文章目錄
- <1%的“例外”查詢影響OLAP引擎的穩定性
- 基于規則判斷的方式比較粗糙,只能解區域分問題
- 借鑒資料庫Query Optimizer思想建立查詢成本指標
- 掃描資料量預估
- 回傳結果集預估
- 回傳結果集基數預估的修正
- 確定成本閾值
- 基于SparkSQL的實作方案
- 統計每個時間片中資料總行數
- 統計每列資料的直方圖資訊
- 后記
- 多OLAP引擎聯合支撐
- 基于HyperLogLog演算法預估結果集基數
隨著用戶分析資料量的急劇增長與用戶多維實時互動分析資料的需求,OLAP引擎成了互動式資料分析的標配,
<1%的“例外”查詢影響OLAP引擎的穩定性
如何保證讓OLAP引擎能穩定高效地提供資料服務,是普遍面臨的一個問題,而影響OLAP引擎穩定性的一大原因是來自用戶的“例外”查詢:用戶由于錯誤操作或確實基于合理需求而觸發的大查詢可能會擠占整個集群的資源甚至會讓集群崩潰,從而影響到其他用戶的正常使用,甚至造成資料的丟失,

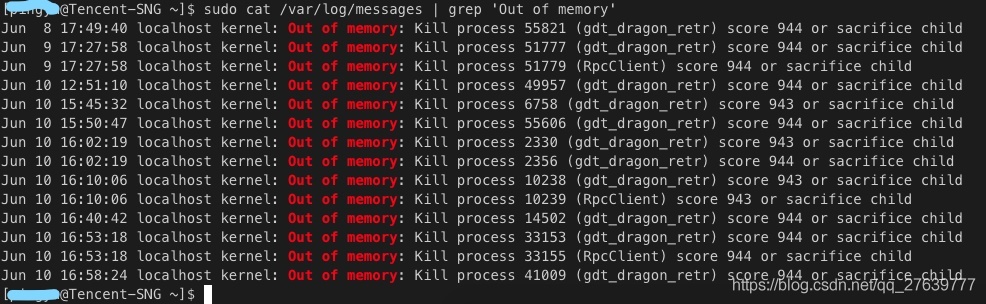
通常的做法是攔截或者采用其他計算引擎如SparkSQL來處理這些“例外”查詢,這都首先要求能很好的識別這些“例外”查詢,
基于規則判斷的方式比較粗糙,只能解區域分問題
首先想到的是基于預定規則判斷的方式來識別并攔截用戶的大查詢,這也是目前大多數系統的解決方案,一般是通過限制用戶查詢資料的時間跨度與同時查詢展開的維度兩個視角來進行識別攔截,如:
- 用戶的查詢跨度不能超過3個月;
- 用戶查詢的展開維度不能同時超過5個;
由于規則依據比較簡單固定,不能根據資料的特性進行調整,因此識別“例外”查詢的準確度比較差,這種方案存在以下不足:
- OLAP引擎多采用列存盤,那在限制查詢時間跨度時是不是需要根據用戶查詢的欄位數量進行動態調整?
- 不同欄位資料型別及其資料內容差異很大,是不是也應該差異對待?
- 不同維度的基數差異很大,且會隨著時間變化,在限制維度展開時是不是應該根據維度的基數進行動態調整?
基于規則判斷的方式比較粗糙,只能解區域分問題,那有更加智能的方式識別“例外”查詢嗎?
借鑒資料庫Query Optimizer思想建立查詢成本指標
總結分析發現“例外”查詢主要有兩大特點:
- 一是因為掃描處理的資料量太大從而占用過多的集群資源,影響對其他用戶查詢的回應;
- 二是由于回傳的結果集太大對節點造成很大的記憶體壓力,甚至導致集群節點OOM崩潰,
因此識別“例外”查詢問題的本質就是計算評估查詢的成本,這自然聯想到關系資料庫的Query Optimizer,資料庫的優化器有兩大類:基于規則的RBO優化器和基于成本的CBO優化器,RBO規則優化器只能承載一些明確的、簡單的預定義規則,應用范圍比較有限,而基于成本的CBO優化器被所有資料庫廣泛使用,不一樣的只是不同資料庫會定義不同的成本指標與優化函式,因此可以建立評估“例外”查詢的成本指標:
COST1 = 掃描資料量
COST2 = 回傳結果集
“例外”查詢 = COST1 > Threshold1 or COST2 > Threshold1
這樣識別“例外”查詢的問題就轉化為對掃描資料量和回傳結果集大小的預估,并根據其對集群穩定性影響的大小來評估確定兩個閾值,
掃描資料量預估
目前幾乎所有的OLAP引擎都采用列存盤來存盤資料,相比行存盤來說需要掃描的資料量小并且資料壓縮率更高,由于列存盤中不同列是分開獨立存盤的,則可以根據用戶查詢需要掃描的列以及各列占用存盤的大小來評估查詢要掃描的資料量,
// row_number表示查詢時間范圍內的總行數
// col1_bytes、col2_bytes分別表示各列資料占用的平均位元組大小
掃描資料量 = row_number * (col1_bytes + col2_bytes + ...)
OLAP引擎為了加速查詢都會對各列資料建立稀疏索引,同時在BI系統中用戶的查詢往往會帶有一些篩選項(通常是對維度的某幾個列舉進行篩選,而且各維度間的篩選條件是與的方式聯結),那是不是可以對上述的評估方法進行修正?如果能根據維度列的篩選項對滿足篩選條件的資料量進行預估(可依據下一小節的直方圖統計資訊預估),則可以將掃描資料量預估方法進行修正:
// col1_row_number、col2_row_number分別表示各列滿足篩選條件的行數,如該列沒有篩選條件,則其等于總行數row_number
// col1_bytes、col2_bytes分別表示各列資料占用的平均位元組大小
掃描資料量 = (col1_row_number * col1_bytes + col2_row_number * col2_bytes + ...)
維度型別可分為可列舉的維度和不可列舉的維度,對于可列舉維度來說,用戶往往是給定幾個篩選項來進行選擇,如選擇某個商品,對于不可列舉維度來說,用戶往往是給定一個篩選區間來進行選擇,這兩種情況都可以使用列資料直方圖的統計資訊預估滿足條件的資料量,
回傳結果集預估
在資料庫中預估回傳結果集基數大小cardinality-estimation多采用列直方圖預估的方式實作,假設在一個直方圖區間中值的分布是均勻的,其通過掃描各列資料,預先統計各列資料分布的直方圖資訊,以年齡列統計的等高直方圖為例:
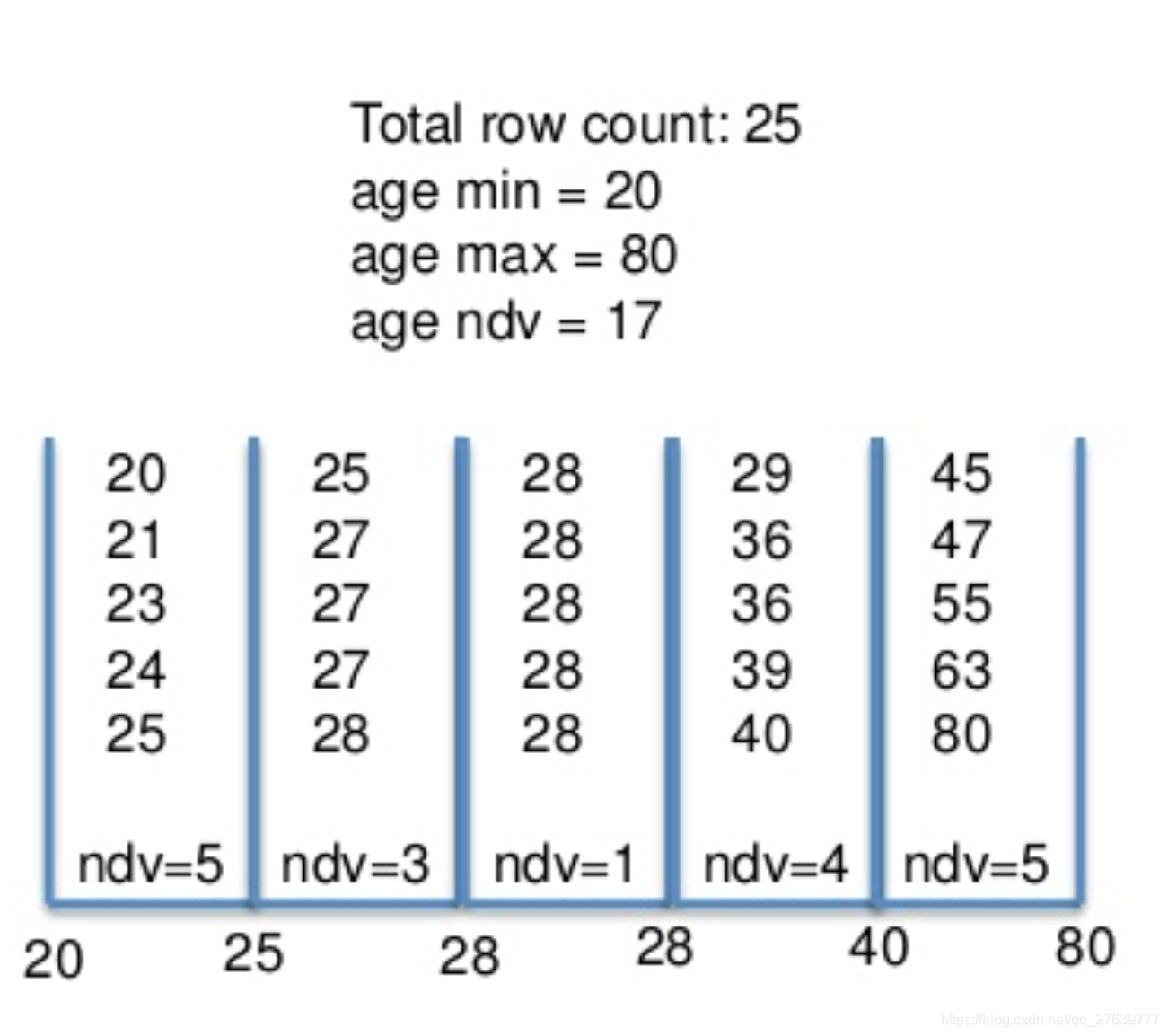
由于列資料中值的分布往往是不均勻的,因此直方圖統計多采用等高直方圖(即各區間的寬度是動態不固定的,而落入每個區間中的值的個數是相同的即等高)的方式,上圖中ndv表示每塊中不同值的個數即基數,
示例一:對于給定列舉值的基數預估,如預估age = 27的基數,
// 此類情況的基數預估比較簡單,直接等于篩選值的個數
// 由于篩選值在資料中不一定存在,是不是可以建立每個區間的Bloom filter來進一步判斷值是否存在?
回傳基數ndv = 1
// 由于是等高直方圖,因此每個區間的值個數為5,而第二個區間中不同值的個數為3,因此可預估age=27的資料量
掃描資料量 = 5 * 1 / 3 = 1.67
示例二:對于給定范圍的基數預估,如age > 38的基數,
// 范圍命中了最后兩個區間,根據每個區間的劃分范圍和其基數大小進行預估
回傳基數ndv = (40-38)/(40-28)*4 + (80-40)/(80-40)*5 = 5.67
// 范圍命中了最后兩個區間,每個區間中值的個數為5
掃描資料量 = (40-38)/(40-28)*5 + (80-40)/(80-40)*5 = 5.83
因此回傳結果集預估的成本指標函式如下:
// 回傳結果集基數等于各回傳維度基數預估的乘積
result_cardinality = col1_cardinality * col2_cardinality * ...
// 回傳結果集資料量大小等于結果集的總行數乘以每行的位元組數,每行的位元組數等于回傳各列位元組數的加和
result_bytes = result_cardinality * (col1_bytes + col2_bytes + ...)
回傳結果集基數預估的修正
直方圖預估基數的方式是假定各維度之間是相互獨立的,各列之間的資料是笛卡爾積組合的,因此其總的基數等于各列基數的乘積,但實際情況中各維度項之間往往是相關聯的,特別是當維度間具有層次關系時基數預估的誤差會被放大,
KYLIN引擎建立CUBE時通過用戶預定義聚合組、聯合維度和層級維度的方式裁剪維度組合的數量,那我們是不是可以將維度按其相關性進行分組,將相互關聯的維度劃分到一組中,假定各組維度之間是相互獨立的,在結果集基數預估時首先在每組維度中選出結果基數最高的維度作為這一組維度總的基數值,然后將各組的基數相乘來估算最終結果集的基數,
// 首先計算各組中維度基數的最大值作為該組的基數
group1_cardinality = max(col1_cardinality, col2_cardinality)
group2_cardinality = max(col3_cardinality, col4_cardinality)
// 然后將各組的基數相乘得到最終的基數估計值
result_cardinality = group1_cardinality * group2_cardinality
確定成本閾值
在得到掃描資料量和回傳結果集大小的預估值后,就需要確定判斷“例外”查詢的閾值大小,“例外”查詢是影響OLAP引擎的穩定性,因此需要根據實際集群的資源性能情況和對服務穩定性的要求來確定具體的閾值,可以通過實驗模擬實際查詢的方式來確定合適的閾值,
基于SparkSQL的實作方案
由于我們每天的資料都是通過Spark計算得到,因此可以通過在生成資料后新增一個Spark任務來統計每日生成資料的統計資訊,
統計每個時間片中資料總行數
AnalyzeTableCommand通過觸發生成一個job任務來統計表中資料的總行數和總位元組大小等資訊,
val tableName = "table_name"
val sqlText = "ANALYZE TABLE $tableName COMPUTE STATISTICS"
spark.sql(sqlText)
val tableId = TableIdentifier(tableName)
println(spark.sessionState.catalog.getTableMetadata(tableId).stats.get.simpleString)
// 總行數為7922238,資料總位元組大小為142276791 bytes
142276791 bytes, 7922238 rows
在每天的例行任務完成后增加一個Spark任務將每個時間片的資料臨時存入到一個臨時表中,然后通過表分析命令統計總行數資訊,
統計每列資料的直方圖資訊
AnalyzeColumnCommand命令可以統計表中列的統計資訊(默認直方圖資訊是不統計的,需要設定引數spark.sql.statistics.histogram.enabled=true來打開直方圖資訊的統計),
// AnalyzeColumnCommand represents ANALYZE TABLE...FOR COLUMNS SQL command
val tableName = "table_name"
val allCols = df.columns.mkString(",")
val analyzeTableSQL = s"ANALYZE TABLE $tableName COMPUTE STATISTICS FOR COLUMNS $allCols"
spark.sql(s"DESC EXTENDED $tableName adgroup_id").show(truncate = false)
spark.sql(s"DESC EXTENDED $tableName scene").show(truncate = false)
+--------------+-----------------------------------------------------------------------------+
|info_name |info_value |
+--------------+-----------------------------------------------------------------------------+
|col_name |adgroup_id |
|data_type |bigint |
|comment |廣告id |
|min |-1 |
|max |324051755 |
|num_nulls |0 |
|distinct_count|7020464 |
|avg_col_len |8 |
|max_col_len |8 |
|histogram |height: 4.71102879E7, num_of_bins: 10 |
|bin_0 |lower_bound: -1.0, upper_bound: 0.0, distinct_count: 2 |
|bin_1 |lower_bound: 0.0, upper_bound: 2.79059772E8, distinct_count: 924598 |
|bin_2 |lower_bound: 2.79059772E8, upper_bound: 2.86615295E8, distinct_count: 785414 |
|bin_3 |lower_bound: 2.86615295E8, upper_bound: 2.91429173E8, distinct_count: 649131 |
|bin_4 |lower_bound: 2.91429173E8, upper_bound: 2.95652736E8, distinct_count: 574800 |
|bin_5 |lower_bound: 2.95652736E8, upper_bound: 3.00972268E8, distinct_count: 709904 |
|bin_6 |lower_bound: 3.00972268E8, upper_bound: 3.04869169E8, distinct_count: 534671 |
|bin_7 |lower_bound: 3.04869169E8, upper_bound: 3.08332988E8, distinct_count: 473591 |
|bin_8 |lower_bound: 3.08332988E8, upper_bound: 3.14375206E8, distinct_count: 1031744|
|bin_9 |lower_bound: 3.14375206E8, upper_bound: 3.24051755E8, distinct_count: 1301775|
+--------------+-----------------------------------------------------------------------------+
+--------------+--------------------------------------------------------+
|info_name |info_value |
+--------------+--------------------------------------------------------+
|col_name |scene |
|data_type |int |
|comment |場景 |
|min |0 |
|max |95 |
|num_nulls |0 |
|distinct_count|64 |
|avg_col_len |4 |
|max_col_len |4 |
|histogram |height: 4.71102879E7, num_of_bins: 10 |
|bin_0 |lower_bound: 0.0, upper_bound: 1.0, distinct_count: 2 |
|bin_1 |lower_bound: 1.0, upper_bound: 3.0, distinct_count: 2 |
|bin_2 |lower_bound: 3.0, upper_bound: 6.0, distinct_count: 2 |
|bin_3 |lower_bound: 6.0, upper_bound: 12.0, distinct_count: 5 |
|bin_4 |lower_bound: 12.0, upper_bound: 12.0, distinct_count: 1 |
|bin_5 |lower_bound: 12.0, upper_bound: 12.0, distinct_count: 1 |
|bin_6 |lower_bound: 12.0, upper_bound: 13.0, distinct_count: 1 |
|bin_7 |lower_bound: 13.0, upper_bound: 28.0, distinct_count: 5 |
|bin_8 |lower_bound: 28.0, upper_bound: 45.0, distinct_count: 16|
|bin_9 |lower_bound: 45.0, upper_bound: 95.0, distinct_count: 33|
+--------------+--------------------------------------------------------+
可以看到,列統計資訊中包括:
min:最小值
max:最大值
num_nulls:null值個數
distinct_count:基數大小
avg_col_len:平均位元組長度
max_col_len:最大位元組長度
histogram:直方圖資訊,包括height - 每個區間的值個數,num_of_bins - 區間個數
lower_bound/upper_bound - 直方圖中每個區間的上下限值,distinct_count - 每個區間中值的基數大小
基于列統計資訊可以計算得到查詢掃描資料量和回傳結果集的大小,以下面的查詢為例:
維度展開:adgroup_id, scene
過濾條件:adgroup_id > 2.86615295E8 and adgroup_id < 3.04869169E8 and scene = 5
掃描的資料量為:
// adgroup_id > 2.86615295E8 and adgroup_id < 3.04869169E8命中了bin_3~bin_6,剛好是四個區間
adgroup_id列命中的記錄數 = 4.71102879E7 * 4 = 1.884411516E8
// scene = 5命中了bin_2,該區間只有兩個不同的值
scene列命中的記錄數 = 1 / 2 * 4.71102879E7 = 2.355514395E7
// adgroup_id列的平均列長度為8位元組,scene列的平均位元組長度為4位元組
掃描的資料量 = 1.884411516E8 * 8 + 2.355514395E7 * 4 = 1.6017497886E9 bytes
回傳結果集資料量為:
// adgroup_id > 2.86615295E8 and adgroup_id < 3.04869169E8命中了bin_3~bin_6
adgroup_id列的回傳基數 = 649131 + 574800 + 709904 + 534671 = 2468506
// scene = 5是屬于列舉值篩選
scene列的回傳基數 = 1
// 總基數等于各組維度基數的乘積
回傳結果集總基數 = 2468506 * 1 = 2468506
// adgroup_id列的平均列長度為8位元組,scene列的平均位元組長度為4位元組
回傳結果集資料量 = 2468506 * (8 + 4) = 29622072 bytes
SparkSQL的AnalyzeColumnCommand只支持數值列型別的統計,無法對字符型維度進行統計分析,可以參考Oracle在收集直方圖統計資訊時的處理方式,取文本值的頭32位元組(可根據情況減少到如8位元組)后將其轉換成數值型別進行統計分析,
后記
多OLAP引擎聯合支撐
這些對于像ClickHouse、Hermes等OLAP引擎來說是“例外”查詢的請求,也可能確實是用戶的正常需求,對于這類大查詢請求,可以結合使用如SparkSQL、presto和impala等OLAP引擎進行支撐,不同的OLAP引擎有不同的特性與支持場景,應該對用戶查詢進行智能分析,首先分析資料在哪里,然后根據查詢的特性選擇合適的引擎執行,多OLAP引擎聯合支撐才能很好地滿足用戶的需求,
基于HyperLogLog演算法預估結果集基數
對于預估結果集基數的問題,第一反應肯定是使用count(distinct)的方式直接進行統計,但這種精確去重的方式需要消耗大量的記憶體資源,甚至可能導致集群崩潰,如果在掃描資料量不是特別大的情況下,這種方式不可行的最大原因是需要精確去重,而基數預估本身是允許精度損失的,
結果集預估本質上就是一個UV量統計問題,那可以將其轉化成普通的可加性指標嗎?很容易可以想到采用HyperLogLog演算法來進行實作,HyperLogLog演算法將UV量轉變成普通的可加性指標,這樣只需要在每個服務器本地就行統計后將結果匯總即可得到總的結果,
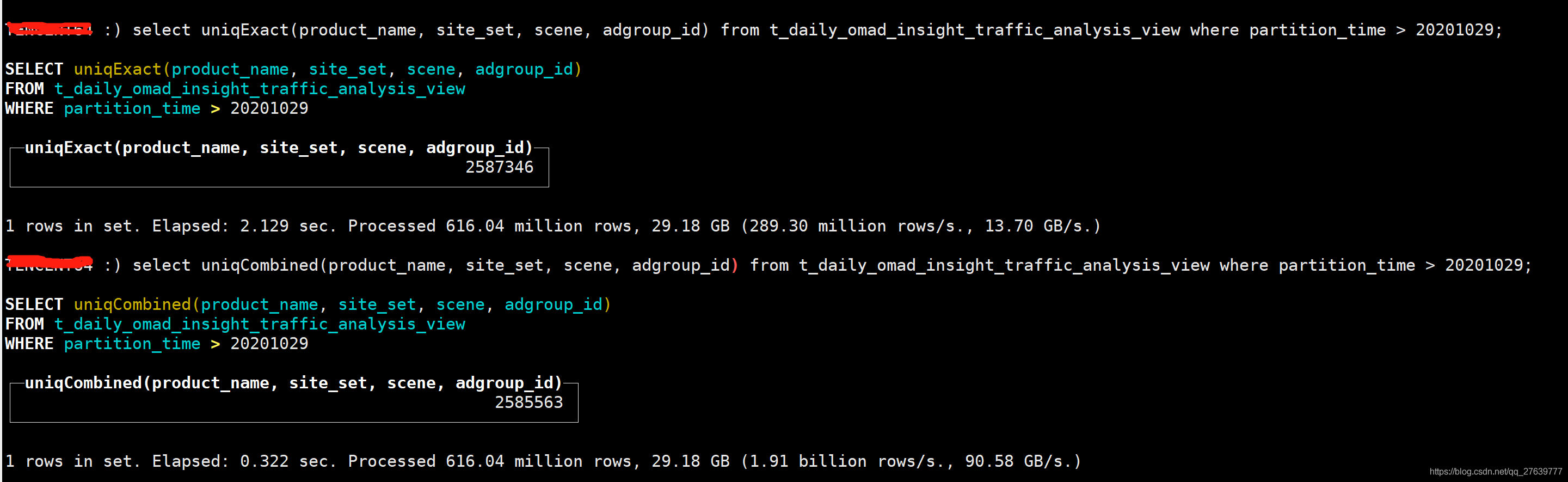
我們目前采用ClickHouse引擎來提供底層OLAP資料服務,查詢其檔案資料后發現其可以支持近似數量統計函式uniqCombined,而且其進行了實作優化,查詢性能非常好,
select uniqExact(product_name, site_set, scene, adgroup_id) from t_daily_omad_insight_traffic_analysis_view where partition_time > 20201029;
select uniqCombined(product_name, site_set, scene, adgroup_id) from t_daily_omad_insight_traffic_analysis_view where partition_time > 20201029;
轉載請註明出處,本文鏈接:https://www.uj5u.com/qianduan/200381.html
標籤:其他
上一篇:虛擬機時間同步的實作