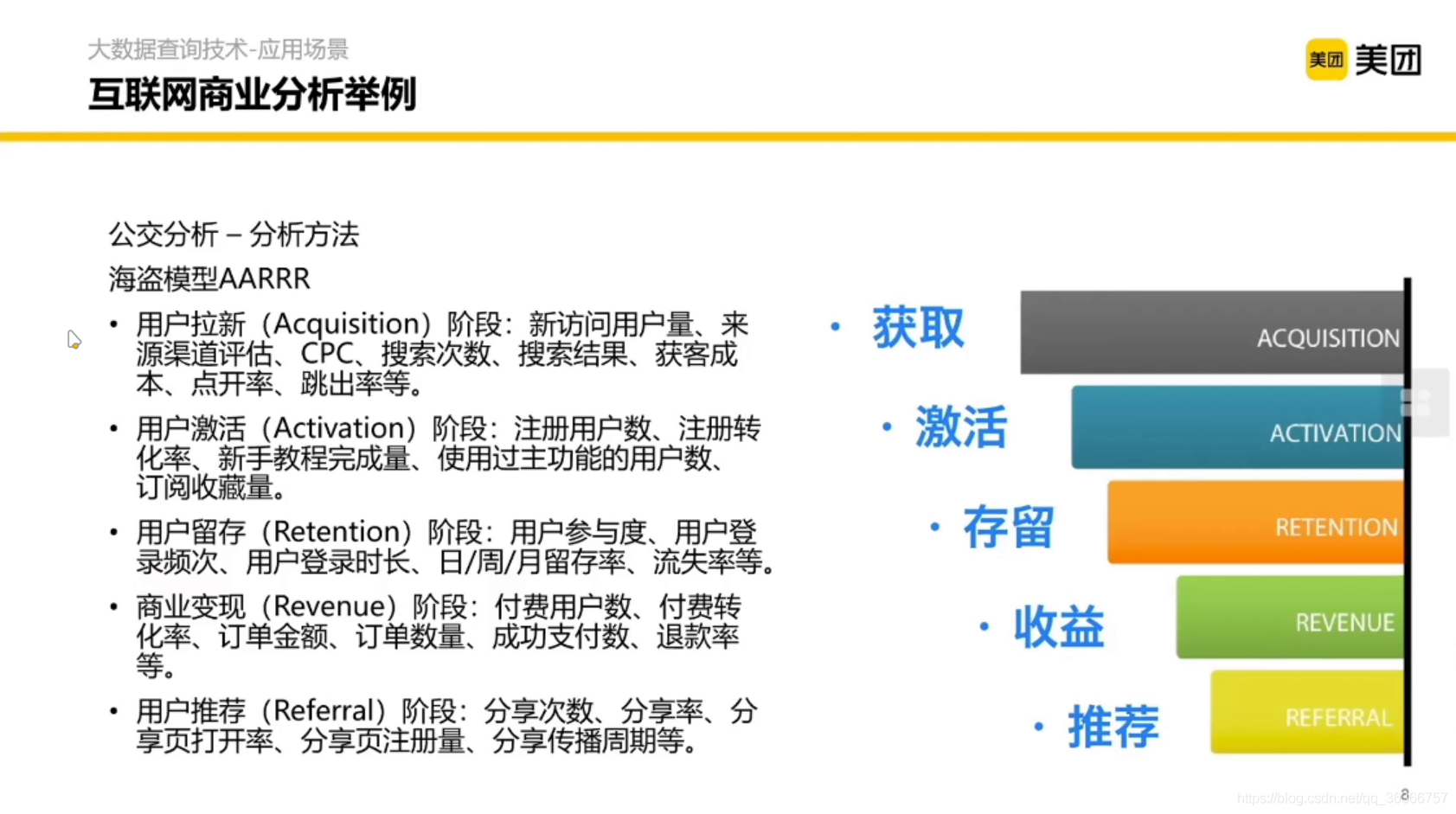
《增長黑客》中提到了一個海盜模型的方法,本質上是對流量的轉換做一個漏斗形的拆解和分析,包含了從獲取用戶到用戶轉化和激活的步驟和對應的分析方法,
但是僅有方法是不夠的,還要有對應的資料支撐,那資料是怎么組織的呢?這里分為5個部分,
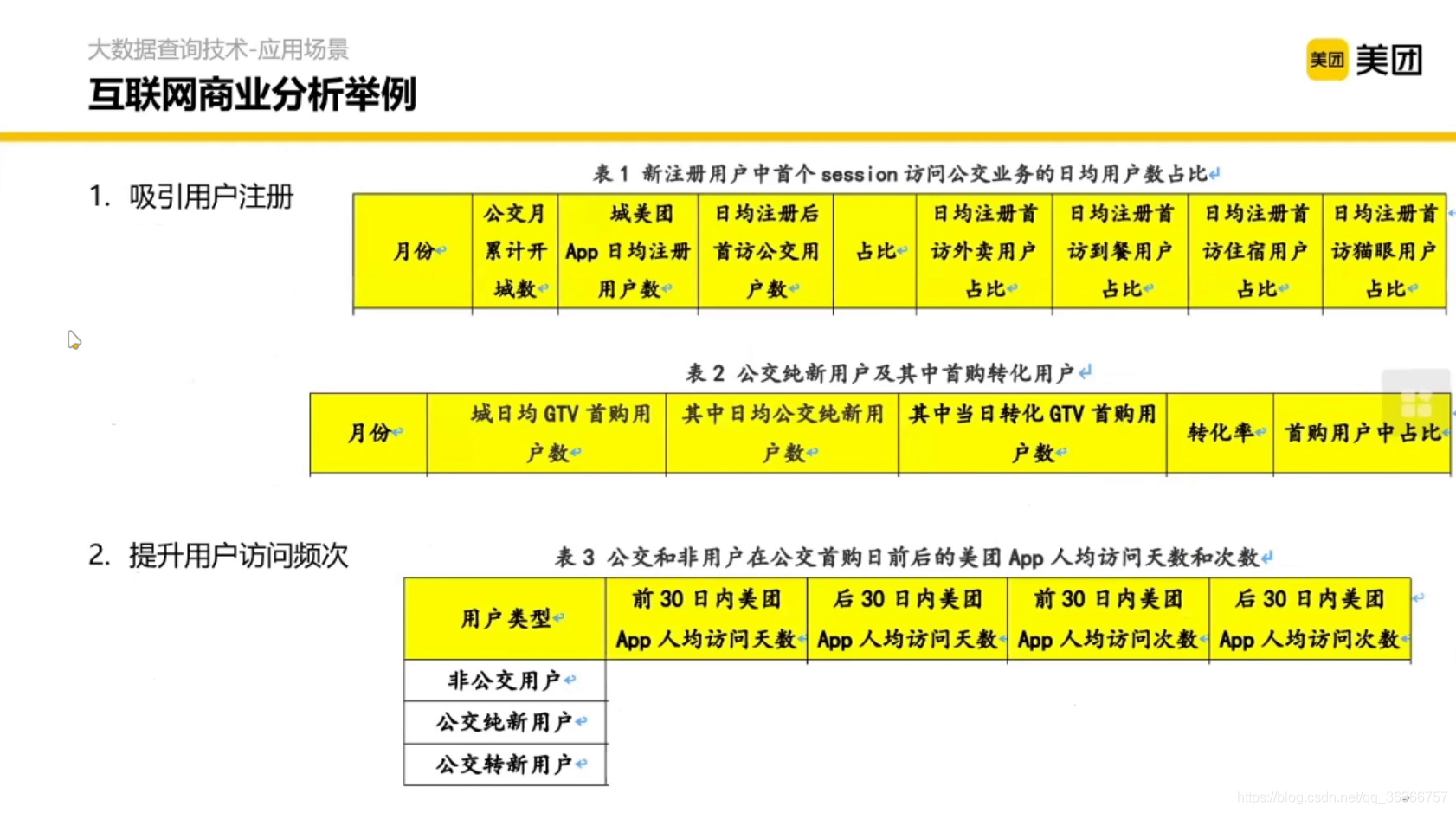
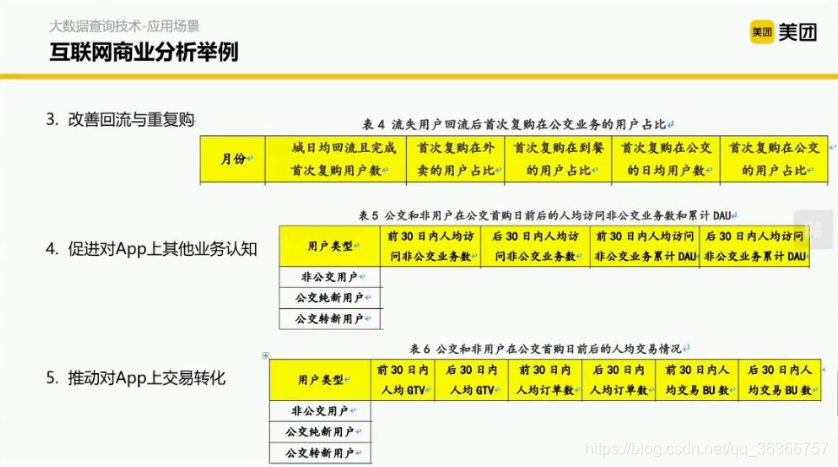
那我們要做這些分析的時候該怎么辦呢?
就要看下面這種 SQL,
先看 FROM,關聯訂單表、城市表和城市維度表
然后看 WHERE,選出來在 18 年 8 月到 19 年 8 月之間的公交業務和復購的訂單
再看 GROUP BY 和 SUM,基本就清楚了,

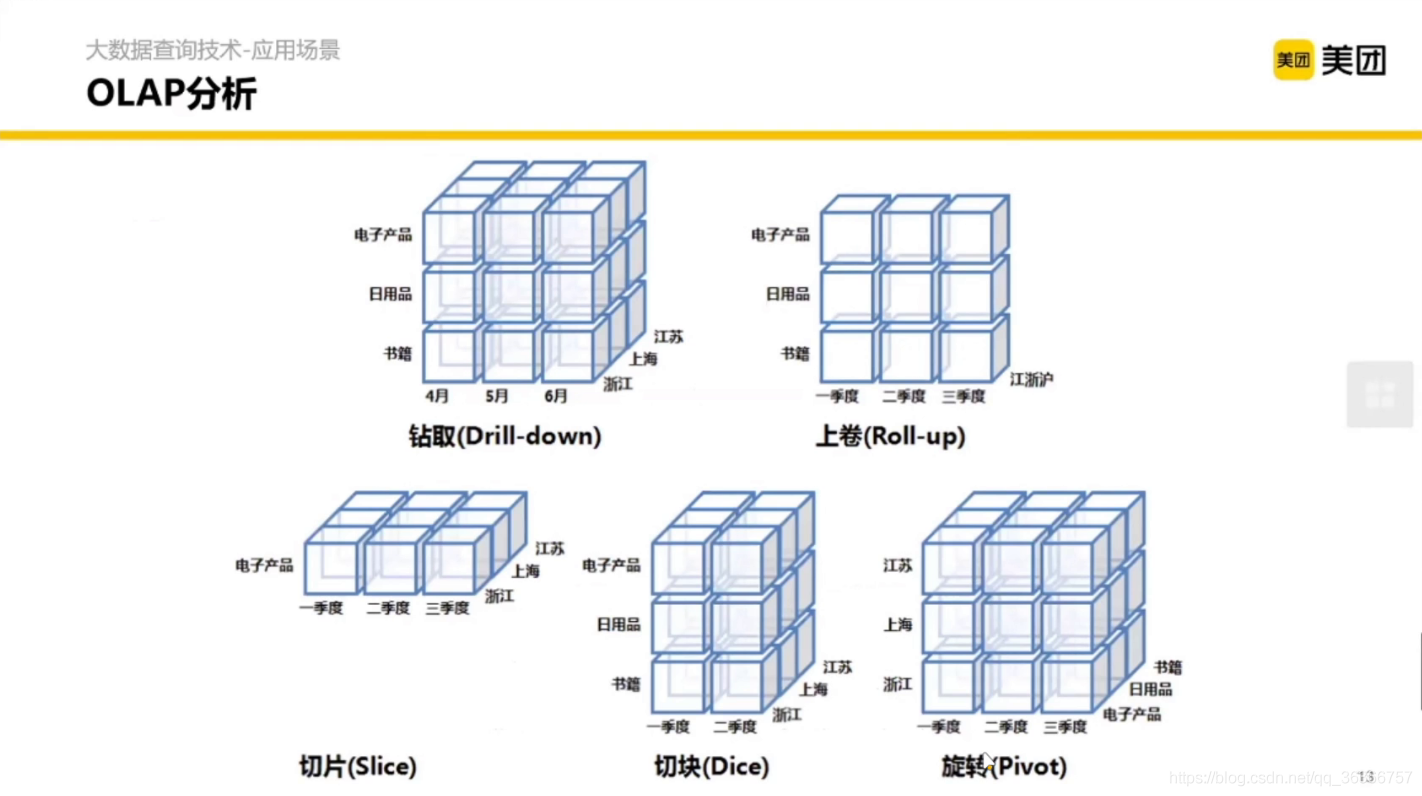
這里用到了之前說到的 OLAP 分析,OLAP 分析有哪些方法呢?這里提到了 5 種,
- 鉆取(下鉆):增加維度,能夠通過更細的粒度去分析問題,(假設一個長方體有一層,擴展成三層)
- 上卷(上鉆):減少維度,能夠從宏觀(相對)的角度看待問題,(假設一個立方體有三層,壓縮成一層)
- 切片:同一個維度,只看其某一個值,(假設一個立方體有三層,只保留一層)
- 切塊:同一個維度,只看其某幾個值,(假設一個立方體有三層,只保留兩層)
- 旋轉:行列變換,
一些商業 BI 系統

二、系統架構
2.1.系統架構 Review - Presto
重點介紹一下使用比較廣,也比較有代表性的資料庫來看一下分布式 SQL 陳述句是怎么跑起來的,
首先介紹一下美團這邊的資料庫選型思路,主要分為三種以下場景:
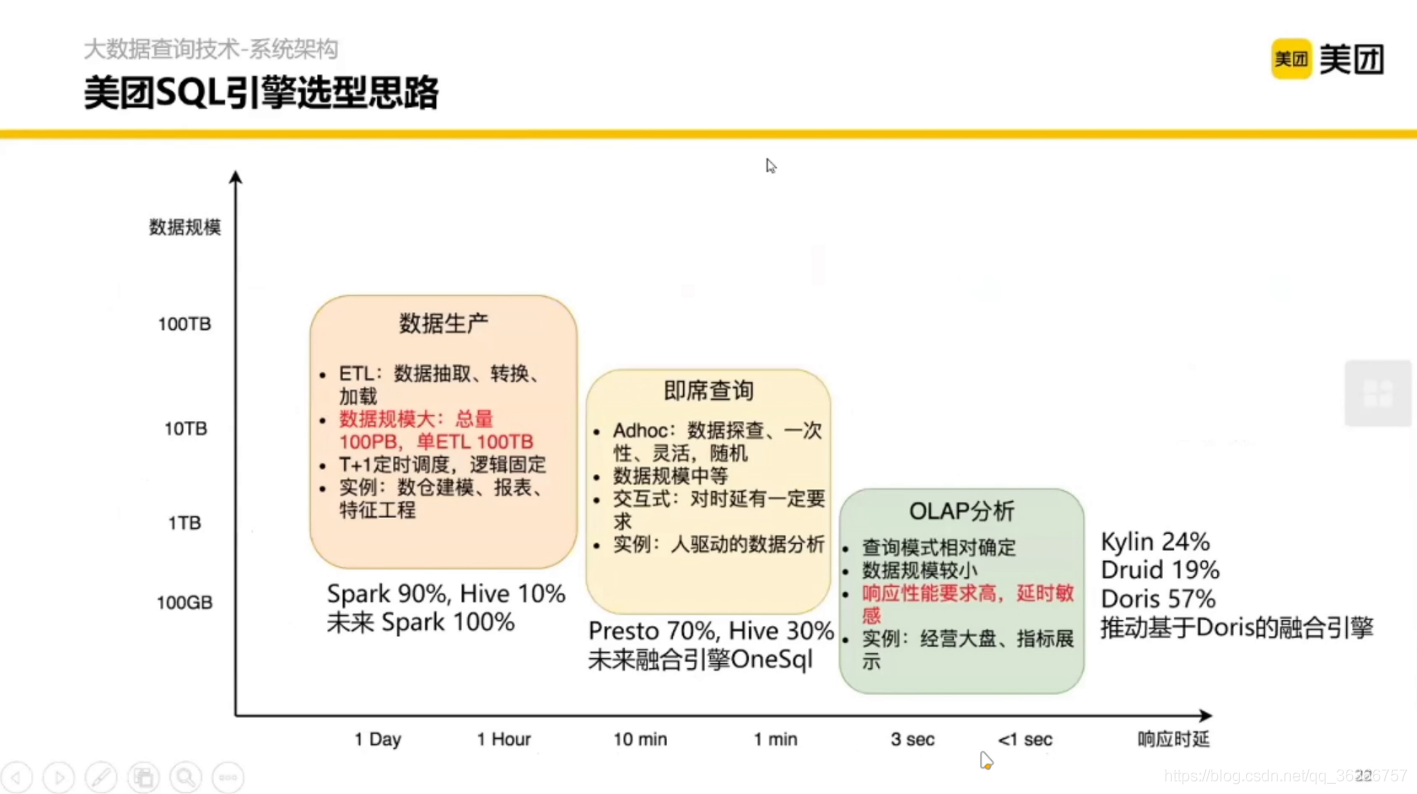
我們下一階段介紹的 Presto 主要是在即席查詢這個部分,先來看下 Presto 的演化歷史,如果有興趣的話,

設計理念一言以蔽之的話就是用可靠性換性能,之前我們說到的 Spark 和 Map Reduce 在 shuffle 的程序中是落盤的,這樣即使一個節點掛了,也能在之前的基礎上很快的跑起來,盡可能的復用之前的資料,但是 Presto 并沒有考慮這個問題,他的定位相對于 Hive 和 Spark 超大規模的場景,
然后如果扛不住了就盡快掛掉(fail fast),也可以關聯其他型別資料庫的資料,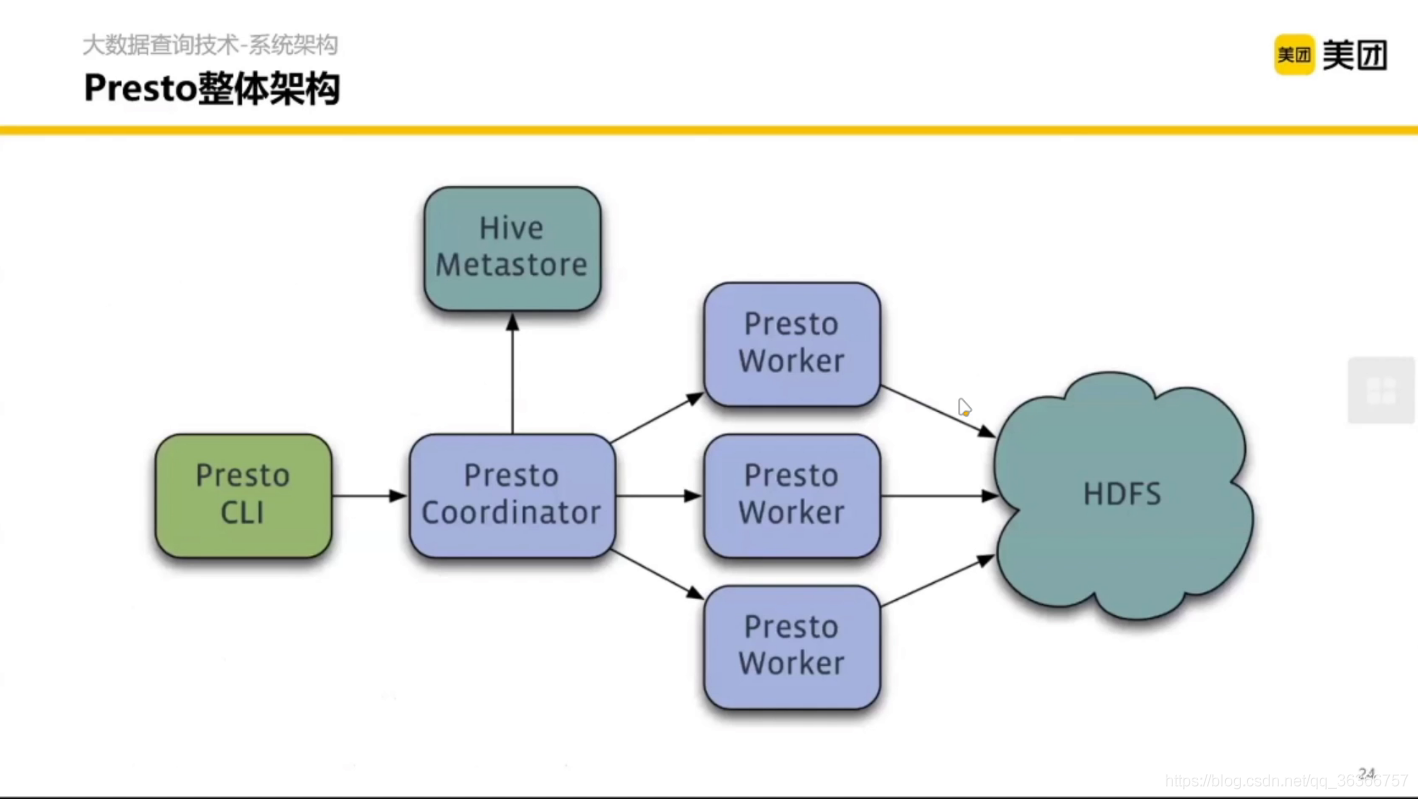
然后宏觀來看,整體架構如上圖,藍色的是 Presto 本身的服務, 前置呢是一個客戶端型別的控制元件,類似 MySQL 的命令列,MetaStore 基本上存的是資料在 HDFS 上的表、庫怎么組織的元資料,(禁止套娃)
Presto 內部還是主從架構,Cordinator 是協調者, Worker 是打工人,
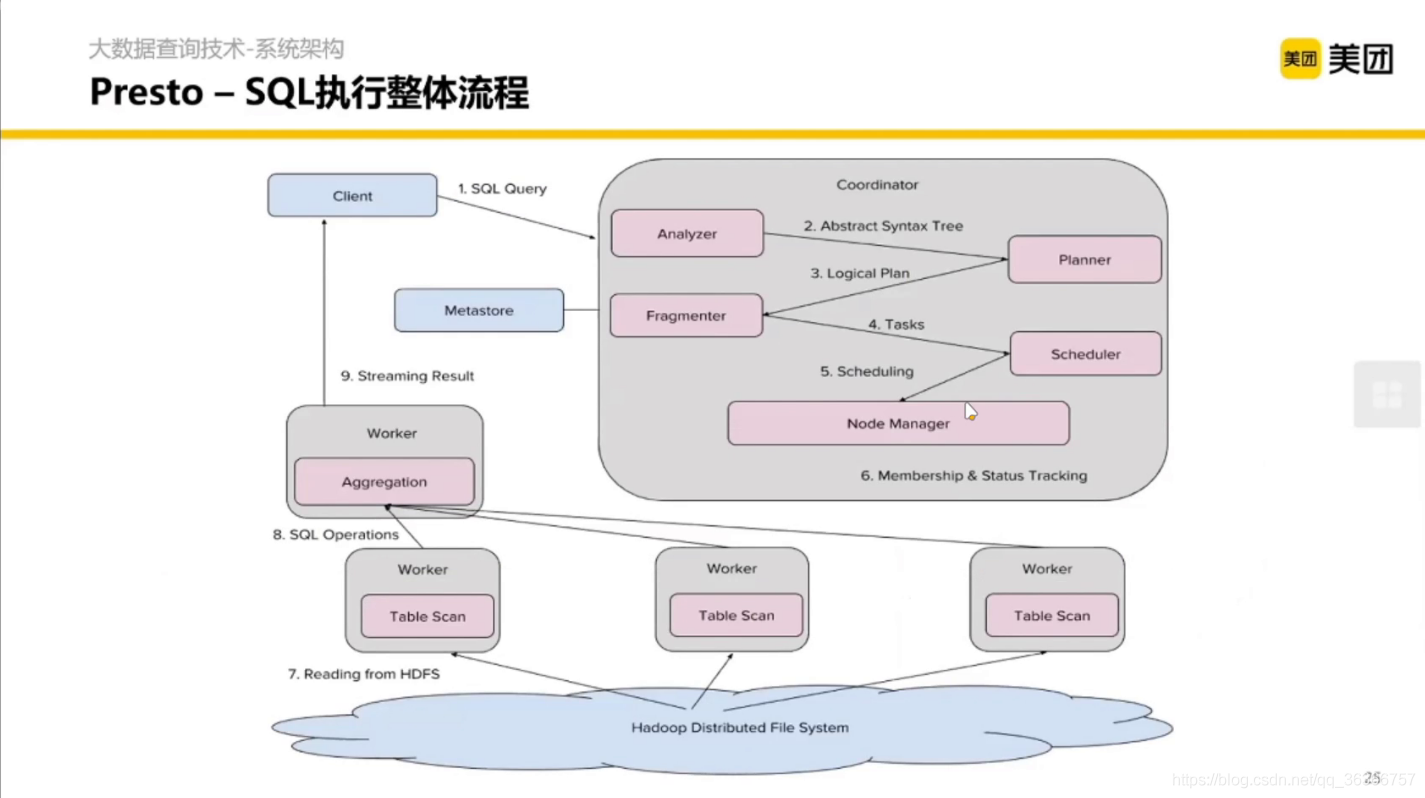
詳細架構如圖:
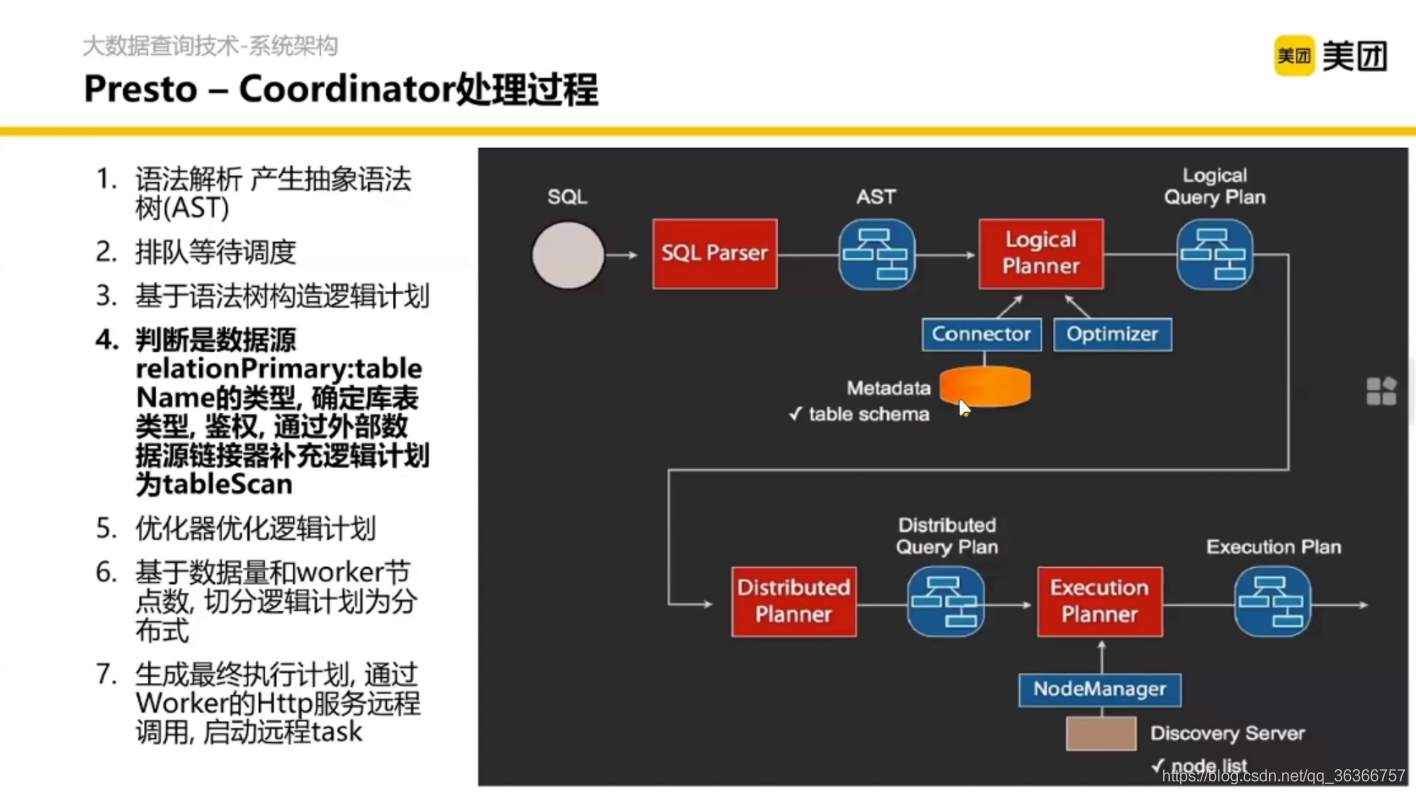
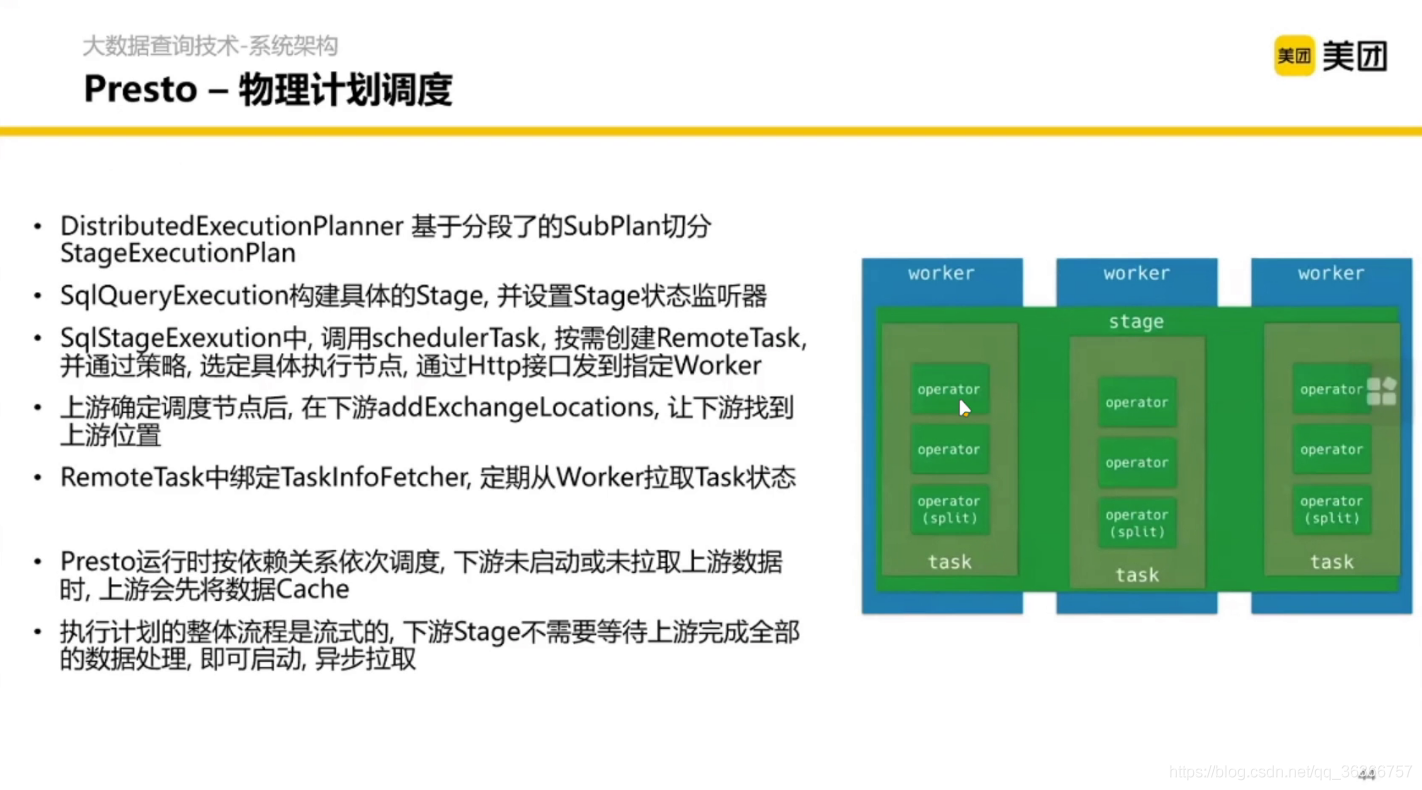
Client 提交一個 SQL,在 Coordinator 內做分析、計劃、拆分、調度,然后提交每個 Worker 管理的模塊,每個 Worker 拿到任務之后從 HDFS 去掃資料然后計算,每個 Worker 聚合之后再通過一個流介面回傳給 Client,
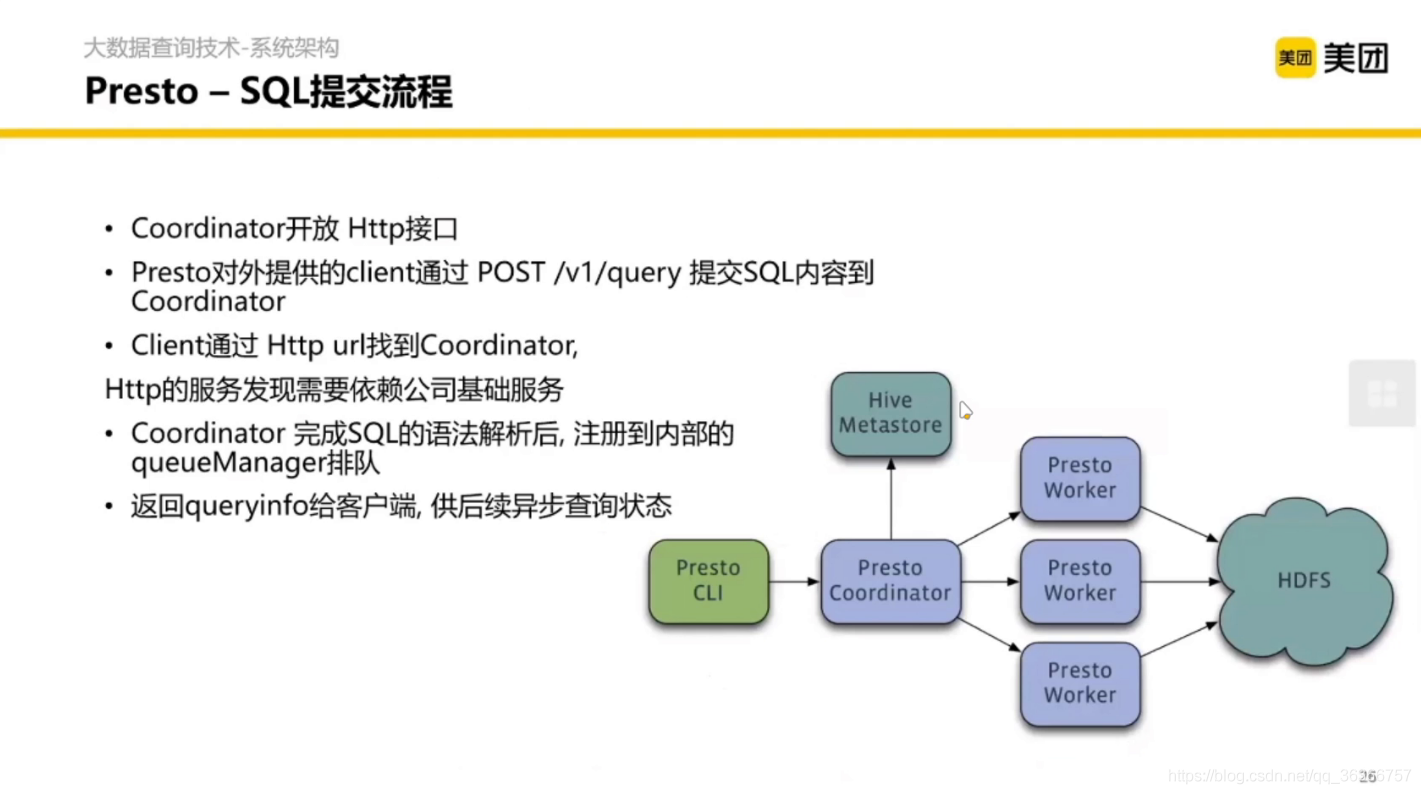
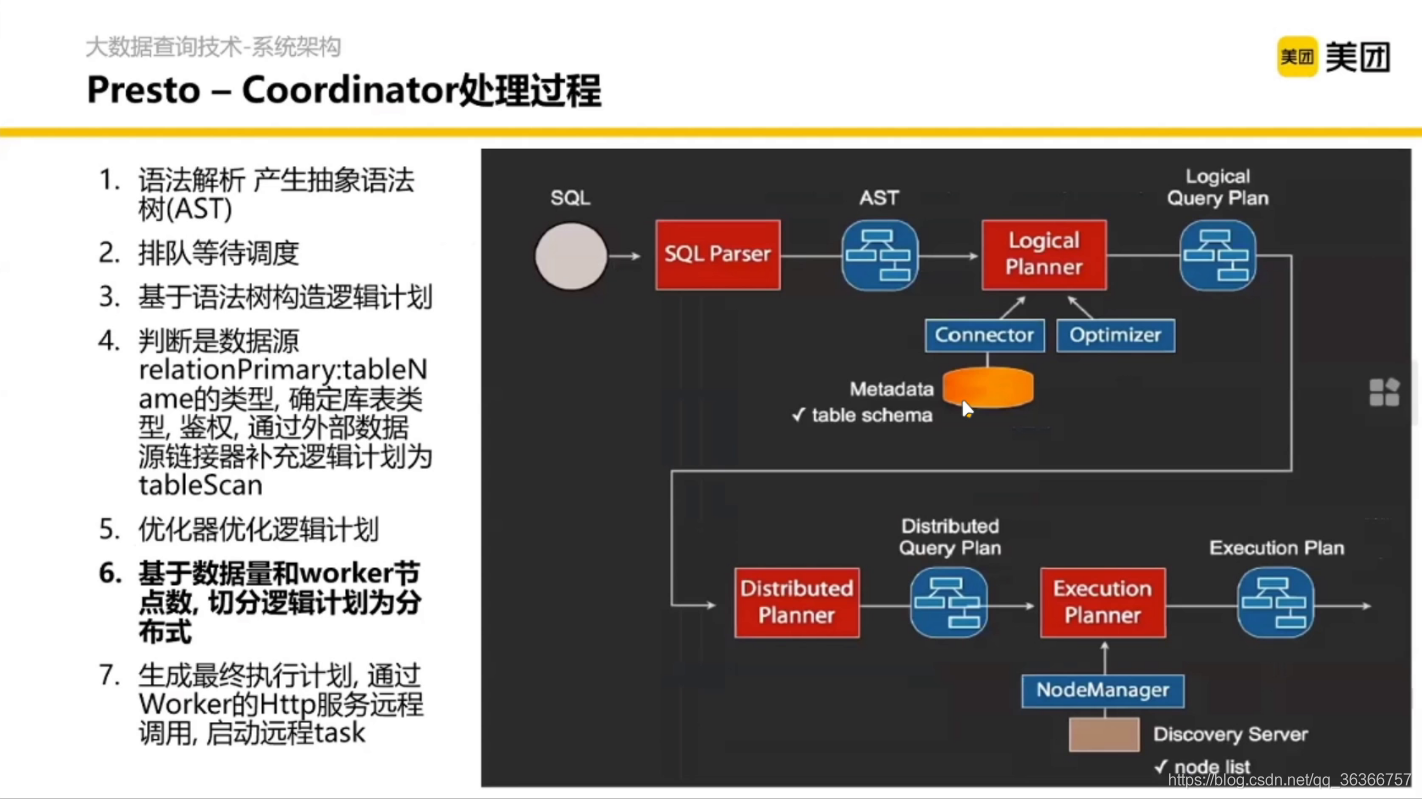
重要的部分是 Coordinator 內部的處理程序,
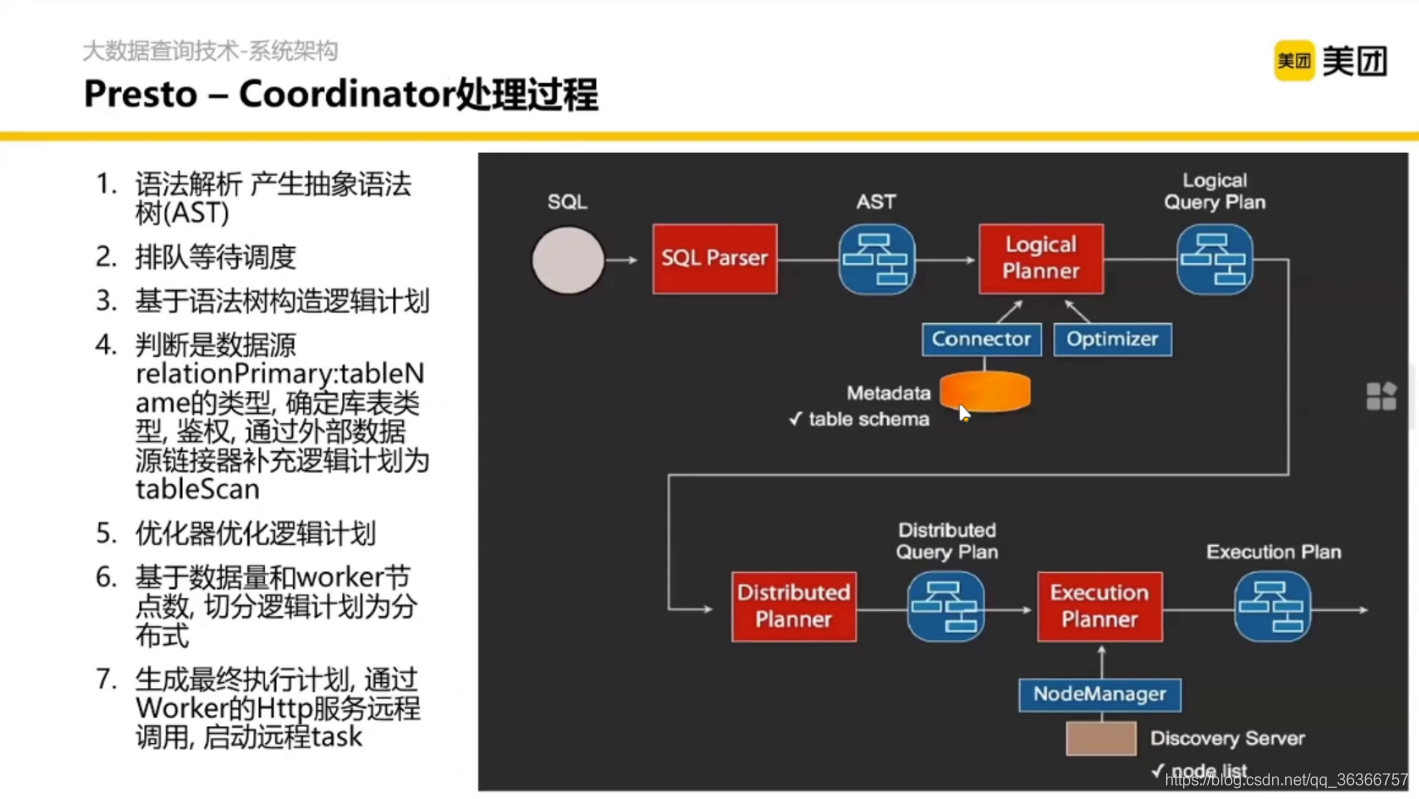
語法決議怎么決議呢?這里其實涉及編譯原理的知識,通過詞法分析、語法分析等生成語法樹,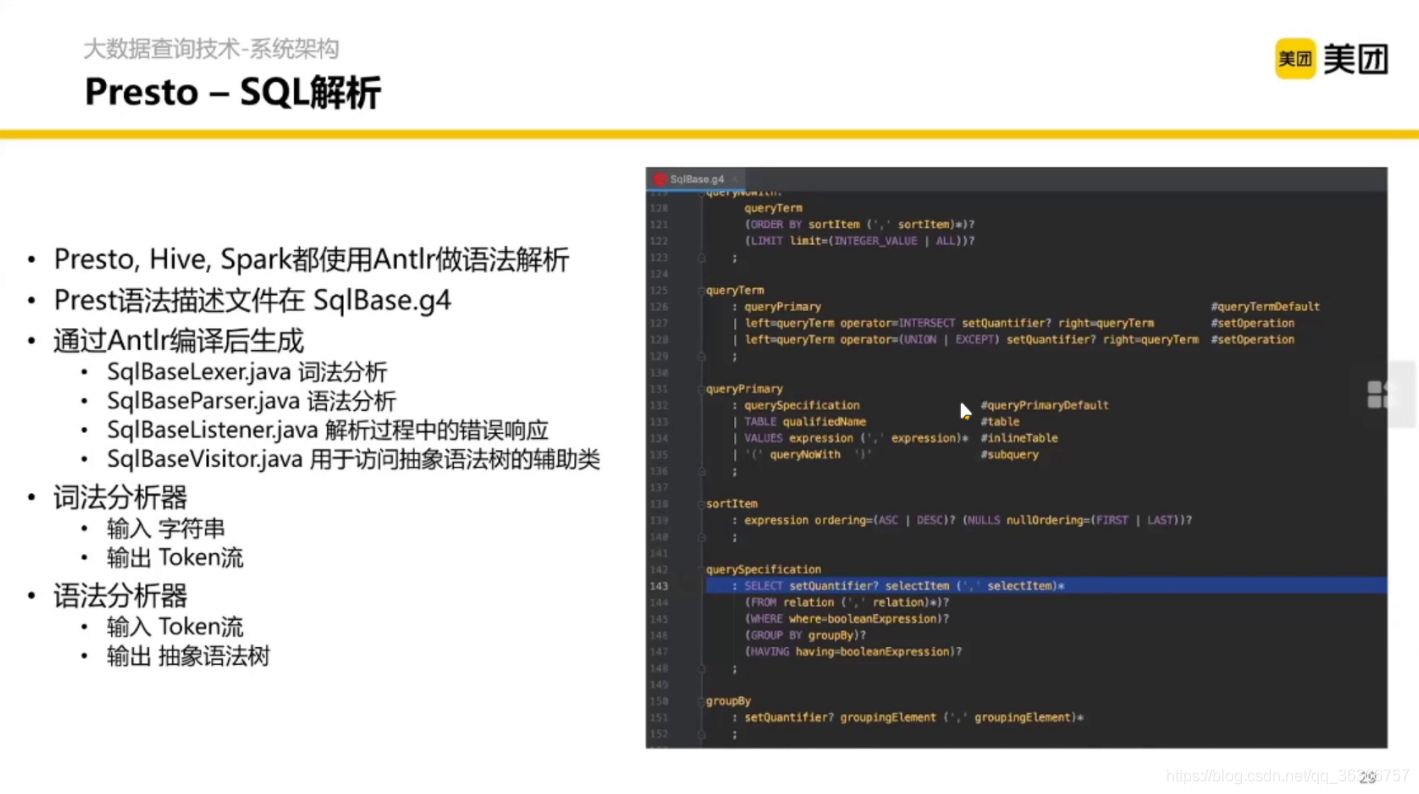
語法樹長什么樣呢?大概就是這個樣子
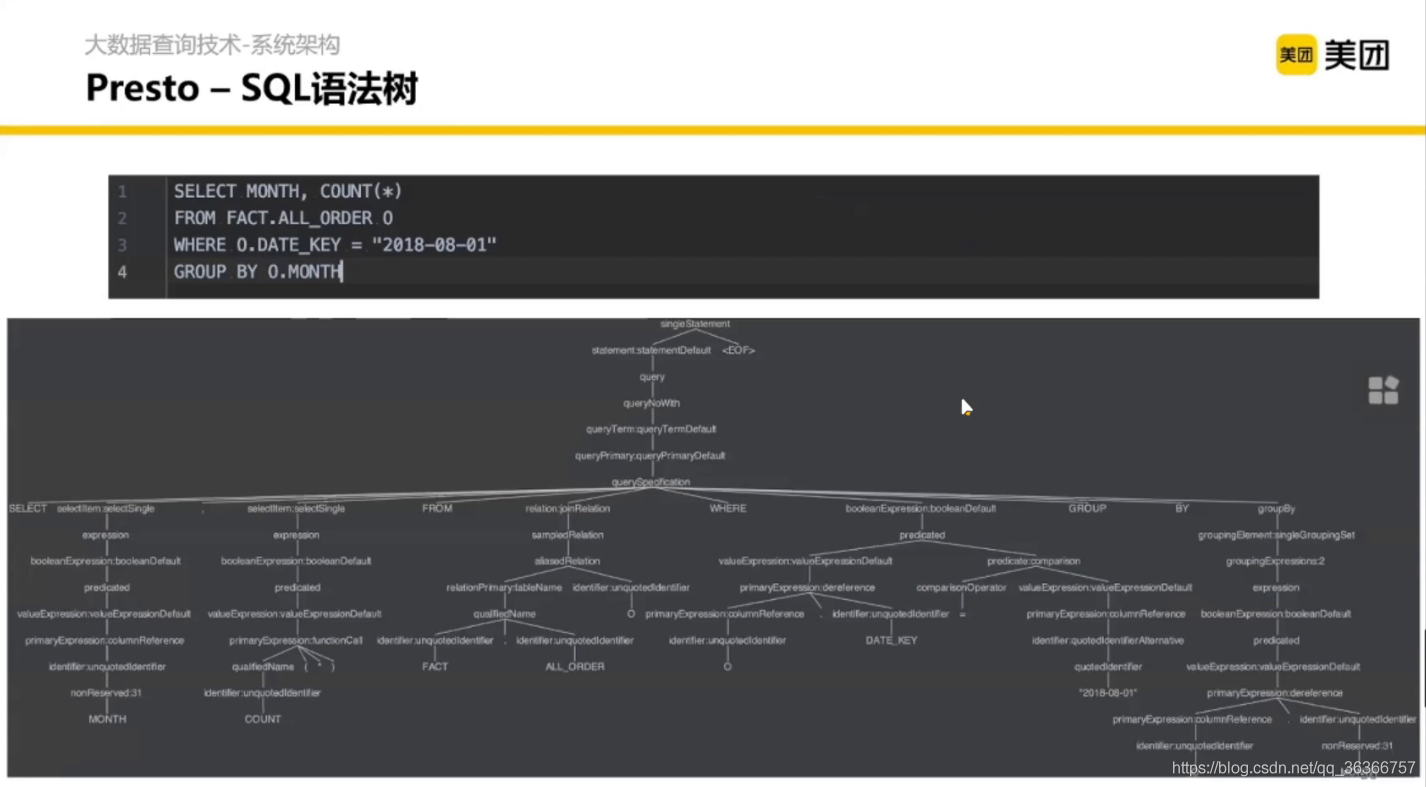
在 SQL 陳述句打一個 explain 資料庫會告訴你接下來怎么執行,根據上面得到的語法樹去構造一個執行程序的邏輯計劃,

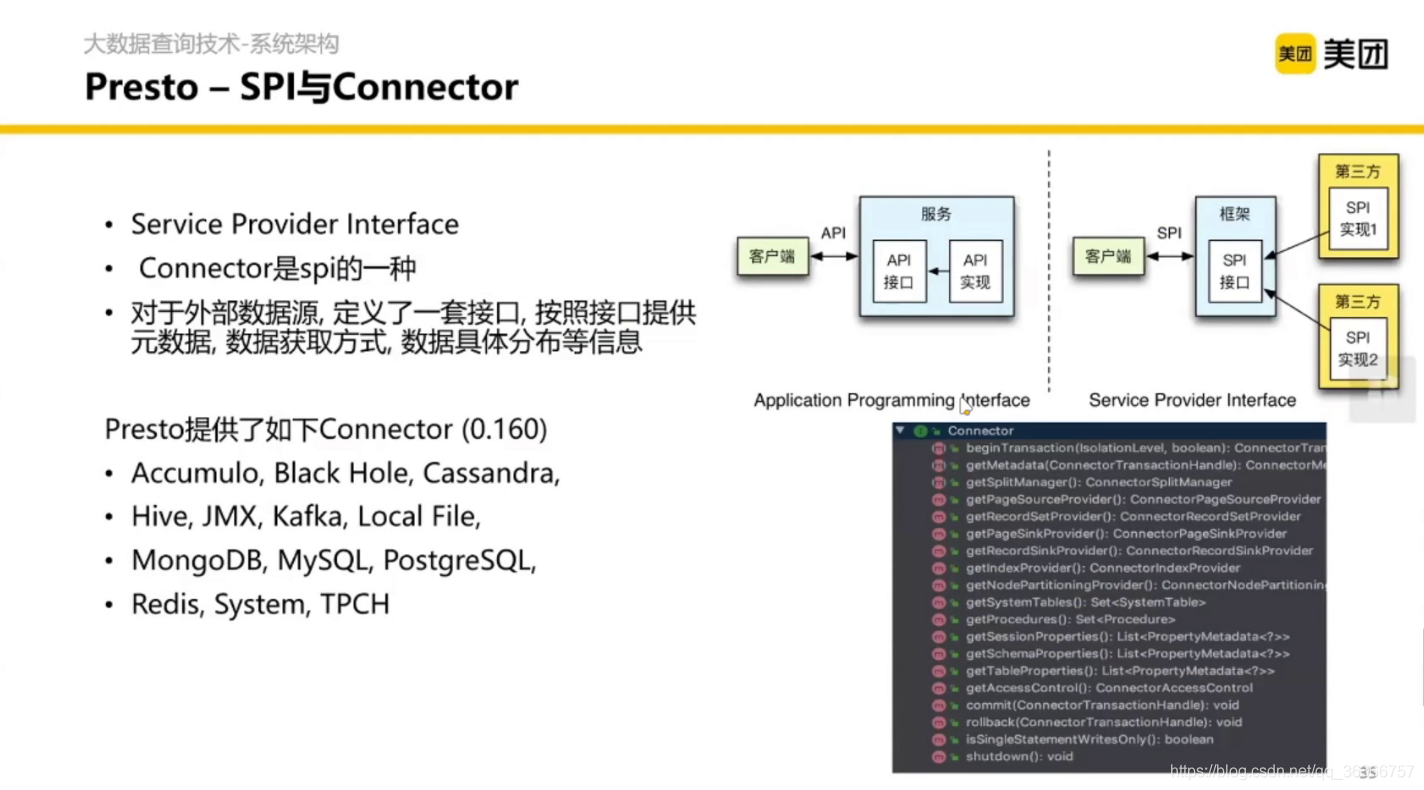
這里是 Presto 對資料源的接入抽象,在讀資料這一層對于 SQL 本身是屏蔽了的,這要做一些配置就能去訪問資料源,
這里說的是 SQL 的優化部分,pv 是用戶瀏覽的表,
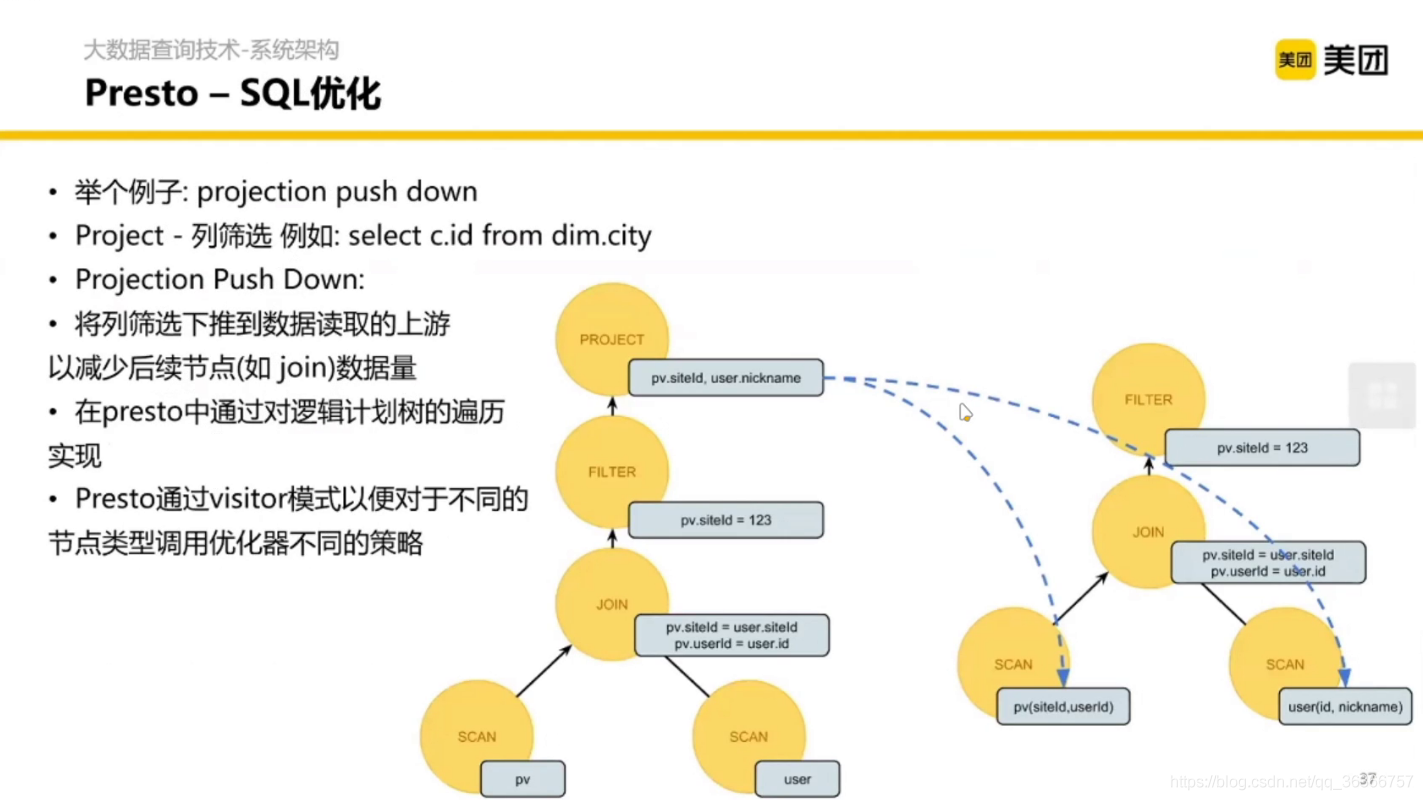
正常我們寫一個 SQL 的程序是關聯 pv 和 user,然后選出符合條件的行,那這里能不能優化呢?如果能又要怎么優化呢?
當資料很多的時候,如果我們在關聯表之前篩選出我們需要的資料就好了,在 Presto 中,在關聯之前,掃描表的時候,并不拿出全部的資料,只用 siteId 和 userid 進行關聯,這樣變得更高效了,
那怎么做到這些優化呢?首先會定義一些規則,然后基于這些邏輯計劃的樹結構,一遍遍的去跑這些優化的策略,但凡是發現類似的結構,就可以去調邏輯計劃的樹,讓整個 SQL 更高效,


對邏輯計劃優化完之后,我們就要考慮如何將邏輯計劃進行物理實作,
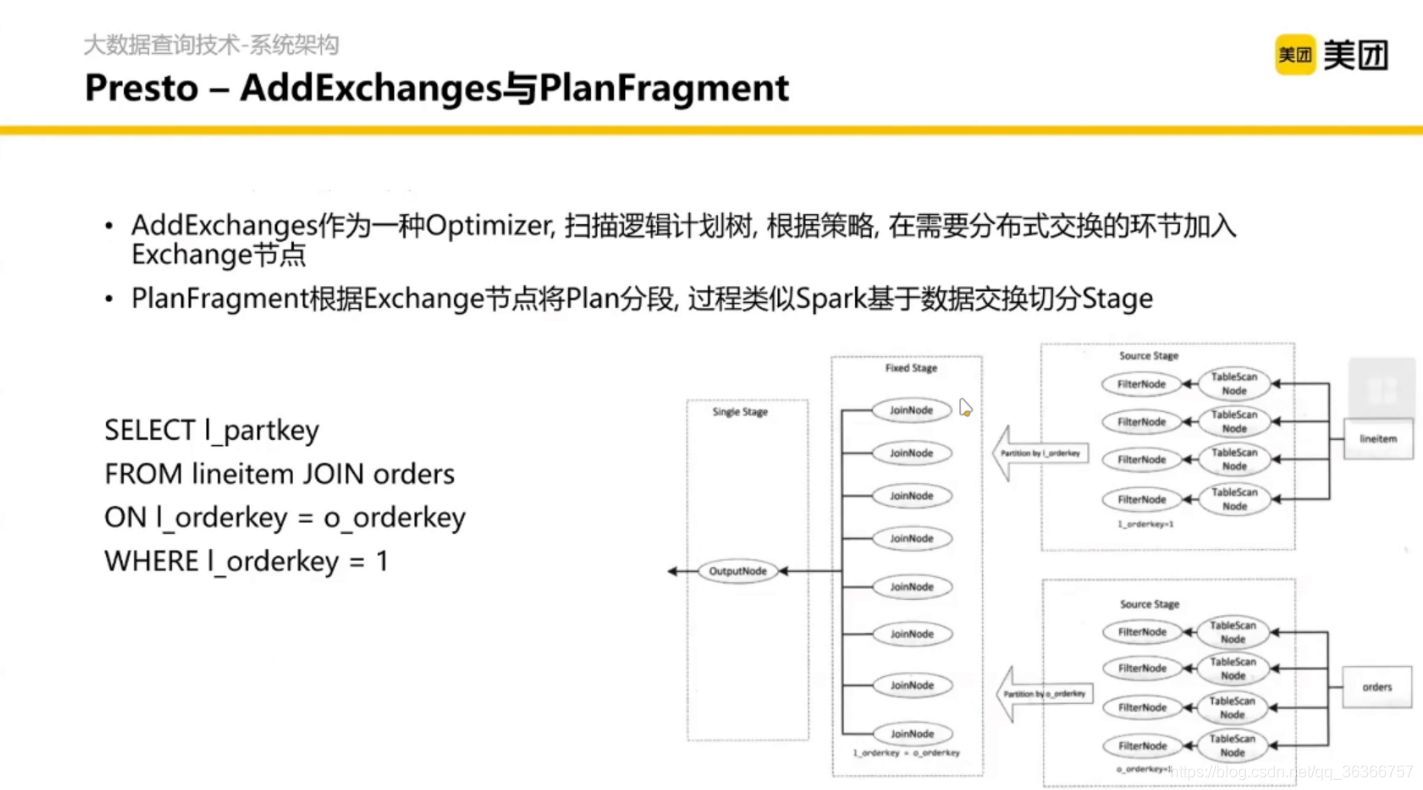
劃分主要是基于 Optimizer 的抽象做的,然后切分完之后會做一些 Shuffle 和 Group by 以及 HashJoin,
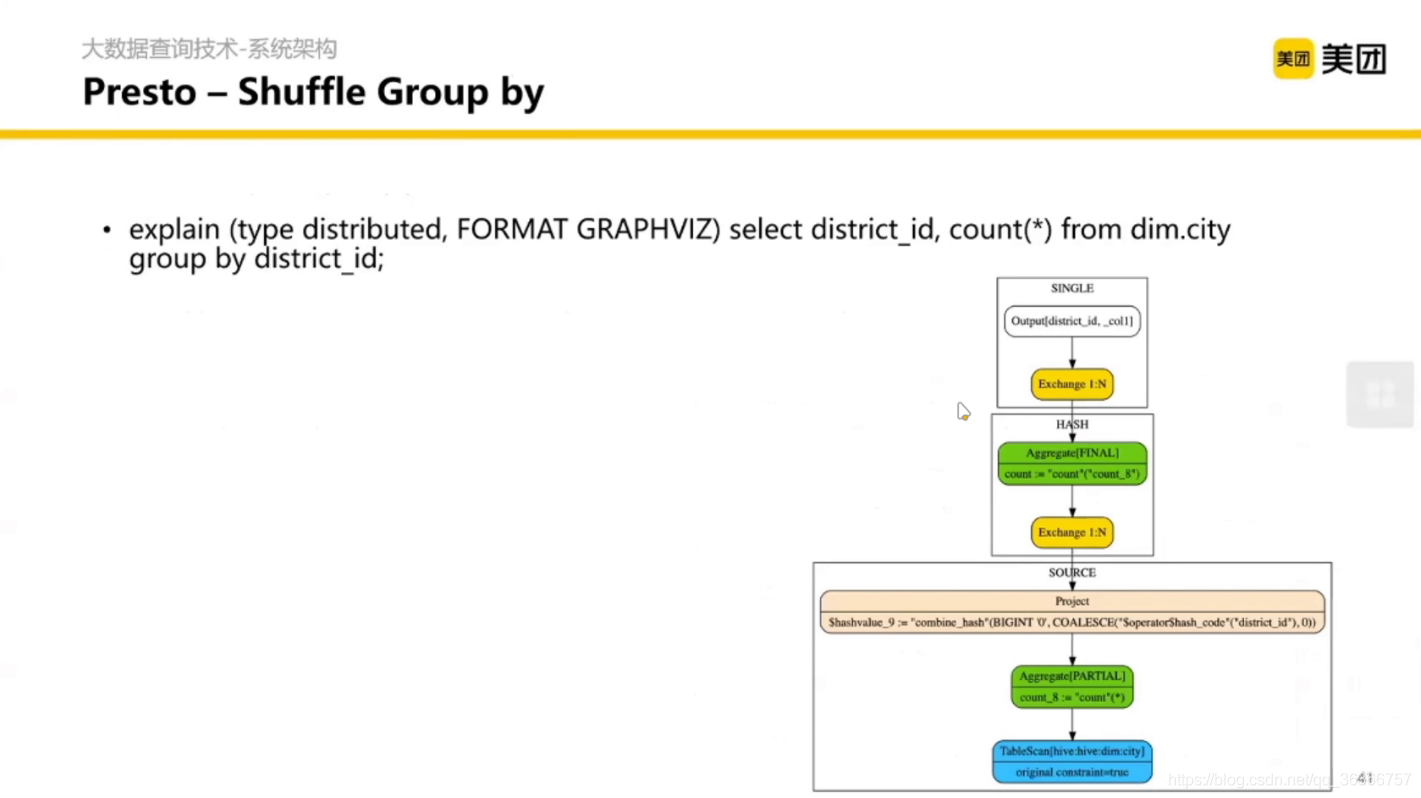
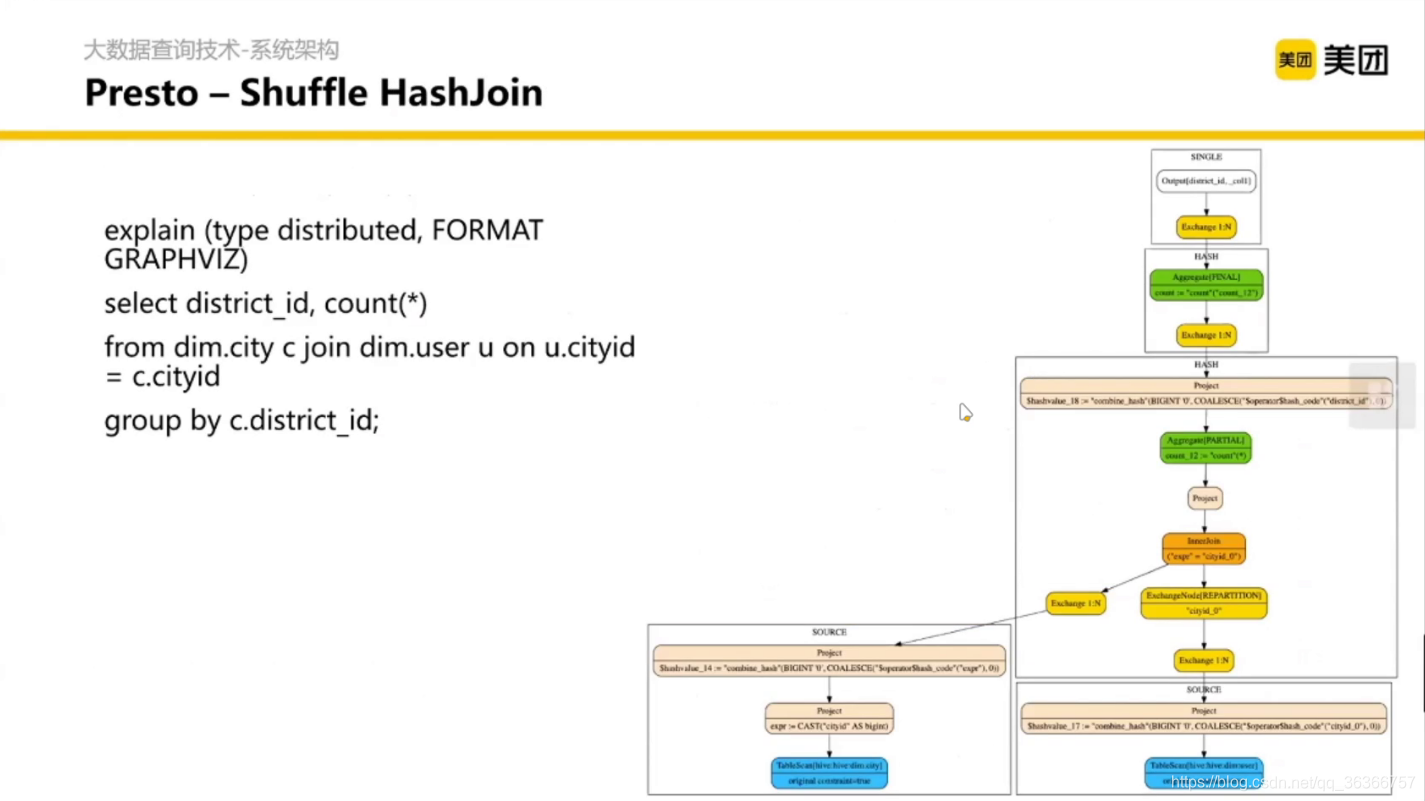
這里的 Shuffle 是不落盤的,
提問:如果在 Shuffle 的時候不落盤了, SQL 會收什么限制?(提示:在 join / groupby 的時候)
答:在關聯的時候或者合并的時候,我們想要把同一個 key
的資料在同一個節點計算,但是如果發生了資料傾斜,某一個節點的資料特別多這個節點的記憶體就會爆炸,
然后我們得到了分布式的執行計劃,調度到每個節點分別執行,這就是 Coordinator 內部的詳細執行邏輯,
下面是物理計劃的調度,
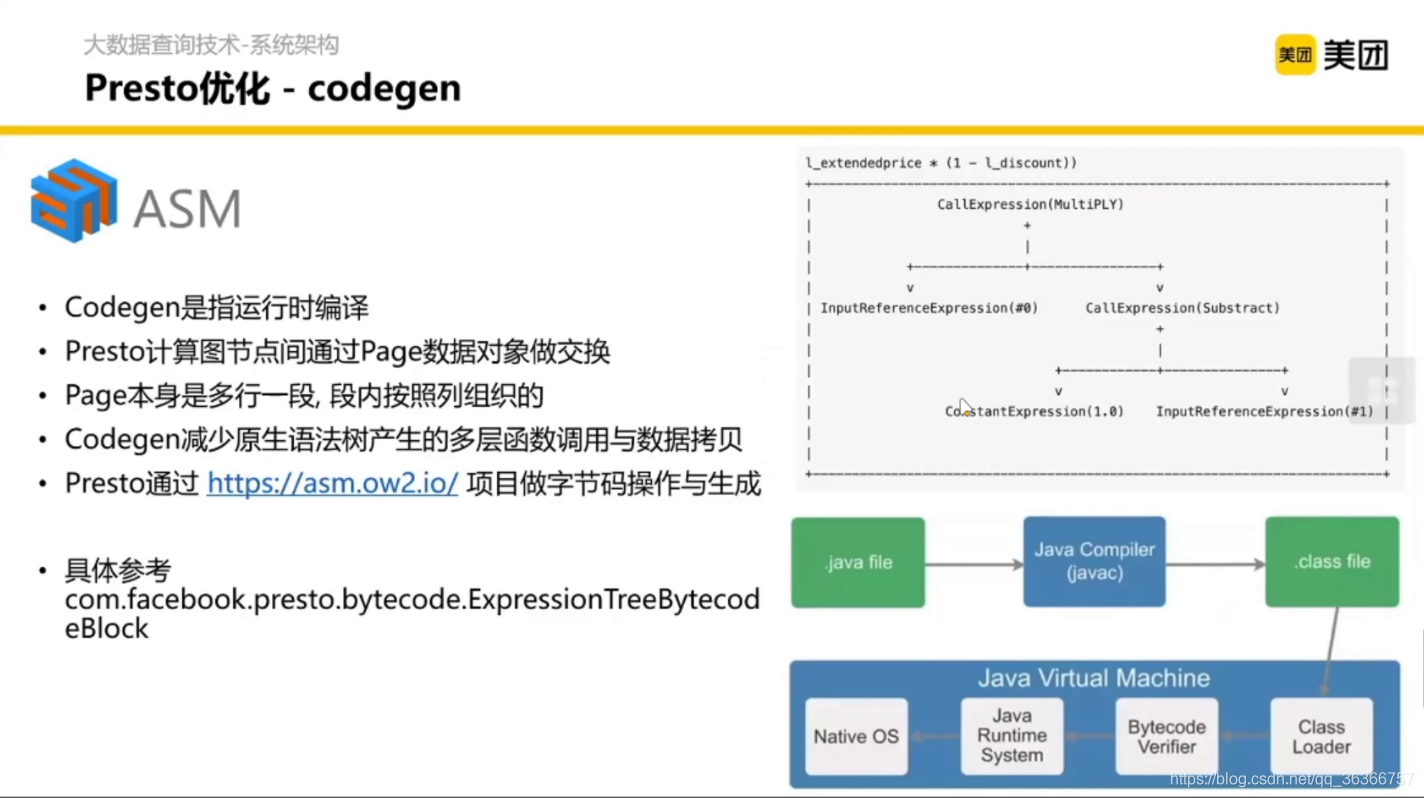
Presto 也會做一些物理層面的計劃,比如 codegen,主要特點是 運行時編譯,
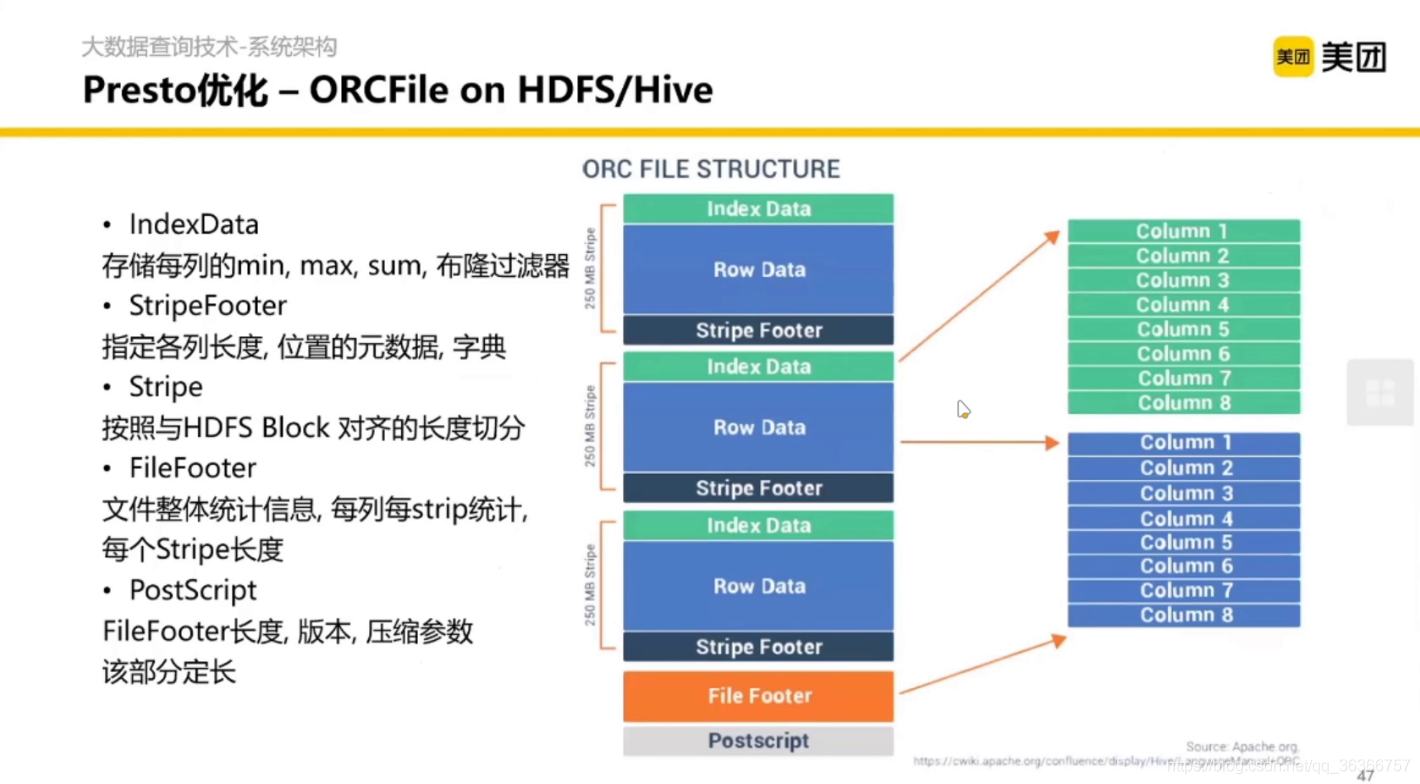
另外一個優化是偏存盤層的,資料索引和資料組織結構的優化,從只按行存盤的結構衍生出按列存盤的結構(如 ORC、parquet等),
2.2.分布式 OLAP 系統擴展技術
介紹一些系統在實作架構設計的時候的一些權衡,主要介紹四個系統:Kylin,Druid,Clickhouse 和 Doris,
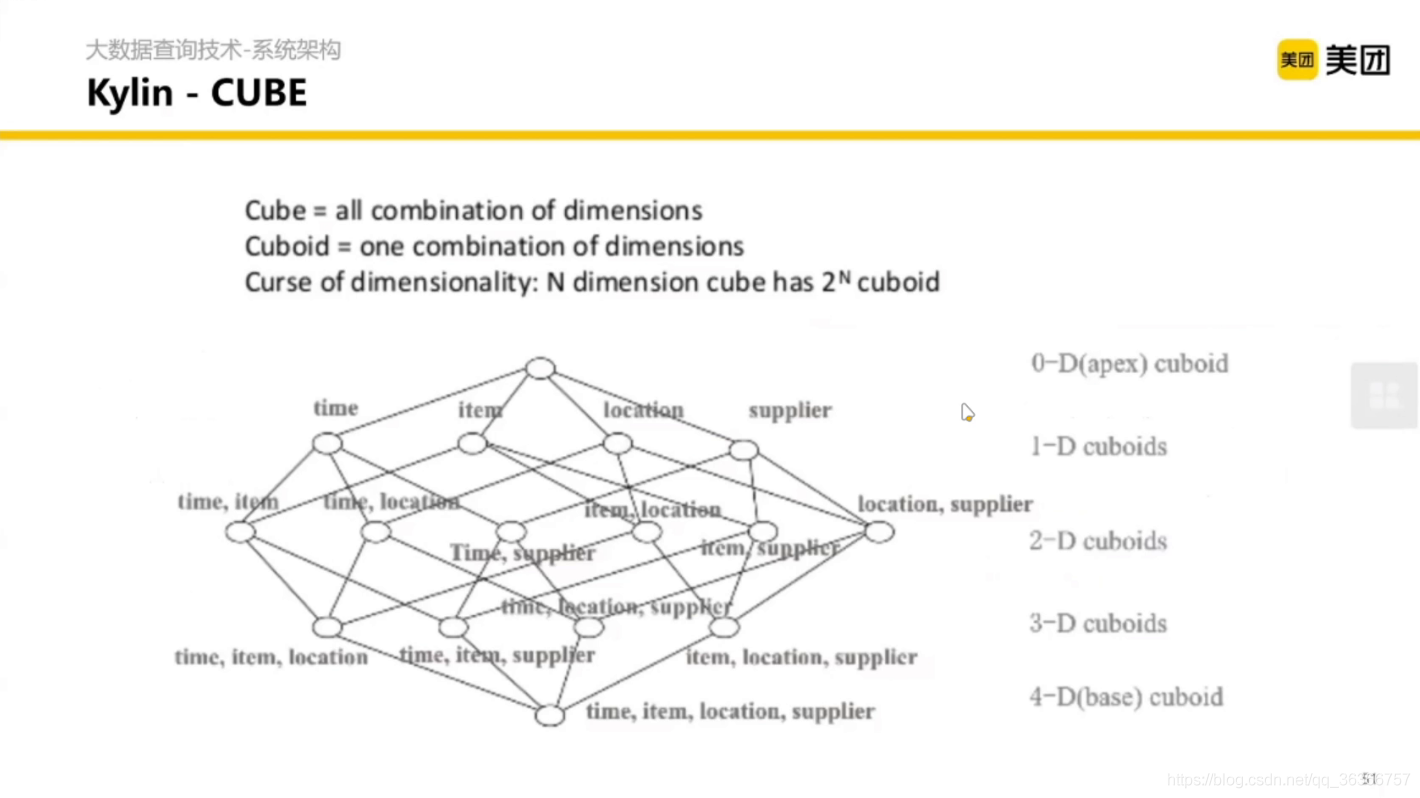
2.2.1 Kylin 與 Cube 預聚合
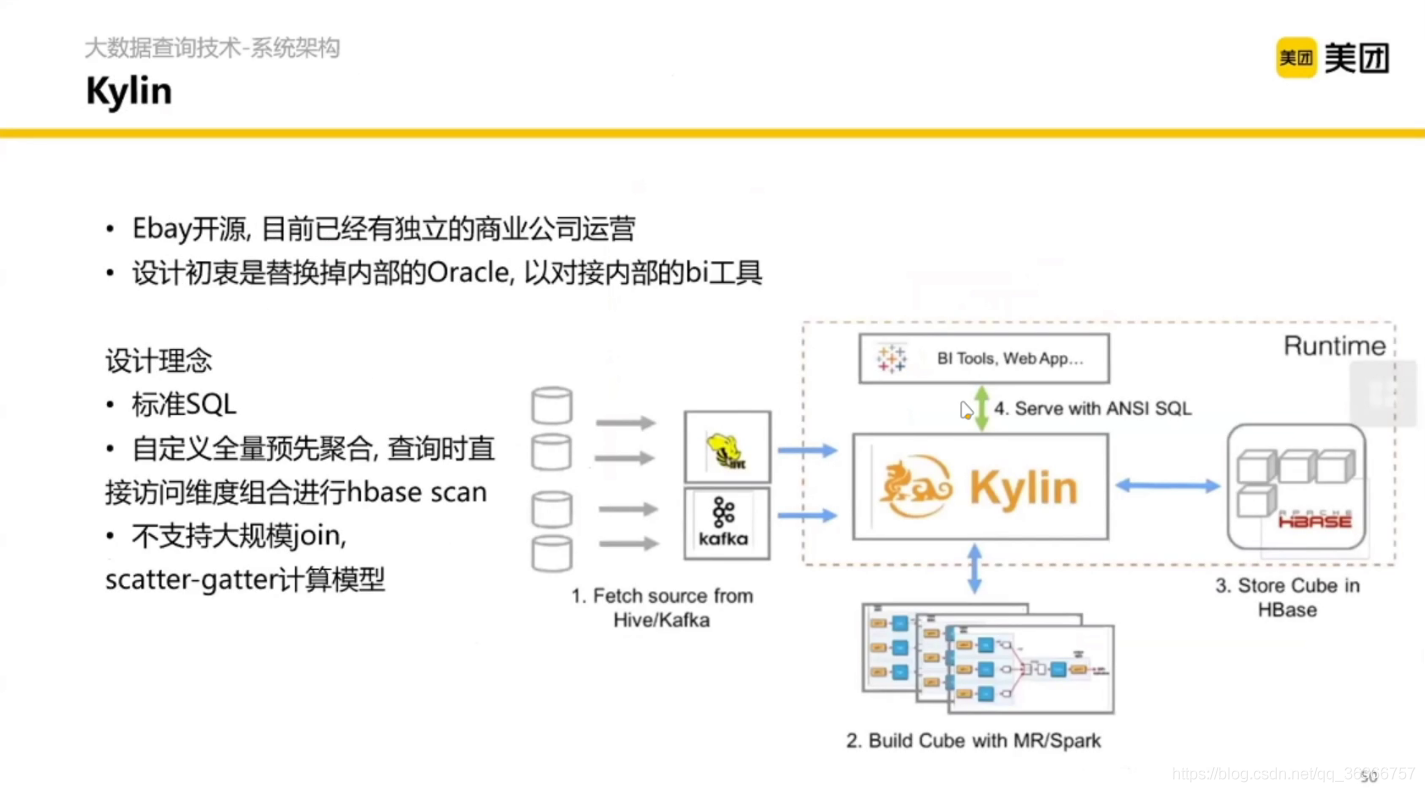
有開源和商業版本,具體特點的是預聚合,什么意思呢?
假設一個事實表有很多維度,經常需要根據這些維度進行聚合,然后 Kylin 在我們查找之前就會聚合好,當我們查找到時候去到 Kylin 里面刷選就好,在資料立方體分析的時候很常用,
2.2.2 Druid 與 流式寫入隔離,維度列倒排
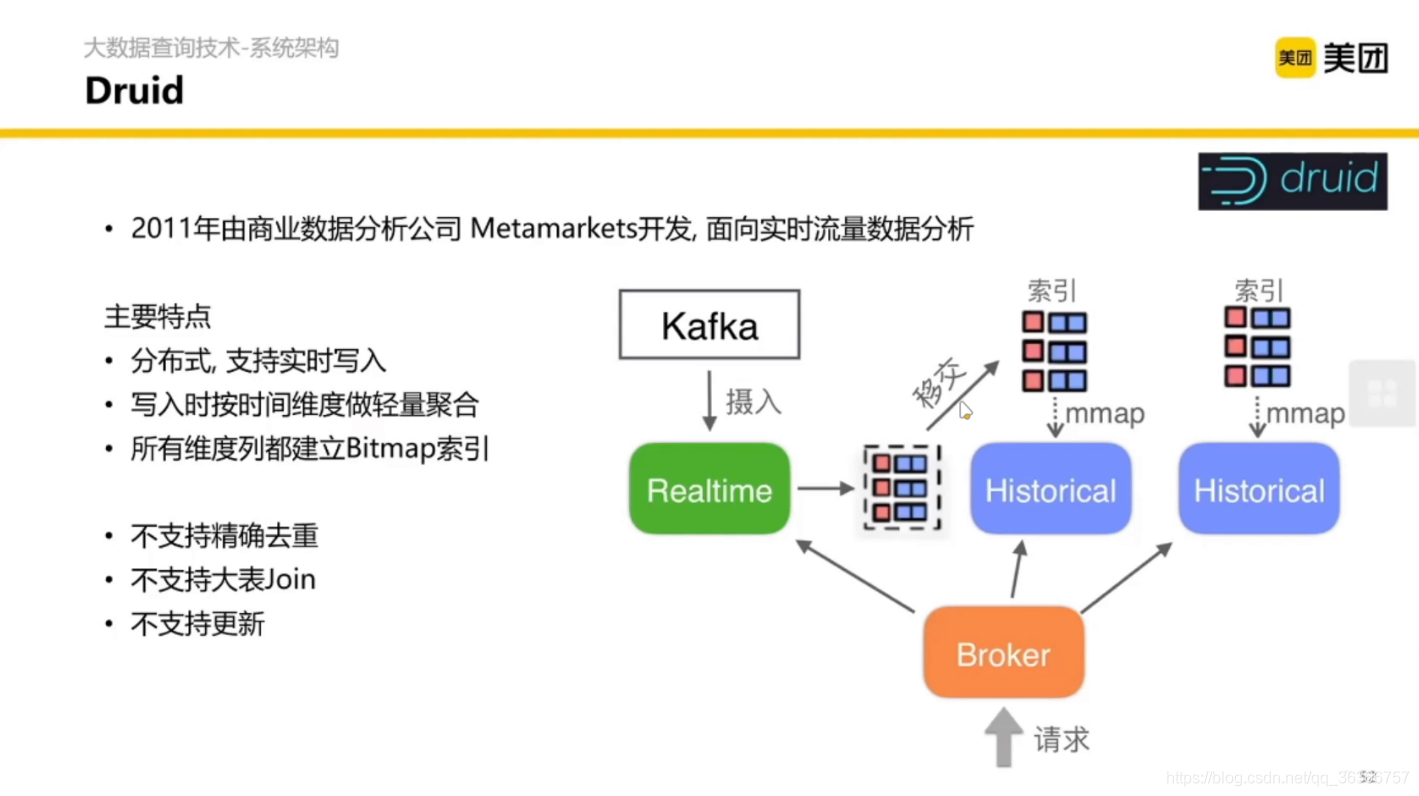
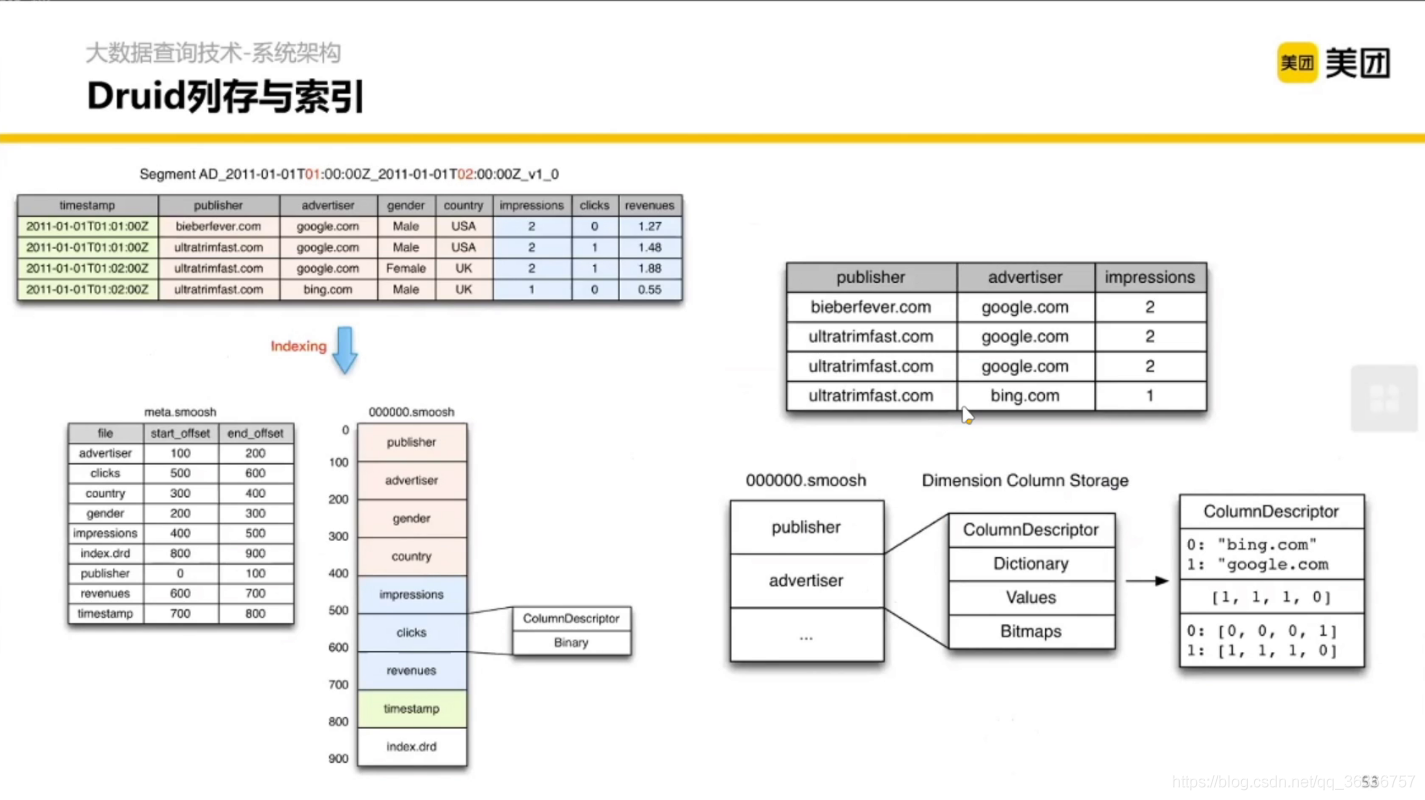
本身 Druid 也是列式存盤,更極致的是做了一個倒排索引——用一個 bitmap 存盤一個列的值的索引,
比如在列 advertiser 中有兩個值,我們掃描整列可以得到一個 bitmap,{"bing.com” :[0,0,0,1], “google.com” : [1, 1, 1, 0]},陣列的長度是列的行數,bing.com 對應的 [0,0,0,1] 的意思是在第 4 行出現的 bing.com 這個值,為什么是 4 呢?因為陣列中 1 的位置/索引是 4 (索引 1 開始),我們也很容易看出 google.com 對應的 [1, 1, 1, 0] 意思是在第1,2,3 行出現了 google.com,
這樣當我們 WHERE 之后有多個條件的時候就可以直接取 and 操作,使運算變得高效,
2.2.3 Clickhouse 與 SIMD
主要是通過利用硬體和記憶體提高現場計算能力,能夠充分利用CPU,


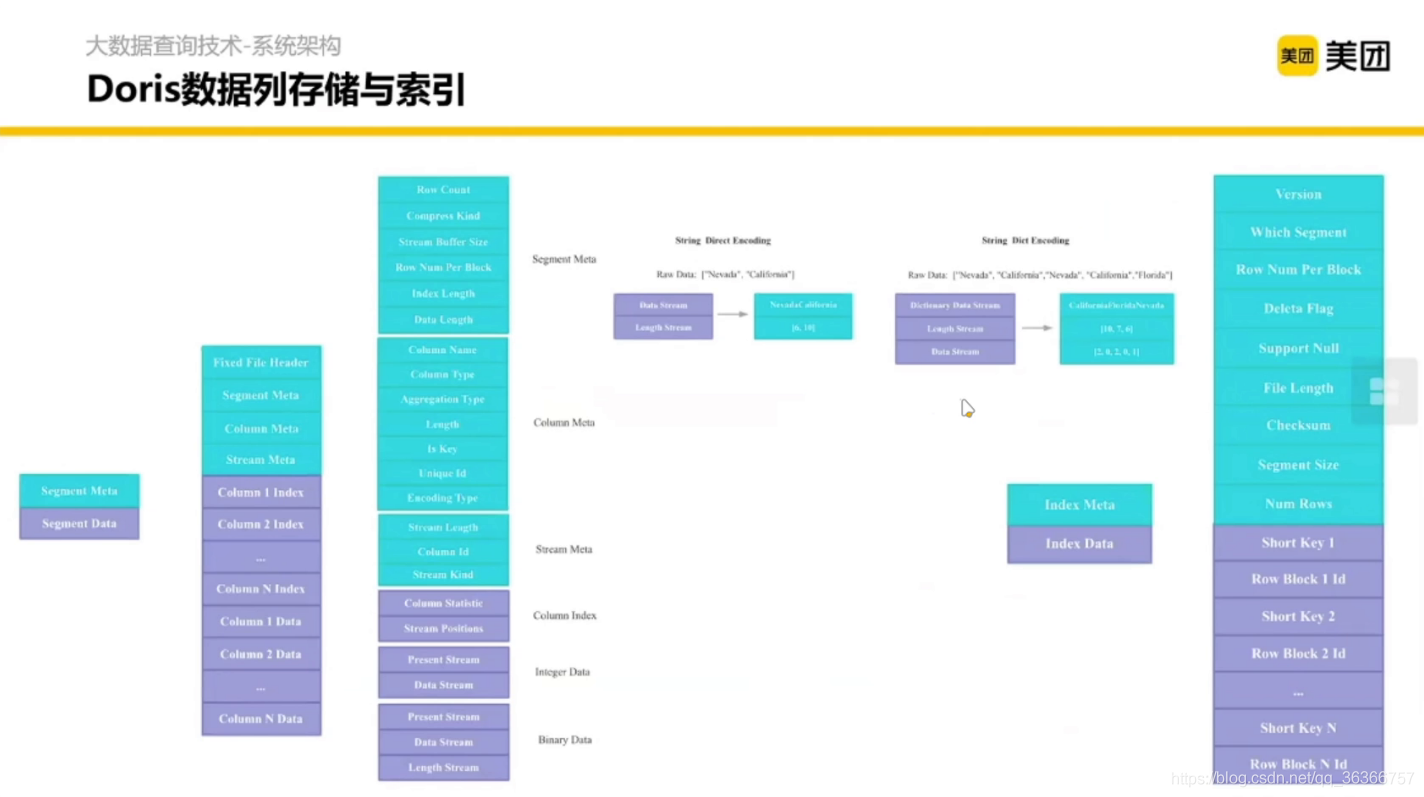
2.2.4 Doris 與 我們的融合計劃
Doris 是內聚的,沒有大的外部依賴,兼容 MySQL 協議,(之前叫Palo,OLAP的反寫)

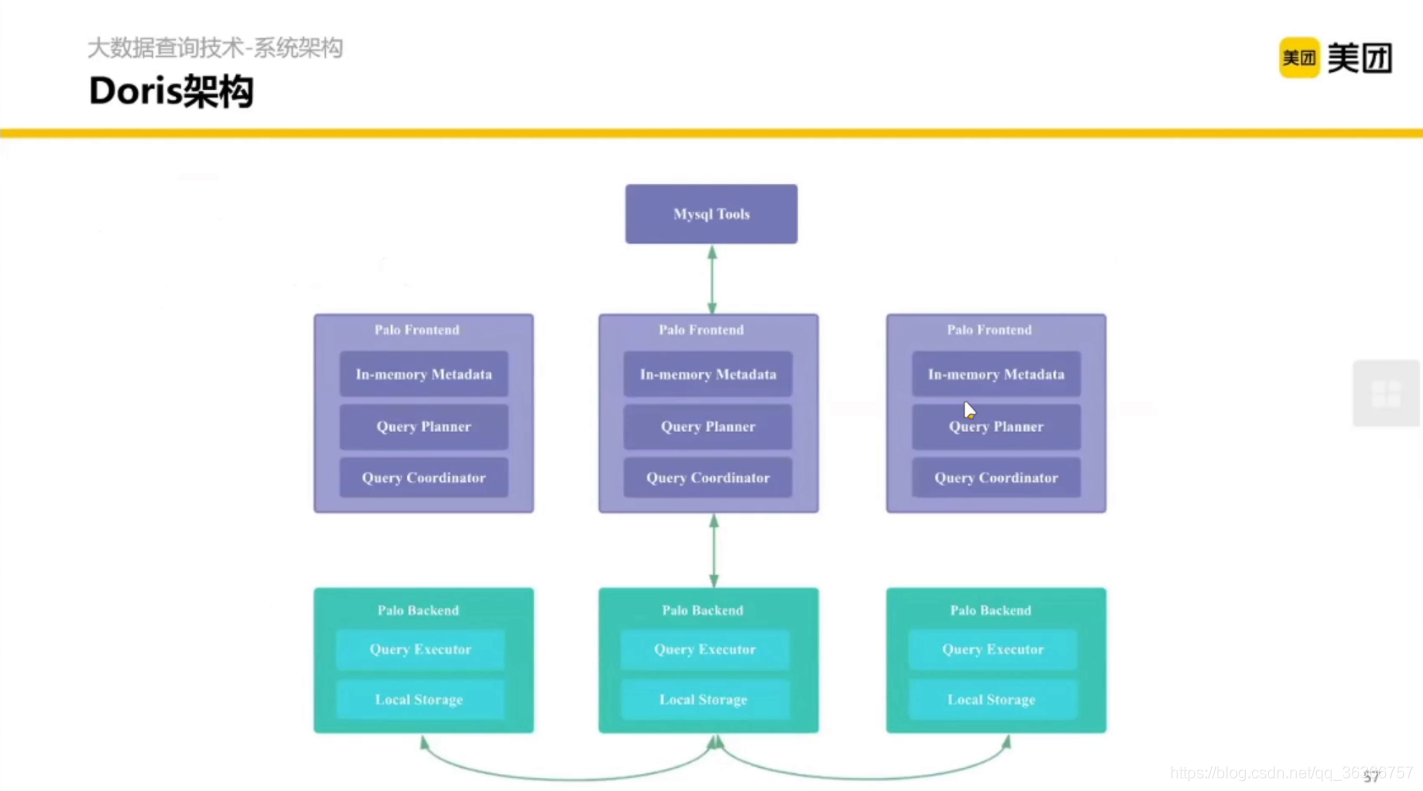
Frontend 可以認為是 Presto 橫向擴展的 Coordinator,Bankend 可以認為是橫向擴展的 Worker 加一些存盤,
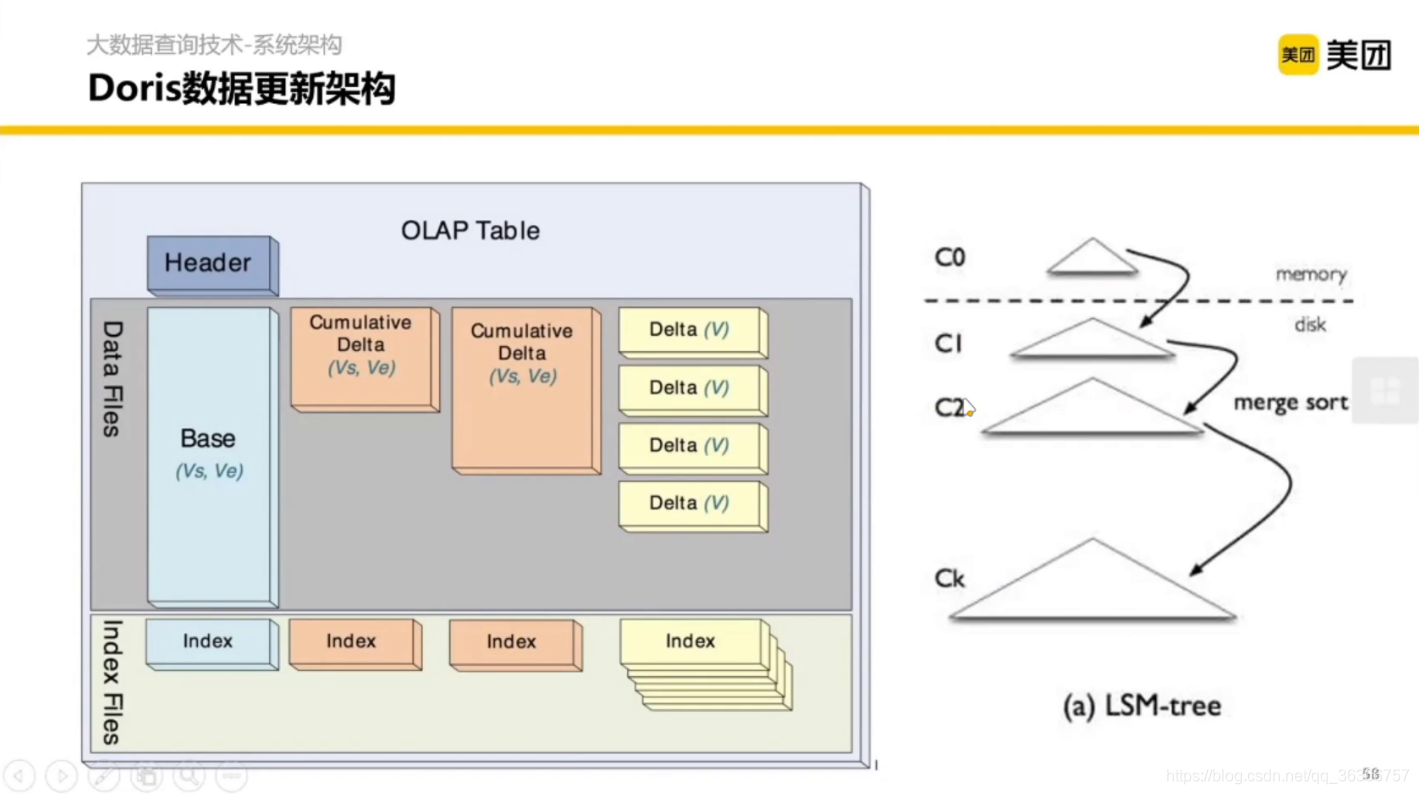
使用 LSM-Tree 的模式,解決了在快速大批量寫入的時候,我希望在整體吞吐能力提升的同時,對 KV 的查詢有一個比較快的結果的問題,
三、改造案例
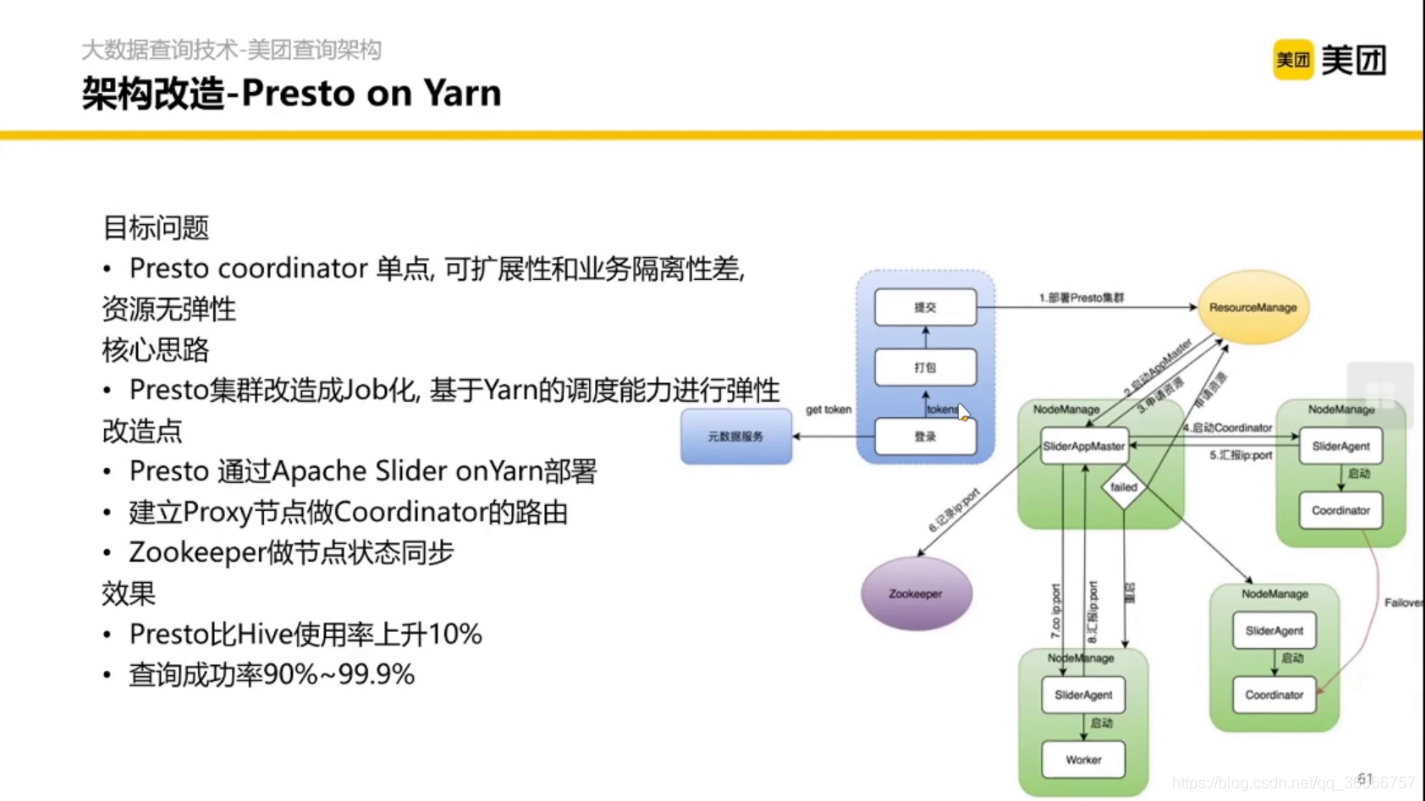
3.1 Presto on Yarn
把 Presto 的彈性伸縮,查詢調度以及 YARN 系結在一起,
3.2 統一ADhoc查詢One SQL
主要是解決多引擎的方言不同等問題
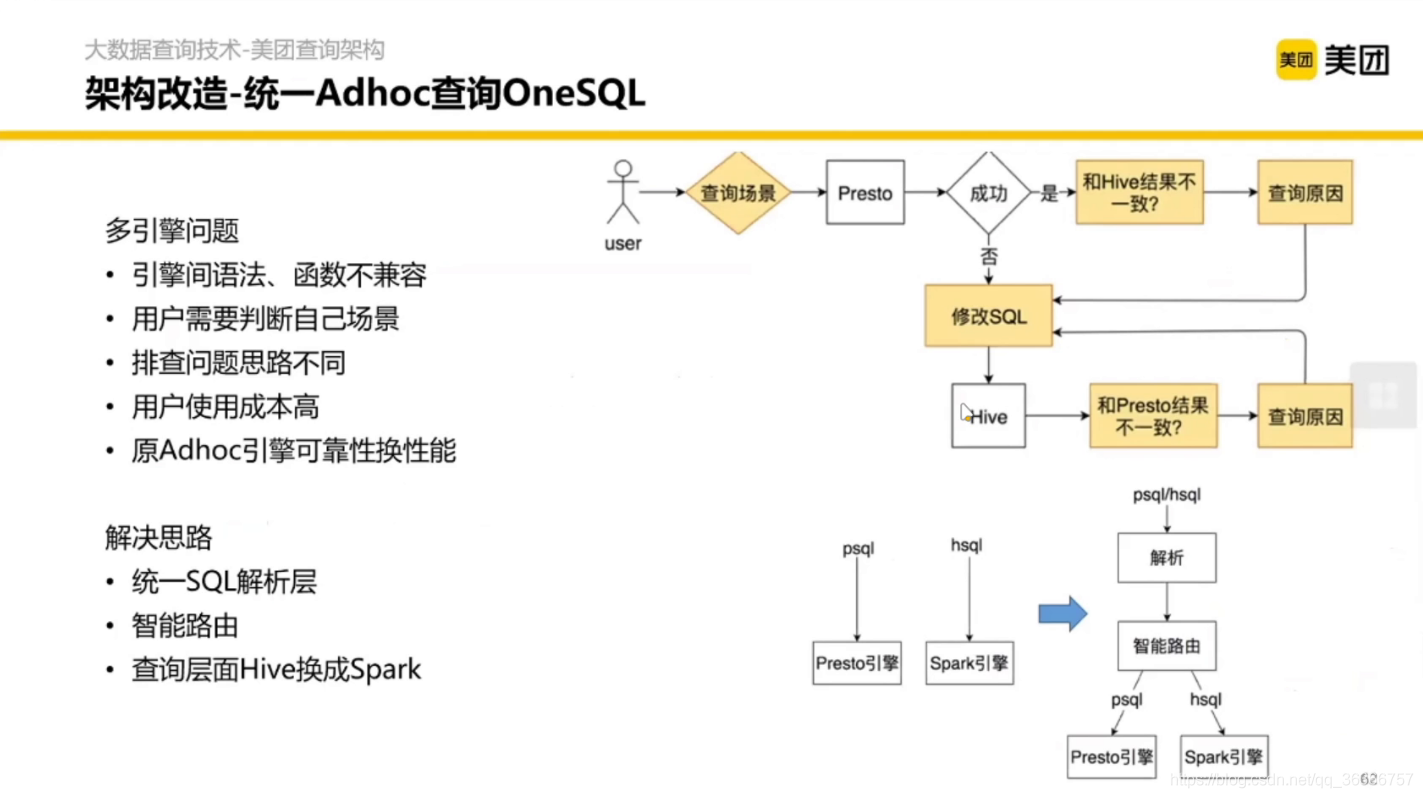
改造后的架構如圖:
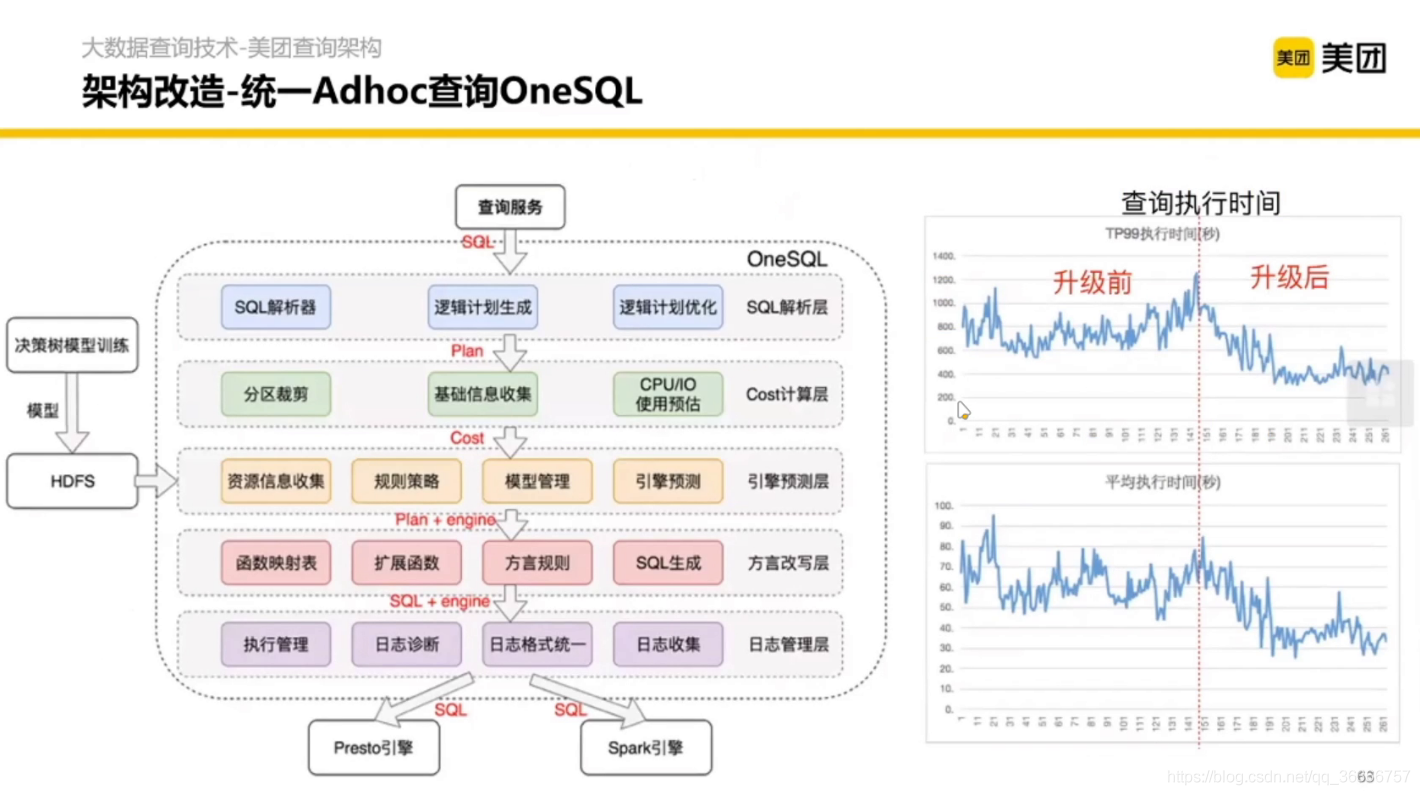
(竟然還有訓練決策樹模型,抽取特征判斷陳述句在那個資料庫上更快,再生成對應的引擎方言)
3.3 統一OLAP建設
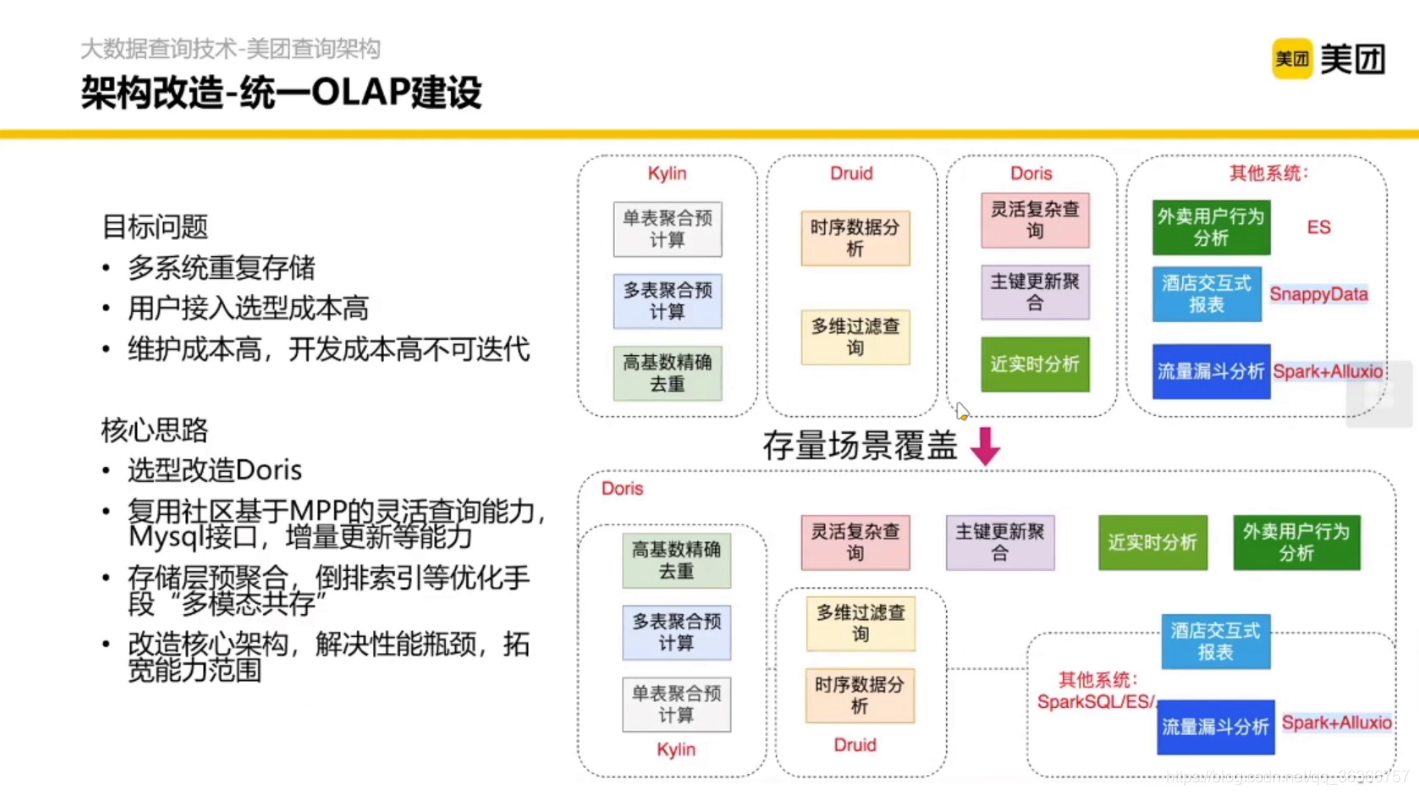
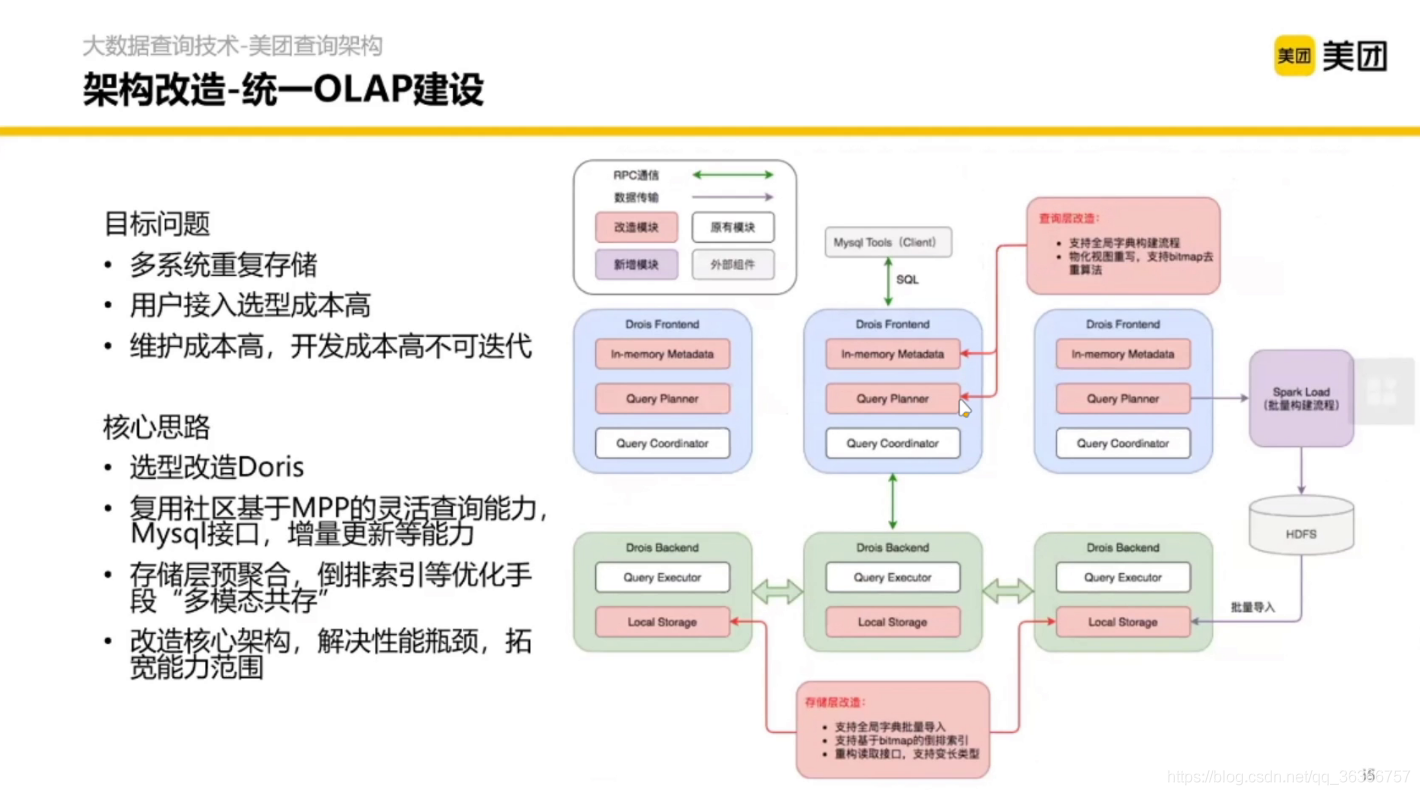
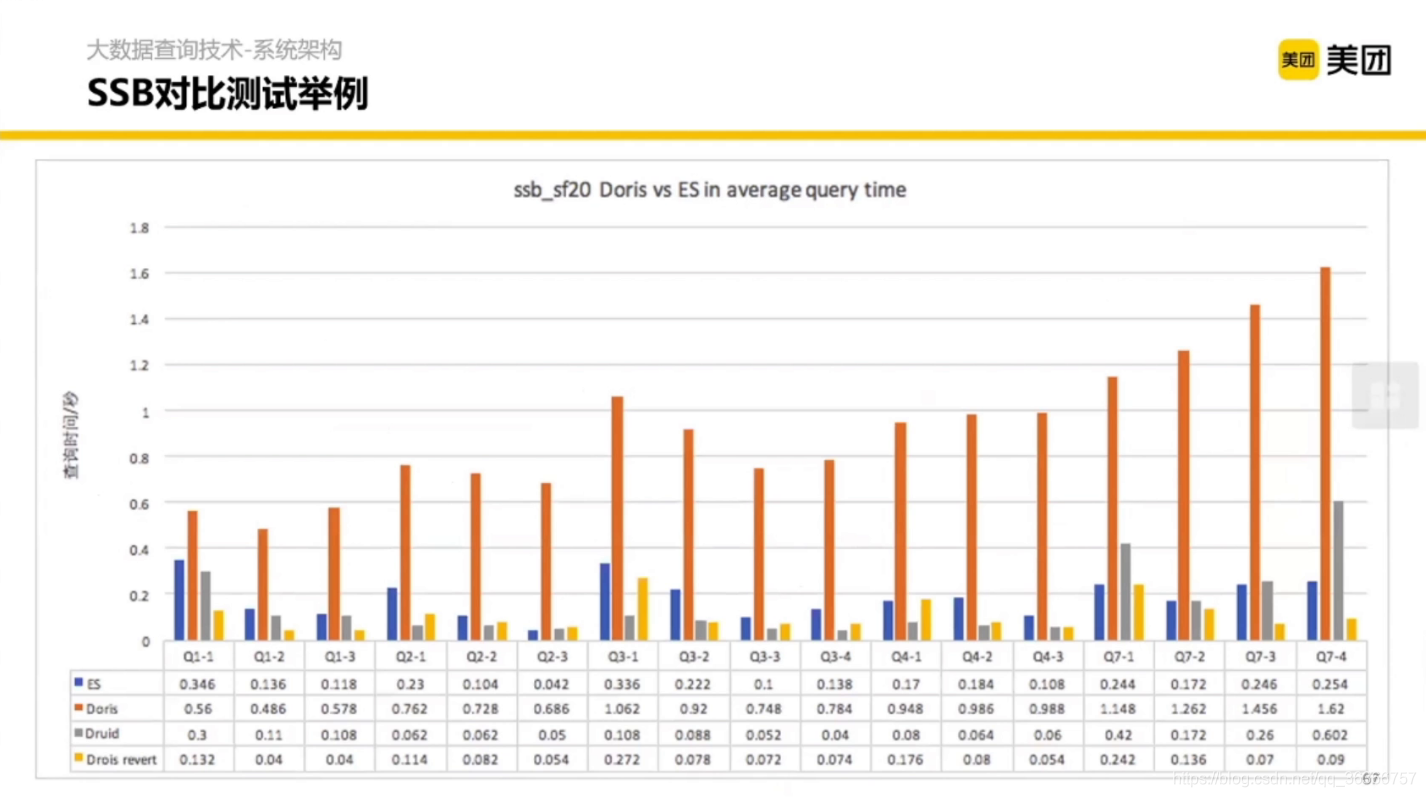
3.4 資料庫對比方法
通過多維角度對比資料庫,有兩個方法可以幫你構建資料庫的內容和 SQL 的結構,后拿著結構去測驗資料庫的實作,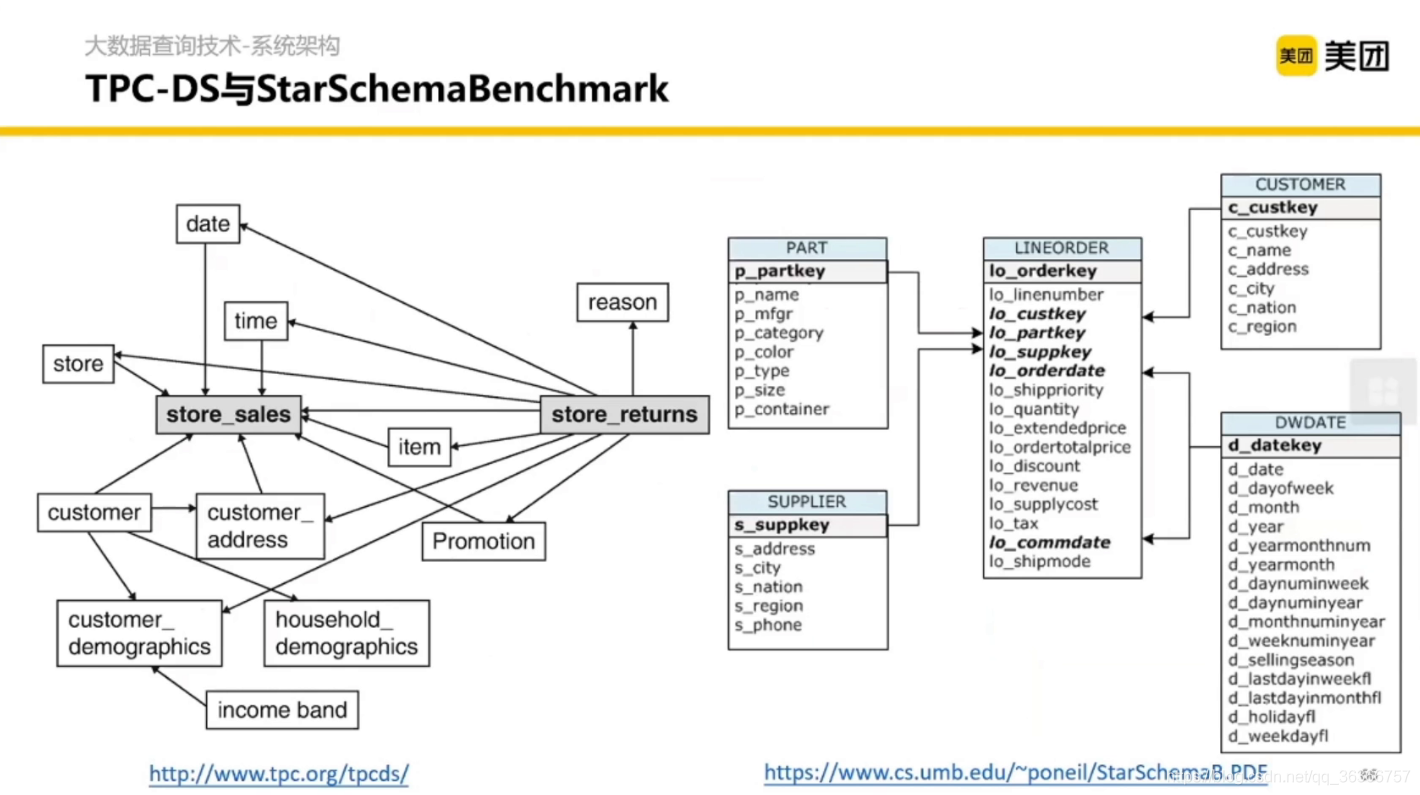
這是改造完之后的性能對比:
學習不易,且贊且收藏,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/199029.html
標籤:其他